人工智能在作战仿真中的应用研究
2020-04-02付长军郑伟明刘海娟
付长军,郑伟明,葛 蕾,刘海娟
(中国电子科技集团公司第五十四研究所,河北 石家庄 050081)
0 引言
现代战争的范围已经从陆、海、空、天向网络空间、电磁空间拓展,未来的对抗形式主要表现为陆、海、空、天、电、网六位一体保障条件下的精兵作战。随着网络空间和电磁空间的加入,战场的要素和相互制约关系已经远超人类合作协同所能掌控[1]。战争的胜负将不仅仅取决于人员的多少、装备的数量,更重要的是作战双方对信息的掌握和应用。战争胜利的关键将取决于认知速度,而认知速度的快慢,取决于对智能技术的利用程度。在认知域,计算机的角色将从辅助决策转变为自主决策。
AlphaGo在机器模拟人类直觉判断、自主学习等人类行为模拟方面取得的突破,给作战推演的智能化发展带来很多成功经验[2]。综合利用多种机器学习、深度神经网络等人工智能技术,构建联合作战指挥兵棋推演环境,对新战法的发现和武器装备的检验具有重大意义。美国国防高级研究计划局于2016年启动了频谱协同挑战赛,希望借助挑战赛的形式,依靠人工智能去发现和利用频谱“空隙”和其他可提高频谱效率的机会,找到未来全新的通信系统和对抗模式。国内,国防科技创新特区从2018年开始举办了“先知·兵圣”人机对抗挑战赛,旨在以兵棋推演等作战模拟对抗技术为手段,探索人工智能在作战决策中的作用。
未来,在认知域作战需求的驱动下,智能辅助成为作战推演系统升级换代中一个不容忽视甚至是需要争分夺秒去解决的问题。仿真推演作为一种研究战争的利器,是体系作战的重要决策判断工具,在提高指挥人员谋略水平、辅助作战决策、进行战术战法研究与验证等方面发挥重要作用,主要形式包括兵棋推演、红蓝对抗及人在回来等。如果说认知域是未来体系对抗的主战场,那么作战仿真就是体系对抗研究的虚拟战场,而智能推演就是未来体系对抗的机关枢纽。
1 作战仿真概述
1.1 概念与内涵
仿真是构造反映实际系统运行行为特性的数学模型和物理模型在计算机或其他形式的仿真设备上,复现真实系统运行的复杂活动[3]。美国国防部将仿真定义为“建立系统、过程、现象和环境的模型,在一段时间内对模型进行操作,应用于系统的测试、分析或训练,系统可以是真实系统或由模型实现的真实和概念系统[4]”。作为系统仿真的一个重要分支,作战仿真通过对作战平台和参战装备进行模型化,模拟交战过程中平台和装备的运行数据,对作战规律和技战法进行研究,主要包含体系仿真、战役仿真、战术仿真和技术仿真4个层次的内容[5]。
1.2 关键技术概述
20世纪90年代以来,仿真技术均作为国防关键技术出现在历年《国防技术领域计划》中,被视作“军队和经费效率的倍增器”,美国军用仿真计划发展态势如图1所示。针对作战仿真推演中不同仿真平台之间的连接问题,美国于90年代在DIS2.x系列标准和ALSP标准之上形成了分布交互仿真技术,但是该技术体制在互操作性和重用性等方面显示出一定的局限和不足。

图1 美国军用仿真计划发展态势Fig.1 Development trend of US military simulation program
1996年,由使命空间概念模型、高层体系结构(High Level Architecture,HLA)和系列数据标准组成的体系架构,成为当前交互式仿真的主要标准,并为各国所借鉴[6-7]。HLA通过在底层采用以面向对象程序设计的思想和方法,解决了大规模复杂的分布式交互仿真系统中不同种类、不同规模的仿真系统的互操作、重用和扩展等问题[8]。2001年美国国防部将非HLA技术架构的仿真项目全部淘汰。
进入21世纪后,实时通信数据交互逐渐兴起,国际对象管理组织制定了面向数据实时通信要求的标准和规范——数据分发服务(Data Distribution Service,DDS)[9]。作战仿真推演系统开始采用以HLA+DDS的开发与运行模式,基于匿名发布/订购机制和服务质量策略,DDS规避了仿真建模领域中的互操作、重用和可组合的问题,达到“在正确的时间把正确的数据分发给正确的接收者”的目标,实现了基于功能集成的显式耦合向基于数据集成的隐式耦合的转变。现有的导调控制软件中绝大多数都是基于 HLA 与DDS联合开发实现的。
针对作战试验与训练领域的烟囱式设计问题,实现靶场资源之间的互操作、重用和可组合,2010年美国国防部启动了基础计划工程(FI2010),提出试验与训练使能体系结构(TENA),形成匿名发布/订购数据分发和CORBA分布对象的概念,采用状态分布对象这种编程抽象,为整个靶场事件生命周期的数据库信息包括剧情信息和演练期间采集数据提供管理和标准化。
HLA,DDS,TENA已经成为当前军事仿真推演领域成熟而有力的标准规范,能够较好地解决各类仿真需求中面临的问题。
1.3 应用价值
装备仿真推演不仅可以指导实战,还能够形成从大系统协同设计到仿真验证和试验评估的闭环,有效支撑军委总部及各军兵种用户方向总体类项目的规划、立项论证、研制、试验验证和验收工作,从作战需求层面牵引专业技术发展。具体的应用包括但不限于以下几个方面[10-11]:
① 指导实战:通过作战仿真,能够对演习和真实交战过程进行复盘,从而发现军事部署和战斗过程中的问题,从第一次世界大战开始,作战仿真就已经发挥了重大作用。
② 战法发现:通过作战仿真,发现新时代网络信息体系下联合作战的新战法。
③ 军事训练和军事教学:19世纪末,仿真推演在军事训练中的重要作用已经突显出来。特别是在第一次世界大战期间,基于兵棋的作战模拟已经作为军事学校的教学内容在欧美国家的军队中推广。
④ 演示验证:能够对武器装备产品的作战能力和体系贡献度进行充分演示验证。
⑤ 效能评估:综合地形、防御态势、气候、电磁环境和机动性等多个要素,对武器装备或技战法的作战效能给出客观评价。
⑥ 工程服务:通过作战仿真及早发现设计中维修、保障等方面的问题,提高工程服务质量。
⑦ 展览展示:基于战场环境实时态势,显示参战各方推演态势,极近真实地体验装备产品对联合作战的贡献程度。
⑧ 交流培训:对装备使用者和指挥员进行培训,与用户、业内人士进行交流。降低培训成本,提高培训质量,提高学习训练的实操性和互动性。
⑨ 商业应用:作战推演不仅应用于军事领域,还受到军事爱好者的青睐。冯·莱斯维茨发明兵棋后不久,就有人把它变成了商品在市场上公开出售。目前市面上仍流行着多种兵棋推演游戏以及基于作战仿真为理念的策略游戏,如《指挥官:伟大的战争(Commander:The Great War)》。
2 AlphaGo 对作战仿真的启示
AlphaGo的成功让人类看到了机器在认知方面的希望,使人们相信机器智能能够从辅助决策的角色转变为自主决策的角色[2,12]。AlphaGo的策略框架充分模拟了人类下棋时的思维特性。首先,模仿人类下棋时先对各种出现情况的全面思考,借鉴另外一个围棋机器人CrazyStone采用的蒙特卡洛树搜索(MCTS)策略,CrazyStone每一步棋的走棋策略生成方式如算法1所示,对各种着手方式予以考虑。

算法1:CrazyStone的蒙特卡洛搜索策略给定初始棋局S0,将己方和对方所有可能落子方法的权重均设为1。迭代以下步骤: 1.随机地下完一局棋:① 己方从所有可能的落子方法中等概率地随机选择一个走法a0。落子之后,棋盘状态变成S1。② 对手也从所有可能的落子方法中等概率地随机选择一个走法,这时棋盘状态变成S2。③ 重复步骤①和②,直到分出胜负r,赢了就r记为1,输了则为0。 2.把刚才那个落子方法(S0,a0)记下来,将己方该落子方法的权重提高一些: 新权重=权重+r ; 3.按照步骤1和步骤2的方法,针对棋盘状态S1,同样更新对手所有可能落子策略的权重。多次迭代后,有前途的落子方案的权重会越来越高,经过10万次迭代后,选择权重最大的那个方案作为最终的走棋策略。
接着对模仿人类打棋谱,向围棋高手学习的特点,通过有监督学习策略网络从围棋对战平台上的大量棋谱学习出走棋策略Pσ,如算法2所示。

算法2:基于有监督学习网络的走子策略 Pσ数据准备:利用围棋网络棋牌室中约16万左右的对弈棋局,每一局棋通常会有200手左右,因此会形成3 000万左右的棋局状态s和对应的落子a,从而形成同等数量的标注数据
进而模仿人类“手下一着子,心想三步棋”的推演模式,借助增强学习策略网络,通过机器自身博弈进化更高级的走子策略Pρ,如算法3所示。同时,受人类对围棋赢面的直觉判断能力启发,综合大量棋局利用价值判断网络得出赢棋概率V(x),从而综合利用经验和棋感以减少搜索空间,更加逼近最优下棋策略,如算法4所示。综合以上模拟人类思维形成的策略算法,最终形成的下棋策略如算法5所示[13-14]。
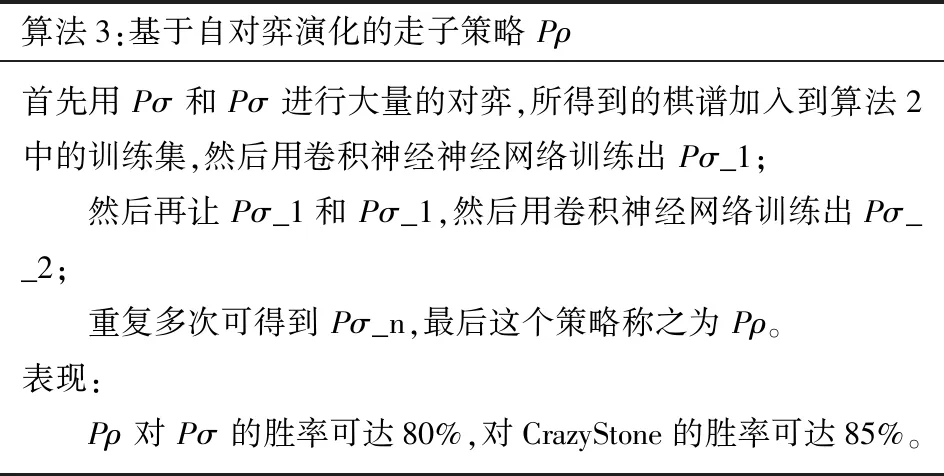
算法3:基于自对弈演化的走子策略 Pρ首先用 Pσ 和 Pσ 进行大量的对弈,所得到的棋谱加入到算法2中的训练集,然后用卷积神经神经网络训练出 Pσ_1;然后再让 Pσ_1和 Pσ_1,然后用卷积神经网络训练出Pσ__2;重复多次可得到 Pσ_n,最后这个策略称之为 Pρ。表现:Pρ 对 Pσ 的胜率可达80%,对CrazyStone的胜率可达85%。

算法4:赢棋概率V(x)的估算方法赢棋概率 V(x) 通过多层神经网络从大量棋局的输赢状况中获取,最后一层的目标函数从分类向量改为了赢棋的概率函数 V(x)。所需要的训练集将远远超过算法3的样本数。为此,先用 Pσ 随机走L步,然后在L+1步的时候,从所有可能的落子方法中随机选择一个走法,然后再用Pρ走完剩余步骤,直到分出胜负。由于每下一步棋都会对应一个棋局,因此可生成足够丰富的样本。

算法5:AlphaGo的下棋策略最终策略是在MCTS框架之上融合局面评估函数V(s)。在每落一颗棋子之前,重复以下步骤: 1.先用 Pσ 下L步之后,改用 Pσ_fast把剩下的棋局走完,赢了就r记为1,输了则为0。 2.同时调用V(x),评估局面的获胜概率。 3.更新权重:新权重=调整的初始权重+0.5∗r+0.5∗V(x);调整的初始权重= Pσ赋予的权重 /(被随机到的次数+1); 4.按照步骤1,2,3,同样更新对手落子策略的权重。多次迭代后,选择权重最大的那个方案作为最终的走棋策略。
从算法上看,AlphaGo虽然利用的是机器学习的一些常规算法,但是通过巧妙运用,让机器具备了自我推演和直观判断的能力。它的故事远没有结束,AlphaGo Zero在不利用人类对弈数据的条件下,仅通过自我博弈就打败了之前所有的AlphaGo版本,这为科学家破解机器智能带来了信心。机器智能进步带来的将是一场“认知的革命”,对军事家而言,重新评估和定位机器认知在未来军事战争中扮演的角色将变得迫切。
在军事作战方面,未来单装的能力将可以充分定义,战场资源的网络化和服务化能力将会充分释放[15],取胜的关键从单装能力的比拼转化为体系对抗。联合作战条件下的体系对抗具有对象层次多、种类多、关系复杂的特点,如何在作战使命指引下快速编排作战任务、部署作战力量、提供条件保障成为胜负的关键。这种组织调度和指挥决策难度已经远非指挥官所能筹谋,决策速度将成为胜负的关键。如果谁能在机器智能上取得突破,必将大幅提升决策速度。构建支撑机器博弈的仿真平台是探索机器智能在作战中潜在应用的先决条件,是探索机器决策在军事运筹中的有效途径,也为适应未来机器决策条件下武器装备的能力设计提供保障。
3 作战推演智能化发展建议
为实现作战推演智能化,一方面需要加强智能推演方法的研究,还需要利用虚拟化与组装化等技术将作战单元、参试装备、部署情况等要素进行精细化建模,联合各个装备研制部门和应用部门,构建从装备仿真、系统仿真到作战仿真不同层级不同粒度的仿真试验体系。数字模型的准确程度会直接影响到推演结果的科学性。仿真推演发展构想如图2所示。

图2 仿真推演发展构想Fig.2 Development vision of simulation and deduction
与作战演训相结合,通过数字仿真与部队演习紧密结合,让智能作战推演贴近实战。联合作战试验指挥协调机构将试验任务下达到各个试验靶场,同时与演习部队建立联系,在推演中,通过演习部队红蓝双方的投影到导调中心,导调中心通过交战模拟,实现虚实、虚虚、实实多种对抗演练方式。借助智能推演算法发现新战法和装备体系的问题,从而为装备研制部门、采办机构以及作战指挥部门提供有力支撑。
4 结束语
AlphaGo对人类思想最大的冲击在于:机器智能在某些领域从经验利用、自主创新和知识学习等方面可以做得比人更好。计算机可以不再是单纯地辅助人决策,而在有些情况下可以替代人决策,提出的不仅仅是建议。在未来高速一体化联合作战行动中,人的决策速度根本无法跟上行动过程,如果谁能率先让计算机替代人去决策,就能真正地料敌于先,谁就在认知域的军事斗争中占据主动,让对手处于步步被动之中。作战仿真推演系统的智能认知,是开展作战态势智能认知的必由之路,是应对未来认知域作战的有效途径。
