一种基于SSD改进的目标检测算法
2020-04-02苏蒙,李为
苏 蒙,李 为
(华北电力大学控制与计算机工程学院,北京 102206)
0 引 言
目标检测是当前计算机视觉领域中一个极其重要同时也十分热门的课题。它的目的是识别出图片中的目标物体,并使用边界框将其定位出来。目前来说,基于深度学习的目标检测算法分为2大类:基于区域候选的模型和基于回归的模型。
基于区域候选的深度学习目标检测模型一般分为2个阶段:一是候选区域的建议;二是特征的提取和分类。这类模型的典型代表有:R-CNN[1]、SPP-net[2]、Fast R-CNN[3]、Faster R-CNN[4]、R-FCN[5]等。虽然以Faster R-CNN为代表的算法已经实现了端到端的训练,但是这些算法由于网络结构复杂,训练参数多,检测速度难以达到实时性的要求[6]。
基于回归的深度学习目标检测模型需要预先按照一定的方式划定默认框,然后在各个默认框上进行物体的分类和边框的预测。这类模型的典型代表有YOLO[7]、SSD[8]。YOLO的思想是将图像划分成为S×S大小的网格,然后对每个网格进行边界框和类别的预测。它舍弃了候选区域的建议,使得网络更加简单,极大地提高了检测速度[9],但是,这也限制了模型对临近物体的预测能力,导致密集型目标的检测会出现漏检,同时目标的定位准确度相比Fast R-CNN也下降了10%[10]。SSD结合Faster R-CNN和YOLO两者的优点,在YOLO的基础上借鉴了RPN的思路,在保证高精度检测的同时,兼顾了检测速度。之后,Fu等[11]在SSD的基础上,使用特征提取能力更强的残差神经网络Residual-101[12]来替换原来的VGG16[13],同时引入反卷积模块,提出新的DSSD模型。DSSD模型虽然提高了检测精度,但是其在速度上却有很大的下降。Jeong等[14]提出的R-SSD模型也有相同的问题。
深度学习中的注意力机制理论最早是由Bahdanau等[15]提出并应用到了机器翻译领域,之后,Minh等[16]将注意力机制应用到了RNN模型上,来进行图像分类。本文将在SSD模型的基础上,引入注意力机制,提出改进的SSD模型。并在Pascal VOC[17]数据集上进行对比实验。实验结果表明改进后的SSD模型在检测精度上有明显的提高。
1 改进的SSD模型
1.1 SSD模型简介
SSD是一种one-stage的目标检测网络。它借鉴了Faster R-CNN中的anchors机制,结合了YOLO回归的思想,并针对不同尺度的特征表达不同这一特点,采取了多尺度目标特征提取的方法,这些设计使得SSD的检测性能相对其他检测模型更好。
1.1.1 SSD模型结构
SSD模型主要分为2个部分:一个是位于前端的基础网络,它是一个深度卷积神经网络,主要用来对图像目标进行特征提取;另一个是一组级联的卷积神经网络,它的作用是将前一个网络所得到的特征图进行不同尺度条件的特征提取并进行分类和边框的预测。SSD模型框架如图1所示。

图1 SSD模型框架
图1中的SSD模型的输入图像大小为300×300,基础网络是VGG16,它将VGG16最后2个全连接层替换成了卷积层(图1中的Conv6和Conv7),之后又增加了多个卷积层。最后,SSD在Conv4_3、Conv7、Conv8_2、Conv9_2、Conv10_2、Conv11_2卷积得到的特征图上进行分类和位置回归。
1.1.2 SSD模型默认框的选取以及训练样本的选取
SSD采用多尺度的方法得到了多个不同尺寸的特征图。假设模型检测时共采用m层特征图,则第k个特征图的默认框比例公式如下:
(1)
式中:Smin一般取0.2;Smax一般取0.95,分别代表特征层默认框输入图像的比例。
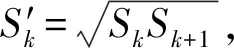
(2)
(3)
(4)
特征图上默认框坐标与原始图像坐标的映射关系如下:
(5)
(6)
(7)
(8)
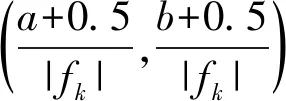
因为SSD产生了大量的默认框,在这之中仅选取与ground truth物体框交并比超过0.5的默认框进行下一步的训练。
1.2 改进的SSD模型
深度学习中的注意力机制借鉴于人类视觉的选择性注意力机制,通过快速扫描全局图像,获取需要重点关注的目标区域,而后对这一区域投入更多计算资源,以获取更多需要关注的细节信息,而抑制其他无用信息。这一机制极大地提高了视觉信息处理的效率与准确性。
本文将结合卷积块注意力模块(Convolutional Block Attention Module, CBAM)来对SSD模型进行改进。
1.2.1 CBAM介绍
CBAM在通道和空间2个维度上引入了注意力机制。CBAM的结构概览如图2所示。
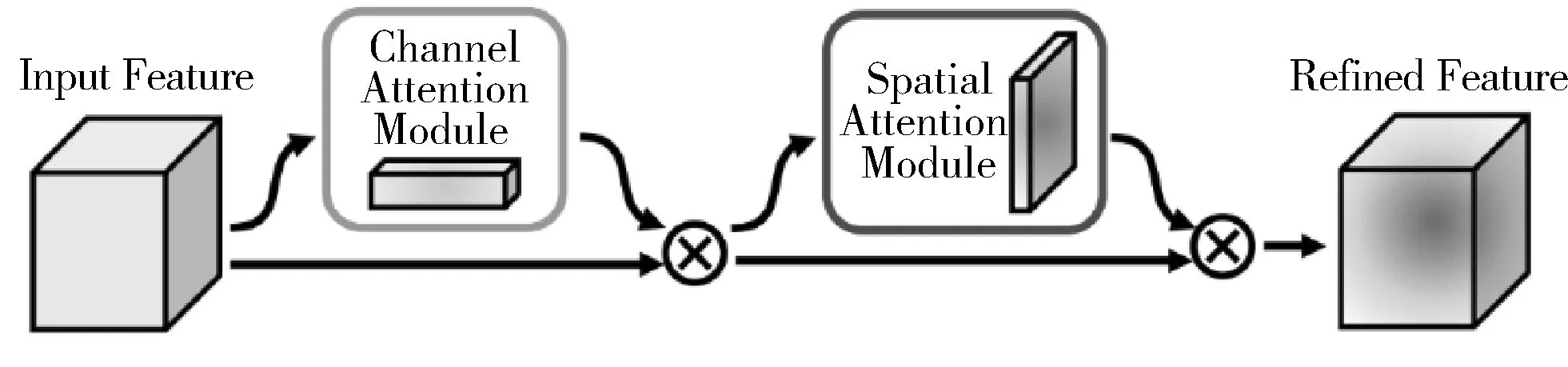
图2 CBAM的结构概览
CBAM模块主要是由2个部分构成:一部分是通道注意力模块(Channel Attention Module),另一部分是空间注意力模块(Spatial Attention Module)。
通道注意力模块借鉴了SENet[18](Squeeze-and-Excitation Networks)的思想,先对输入的特征图进行空间维度的压缩,然后进行通道注意力图的计算。与SENet不同的是,在进行压缩时,该通道注意力模块不仅考虑了average pooling,还额外地引入了max pooling作为补充。通道注意力模块具体结构如图3所示。
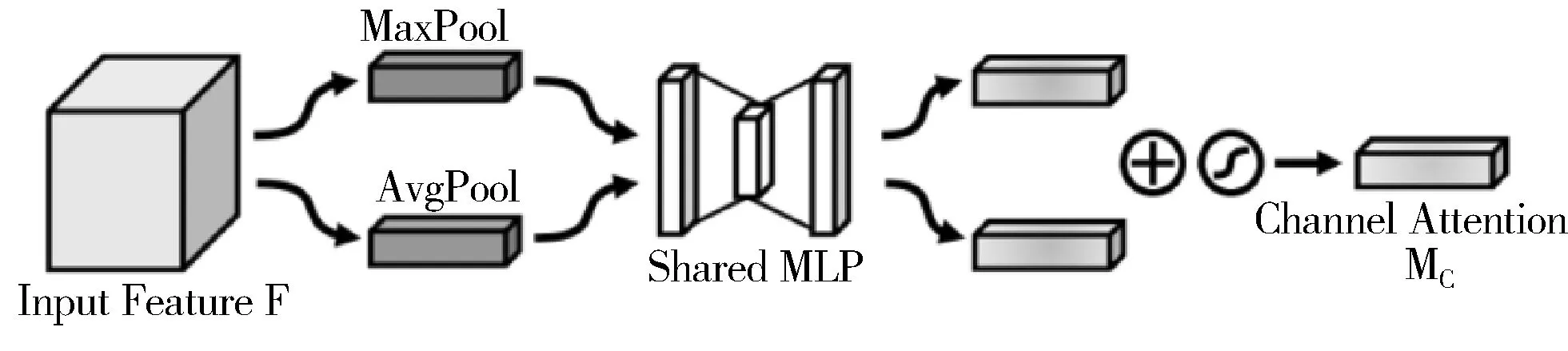
图3 通道注意力模块
具体计算公式如下:
Mc(F)=σ(MLP(AvgPool(F) )+MLP(MaxPool(F)))
(9)
Mc(F)=σ(W1(W0(Fcavg))+W1(W0(Fcmax)))
(10)
F表示输入的特征图,Fcavg和Fcmax分别代表经过average pooling和max pooling的特征图。W0和W1代表的是多层感知机模型中的2层参数,这2层神经网络的神经元使用ReLU作为激活函数。σ为sigmoid函数。在计算的时候,Fcavg和Fcmax共享多层感知机模型中的2层参数W0和W1。
空间注意力模块首先在通道层面上进行压缩,对输入的特征图在通道维度上分别做average pooling和max pooling,得到通道数为2的特征图。之后使用一个包含单个卷积核的隐藏层对其进行卷积操作。空间注意力模块具体结构如图4所示。
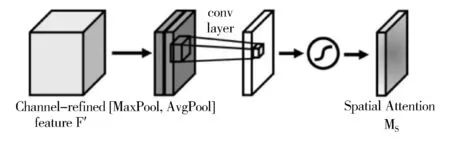
图4 空间注意力模块
具体计算公式如下:
Ms(F′ )=σ(f7×7([AvgPool(F′); MaxPool(F′)]))
(11)
Ms(F′)=σ(f7×7([Fsavg;Fsmax]))
(12)
F′表示经过通道注意力模块计算之后的特征图,Fsavg和Fsmax分别表示经过average pooling和max pooling的特征图。f7×7表示的是卷积运算,卷积核大小为7×7。σ为sigmoid函数。
1.2.2 嵌入CBAM的SSD模型
本文将在SSD模型的基础网络中嵌入CBAM模块,以提高SSD模型对图像中目标物体特征的提取能力,从而提高检测精度。
可以通过调整CBAM模块的输入和输出的大小,使得一个特征图在经过CBAM模块的处理后,仍然保持着之前的大小。因此,本文在保持SSD基本结构不变的前提下,将2个CBAM模块嵌入到SSD模型中。
改进后的模型在原SSD模型的基础上,在Conv4_3层以及Conv7层之后增加了CBAM模块。改进后的SSD模型网络结构如图5所示。
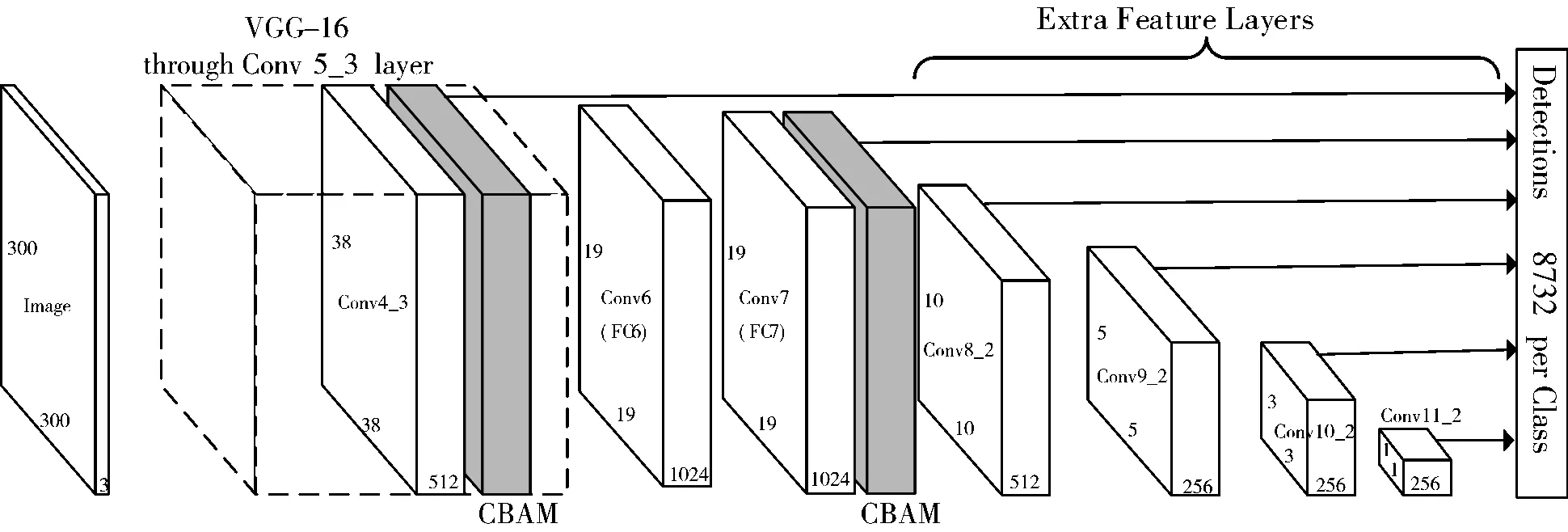
图5 改进的SSD模型结构示意图
虽然在Conv4_3和Conv7之后嵌入了CBAM模块,但是,Conv4_3和Conv7的特征图在经过CBAM模块的处理后,形状大小并没有发生改变,因此,SSD模型在Conv4_3、Conv7、Conv8_2、Conv9_2、Conv10_2、Conv11_2卷积得到的特征图的形状大小与之前一样。
2 实 验
搭建开发平台,CPU选用Intel(R) Core(TM) i7-7820X,GPU选用NVIDIA GeForce GTX 1080Ti,操作系统选用Ubuntu 16.04,深度学习框架为Pytorch1.1.0。
2.1 实验数据
本文使用的数据集是Pascal VOC,它是一套标准化的物体检测数据集,其中VOC2007中包括9963幅标注过的图片,共有24640个物体,VOC2012包含11540幅图片共27450个物体。
2.2 实验过程
本次实验使用随机梯度下降(SGD)的方法进行训练,每个batch的大小为32,初始学习率为0.001。当epoch等于150、200、250时,学习率下降90%,在训练至270 epoch时,停止训练。
在VOC2007训练集和VOC2012训练集上对改进后的SSD模型进行训练,模型的总误差稳定在2.4左右。误差变化曲线如图6所示。
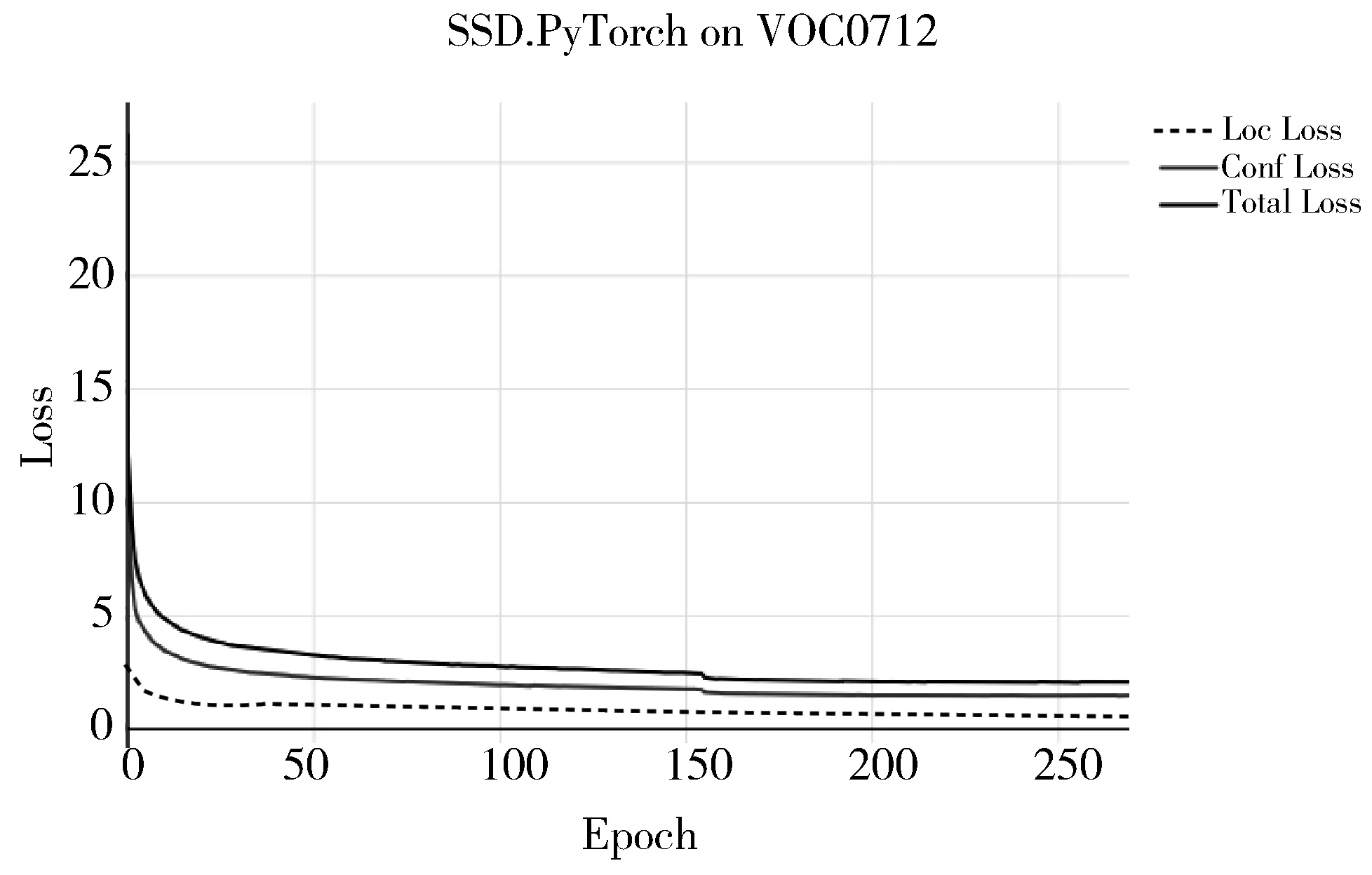
图6 Loss值变化图
在VOC2007训练集、VOC2007测试集以及VOC2012训练集上对改进后的SSD模型进行训练,模型的总误差稳定在2.5左右。误差变化曲线如图7所示。

图7 增加测试集后的Loss值变化图
2.3 评价指标
本次实验采用mAP作为模型的评价指标。mAP是平均精度均值,mAP兼顾了查准率和查全率,常被用作多目标检测的模型评价指标。mAP的计算公式如下:
(13)
其中,Q为目标物体的种类。q为某类物体在不同查全率下的查准率。AveP(q)是求某类物体的平均精度。
2.4 实验结果
在VOC2007训练集和VOC2012训练集上对改进后的SSD模型进行训练,并在Pascal VOC2007测试集上进行实验。实验结果与其他主流模型的对比如表1所示。
表1 VOC2007测试集实验结果对比
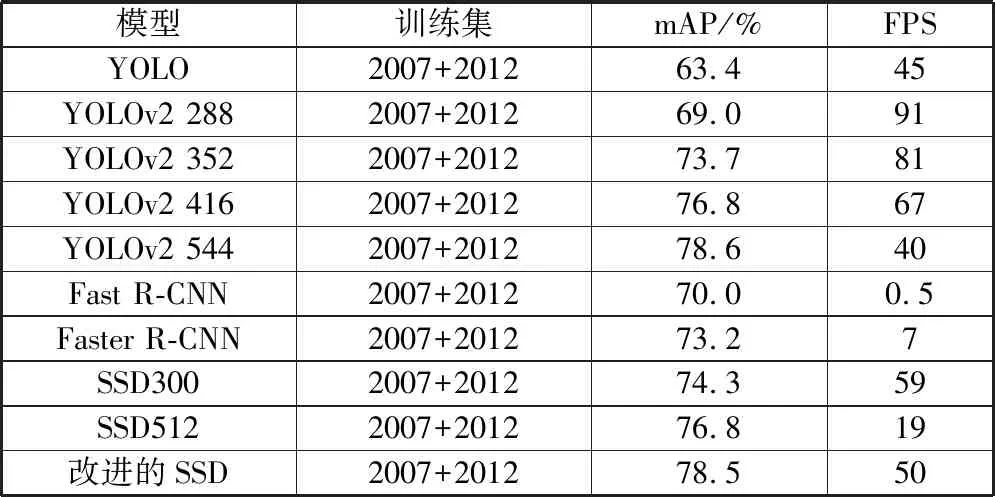
模型训练集mAP/%FPSYOLO2007+201263.445YOLOv2 2882007+201269.091YOLOv2 3522007+201273.781YOLOv2 4162007+201276.867YOLOv2 5442007+201278.640Fast R-CNN2007+201270.00.5Faster R-CNN2007+201273.27SSD3002007+201274.359SSD5122007+201276.819改进的SSD2007+201278.550
在VOC2007训练集、VOC2007测试集以及VOC2012训练集上对改进后的SSD模型进行训练,并在Pascal VOC2012测试集上进行实验。实验结果与其他主流模型的对比如表2所示。
表2 VOC2012测试集实验结果对比
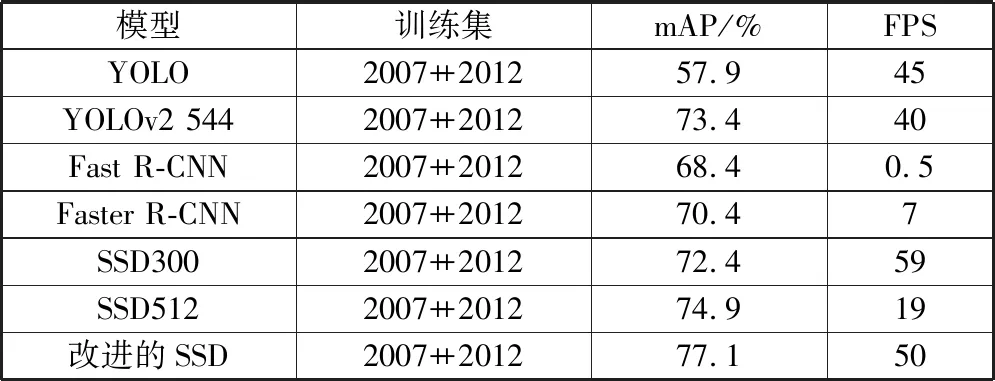
模型训练集mAP/%FPSYOLO2007++201257.945YOLOv2 5442007++201273.440Fast R-CNN2007++201268.40.5Faster R-CNN2007++201270.47SSD3002007++201272.459SSD5122007++201274.919改进的SSD2007++201277.150
表1和表2的实验结果表明:改进后的SSD模型在VOC2007测试集上的检测精度到达了78.5%,相较于原始的SSD300模型提高了4.2个百分点,在VOC2012测试集上的检测精度达到了77.1%,相较于原始的SSD300模型提高了4.7个百分点。改进后的模型在检测精度上高于表中的其他模型,检测速度可以达到50 FPS。
改进后的模型对各类目标的检测精度如表3和表4所示。
表3 VOC2007测试集各类目标检测精度对比 单位:%
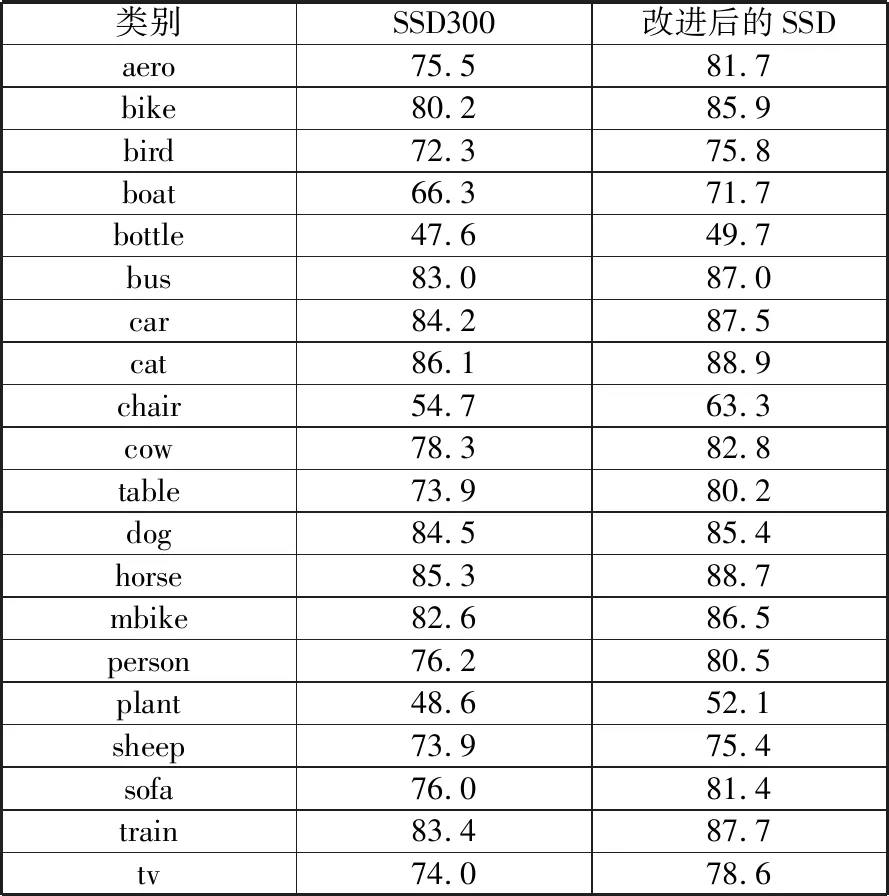
类别SSD300改进后的SSDaero75.581.7bike80.285.9bird72.375.8boat66.371.7bottle47.649.7bus83.087.0car84.287.5cat86.188.9chair54.763.3cow78.382.8table73.980.2dog84.585.4horse85.388.7mbike82.686.5person76.280.5plant48.652.1sheep73.975.4sofa76.081.4train83.487.7tv74.078.6
表4 VOC2012测试集各类目标检测精度对比 单位:%
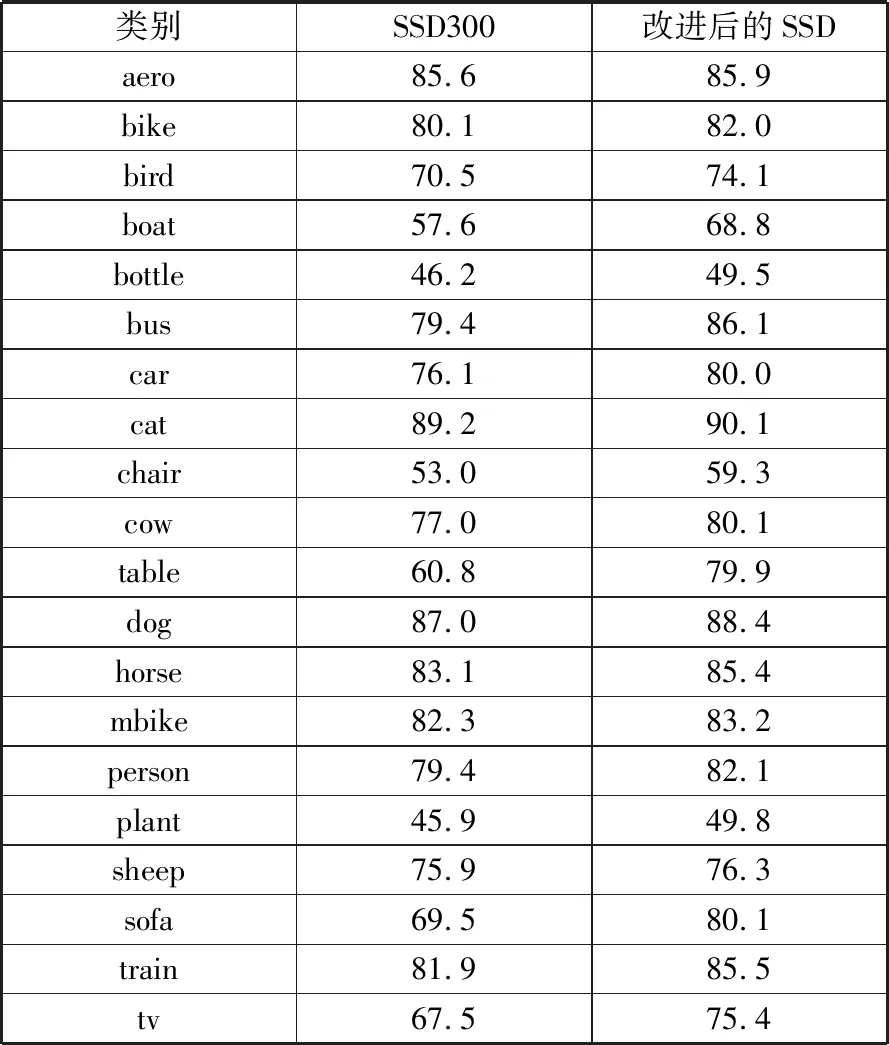
类别SSD300改进后的SSDaero85.685.9bike80.182.0bird70.574.1boat57.668.8bottle46.249.5bus79.486.1car76.180.0cat89.290.1chair53.059.3cow77.080.1table60.879.9dog87.088.4horse83.185.4mbike82.383.2person79.482.1plant45.949.8sheep75.976.3sofa69.580.1train81.985.5tv67.575.4
表3和表4中的实验结果表明:改进后的SSD模型对各类目标物体的检测精度都高于原始的SSD300模型。
2.5 实验结果分析
结合上述的实验结果可以得到如下结论:改进后的SSD模型,相较于SSD300模型在检测精度上有明显提高。这说明引入注意力机制,可以有效地提高模型对于图像特征的提取能力,使得模型对于各类目标的检测能力都有所提高。
3 结束语
为进一步提高目标检测算法SSD的检测精度,本文在SSD模型的基础上引入了注意力机制,以提高模型对目标特征的提取能力,在此基础上提出改进的SSD模型。改进的SSD模型检测精度有了明显的提高,同时在检测速度上也没有太大的下降。在之后的工作中,会尝试将注意力机制与多尺度特征融合相结合,引入自注意力等机制,进一步提高模型的检测精度。
