高职院校就业推荐系统的算法
2020-04-01刘西祥
刘西祥
摘要:分析了传统的基于用户的协同过滤推荐算法和改进的基于用户的协同过滤推荐算法的算法思想和算法步骤,并对2种推荐算法在高职院校就业推荐系统中的应用结果进行了对比,证实了改进的基于用户的协同过滤推荐算法更适用于高职院校就业推荐系统,提高了相似学生推荐的准确性,推荐的结果也更加符合实际。
关键词:协同过滤推荐算法;就业推荐系统;聚类分析
中图分类号:TP391文献标志码:A文章编号:1008-1739(2020)23-68-4

0引言
就业推荐系统的推荐算法是整个推荐系统中最核心、最关键的部分,目前关于就业推荐系统的算法研究主要有:吴迪的基于经验公式的算法、魏丽芹的基于历史信息的就业推荐算法、陈玉峰的ID3算法以及基于内容和Item-based协同过滤的组合推荐算法等,他们研究的对象一般比较广泛,采用的算法也比较传统,不适用高职院校就业推荐工作。本文采用基于用户的协同过滤推荐算法(学生当作用户,就业单位当作项目)来进行就业推荐。首先根据所有学生(含往届毕业学生和应届毕业学生)对就业单位签约情况、感兴趣程度,发现与应届毕业学生对就业单位兴趣度相似的往届毕业学生最相邻学生,然后根据该相邻的往届毕业学生的签约情况,为该应届毕业学生推荐就业单位,实现就业推荐功能。
1传统的基于用户的协同过滤推荐算法
1.1相似度计算
查找最近邻居是基于用户的协同过滤推荐算法的主要工作,通过应、往届毕业学生对就业单位的评分矩阵,可以计算出他们之间的相似度,相似度越高,他们越接近。把应届毕业学生与往届毕业学生之间的相似度定义为( , ),每一个学生对就业单位的评分可以看作是一个维的向量,应届毕业学生与往届毕业学生之间的相似度就可以用不同的维向量间的相似度来进行度量。通过Cosine相似度(余弦相似度)来计算他们之间的相似度,设应届毕业学生与往届毕业学生在维对象空间上的评分表示为向量,,则( , )的相似度计算方法如公式(1)所示。
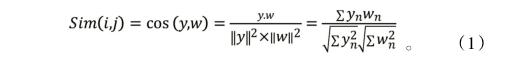
1.2推荐实现
通过计算相似度得到了应届毕业学生的最近邻居集(最相似的往届毕业学生),然后就可以通过最近邻居集进行预测评分,计算方法为:

1.3推荐算法步骤及流程图
(1)推荐算法步骤
①通过应、往届毕业生对企业评分表分别构建应、往届毕业生評分矩阵。
②构建应届毕业生和往届毕业生的相似度矩阵。
③根据相似度矩阵求出个与该应届毕业生相邻的往届毕业生。
④根据统计的相邻的节点个数,预测该应届毕业生对企业的评分值。
⑤根据预测的评分值,按降序排列得出TOP-个企业推荐给应届毕业生。
(2)推荐算法程序流程图。
传统的基于用户的协同过滤推荐算法流程图如图1所示。

2改进的基于用户的协同过滤推荐算法
传统的基于用户的协同过滤推荐算法只考虑了应届毕业学生和往届毕业学生对就业单位的兴趣度,即评分矩阵的评分值只是针对签约单位和感兴趣的就业单位来进行的,而没有考虑应届毕业生和往届毕业生本身的相似度,比如专业、性别、专业考证、是否学生干部、生源地、职业素养、专业课成绩、外语成绩、综合评定、身高及毕业时间等特征属性。实际就业推荐过程中,必须首先考虑学生的基本特征和综合素质,因为基本特征和综合素质相当的学生才能胜任类似的工作,而就业单位在招聘应届毕业生的时候也会参考历年招聘的往届毕业生的基本特征和综合素质,即招聘条件在近期内不会有太大的变化。当然,随着时间的推移,往届毕业学生数据库的数据越来越多,所以在计算应届毕业生和往届毕业生相似度的时候还要考虑毕业时间的因素,加入时间权值。另外,高职院校毕业生就业专业比较对口,可以对就业推荐的对象先分类,再推荐。即进行相似度计算和推荐之前,先对应、往届毕业生按专业进行聚类分析,然后按专业进行就业推荐。
2.1学生聚类分析
如果每次相似度计算都以全校所有毕业学生数据来进行,推荐复杂度和推荐效率势必受到影响,不是理想的方法。所以在进行相似度计算和推荐之前首先对应届毕业生和往届毕业生按专业进行聚类分析,形成新的数据库。
2.2兴趣企业最近邻
对应届毕业生和往届毕业生按专业进行了聚类分析,缩小了推荐范围。而相同专业的应、往届毕业生,由于有些专业人数特别多,故往届毕业生对同一企业感兴趣的情况也会经常出现,所以可以利用兴趣企业最近邻方法来进一步缩小计算范围。把与应届毕业生有共同感兴趣的企业(共同给予评分)的相关往届毕业生的所有评分进行求和,然后根据得分排名从高到低选择个往届毕业生与应届毕业生进行相似度计算。找出与应届毕业生有共同感兴趣的企业(共同给予评分值较高)的相关往届毕业生进行相似度计算,而那些与该应届毕业生无共同感兴趣企业(无共同给予评分或共同给予评分值较低)的往届毕业生没有推荐能力,不参与相似度计算,大大改善了推荐实时性,降低了数据稀疏性。
