基于TensorFlow及LSTM模型的室内行为识别算法的研究与实现
2020-04-01董海山徐晓姗郑春红
董海山,徐晓姗,郑春红
(青岛职业技术学院信息学院,青岛266555)
0 引言
近来像智能手机等移动设备加入了越来越多各式各样功能强大的传感器,这些传感器包括:GPS传感器、视觉传感器(如摄像头)、听觉传感器(如耳机)、光传感器、温度传感器、方向传感器(如指南针)和加速度传感器(如加速计)。这些移动设备虽体积小,但计算能力强,可以发送和接受大量数据,因此被大量的在我们日常生活中使用,也为数据挖掘的研究和应用开辟了新的领域。本文的目的就是通过利用智能手机所产生的传感器数据来研究和实现可以识别人体室内行为的算法。
大部分Android智能手机及其他智能设备都配有加速度传感器、重力传感器和方向传感器,这些传感器不光具备测量立体空间的能力,还可以检测方向(通过手机重力传感器)。如果建立了通过传感器数据识别人体室内行为的模型,我们就可以创建一些应用,例如自动生成用户每天、每周甚至每月的活动报告,并自动发给用户,报告中可以根据检测的运动量给用户一些运动乃至营养建议。同时行为信息还可以被用来匹配用户行为,例如检测到用户在运动或睡觉,可以把电话自动转到语音信箱,还可以有其他各种各样的应用场景。通过手机传感器可以测量出一段随时间变化的三向加速度数据,而活动也可以看成一个由时间和空间组合而成的一个序列,因此通过对传感器数据的处理、判断、分类,我们就可以有效的对室内活动进行识别。
本文所提出的构建基于LSTM模型的算法,对传感器中获取的数据进行表征学习,并对数据进行处理、分类,最终实现对人体活动的有效识别。实验表明,本文所使用的算法在识别人体活动时具有较高的准确率,表明实验方法的实际可行性。
1 深度学习简介
深度学习是机器学习中一种基于对数据进行表征学习的方法[1]。它通过多层结构让机器自动在数据里找到特征或者规律,从而对数据进行预测和分类,减少了人为设计特征造成的不完备性。
神经网络[2]由大量的神经元相互连接而成。每个神经元在接受线性组合的输入后,最开始只是简单的线性加权,后来给每个神经元加上了非线性的激活函数,并进行非线性变换后输出,增强了神经元的表征能力。每两个神经元之间的连接代表加权值,称之为权重(weight)。不同的权重和激活函数,会导致神经网络不同的输出。
RNN(Recurrent Neuron Network)是一种特殊的神经网络结构[3],它是根据“人的认知是基于过往的经验和记忆”这一观点提出的。它与CNN(Convolutional Neural Network)不同的是:它不仅考虑前一时刻的输入,而且赋予了网络对前面的内容的一种“记忆”功能.。RNN所以称为循环神经网路,即一个序列当前的输出与前面的输出也有关,具体的表现形式为网络会对前面的信息进行记忆并应用于当前输出的计算中,即隐藏层之间的节点不再无连接而是有连接的,并且隐藏层的输入不仅包括输入层的输出还包括上一时刻隐藏层的输出。
2 LSTM神经网络
2.1 基本思想
LSTM(Long Short Term Memory networks)神经网络是一种特殊的RNN网络[4],该网络设计出来是为了解决长依赖问题。本文使用谷歌开源TensorFlow机器学习框架构建LSTM模型,模型主要包括了输入层、LSTM层、输出层、loss、optimizer等部分的构建。LSTM模型主要用于解决RNN模型中梯度消亡现象,如图1所示,LSTM接受上一时刻的输出结果,当前时刻的系统状态和当前系统输入,通过输入门、遗忘门和输出门更新系统状态并将最终的结果进行输出。如下公式为核心算法,输入门为It,遗忘门为ft,输出门为ot,遗忘门来决定上一时刻的状态信息中某部分数据需要被遗忘,输入门来决定当前输入中某部分数据需要保留在状态中,输出门来决定由当前时刻的系统输入、前一时刻的输入和状态信息组合而成的信息中那些部分可以作为最终的输出[5]。

图1 LSTM模型

2.2 算法设计
活动识别的算法流程框架如图2所示。首先对从手机传感器上采集到的数据进行预处理,通过数据标准化使得训练时能更快地收敛,并且不被异常值所影响;然后通过LSTM模型方法对人体典型活动进行学习,以实现不同活动的特征提取;最后进行活动的分类。

图2 算法流程
3 TensorFlow实现
3.1 数据预处理
生活中的活动各种各样,为了更好地、更精确地识别人体行为特征,我们对人体典型行为分六大类:上楼(Upstairs)、下楼(Downstairs)、坐(Sitting)、站(Stand⁃ing)、慢跑(Jogging)、走路(Walking)。为了得到更有利于特征提取的形式,在对数据进行特征提取和识别之前,先要对原始数据进行预处理:本文利用标准分数进行数据标准化,同时对数据序列进行固定切片,每个序列包含200个训练例子,如此可以保证这些特征都具有相近的尺度,帮助梯度下降算法更快地收敛,代码如下:
N_TIME_STEPS=200
N_FEATURES=3
step=20
segments=[]
labels=[]
for Iin range(0,len(df)-N_TIME_STEPS,step):
xs=df[‘x-axis’].values[i:I+N_TIME_STEPS]
ys=df[‘y-axis’].values[i:I+N_TIME_STEPS]
zs=df[‘z-axis’].values[i:I+N_TIME_STEPS]
label=stats.mode(df[‘activity’][i:I+N_TIME_STEPS])[0][0]
segments.append([xs,ys,zs])
labels.append(label)
3.2 模型建立
对标准化的数据进行两次卷积操作,卷积使用Re⁃LU激活函数,并且在后面带有最大池化层。同时使用tf.reshape函数对第二个卷积层的输出进行变形,将其转成一维向量,然后连接两个全连层,隐含节点为100,并使用tanh激活函数。
为了减轻过拟合,增加一个Dropout层,通过placeholder传入数值类控制。训练时会随机丢弃一分类相似数据来减轻过拟合,预测试则保留全部数据追求更高的预测性能。全连接层的输出连接一个Soft⁃max层,得到最后的概率输出。
N_CLASSES=6
N_HIDDEN_UNITS=64
def create_LSTM_model(inputs):
W={
‘hidden’:tf.Variable(tf.random_normal([N_FEATURES,N_HIDDEN_UNITS])),
‘output’: tf.Variable(tf.random_normal([N_HID⁃DEN_UNITS,N_CLASSES]))
}
biases={
‘hidden’: tf.Variable (tf.random_normal([N_HID⁃DEN_UNITS],mean=1.0)),
‘output’:tf.Variable(tf.random_normal([N_CLASSES]))
}
X=tf.transpose(inputs,[1,0,2])
X=tf.reshape(X,[-1,N_FEATURES])
hidden=tf.nn.relu(tf.matmul(X,W[‘hidden’])+biases[‘hidden’])
hidden=tf.split(hidden,N_TIME_STEPS,0)
lstm_layers = [tf.contrib.rnn.BasicLSTMCell(N_HID⁃DEN_UNITS,forget_bias=1.0)for_in range(2)]
lstm_layers=tf.contrib.rnn.MultiRNNCell(lstm_layers)
outputs,_=tf.contrib.rnn.static_rnn(lstm_layers,hidden,dtype=tf.float32)
lstm_last_output=outputs[-1]
return tf.matmul(lstm_last_output,W[‘output’])+biases[‘output’]
下面开始训练过程。首先依然是初始化所有参数。共进行50次训练迭代,参与训练的样本数量总共54901。其中每次训练都分批次处理,同时我们会对准确率进行一次评测,用以实时监测模型的性能,通过图3可以看到模型的准确率大概在97%,损失值大约0.2。
saver=tf.train.Saver()
history=dict(train_loss=[],
train_acc=[],
test_loss=[],
test_acc=[])
sess=tf.InteractiveSession()
sess.run(tf.global_variables_initializer())
train_count=len(X_train)
for iin range(1,N_EPOCHS+1):
for start,end in zip(range(0,train_count,BATCH_SIZE),
range(BATCH_SIZE,train_count+1,BATCH_SIZE)):
sess.run(optimizer,feed_dict={X:X_train[start:end],
Y:y_train[start:end]})
_,acc_train,loss_train=sess.run([pred_softmax,accuracy,loss],feed_dict={
X:X_train,Y:y_train})
_,acc_test,loss_test=sess.run([pred_softmax,accuracy,loss],feed_dict={
X:X_test,Y:y_test})
history['train_loss'].append(loss_train)
history['train_acc'].append(acc_train)
history['test_loss'].append(loss_test)
history['test_acc'].append(acc_test)
ifi!=1andi%10!=0:
continue
print(f'epoch:{i}testaccuracy:{acc_test}loss:{loss_test}')
predictions,acc_final,loss_final=sess.run([pred_softmax,ac⁃
curacy,loss],feed_dict={X:X_test,Y:y_test})
print()
print(f'finalresults:accuracy:{acc_final}loss:{loss_final}')

图3 训练过程
3.3 效果评估
深度学习结果的准确性判定比较复杂,一般基于个人经验的,没有严格的数学和理论来支持和计算准确度,绝大多数研究使用交叉验证和统计测试来比较分类器对特定数据集的性能,本文选取20%样本数据作为测试集。针对具有n个类别的分类问题,针对特定方法的分类结果可以被保存在混淆矩阵Mn×n中。混淆矩阵可以使得元素Mij的值等于实际分类为类j的来自类别i的实例的数量。
4 程序运行界面效果
该程序运行的效果如图5所示,主界面显示六大类活动的名称及概率值,最高概率的即为模型所预测的活动,非常直观。
5 结语
本文首先介绍了深度学习和RNN神经网络的基本概念,其次给出了LSTM模型的思想和算法设计,然后介绍使用TensorFlow标准化数据、创建训练LSTM模型并评估效果,最后实现了一个简单应用:根据手机持有人的活动预测其行为。与传统的识别方法相比,本方法无需人为地优选特征即可有效识别相似动作,如走、上楼、下楼、慢跑、站和坐,能明显提高人体行为的识别率,可在实际应用中实时使用,是一种理想的分类模型。
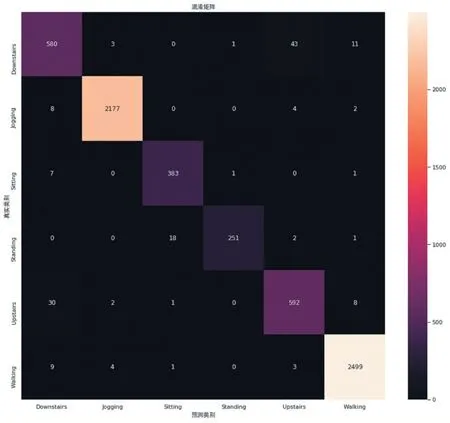
图4 混淆矩阵

图5应用界面
