一种针对大规模CGRA的编译器后端设计
2020-04-01叶鹏飞
叶鹏飞
(上海交通大学电子信息与电气工程学院,上海200240)
0 引言
在面向计算密集型应用时,粗粒度可重构架构(CGRA)具有高加速比、高能效比和高灵活性,受到了学术界和工业界的广泛认可,并成为了近年来国内外的研究热点[1-8]。将一个应用程序的循环体数据流图(DFG)映射到CGRA的处理单元阵列(PEA)上,通过多个处理单元(PE)并行计算,即可实现更高的应用加速性能。随着半导体工艺的飞速的发展,CGRA上的PE数量已经越来越多,相比GReP[1]可重构处理器上4个4×4大小的PEA,大规模CGRA中一个PEA就可以包含64个PE。同时,CGRA面向的应用也越来越复杂,应用循环体内的DFG变得越来越大,对CGRA编译器的后端设计带来了更大的挑战[2-3]。编译器后端负责把前端生成的程序中间表示(IR)转化为最终目标CGRA指令集系统的配置包,并尽可能保证应用在CGRA上的高效运行。针对大规模CGRA的诸多架构新特性,需要设计一套新的编译器后端流程。
1 大规模粗粒度可重构架构
通过RTL实现和测试,实验证明8×8是目前28nm半导体工艺下较合适的PEA规模。同时,为了进一步提高CGRA的算力,PEA的数量也将进一步扩大。本文所针对的大规模CGRA共包含16个8×8大小的PEA,共1024个PEA,具体架构如图1所示。其中每4个PEA和一个协处理器组织构成1个RPU,协处理器负责多个PEA的启动顺序、PEA指令和数据的预取等并行计算以外的准备工作,全局寄存器由同一PEA共享且支持同时读取,主控核负责四个协处理器程序的搬运和RPU的启动顺序。通过RTL实现验证了该CGRA可以工作在500MHz的频率,由此可以在8比特整型数下实现至少2TOPS的算力。当CGRA上PEA的数量和规模增加后,算力提升的同时出现了一些大规模CGRA特有的架构设计特点,接下来详细介绍。
1.1 异构访存结构
当CGRA的规模较小时,所有的PE都是同构的,同时支持数据访存和逻辑运算[1],但在大规模CGRA中,为同一个PEA的64个PE都设计数据访存功能不仅给PE带来更大的面积开销,也给片上共享数据存储器带来更大的带宽压力,由此选择部分PE设计访存功能是较为合理的设计方案。同时综合考虑芯片最终布局布线时的拓扑结构,该大规模CGRA选择给8×8 PEA的外围一圈PE增加了访存功能,共28个访存型处理单元(LSU),即图2中的深色PE。而逻辑运算单元由于不需要和片上共享数据存储器通信,带宽限制较小,因此所有PE都被赋予了逻辑运算能力(ALU)。LSU和ALU功能不同,对应有两套不同的64位精简指令集系统,故在设计编译器后端的时候不仅需要考虑到异构访存单元的映射限制,还需要在生成配置包时为每个PE根据其操作类型生成对应的指令。
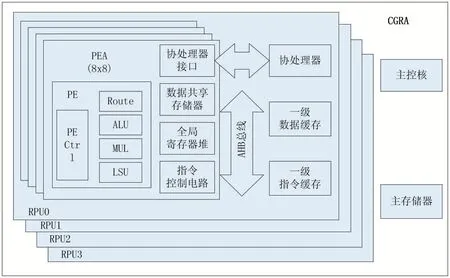
图1 大规模CGRA架构

图2 异构访存结构和PE互连方案
1.2 有限的PE互连资源
为了提供更灵活的配置方式保证应用的通用性,CGRA上的PE可以通过一个多路选择电路访问相邻PE在上一个周期的计算结果,因此PEA上存在非常多PE间的互连线。在传统CGRA中由于PEA的规模比较小,因此PE间的互连可以实现得非常丰富,例如GReP可重构处理器中,每个PE可以访问相邻的11个PE[4]。但是当PE数量变多后,这样丰富的互连资源设计必然会使PEA整体工作频率下降,因此大规模CGRA只能实现相对有限的PE互连资源,再加上异构访存结构的存在,不同PE的互连能力的也应有所区别。最终,本文所针对的大规模CGRA的PE互连方案如图2所示,主要是对经典2D-Mesh互连结构的改进,其PE来源主要有以下三种:
(1)上、下、左、右四个PE
(2)上端、下端、左端、右端四个PE
(3)同行或同列距离为1、2、3、7的PE(只对LSU有效)
上述三种PE来源互相也会有所重叠,互连能力最强的PE在四个顶角(PE0,PE7,PE56,PE63),可以访问包括自身的相邻共9个PE,互连能力最弱的PE在内部区域的四个顶角(PE9,PE14,PE49,PE54),可以访问包括自身的相邻共5个PE,64个PE的平均互连能力为7,相比GReP可重构处理器下降了36%。
2 编译器设计
2.1 编译器整体流程
本文实现的编译器基于LLVM开源编译器框架,该框架对编译过程中的不同步骤和优化拆分为独立的编译路径,编译路径之间可以自由组合,也可自定义新的编译路径,由此提高了编译器开发的灵活性。本文的编译器前端基于一种面向CGRA的ANSIC扩展语言——GR-C,后端基于自定义编译路径的opt和llc工具,通过解析前端生成的中间表示,最终生成不同目标指令集系统的十六进制可执行文件和配置包文件,具体流程如图3所示。其中波浪框表示文本文件,矩形框表示编译器工具,rocket和pico分别表示大规模CGRA的主控核和协处理器,由于这两个处理器都基于RISC-V指令集系统,目前LLVM对RISC-V指令集系统的支持还不完善,因此汇编器和链接器用到了gcc中的现成工具as和ld。
编译器前端基于LLVM的clang工具,接受以GRC语言描述的程序代码作为输入,经过预处理、词法分析、语法分析、语义分析等步骤,生成LLVM编译器框架的中间表示,后端接受中间表示以后需要先分离出循环体程序代码;再根据LLVM提供的类层次结构解析出循环信息,包括循环深度、迭代空间、索引变量等,以及循环体内的操作运算集合,以ConfigIR的形式保存下来[5];根据ConfigIR中保存的信息,建立出循环体内程序的DFG,经过一系列的预处理、调度和映射生成DFG在PEA上执行的调度映射方案;再通过目标CGRA指令集系统的定制代码生成器处理,最后生成目标CGRA的配置包。
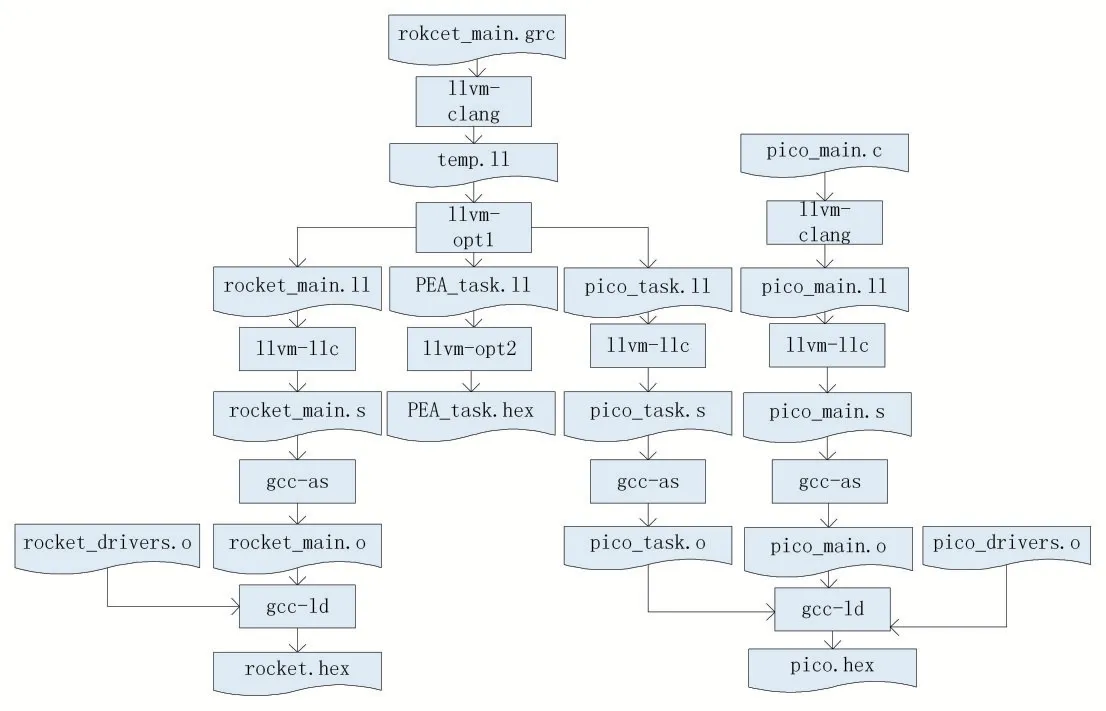
图3 编译器完整流程
2.2 后端流程设计
对于CGRA这种并行计算架构,编译器后端流程的优劣直接决定了应用最终的性能,因此后端流程设计一直是CGRA研究领域的热点。目前主流的后端流程大多基于模调度算法[6]。模调度通过将PEA在时间域上展开,使得PE可以在运行时在多个操作之间动态切换,有效缓解了映射DFG的压力,由此提升了映射成功率和映射性能。本文设计的编译器后端同样基于模调度,具体流程如图4所示。
寄存器分配是为了解决PE互连资源有限而增加的单独编译路径,该编译路径通过分析DFG中的特殊节点,将某些原本通过PE互连实现的数据依赖,改用全局寄存器的读写来实现,这些特殊节点包括DFG中高扇入扇出的节点、访问临时变量的节点,以及具有长数据依赖边的节点等。
在模调度之前,还需要额外对算子进行一系列的预处理操作,包括算子平衡、路由共享[7]和存储器感知优化,这些操作基本都是对DFG进行有效的剪枝处理,在保证DFG功能不变的前提下减少节点和依赖边数量,降低了后续映射算法的难度。

图4 编译器后端流程
通过对DFG上的算子根据其发射时间取模PEA大小(64)的计算结果,得到算子的实际模调度发射时间后,需要构建出DFG的映射对象PEA。由于目标大规模CGRA采用了异构访存结构和不同位置不同的PE互连方案,此时应通过额外的描述文件作为构建PEA的输入,这样才能使本文所实现的编译器后端流程对大规模CGRA具备通用性和扩展能力。
异构映射算法基于一种前向贪心和反向回溯的启发式算法[8],通过改进映射时的PE优先级计算方法,实现了对异构访存结构的支持,该计算公式如下:
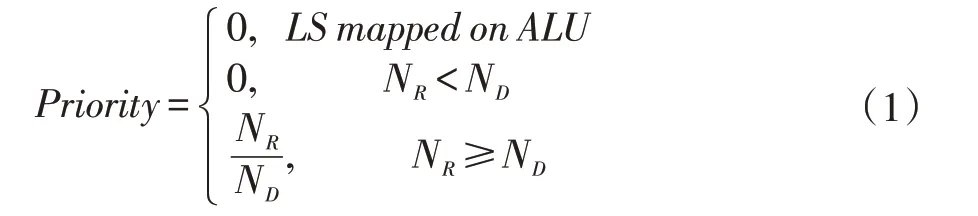
当DFG上的某一算子D被映射到阵列上的某一处理单元R时,首先需要先检查没有发生访存型算子被映射到ALU型PE的情况,再去根据R相邻PE的空闲程度依次映射算子。公式中NR表示该PE通过连接其它空闲PE能访问到的PE数量,ND表示当前算子D还没有被映射的前驱和后驱节点的数量。当ND小于NR时,才能满足映射D之后,继续映射D的前驱和后驱节点不会映射失败,且NR越接近ND,该PE的映射优先级越高,由此间接提升后续算子的映射成功率。
得到调度映射方案后,本文实现的编译器后端工具定制了一个目标CGRA指令集系统的代码生成器,通过遍历分析映射在每个PE上的不同操作,结合其调度时间,根据其是ALU型操作还是LSU型操作生成对应的64位指令,按PE为单位组织成配置包文件。
3 实验结果与分析
本文通过vcs搭建了包含目标大规模CGRA的RTL仿真环境,该仿真环境通过读取本文所实现编译器生成的rocket、pico和PEA三层异构架构的可执行文件和配置包程序,可以仿真得到应用正确运行的波形,由此证明了本文编译器后端流程的正确性。
为了进一步说明本文编译器后端流程设计的高效性,针对几个典型计算密集型应用的循环体,本文将在CGRA仿真环境得到的运行时间和在Intel Core i5-4590传统CPU平台下的运行时间作了比较,具体结果如表1所示。

表1 典型应用在CGRA和CPU上的运行时间比较
统计上表结果发现,在典型计算密集型应用中,本文编译器可以使得大规模CGRA相对传统CPU架构获得平均76倍的应用加速比,充分利用了大规模CGRA的并行计算资源,此结果验证了在大规模CGRA背景下本文所提出编译器后端流程的合理性和高效性。
4 结语
本文针对大规模CGRA的异构访存结构和有限PE互连资源的架构特点,基于LLVM设计并实现了一套新的编译器后端流程,该后端流程可以较容易地被集成到现有的编译器工具链中。本文搭建了目标CGRA的RTL仿真环境,验证了该编译器后端流程所生成配置包的正确性。综合比较典型计算密集型应用在CGRA和CPU上的运行时间,本文的编译器后端流程可以实现平均76倍的应用加速比,由此验证了本文设计的高效性。
