支持动态更新的微博话题用户影响力度量方法
2020-04-01赵迪孟剑郭岩俞晓明刘悦程学旗
赵迪,孟剑,郭岩,俞晓明,刘悦,程学旗
(1.中国科学院 计算技术研究所 中国科学院网络数据科学与技术重点实验室,北京 100190;2.中国科学院大学,北京 100049;3.烟台中科网络技术研究所,山东 烟台 264005)
0 引言
近年来微博的活跃用户在持续稳步增长。微博已经成为人们获取信息、分享信息和传递信息的重要媒介。
发现微博话题的高影响力用户有助于给用户提供相关话题的权威用户推荐,可以帮助构建话题目录及该话题高影响力用户来吸引新用户以解决冷启动问题,同时也有助于实施有效的广告投放。与此同时大量的用户生成信息带来了信息过载等问题,给寻找给定话题下的高影响力用户带来了挑战。
本文从用户文本的话题相关度以及传播网络转评关系出发构建用户特征向量,然后对生成的用户向量使用概率聚类的方法得到一批高影响力用户,再对该部分用户进行排序最终得到该话题下的高影响力用户排序列表。本文的主要工作在于构造了少量但有效的用户特征,并且支持特征的实时更新,使得该方法能在实时环境下增量式运行,适用于捕捉微博中频繁的动态变化。
寻找在线服务中高影响力用户是一个被广泛研究的问题。
基于非图结构的方法。基于非图结构的方法没有使用用户网络信息。Cha[1]等人分析了Twitter网络中用户影响力与用户关注数、转发数和评论数的关系,发现用户关注数并不是用户影响力的关键因素。他们以一种不同的方式来定义社交影响力,不再强调用户的作用并确定了决定影响力的关键因素,如普通用户之间的人际关系和社会采纳某个想法的意愿。他们提出转发和提及是更好的指标,这就意味着高影响力用户是那些增加了消息扩散的用户。长孙萌[2]等人总结提出了影响信息传播效率的因素包括知名度、活跃度、人脉力、用户类型、信息表述方式、内容形式、字数、链接等特征。
基于图结构的方法。最流行的图结构算法是PageRank[3]、HITS(基于普通的加权图)[4]和它们的变体。例如Farahat[5]等人提出了一个基于HITS算法的模型,将社交网络和文本信息权威性结合起来对万维网中的链接进行权威性排序。虽然基于图结构的排序方法(比如PageRank和HITS)很流行,但是算法迭代过程中会传递更多的权重给拥有更多相邻节点的节点,因此更倾向于找到名人。并且算法时间复杂度也比较高,不易应用于实时计算场景。
在微博领域,探究话题用户权威性的工作较少,其中有两个最为著名。第一个是由Weng等人提出的TwitterRank[6],该方法首先使用文档主题生成模型(LDA[7-9])计算用户的话题分布,再构建一个加权用户图,其中图中边的权重表示用户间的话题相似度。随后在该有向加权图上运行PageRank算法的变体。为了得到每个话题的权威用户需要对每个话题独立运行该算法。但是该算法是PageRank算法的一个变体,自然也避免不了上面提到的基于图结构方法的通病,该算法容易向名人倾斜并且算法比较耗时,不适用于实时场景。第二个工作是由Pal[10]等人提出的使用基于特征的方法来寻找话题中的高影响力用户。他们通过构造特征来捕获用户的话题信息和话题显著度,然后使用了聚类算法来获得一簇高影响力用户,最后使用了基于高斯排序的算法获得最终的高影响力用户排序列表。该算法通过构造了一些自己提出的用户特征并通过聚类方法缓解了名人效应,对比基于图结构的算法在时间复杂度上有了很大的进步,使得算法能在接近实时场景中应用。近几年也有一些关于话题用户影响力度量的文章,如[2,11-14],其中一些特征构建以及算法研究都能给我们的工作带来一些启发。
寻找高影响力用户的前期相关研究一直由网络分析方式主导,通常与文本分析相结合,但是大多数算法都是非常耗时的。后来Pal[10]等人提出的方法创造性地使用特征聚类的方式,大大降低了时间复杂度,使得算法能够在接近实时场景下运行。本文在该算法的基础上充分利用其优点,使用概率聚类寻找出一簇高影响力用户,然后再通过排序获得最终的影响力用户排名列表,同时为了使该方法能在实时环境下增量式运行来感知微博中的动态变化,本文构造了可实时更新的用户特征。
1 微博中的用户特征
1.1 微博数据特点
为了获得微博中的用户特征,首先要分析一下微博数据特点。在本文中一条微博数据记录可能是一篇原发微博,可能是一篇转发微博,也可能是针对某篇微博的一则评论。数据格式如表1所示。
由于在微博中用户昵称是独一无二的,因此可以使用用户昵称来唯一标识一个用户。数据消息类型有三种,第一种是原发微博,表示该微博是用户原创微博;第二种是转发微博,用户转发他人的微博,转发路径位于消息内容中,每一个“∥@”和“:”之间都代表着参与转发的一个用户昵称,且每一用户都转发自右边紧邻着的用户,转发消息的原始微博可以通过原发ID来进行匹配,这样通过消息内容和原发ID本文就能找到一条从该条微博记录中的转发用户到原发用户之间的一条路径,微博转发方式决定了本文采用用户昵称来唯一标识一个用户,这样才能使得用户和转发中的所有用户昵称对应起来;第三种是评论微博,评论是对其他用户发布的微博或微博下的评论进行评论,本身并没有对此信息进行传播,该用户获得消息的来源是原发用户,因此受原发用户的影响。

表1 微博数据格式
1.2 构建用户节点信息
为得到特定话题下的微博数据,需要考虑以什么标准来抽取这部分数据。本文希望抽取到的微博是话题相关的,为此本文定义了一个特征——话题相关度,来度量一篇微博与该话题的相关度。
要抽取某话题下的微博数据以及计算出微博相似度,首先需要给定初始话题关键字,如对凉山火灾话题,输入关键字“凉山”“火灾”,抽取出含有该关键字的微博。随后对所有微博博文进行分词并统计词频,去停用词后选择排名靠前的n个关键词(本文中采用了前20个关键词)构成关键词列表KW,并为每个关键词计算权重,权重计算公式见式(1)。

(1)
即对关键词KWi,其权重为其词频占所有词的比重,其中frequency(KWi)为关键词KWi的出现的次数,|#words|为所有词的总个数。
此时对任意一篇博文都可以计算其话题相关度,话题相关度定义见式(2):
relevance(content)=

(2)
其中δ(KWi,content)表示关键词KWi是否出现在文本中,如果是则为1,否则为0。即一篇博文其含有的关键词越多,所含关键词权重越大,其话题相关度越高。
通过关键字去指导抽取更多的含有关键字的博文作为本文的数据集,同时抽取出转发和评论数据中涉及的原发微博,防止原发微博没有出现在该批数据中导致不能形成完整的转发路径。到此为止本文的数据集准备完成。
通过解析该批数据本文能够得到该话题下的用户关系图,其中每个节点代表一个用户,节点i中保存了用户i在图中的节点编号Ni、用户昵称Ui、父节点列表Pi和子节点列表Ci以及解析出的属于用户发言的文本列表Ti。如表2所示为用户关系图中节点信息。

表2 用户关系图中节点信息示意图
1.3 构建用户特征
本文定义了以下三个用户特征——用户影响范围、用户话题相关度和用户领导力。接下来本文依次介绍这三个特征:
第一个特征是用户影响范围。一个用户的影响力大小很大程度上体现在他所影响的用户范围,因此可从传播路径入手将路径上影响用户数目作为用户影响力的一个特征。考虑所有可能的传播路径能够对用户的影响力传播范围进行准确的计算,但是这种方法计算复杂度高,耗时很长,不适用于大规模动态网络。Walker等指出用户行为倾向于在网络中传播三步[15],为此可以使用三步内影响范围作为一个用户影响力指标。用户u的影响范围计算方法见式(3):
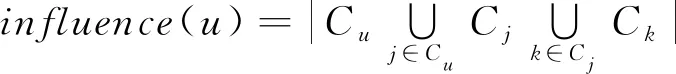
(3)

本文使用的影响范围是通过解析数据集中的转评关系得到的,而不是直接通过微博中自带的转评数目去获得。这样做的原因有以下两点:首先,仅通过转评数目无法获得转评具体用户,无法形成具体转评网络;其次,直接使用微博中自带的转评数目在进行更新时需要对所有的微博进行数据更新,此方法过于耗时,不适用于快速变化的网络环境,而通过解析数据集中的转评关系,本文可以只更新该用户所影响到的向上三步以内的用户节点信息以及用户特征即可。
用户话题相关度。考虑到用户在某个话题下的影响力,希望用户的博文能够尽可能包含更多关于该话题的信息,可以将用户的所有博文作为一个整体来计算用户u的话题相关度。用户u的话题相关度表达见式(4)。
δ(KWi,AllContentu)
(4)
其中AllContetnu代表用户的所有博文内容,δ(KWi,AllContentu)表示AllContentu是否含有关键词KWi,如果是为1,否则为0。即用户u博文包含的话题关键字越多,其话题相关度得分也就越高。
本文希望找到的高影响力用户更倾向于意见领袖,而不是受他人意见的影响。体现在用户关系网络图中就是高影响力用户能拥有较多的子节点以及较少的父节点。据此本文定义了特征——领导力。用户u的领导力计算见式(5)。
lead(u)=ln(|Cu|+1)-ln(|Pu|+1)
(5)
即用户领导力为ln级别下子节点个数与父节点个数的比值,加1是为了防止除0操作的出现。子节点与父节点个数比值越大,用户的领导力越高。
综上所述,得到用户特征如表3所示。

表3 用户特征列表
其中用户影响范围和用户领导力考虑的是基于图结构的用户信息,话题相关度考虑的是基于文本的用户信息。
1.4 特征更新
本文工作还支持处理动态网络,实时追踪话题中的变化。其中考虑的主要变化是随着时间的推移新产生的微博数据对话题的影响。
对于涉及的微博用户来说,其微博文本列表会增加一条记录,若新博文相比于以前文本包含有新的关键字那么其话题相关度会发生改变,否则话题相关度不会改变。话题相关度更新如式(6)。
relevance(u)=relevance(u)+
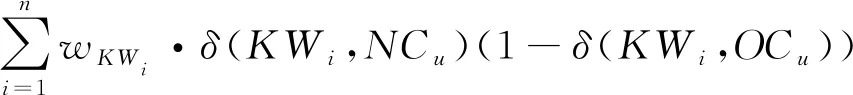
(6)
其中δ(KWi,NCu)表示新文本中是否含有关键字KWi,若是则为1,否则为0。δ(KWi,OCu)表示旧文本中是否含有关键字KWi,若是则为1,否则为0。
若增加了一条原发微博,那么用户关系网络不会发生变化,用户节点信息以及用户影响范围和领导力都不会改变;若增加了一条转发微博,则需按照其转发路径添加用户关系,若在此过程中没有新边产生,则无须更新用户节点信息以及用户影响范围和领导力,否则需要对添加边涉及的节点更新相关信息,同时对新加边子节点三步以内的父节点更新影响范围以及更新新加边涉及的节点的领导力。
对新加边涉及的三步以内的父节点更新影响范围表达见式(7)。
influence(u)=influence(u)+
(1-δ(u,child))·|set(child,u)-
set(influence(u))|
(7)
其中child为新加边中的子节点,u为新加边父节点及其两步以内的祖先节点,δ(u,child)表示节点u的影响范围内是否包含child,若是则为1,否则为0。set(child,u)表示节点u能影响到的节点child影响范围内的节点集合,set(influence(u))是节点u原本能影响到的节点集合,|set(child,u)-set(influence(u))|表示的是新加边后节点u增加的影响节点的个数。
对新加边涉及的节点直接使用原公式更新即可,因为Cu和Pu本文可以直接获得,见式(8)。
lead(u)=ln(|Cu|+1)-ln(|Pu|+1)
(8)
至此,本文已经完成用户特征的构建以及更新,接下来将要介绍如何更新这些用户特征得到高影响力用户排名列表。
2 聚类和排序
使用高斯混合模型[16-17]在用户特征空间上进行聚类,以减少候选目标簇的大小。同时由于聚类对名人效应不敏感,也使后续的排序过程更加鲁棒。高斯混合模型如下:
2.1 高斯混合模型(Gaussian Mixture Model,GMM)
基于高斯混合模型的聚类本质上是概率性的,在给定k个高斯元件的情况下旨在最大化数据的似然估计。考虑在d维空间中的n个数据点x={x1,x2,…,xn},任何给定数据点x的密度可以定义见式(9)。
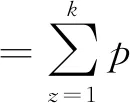
(9)
其中,π是k个高斯元件的先验知识,θ={θz:1≤z≤k}是k个高斯模型的参数,其中θz={μz,∑z},p(x|θz)定义见式(10)。
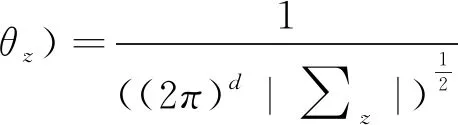
(10)
假设数据点之间是独立同分布的,则对观察样本的似然表达见式(11)。
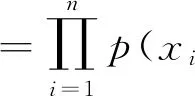
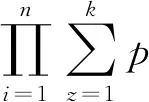
(11)
使用期望最大化(EM)方法来最大化似然估计。EM算法是一个迭代算法,每次迭代包含E步和M步。EM算法将会迭代运行直到似然达到最大可能值。通常GMM比经典的硬聚类算法(如K-means)表现更好,因为它对异常值不太敏感。
根据GMM算法将用户数据分为两簇,分别为每一簇计算平均影响范围,话题相关度以及领导力,选择其中拥有更大的特征的簇作为目标簇。
2.2 排序算法
通过前面聚类算法获得的目标簇通常只含有少量的用户,和初始用户相比数量大大减少了。为了对目标簇进行排序,本文使用了基于列表排序的方法。
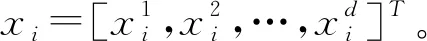
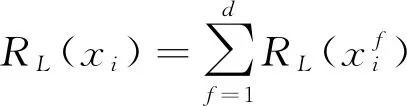
(12)
用户最终排名由用户特征总和排序获得。此外,还可以使用加权版本的用户排名算法。为了将权重因素考虑在内,排序加权和定义见式(13)。
(13)
其中ωf是特征f的权重。通过用户特征总和对用户影响力进行排序,这样就得到最终的高影响力用户排序列表。
ω的确定可以通过对已经标注的话题数据使用线性回归算法学习出来,由于每个话题都能够获得一个ω具体取值,且由于话题的差异性ω取值也有差异,通过取其平均值可以获得最终的ω。
3 实验
3.1 实验数据
目前针对微博数据的用户影响力分析课题还没有特定的标准数据集。本文的微博数据是通过网络爬虫爬取的。由于微博平台对访问次数有一定的限制,且考虑到度量某一时间段内微博话题用户影响力,本文采集了2019年4月3日一天22 730条凉山火灾话题相关微博数据,2019年6月3日-2019年7月1日8 001条“5G商用元年”话题相关微博数据和2019年6月25日-2019年6月28日96 329条“张若昀唐艺昕结婚”话题相关微博数据。
3.2 实验流程
本文算法流程图如图1所示。
由图1可知,算法首先根据已有的微博数据解析生成用户关系网络,然后根据用户网络以及用户节点信息抽取特征,获得用户向量表示。接下来使用高斯混合模型进行聚类。在聚类之前剔除掉了用户特征中用户影响范围为0的用户,原因如下:
(1) 用户影响范围为0说明目前为止没有影响到其他人,可以判定这部分人肯定不是高影响力用户,因此不会剔掉高影响力用户。
(2) 用户影响范围符合幂律分布,如图2所示。
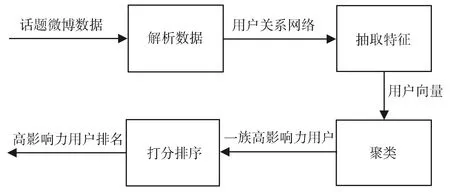
图1 算法流程图Fig.1 Algorithm flowchart
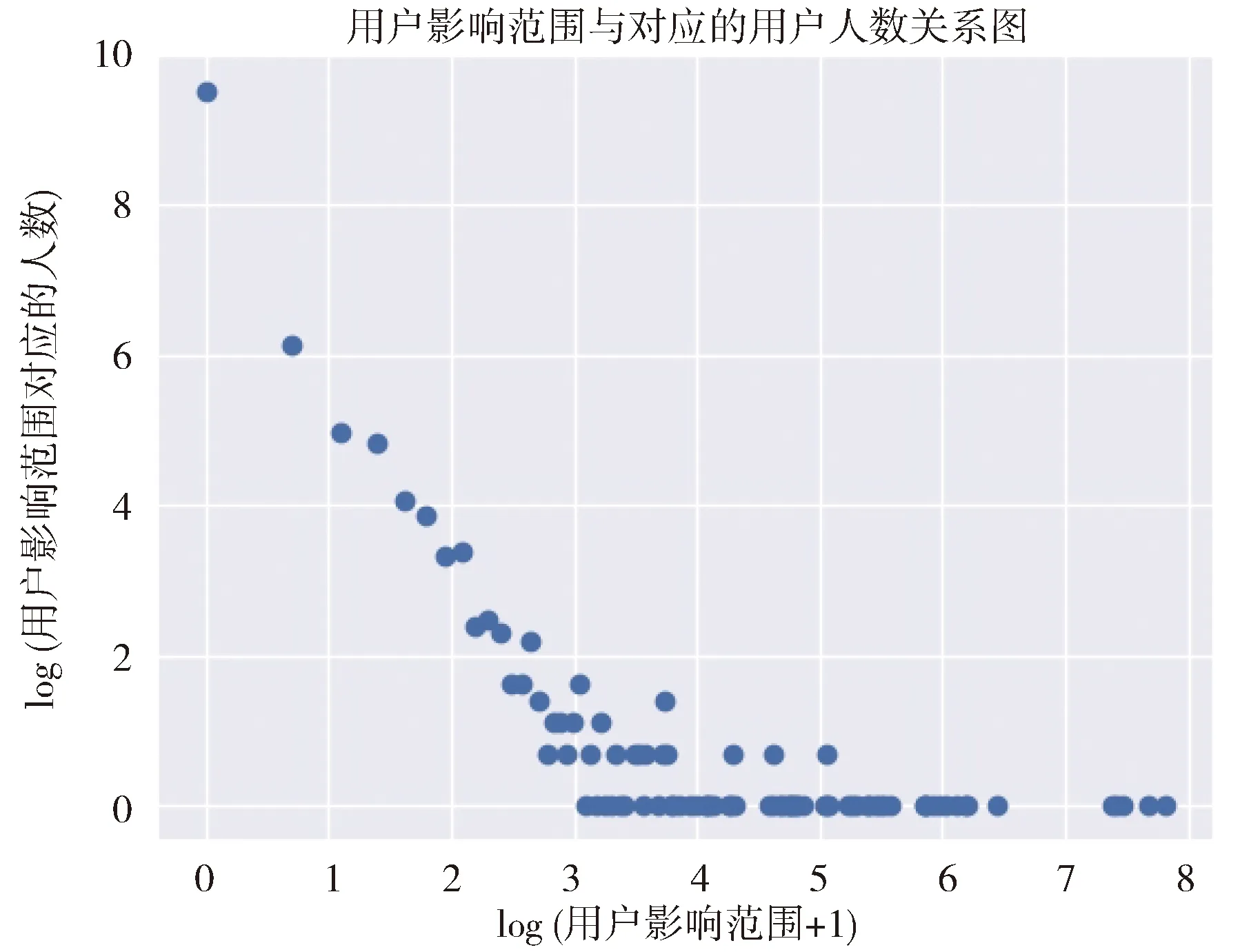
图2 用户影响范围与对应用户人数关系图Fig.2 User influence range and corresponding number of users
即用户中大部分人的影响范围为0,而大量的影响范围为0的用户的存在会使得低影响力用户簇的聚类中心向这批数据偏移,继而有更多的数据被分到高影响力簇中。当去除掉影响范围为用户再进行聚类操作,得到的高影响力用户簇数目得到大幅度降低。如在火灾话题实验中涉及的14 640名用户中有13 591名用户的影响范围为,当本文使用全部数据进行聚类时,聚类后高影响力用户有213名;剔除该批数据后高影响力用户有99名,大大减少了最后待排序的用户数目。
3.3 评价指标
由于对微博话题用户影响力的度量没有统一的标准,采用人工标注的方法为凉山火灾话题生成排名前10的用户。人工标注工作是以各个特征以及综合特征的前十名用户的并集集合为数据集,其中每一名用户信息中包含用户在该话题下的微博以及微博的转赞评数目,让组内20名老师同学来对这些用户进行打分排序,对每一个话题用户去掉其一个最高得分和一个最低得分后计算排序得分平均值,取排序得分的前10名作为最终的参考标准。
采用了排序算法中常用的MAP指标进行算法性能评估,考虑算法得到的前10名用户中也出现在人工标注前10名用户的用户,某话题下的AP(Average Precision)表达见式(14):
AP=averageofP@K
(14)
其中P@K为算法前K个排序中属于人工标注前10名中用户个数占K个用户的百分比。
MAP为在所有的测试话题上计算AP的平均值,见式(15)。
(15)
其中APt表示话题t下的AP值,T为测试话题总个数。MAP的值越高,说明排序效果越好。
3.4 实验结果与分析
本文的模型使用了用户影响范围、用户话题相关度和用户领导力三个特征,使用文中提到的聚类和排序方法得到用户影响力排序列表。
为了证明选择的三个用户特征的有效性,分别设置以下baseline:
B1:使用了用户影响范围和用户话题相关度两个特征,然后再使用文中提到的聚类和排序方法得到用户影响力排序列表;
B2:使用了用户影响范围和用户领导力两个特征,然后再使用文中提到的聚类和排序方法得到用户影响力排序列表;
B3:使用了用户影响话题相关度和用户领导力两个特征,然后再使用文中提到的聚类和排序方法得到用户影响力排序列表。
本文共收集了“凉山火灾”“5G商用元年”“张若昀唐艺昕结婚”三个话题数据,对每种方法使用上述的评价指标进行评价,得到结果如图3所示。
如图3所示,本文算法MAP得分为0.903,B1方法MAP得分为0.735,B2方法MAP得分为0.871,B3方法MAP得分为0.742。通过比较可知本文算法综合考虑了用户影响范围、用户话题相关度、用户领导力三个因素,达到了最好的效果;同时通过控制变量可以看出不同的特征对排序算法有着不同的影响。由图3可得:B1, B3方法MAP得分下降较多,说明用户影响范围和用户领导力特征对寻找高影响力用户有着关键作用;B2方法MAP得分比本论文方法MAP得分低0.32,说明话题相关度对寻找用户影响力作用较小,但是也会有一定的效果改善。通过实验结果不同方法在不同话题上的效果有着较大的差距,但本文提出的方法最为稳定且MAP值最高。实验结果证明本方法可以综合考虑用户影响范围、用户话题相关度、用户领导力三个因素来度量用户影响力。后续将使用本文算法在更多的话题上进行测试,以寻找话题普适且有着更好效果的特征权重。
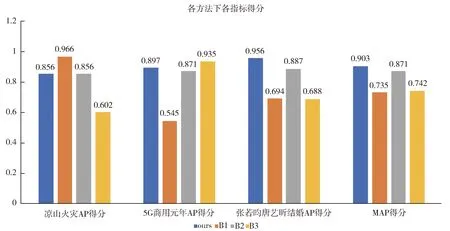
图3 各方法下各指标得分图Fig.3 Score chart of each indicator under each method
4 结论
本文从用户文本的话题相关度以及传播网络转评关系出发构建用户特征向量,然后对生成的用户向量使用概率聚类的方法得到一批高影响力用户,再对该部分用户进行排序最终得到该话题下的高影响力用户排序列表。同时支持特征的实时更新,使得该方法能在实时环境下增量式运行,适用于捕捉微博中频繁的动态变化。实验证明本文的算法是较准确有效的,同时该算法能够支持动态更新用户特征,使得算法可以在实时环境中运行。
