文本情绪原因检测研究综述
2020-04-01陈珊珊姚攀
陈珊珊,姚攀
(四川大学计算机学院,成都610065)
0 引言
当今是一个信息丰富,网络发达的社会,互联网为人们的工作生活带来极大便利,人们利用社交媒体了解时事、分享经历、表达情绪,网络空间中出现了大量包含情绪的文本数据,例如产品评论或者对热点事件的讨论等。从海量文本中识别和理解情绪成为自然语言处理领域中重要的研究方向之一。早期,对情绪分析的研究大多数集中在情绪分类、情绪识别等任务[1]。但是,在实际生活中,企业组织或服务人员有时更关心文本中表达某种情绪背后的原因。他们可以根据消费者产生情感的原因,有效地提高产品的性能或服务质量。例如,某顾客发布一条评论,“旅店的无线网络极其差劲,严重影响我工作,太让人生气了,下次不会再来了。”酒店经理更想知道顾客为什么不喜欢他们的酒店,而不是简单的情绪分类。在确定情绪产生的原因后,他们可以改善无线网络环境,吸引更多的客人,这显然比单纯了解顾客是否满意更加具有实践上的指导意义,所以对文本情绪原因检测的研究具有重大的商业应用价值。相比与一般情绪分类任务,情绪原因检测需要更深层次的理解情绪与情绪原因间的关系,具有更高的难度。
本文结构分为三个部分,第一节介绍文本情绪原因检测的任务描述和主要方法;第二节介绍相关语料资源的基本情况;第三节总结和展望。
1 文本情绪原因检测研究现状
1.1 任务描述
情绪原因检测任务是指识别文本中触发某一情绪的原因[1],具体做法是将文本分割为多个子句,在已知情绪表达的情况下,识别文本中的子句是否包含情绪原因。如例句1,已知“伤心”的情绪,识别目标是原因所在子句“却被告知丈夫殉职的噩耗”。

1.2 规则方法
文献[1]首次提出情绪原因检测任务,基于Sinica语料库构建了一个较小的情绪原因数据集[1],通过观察、分析数据集,总结出与文本情绪原因有关的常见使役动词、原因连词、感知动词、连词、其他线索词等,归纳了七组语言学线索,并构建相应的规则系统。随着社交媒体的发展,情绪原因检测在微博文本中有了较大的需求。由于微博文本语言表达口语化和生活化,多为短句,并含有较多表情符号,与普通新闻文本存在差异,解决新闻文本的规则并不适用于微博本文,文献[2]在文献[1]提出的规则基础上,针对微博文本的特点重新定义了适用于微博文本的规则。文献[3]提出从情绪原因到情绪表达可以看作一个认知的过程],研究产生情绪的常识知识有助于情绪原因检测,文中搜集了情绪原因词对,构建情绪——情绪原因常识知识库,并利用其他情绪表达知识库对其进行扩展,用基于规则的方法实现情绪原因检测。实验显示常识库可以作为基于规则模型的情绪原因检测方法的有效补充,提高情绪原因检测的效果。
1.3 机器学习方法
基于规则的方法不能覆盖所有语言规则,存在规则繁多、覆盖率低的缺点;针对不同风格的文本,需要重新构建相应规则。与传统的基于规则方法相比,基于统计机器学习的方法不需要更新大量的规则,所以研究人员选择机器学习的方法来解决文本情绪原因检测问题。
基于机器学习的方法又可以分为分类方法和序列标注方法。采用分类的方法,文献[4]将情绪原因检测任务看作多标签分类问题,并泛化文献[1]提出的规则,设计了基于语言学规则的特征和情绪原因检测的通用特征。文献[5]将情绪原因检测看作二分类问题,将人工构建的规则,候选原因子句与情绪表达的位置关系,情绪原因的词性标注作为特征编码候选原因子句,用SVM对子句进行分类。文献[6]利用卷积核的学习方法训练多核分类器,用于识别情绪原因事件,文中定义了一个7元组描述情绪原因事件,使用语法结构来获取情绪原因的结构特征和词汇特征。
分类模型将文本中每个子句单独对待,无法捕捉子句标签之间的关系。文献[7]将情绪原因检测任务看作序列标注问题,文中分析了词性特征,情绪表达与情绪原因之间的相对距离特征,语言学规则特征,采用条件随机场算法(CRF)对特征序列进行学习和标注。序列标注模型可以克服分类模型无法利用文本子句间关系的缺点,同时模型融入词法、相对距离和语法规则等特征,提高模型识别效果。
1.4 神经网络方法
情绪表达与情绪原因的关系通常是语义相关的,基于规则和机器学习的方法都只是在对于情绪原因子句上的特征进行分析和提取,少有考虑到情绪表达子句与原因子句间的语义关系。由于神经网络模型自动学习特征的优势,越来越多的研究人员使用神经网络模型来解决情绪原因检测问题。
(1)考虑情绪表达子句与原因子句间的关系
文献[8]从问答系统的角度来解决文本情绪原因检测问题,研究结合注意力机制的记忆网络[8],建模文本中情绪表达与情绪原因之间的相关关系。将文本分成多个子句,模型接受候选情绪原因子句和情绪表达关键词两个输入,通过注意力机制建模两个输入的关系,以此判断候选情绪原因子句是否为情绪原因子句。该方法为后续的研究者提供新的研究思路与方向。文献[9]提出将情绪表达关键词作为查询输入,这一做法忽略了情绪表达关键词的上下文所包含的信息。例如例句2,其中情绪表达关键词为“沮丧”,情绪原因子句为子句④“马刺队的邓肯也宣布退役”:
例句2:
①在2016年,
②湖人队的科比宣布退役,
③同一年,
④马刺队的邓肯也宣布退役。
⑤ 马刺队的队员和邓肯的粉丝都感到十分沮丧。
若将“沮丧”作为查询输入,文本中每个子句作为被查询内容,那么子句②与子句④都是将是满足查询输入的答案。然而,显然子句②虽然满足“沮丧”,但它却并不是正确的查询结果。针对该问题,文献[9]提出应当将情绪表达关键词所在子句中的其他词的语义也纳入考虑,即将整个情绪表达子句作为查询输入。在此例子中查询输入就由“沮丧”变为了整个子句⑤。考虑了情绪表达关键词的上下文后,对情绪原因检测的识别效果有了进一步提升。
(2)考虑文档中各子句间的关系
文献[10]提出了使用整个文本和情绪表达作为输入,考虑文本中各个候选原因子句间的语义影响,使用注意力机制在词语级、短语级层次上对候选原因子句与情绪表达间的对应关系建模,再在句子级融合子句间的上下文信息,通过这种多层级网络模型来确定情绪原因子句。情绪原因检测任务除了考虑情绪表达与情绪原因的关系之外,子句与情绪表达的相对位置关系和子句间的标签关系[11]也是有助于情绪原因检测的重要特征。在只考虑情绪表达子句与原因子句间的关系的建模方式中,将文本分成多个子句分别与情绪表达所在子句配对,这种建模方式可能导致一个文档中没有子句被预测为原因子句,或者太多子句被预测为原因子句。为了解决该问题,文献[11]将情绪原因检测任务转化为重新排序后的子句预测问题,将原始文本中的子句按照距离情绪表达子句的相对距离,按其绝对值大小升序排序,预测每个子句是否为情绪原因子句,将子句的预测结果作为特征,用于预测下一个子句是否为情绪原因子句。文献[12]提出一种RNN-Trans⁃former层级网络,对整篇文档采用Transformer编码子句的方法进行情绪原因检测,使用Transformer的编码方式能充分利用整篇文档的信息,更有效的编码子句间的相互作用关系。实验结果证明了使用Transformer对多个子句的编码效果使用RNN编码子句间关系的效果更好[12]。
2 语料资源
目前,仍然缺少情绪原因检测的中文微博数据集。对于中文微博的情绪原因检测,大都是研究人员各自构建数据集。文献[6]针对表述规范的文本,公开了基于新闻文本构建的情绪原因检测数据集,弥补了之前没有公开数据集的空白,进而推进了情绪原因检测任务的发展。目前,该数据集已经成为情绪原因检测任务的基准数据集。该数据集包含了喜(Happi⁃ness)、悲(Sadness)、惧(Fear)、怒(Anger)、恶(Disgust)、惊(Surprise)六种情绪[6];包含2105篇文档,11799个子句,其中包括2167个情绪原因子句,情绪原因数量的分布情况如表1;原因子句与情绪表达子句的距离分布如表2,“0”表示原因子句与情绪表达在同一子句,“-”表示原因子句在情绪表达子句左边,“+”表示原因子句在情绪表达子句右边,经过分析可发现大部分情绪原因子句在情绪表达子句的前一个子句或者同一子句。
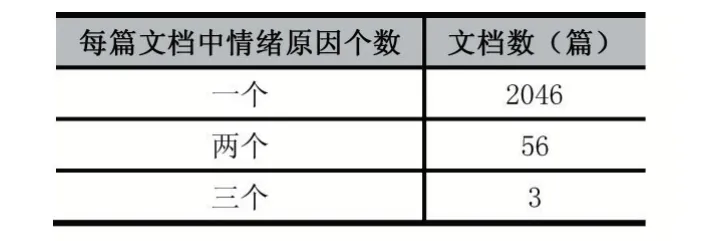
表1 情绪原因数量的分布情况
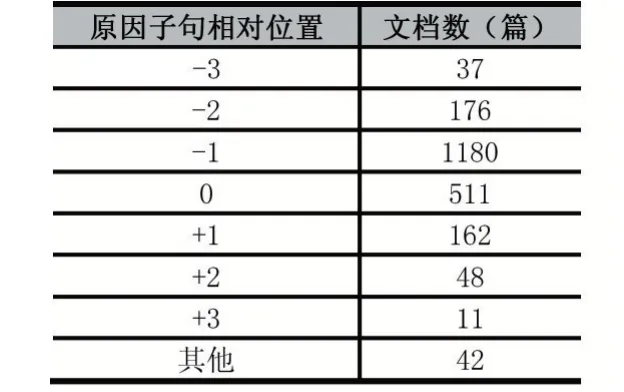
表2原因子句与情绪表达子句的距离分布情况
3 结语
本文对情绪原因检测的研究进展进行了介绍,简单介绍了文本情绪原因检测任务和相关数据集的基本情况,重点介绍了解决情绪原因检测问题的三大主要方法,分析了这几类方法的改进思想。情绪原因检测任务将有助于情绪的识别,问答系统的发展,增强人机交互体验,具有较高的研究价值和应用价值。情绪原因检测是情绪分析领域一个新的研究方向,在实验效果上仍然有很大的提升空间。目前仍存在缺少公开中文微博数据集以及已公开数据量较少的问题,这给该任务提出新的挑战,需要进一步探索新的解决方法。
