基于社交媒体的药物不良反应检测
2020-04-01朱晓旭林鸿飞曾泽渊
朱晓旭,林鸿飞,曾泽渊
(大连理工大学 计算机科学与技术学院,辽宁 大连 116024)
0 引言
目前,药品不良反应(adverse drug reactions,ADRs)已经成为美国第四高的死亡原因,仅次于心脏病、糖尿病、艾滋病的疾病[1]。研究表明,由药物引起的不良反应同时带来了公共卫生问题,每年带来的死亡人数和住院人数以百万计,并且大约每年有七十五亿美元的相关费用[2-4]。药物不良反应作为生物医学界乃至社会关注的热点问题,已经引起世界的高度重视。但实际上在临床试验中不可能调查所有可以使用药物的条件和环境,因此进行药物不良反应的检测问题至关重要。
随着互联网的快速普及,像Twitter这样的社交媒体已经成为用户及患者之间进行分享知识和交流情感的主要平台。在这个平台上,使用者会讨论他们患病吃药物的相关经历和感受,其中包括处方药的使用、副作用以及治疗效果等,这为我们的检测提供了大量的数据。与传统的医学报告相比,社交媒体上的这些信息会更充分,更具有时效性而且传播更快。到目前为止,从社交媒体中进行药物不良反应的自动检测的相关数据和语料还相对较少,所以生成对抗学习、半监督[5]和无监督的发展和研究显得至关重要。
2015年,Sarker and Gonzalez[6]利用手动提取句子中单个单词的特征,然后通过机器学习算法支持向量机(SVM)进行药物不良反应实验,在实验结果中可以看出传统的机器学习算法在文本分类任务中存在一定局限。在2016年,Huynh等人[7]利用卷积神经网络(CNN)提取局部序列窗口特征,在一定程度上增强对文本的分类结果,但是效果并不明显。在2017年的The Social Media Mining for Health (SMM4H)共享任务评测中,许多参赛队伍都利用当前流行的SVM和CNN来实现药物不良反应的分类。虽然传统的神经卷积网络存在局部感知、权重共享和多卷积核的优点,但是其很容易丢失特征之间的空间位置关系以及不考虑任何单词或局部模式的顺序。Hinton[8]提出的通过放射变换和动态路由协议的胶囊网络则有效地解决了这类问题,使得每个神经元的输出不再仅仅是一个标量值,而是一个向量包含特征的一些属性,每个胶囊的模长能够代表这个特征发生的概率。因此,本文提出一种基于胶囊网络的深度学习算法,尽最大努力减少由于药物不良反应对社会造成的影响,同时也减少领域专家对存在药物不良反应的句子进行标注,从而为社会带来便利。
早期,在进行文本分类时,通常使用词袋模型,词频-逆文件频率(TF-IDF)以及N-gram等特征作为机器学习模型的特征输入,其中常用的机器学习算法有支持向量机(SVM)[9]、逻辑回归模型(LR)[10]、朴素贝叶斯(NB)[11]等。但是,基于统计的机器学习方法有一个较为明显的弊端,通常需要依赖于费时费力的特征工程构建和较弱的适应性和迁移性。
深度神经网络的提出大大提高了在文本分类任务上的性能,例如卷积神经网络(CNN)和长短时记忆网络(LSTM)。2014年Kim提出多通道卷积神经网络进行句子分类[12],该实验是将固定的预训练词向量和微调的词向量分别当作一个通道作为神经网络的输入,再经过池化和正则化得到最终的特征提取向量,该模型在4项任务中都提高了性能。2015年提出使用字符级神经网络(Convnets)进行文本分类,实验结果也优于传统方法[13]。在2016年Joulin等提出一种简单而且快速有效的分类方法fastText,同时将N-gram模型融入特征中来提高效率[14]。虽然深度神经网络比传统的机器学习在实验性能上有所改善,但是存在特征空间关系缺失以及建模效率低的缺点[8],原因是必须在大小随维数增加指数增长的复制检测器和以类似指数方式增加标记训练集的体积之间进行选择,同时不管任何单词或局部模式的顺序,使得深度神经网络方法在文本分类任务中有一定的局限性。
2017年Hinton提出了胶囊网络(Capsule Network),以神经元向量来代替传统深度神经网络中的神经元节点,用动态路由协议代替深度卷积网络中最大池化的方法训练全新的神经网络。与CNN中的最大池化不同,胶囊网络不会丢弃区域内实体之间的准确位置信息,在文本分类中保留了语义信息和各种特征之间的空间关系,同时致力于检测特征和它的各种变种。目前,胶囊网络的有效性已经在手写体MNIST数据集上已经得到了证实[7],训练速度快而且准确率高。

表1 数据存储格式
1 问题及方法概述
本文研究的主要目的为从社交媒体中检测出具有药物不良反应的评论,该研究属于自然语言处理、文本挖掘领域的研究,采用的数据集是The Social Media Mining for Health (SMM4H)共享任务中的数据集,完成药物不良反应的检测任务。因此本文的系统主要包括三部分:数据获取模块、特征提取模块和分类器模块,如图1所示。
1.1 数据获取
本文基于Scrapy程序包搭建爬虫平台,根据SMM4H共享任务中公布的Twitter中用户帖子的ID号进行获取对应的帖子,将爬下来的数据统一存储到文本文件中,存储的格式如表1所示。
1.2 特征工程
该部分手动提取自然语言处理任务中常用的词向量,Part-Of-Speech(POS)位置标记等特征,同时由于社交媒体中用户拼写错误以及表达不规范等问题,增加对charCNN特征的抽取。除此之外,考虑到本任务是对药物不良反应的分类任务,对药物名和情感词等特征主题词的标记会使实验性能有所提高,将这些特征进行融合和拼接得到最终的特征向量。将得到的特征向量输入到长短时记忆(LSTM)网络进行句子表示,然后再经过胶囊网络的动态路由协议迭代得到胶囊。其中每个胶囊代表一个高级特征,每个胶囊都输出一个向量,其大小对应该特征存在的概率值。
1.3 分类器
经胶囊网络的扁平层输出输送到softmax激活函数进行分类,选择发生概率大的作为分类器的输出。即评论中若与药物副作用相关,则标签为1;反之,标签则为0,从而达到了通过提取的生物医学特征以及文本挖掘特征进行药物不良反应检测的效果。
2 模型构建及算法介绍
2.1 模型构建
本文应用的模型由Twitter评论中的词特征表示和Twitter分类器两部分组成。其中第一部分由词向量,字符级向量,POS特征,情感词等多种特征构成,第二部分由双向LSTM神经网络和胶囊网络组成,在一定程度上可以改善当前机器学习和卷积神经网络的不足,具体如图2所示。
2.2 特征表示
该模型中的特征表示由CharCNN、词向量、POS标记、药物名称以及情感词特征联合组成,这为检测药物不良反应事件提供了较好的基础。我们将预处理后的Twitter评论存储在一个.txt文件中,记作D。
D=(T1,T2,T3,…,Tn)
(1)
其中T1,T2…Tn表示文件中的每一个Twitter评论,最终通过分类器判断该句子是不是含有药物不良反应的论评。

图2 模型图Fig.2 Model diagram
2.2.1 分布式文本表示
目前,在自然语言处理领域词向量的表示方法有两种,分别是传统的独热表示方法(one-hot representation)和分布式表示方法(Distributed Representation,Embedding)。其中独热表示词向量方法由高维向量组成,但是存在的问题是忽略了单词之间是有语义关系和相似度的。分布式表示方法则是通过训练文本将语言中的每一个单词映射到固定长度的向量,然后将这些词向量形成一个词向量空间,通过词之间在该空间上的距离判断其相似度,如图3所示。

图3 分布式词向量的表示方法Fig.3 Distributed word vector representation
本文利用Word2Vec[13]工具通过对wiki百科进行词向量的训练,Word2Vec工具具有两种工作模式,分别是Skip-gram模型和连续的词袋模型(CBOW),文中利用CBOW模型进行训练,随机初始化,然后将单词或者字词映射到同一个坐标系下,利用神经网络模型进行特征学习,得到连续的数值向量,因此该向量蕴含了丰富的上下文语义信息,对文本分类任务起着重要作用,其在一定程度上决定分类任务的上限。具体公式如下所示。本次实验的窗口C取为5,词汇表的大小为V,则输入层可表示为{x1,x2,x3,x4,x5},可以先计算出隐藏层的输出见式(2)。

(2)
该输出h是对输入向量作加权平均,其中W是输入层到隐藏层的权重矩阵。接着计算在输出层每个节点的输入,见式(3)。
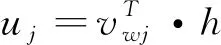
(3)
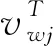
(4)
2.2.2 CharCNN
除了词向量以外,在自然语言处理问题上词向量的选择也同样重要。字符级别的特征对于在形态和语义信息上表示有着较大的优势,尤其面对Twitter上常常出现的缩写和拼写错误等,它起到可以纠正和识别作用。例如,前缀dis-通常在英文中是否定的意思,表示不赞同;后缀-ing通常是现在分词形式,表示正在或者将要发生的动作。在实验中首先构建由符号和字母组成的字母表,对应使用one-hot表示共统计了87个字符,当出现不存在的字符时候,另加全零向量表示。每个单词wi用字符表示为wi=(c1,c2,c3,…,cn),然后通过神经网络的卷积层和最大池化层进行训练优化参数,最终生成可供模型使用的字符级别的特征向量。
2.2.3 POS标记
词性(POS)标记在药物不良反应的分类任务中也起着举足轻重的作用,通常描述一个词在上下文中的作用,同时词的特性和位置一定程度上蕴含了句子的信息。更重要的一点,在此任务中,药物名称和药物不良反应的表述通常有着自己特定的POS标记(如名词)。在该模型中我们应用的是自然语言处理工具包nltk中的Tokenize进行分词和pos_tag来词性标记,然后将标记完的词性作为模型输入的特征之一,与其他特征进行串联拼接。
2.2.4 药物名和情感词
说到药物不良反应,当然离不开药物,所以检测句子中是否含有药物名称是判断药物不良反应的关键因素,只有句子中出现相关的药物名称,才有可能和药物不良反应有关。此外,还需要关注情感词的出现,因为药物不良反应的评论中用户通常会表达出一定的不满或者悲伤甚至绝望的情感。例如,“Metformin has made me very ill for a very long time. It feels good to be alive and not taking that fucking poison”,我们可以很清楚地看到,发该帖子的用户一定被二甲双胍药物折磨得很痛苦。本文提出的模型应用SentiWordNet_3.0.0情感词典和SIDER 4.1医学药典来进行抽取Twitter中每句帖子的药物名和情感词,以此作为训练模型的另一个特征。
2.3 Twitter分类器
药物不良反应的分类器由两部分组成,第一部分是双向长短时记忆网络,第二部分是胶囊网络。
2.3.1 LSTM网络
循环神经网络(RNN)是解决序列数据问题的一种有效的方法,主要分为三层,分别是输入层、隐层以及输出层,其工作核心为每个输入对应隐层节点,而在隐含层之间形成线型序列,但是循环神经网络由于在时间上参数共享,经常会出现梯度消失或者梯度爆炸问题。本文采用的是LSTM模型,它有效地解决了简单循环神经网络的梯度爆炸或者梯度消失问题,然而LSTM自循环的权重是不固定的,它是根据上下文来确定权重值,更好地处理了长距离依赖问题。
LSTM引入了输入门、遗忘门和输出门,由输入门控制当前计算的新状态以多大程度更新到记忆单元中;遗忘门控制前一步记忆单元中的信息有多大程度被遗忘掉;输出门控制当前的输出有多大程度上取决于当前的记忆单元,进而实现了对较长序列的语义长期和短期记忆。具体公式如下:
it=σ(Wixt+Uiht-1+Vict-1)
(5)
ft=σ(Wfxt+Ufht-1+Vfct-1)
(6)
ot=σ(Woxt+Uoht-1+Voct-1)
(7)
ct=ft×ct-1+it×tanh(Wcxt+Ucht-1)
(8)
ht=ot×tanh(ct)
(9)
其中,it代表输入门,ft代表遗忘门,ot代表输出门,ht代表隐含层状态节点,ct代表记忆单元,xt是当前时刻t的输入,σ是logistic激活函数,W、U、V是权重矩阵,其中Vi、Vf、Vo是对角矩阵。
2.3.2 胶囊网络
针对传统深度学习CNN中存在的易丢失特征之间的空间位置关系和建模效率低的问题,Hinton在2017年提出胶囊网络。胶囊网络顾名思义就是由一系列的胶囊组成,每一个胶囊代表一种比较高级别的特征,输出是一个矢量,其幅度代表该高级特征存在的概率。实验中我们选用了10个胶囊,每个胶囊的维度设置为16,并且把路由迭代的次数设置为3。


(10)
每一个胶囊sj的总输入是对所有预测向量的加权求和得到,这一步的关键是通过迭代动态路由找到耦合关系cij。公式见式(11)。
(11)

表2 算法
与CNN中ReLU激活函数不同,胶囊网络中用的是挤压函数Squash,作用是把这个sj向量缩放在0到单位长度1之间。公式见式(12)。

(12)
为了处理胶囊网络中胶囊之间的关系,Hinton引入动态路由机制,详细算法如表2所示。
其中在前向传播时,b的初始值设置为0。cij与b的关系见式(13)。
(13)
2.3.3 分类器层
胶囊网络的扁平层(C)通过连接权重W得到加权,见式(14)。
Y=WC
(14)
然后经过softmax激活函数进行分类,选择较大的概率值作为分类结果。见式(15-16)。
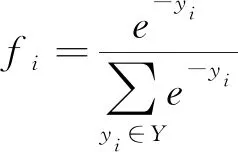
(15)

(16)
3 实验结果与分析
针对所提出来的方法,本文进行了两个实验:实验一是以机器学习中的支持向量机SVM和传统深度学习中的CNN方法以及加了self-attention机制的模型为基线,从而说明本文提出来的基于词特征表示的胶囊网络模型可以有效地进行药物不良反应的检测;实验二是证明用于词表示的每一个特征都是有作用的,是缺一不可的。
3.1 实验结果评价指标
本文的研究内容是药物不良反应的检测任务,是自然语言处理中常见的分类任务,因此对于该系统性能我们可以用准确率(P)、召回率(R)两个参数进行评估,而F1值是对准确率和召回率的综合评价指标,本实验选择用F1值作为参数评估。其计算公式如公式(17-19)所示。

(17)

(18)

(19)
其中TP表示将药物不良反应正确分类的句子,FN表示将含有药物不良反应预测为没有不良反应的句子,FP表示将不含有不良反应的句子预测为药物不良反应的句子,TN表示正确预测不含药物不良反应的句子。
3.2 药物不良反应识别结果
本次实验用的语料集在2017年的SMM4H共享任务评测的数据集,在2016年的共享任务基础上扩展了训练集。但是由于其提供的是Twitter的ID号而且存在用户大量删帖现象,我们一共爬取得到14881条Twitter帖子。在做实验之前,首先对本次实验的数据集进行了详细的信息统计,如表3所示。

表3 数据集统计
为了验证论文中提出的方法的有效性,我们做了多个对比实验,并将实验结果与前人实验结果进行对比分析,表明了本文实验结果的可比性,其实验结果如表4所示。
通过对比实验,可以看出本文提出的基于胶囊网络的药物不良反应分类器相比于机器学习算法、传统深度学习算法均有助于提高分类性能,同时也要比2017年的SMM4H共享任务中最好的分类结果高4.2个百分点(表3中用Model[15]表示)。因为卷积神经网络在对空间信息进行建模过程中,通常需要对特征检测器复制,这就会使模型的建模效率降低;其次,因为卷积神经网络往往对空间位置不敏感,因此对于文本句子中像位置信息,语义信息等难以有效地编码。而胶囊网络中以神经元向量来代替传统深度神经网络中的神经元节点,用动态路由协议代替深度卷积网络中最大池化的方法的特点,使得胶囊网络相比较于其他神经网络架构更容易找到特征之间的空间位置关系,并且可以更高效地建立模型,同时也增强模型的健壮性。

表4 实验结果对比
3.3 实验结果分析
本文的模型中应用的词表示特征由词向量、字符向量、POS标记、药物名和情感词组成,实验一已经证明有效地提高了方法的性能。下面通过实验二来讨论这些特征的作用大小,我们做了这些特征有效性的对比测试,分别将如下特征输入到模型中,经过文中提出的LSTM和胶囊网络得到的实验结果具体如表5所示。
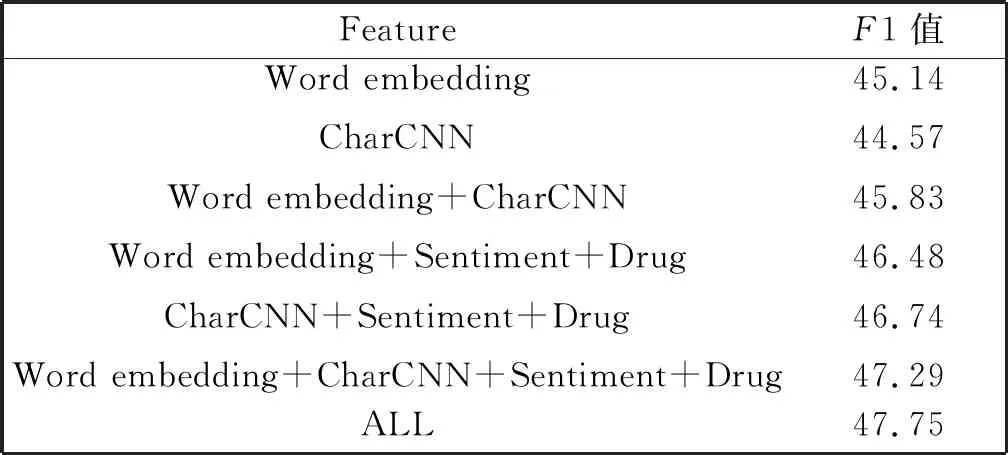
表5 特征有效性对比
可见,一方面,这些特征缺一不可。当词特征仅仅是分布式词向量或者CharCNN时分类效果并不好,然而当与其他特征如POS特征、药物名以及情感词进行特征融合之后,可以看到效果要比只加一两个特征性能要好。另一方面,通过实验也可以看出,仅仅用分布式词向量特征要比单用CharCNN结果好,原因是词向量中包含有更多的语义信息,这是字符级特征向量所不具备的;但是当CharCNN和药物名、情感词进行特征融合时要比词向量和药物名、情感词的特征融合效果好,很重要的一个原因是在药物不良反应检测时,CharCNN可以从Twitter中识别单词缩写和错误拼写,加上药物不良反应句子中负面的情感词可以达到很好的效果。而词向量中本来就带有丰富的情感,因此加上情感词特征性能并没有大的提高。总之,实验结果显示,将这些特征进行串联拼接之后可以使模型的性能更好,对药物不良反应的检测更准确。
模型中先将提取到的特征经过长短时记忆神经网络,然后通过胶囊网络和softmax激活函数对药物不良反应句子进行分类。创新点在于针对传统机器学习模型和卷积神经网络模型存在的不足,提出胶囊网络来提高实验的性能。通过设置对比实验也证明本文提出丰富的词表示的动态路由机制的胶囊网络有助于表示多个特征之间的空间关系,因此可以有效地提高对药物不良反应的分类。
4 结论
为了从传播快,时效性高的社交媒体上检测出含有药物不良反应的句子,本文提出基于长短时记忆网络和胶囊网络的药物不良反应检测模型,通过对含有丰富语义信息的词向量与字符级CharCNN、词性特征、药物名以及情感词特征进行特征融合,使得模型可以进行更加准确地学习。本文研究表明,以社交媒体作为载体,结合文本分类任务的特征表示和胶囊网络的研究,可以做到有效的药物不良反应检测,这对改善人类的健康水平有着至关重大的意义。实验结果虽然客观,但是基于社交媒体做药物不良反应的检测F1值普遍比较低,这与用户在帖子中表达的非正式性以及数据集的正负例不平衡性有很大关系,下一步的研究重点在于如何将用户表达标准化以及解决数据集正负例平衡问题,如何利用相关模型提高系统学习特征的能力等。
