基于SMOTE和XGBoost的贷款风险预测方法
2020-04-02刘斌,陈凯
刘 斌,陈 凯
(陕西科技大学电子信息与人工智能学院,陕西 西安 710021)
0 引 言
互联网的迅速发展,影响着各个行业,金融行业也不例外。数据时代蕴藏着巨大的商机,善于利用大数据的企业将会获得新的发展方向和动力,而如何从大数据中提炼出有价值的信息是增强企业竞争能力的重要手段。随着大数据技术的应用,越来越多的金融企业也开始投身到大数据应用实践中[1]。金融的核心是风控,好的风控依托于数据。在互联网金融迅猛发展的背景下,风险控制问题已然成为行业焦点,基于大数据的风控正在成为互联网金融领域的热门战场。
随着当前贷款总量的不断加大,用户违约概率不断攀升,用户贷款的风险便渐渐显露出来[2-3]。此时,一个准确的风险预测模型是非常重要的。在线信贷的风险是多种多样的,目前对于信贷风险的预测主要有刘红生等人[4]提出的Logistic回归模型,他们以某一农村合作银行为例,建立了Logistic回归模型来对企业的贷款违约情况进行了预测分析和比较,认为Logistic回归模型是较为理想的预测模型。范彦勤[5]应用主成分分析法对数据进行特征提取,然后提出了2种贝叶斯分类模型来对个人信用进行预测,并与其他模型对比,发现基于贝叶斯分类的预测模型误分类较少。文献[6]在建立较为全面的评估体系之后,提出了基于随机森林算法的绿色信贷风险评估模型,并以某一上市公司为对象进行了实例分析,结果表明该模型评估准确率比传统模型更高。但这些算法对于维度庞大,包含大量噪声且分布不平衡的贷款数据,预测效果和性能仍然有待提升。
为了解决上述问题,本文通过特征工程的方法结合SMOTE算法对贷款数据进行处理,得到去噪、纬度较低的数据,并增加数据集中少数类样本的数量,使数据接近平衡。然后通过XGBoost算法构建贷款风险预测模型,将精确率、召回率、准确率、F1值作为分类的评价指标,对预测结果的有效性进行评价,并与上述分类算法进行对比,接着对比不同正负样本比例时模型的预测效果,来验证SMOTE算法对模型是否有提升作用。
1 特征工程
本次实验数据来源于美国网络贷款平台LendingClub在2007-2015年间的信用贷款情况,主要包括贷款状态和还款信息。包括:信用评分、地址、工作年限、房屋状态等累计75个属性(列),89万个实例(行)。算法的应用场景是根据各属性对贷款的风险进行预测。由于数据是从真实场景下得到的,无法直接用于实验,所以特征工程[7]是本次实验的首要任务,也是本次实验的重点。
1.1 特征提取
原始数据中存在缺失值,还存在一些与模型决策明显没有关系的特征,因此要进行特征的筛选与提取。
1)缺失值处理。
本次实验中,存在部分缺失率超过40%的特征,这些特征会影响模型的准确度,因此将这类特征直接删除。对于缺失率较低的特征,根据特征的实际意义使用插补法[8],如均值插补和众数插补法,或者通过其他特征与缺失值之间的关系对缺失值进行预测填补。
2)数据过滤。
对于冗余或者与构建预测模型无关的属性进行删除,如地址、邮编、贷款发行时间、网址等,减少其对模型带来的干扰[9],并降低特征的纬度。
1.2 特征抽象
对于数据集中的一些类别特征,机器学习算法不能直接识别,需要将其转化为合适的模型输入。如数据集中特征变量loan_status(贷款状态)用来描述当前贷款处于什么状态,原始数据中共6种状态。本次实验结果是对贷款的风险进行预测,理想的预测结果分为正常和有风险2种,是一个二分类问题。所以根据实际意义,将上述贷款状态抽象为2类,一类为正常贷款,编码为0,另一类为违约贷款(有风险贷款),编码为1。具体分类方法如表1所示。
表1 贷款状态抽象
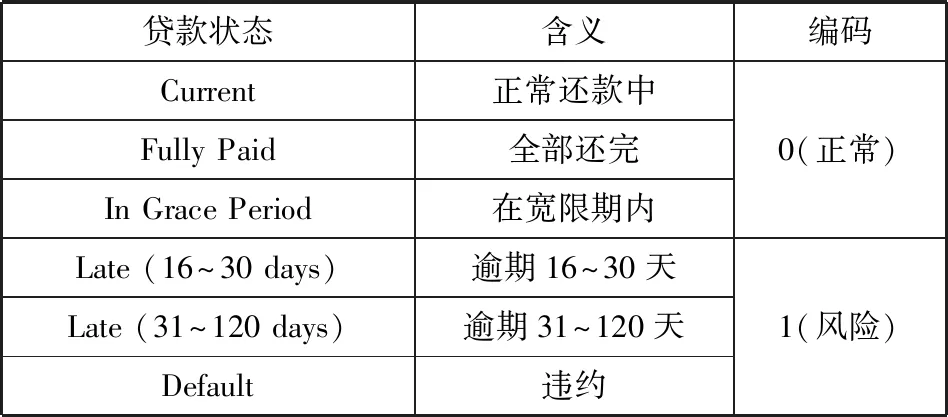
贷款状态含义编码Current正常还款中Fully Paid全部还完In Grace Period在宽限期内0(正常)Late (16~30 days)逾期16~30天Late (31~120 days)逾期31~120天Default违约1(风险)
但是对于贷款类别这种特征,各类别之间并不能进行直接比较,所以无法使用数值编码,这种情况可以使用哑编码方法[10],即利用多个占位符,如用(1,0,0,0)和(0,1,0,0)来代表不同的类别,有多少个类别,就用多少个占位符表示。
1.3 特征缩放
在多指标的评价体系里,各个指标性质不同,因此有着不同的量纲和数量级。当各指标之间的水平相差比较大时,如果直接用原始的值进行学习,就会突出数值较高的指标在模型中的作用,从而削弱数值水平较低指标的作用。因此,为了保证结果的可靠性,需要对原始特征值进行缩放[11]。本次实验采用标准化的方法来进行特征缩放。标准化后的值如式(1)所示:
X′=X-μ/σ
(1)
式(1)中,μ是样本数据的均值,σ是样本数据的标准差。经标准化的数据变成了一个均值为0,方差为1的正态分布。对变量进行的标准差标准化可以消除量纲的影响和变量自身变异的影响。
1.4 特征选择
模型要优先选取与预测目标相关性较高的特征,不相关特征可能会降低分类的准确率,因此为了增强模型的泛化能力,需要从原有特征集合中挑选出最佳的部分特征,并且降低学习的难度,从而简化分类器的计算。特征选择[12]的方法主要有嵌入法(embedded approach)、过滤法(filter approach)、包装法(wrapper approach)。本次实验主要采用filter方法,通过皮尔森相关系数得出各个特征间的相关性,找出相关性极高的冗余特征并将其剔除,降低特征的维度。经过特征工程后得到表2中所示的数据集。
表2 数据集特征描述
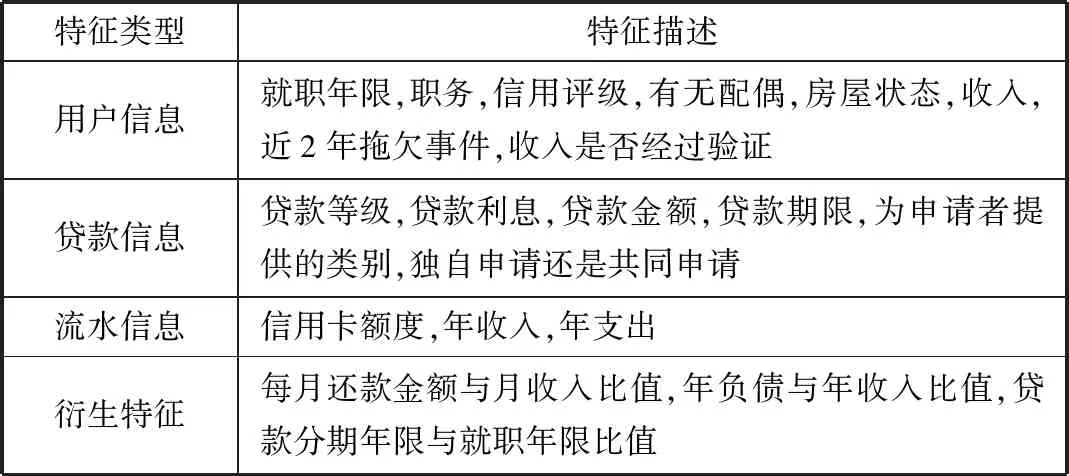
特征类型特征描述用户信息就职年限,职务,信用评级,有无配偶,房屋状态,收入,近2年拖欠事件,收入是否经过验证贷款信息贷款等级,贷款利息,贷款金额,贷款期限,为申请者提供的类别,独自申请还是共同申请流水信息信用卡额度,年收入,年支出衍生特征每月还款金额与月收入比值,年负债与年收入比值,贷款分期年限与就职年限比值
2 非平衡数据处理
2.1 类不平衡问题
类不平衡(class-imbalance)是指在训练分类器中所使用的训练集的类别分布不均[13-14]。比如一个二分类问题,1000个训练样本,比较理想的情况是正、负样本的数量相差不多;而如果正样本有995个、负样本仅5个,就意味着存在类不平衡。图1展示了本次数据中正负样本的分布情况。可知本次实验数据正负样本比约为10:1,是一个典型的高度不平衡的数据。

图1 正负样本分布情况
针对类不平衡问题,在数据层面目前主要的解决办法是通过重采样技术,对样本进行欠采样或者过采样[15-16],调整样本的不平衡程度:
1)欠采样。
对训练集里面样本数量较多的类别(多数类)进行欠采样,抛弃一些样本来缓解类不平衡。欠采样有一个很大的缺点是未考虑样本的分布情况,而采样过程又具有很大的随机性,可能会误删多数类样本中一些重要的信息。
2)过采样。
过采样是指通过人工生成训练集里面样本数量较少的类别(少数类)。目前过采样比较常用的算法是SMOTE算法。
2.2 SMOTE算法
文献[17]提出了一种过采样算法SMOTE。概括来说,此算法通过“插值”来为少数类合成新的样本。
假设训练集的一个少数类的样本数为T,那么SMOTE算法将为这个少数类合成N×T个新样本。这里要求N必须是正整数,如果给定的N<1那么算法将认为少数类的样本数T=N×T,并强制N=1。
考虑该少数类的一个样本i,其特征向量为xi,i∈{1,…,T},为其人工生成样本的步骤如下:
步骤1首先从该少数类的全部T个样本中用欧氏距离找到样本的k个近邻,记为xi(near),near∈{1,…,k}。
步骤2然后从这k个近邻中随机选择一个样本xi(nn),再生成一个0到1之间的随机数,从而合成一个新样本:
xi1=xi+ζ1·(xi(nn)-xi)
步骤3将步骤2重复进行N次,从而可以合成N个新样本:xinew,new∈{1,…,N}。
步骤4对全部的T个少数类样本进行上述操作,便可为该少数类合成N×T个新样本。
本次实验通过Python调用库imbalanced-learn来实现SMOTE算法,初始数据集中正负样本比例为10:1,通过调节参数,分别得到正负样本比例为10:2、10:4、10:6、10:8、1:1的数据集。
3 XGBoost分类
XGBoost是Boosting算法中的一种。Boosting算法的思想是将许多弱分类器集成在一起形成一个强分类器。XGBoost是一种提升树模型[18-19],所以它是将许多树模型集成在一起,形成一个很强的分类器。而所用到的树模型则是CART回归树模型。XGBoost算法在进行优化时,对损失函数进行了二阶泰勒展开,充分利用了一阶导数和二阶导数。算法的步骤如下:
1)模型表示为:
(2)
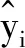
2)优化目标和损失函数:
(3)
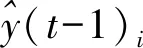
对式(3)进行二阶泰勒展开,并移除常项,简化后的目标函数为:
(4)
式(4)中,gi是一阶导数,hi是二阶导数。
3)求最优值。
将每个样本的损失函数值加起来,每个样本都会落入一个叶子结点中,将同一个叶子结点样本进行重组,可以把目标函数改写成关于叶子结点分数的一个一元二次函数,可以直接使用顶点公式求解最优W和目标函数的值:
(5)
(6)
式(5)为最优W,式(6)为目标函数的值。
XGBoost算法在分类方面表现非常优异,具有很高的准确度和运行效率[20]。本次实验将构建预测模型,把XGBoost算法应用到贷款风险预测中,并与其他分类算法进行比较。
4 实验结果
4.1 评价指标
本次实验中贷款风险的预测是一个二分类模型,因此选取准确率(Acc)、精确率(Pre)、召回率(Re)、F1值作为评估指标[21],定义正样本为正常贷款、负样本为有风险贷款。准确率、精确率、召回率、F1值分别定义如下:
(7)
(8)
(9)
(10)
式中各值的含义如表3中混淆矩阵所示。
表3 风险预测混淆矩阵

混淆矩阵预测正样本负样本实际正样本tpfn负样本fptn
4.2 实验结果分析
本次实验以7:3的比例将数据集分成训练数据集和测试数据集,然后将训练数据集通过SMOTE算法进行过采样,分别得到正负样本比例为10:2、10:4、10:6、10:8、1:1的数据集。然后使用训练数据,进行贷款风险预测模型的训练。并通过交叉检验的方法对模型进行优化,最后通过测试数据集来验证模型的有效性。
4.2.1 分类算法有效性对比
本实验用于对比3种算法的预测效果。分别通过常用的逻辑回归[22]、目前分类效果非常好的随机森林算法[23]以及本文提到的XGBoost算法对相同的数据集进行预测。其中逻辑回归和随机森林使用Python sklearn中的相关模块,XGBoost使用Python中的XGBoost包来实现。各算法中的参数均设置为调参后的最优值,预测结果如表4所示。
表4 3种算法实验结果

算法准确率精确率召回率F1值逻辑回归0.7280.7480.7360.734随机森林0.9370.9290.9370.931XGBoost0.9500.9510.9410.951
由表4可以看出,通过3种算法对贷款风险进行预测时,逻辑回归模型即使将参数调到最佳之后,准确率也仅有0.728,预测效果非常差,精确率和召回率也很低。随机森林和XGBoost算法在准确率、精确率、召回率、F1值4个方面效果都较好,其中XGBoost在各指标方面明显优于其他2种算法。而且XGBoost算法是高效并行机器学习算法,与其他方法相比,能克服传统方法在数据规模较大时效率不够高的问题,模型训练速度优于其他算法,可以有效利用大规模数据提升预测的精度。
4.2.2 过采样算法有效性对比
本实验对比在不同正负样本比例下,算法预测的效果,来验证通过SMOTE算法改变少数类样本数量后,能否提高预测模型的有效性。
本次实验利用本文提到的XGBoost算法对正负样本比例不同的数据集分别进行预测。每组模型中的参数均设置为调参后的最优值。
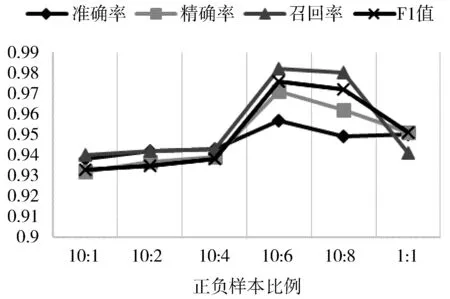
图2 不同样本比例有效性对比
图2为不同正负样本比例时预测结果的有效性指标,从图中可以看出通过SMOTE算法逐渐增加负样本的数目,4个指标都有所提升,其中召回率的提升最为明显。从混淆矩阵可以看出,随着负样本数量的增加,模型对负样本的预测更加准确。在正负样本比例达到10:6时,各指标值达到最高,预测效果最好。之后继续增加负样本的数量,预测效果会开始降低,原因是通过SMOTE算法人工产生的样本过多,复制出的少数类样本会导致模型出现过度拟合的问题,使模型在测试集上的预测效果变差。
5 结束语
本文提出一种基于SMOTE和XGBoost的贷款风险预测方法,通过特征工程对原始数据集进行处理,得到低维度、低噪声的数据。实验结果表明,相比于传统分类模型,XGBoost算法在贷款风险预测模型中具有更好的效果;通过SMOTE算法进行过采样,提高了少数类样本的数量,经对比实验表明,本次实验采用的过采样算法可以提高预测模型的预测效果。
在未来的工作中,希望采用组合模型的方法,将XGBoost与其他分类算法结合,进一步提高预测的准确率。另一方面,应用大数据技术,实现算法并行化[24],提升算法效率。
