基于SimGAN的交通数据生成方法研究
2020-04-01崔方明时宏伟
崔方明,时宏伟
(四川大学计算机学院,成都610065)
0 引言
随着各行业生产的数据量越来越多,对数据分析处理能力的标准不断升高,怎样面对海量数据的挑战,并在其中发现新的机遇,已经得到了各行业的广泛重视。由于大数据分析建立新型智能信息交通服务系统是当务之急,国内外有关交通大数据的研究正在进行中,与此同时,交通大数据一定会成为该领域数据积累的重要方向,应引起重视。
SimGAN是一种深度学习中的对抗生成模型[1]。SimGAN模型是生成交通数据最有效的方法之一。
1 国内研究
目前,国内大数据研究已经比较成熟,有些互联网公司例如:滴滴、美团、天猫等线上运营大型公司,都是通过大量用户兴趣爱好的数据获得更为准确的估算和价值。例如商汤、依图、旷世科技等人工智能独角兽公司则是依靠于AI产品获取用户的线上和线下信息进行分析。当用户利用这些软件和产品进行操作的时候,就会留下自己的信息,当公司获得足够的信息的时候,各种信息汇集起来,就是一个大数据体系。大数据具有:大量、高速、多样、价值、真实性,五个特性。所以,大数据的获取是很关键的,在某些稀缺领域,数据很难准确获得,例如,自动驾驶、手指跟踪、无人机、等高新科技领域。
当下,对大数据的直接和间接获取,在国内外都比较普遍,但是利用深度学习制造仿真数据,却还不是家喻户晓。仿真数据有很多优势,例如在一些不可控因素、危险因素、估计因素下,仿真数据可以暂时性替代,将实验不间断的进行。所以,将大数据本身和获取大数据的方式方法有机结合,更能够有效地解决一些高新科技缺乏数据实验的难题。
2 研究方法
2.1 利用DenseNet网络和ShuffleNet网络训练模型
DenseNet有一个突出优点是网络比较窄,并且参数比较少,这是由于dense块的设计导致的,每个卷积层的输出feature map的数量很少,并不是像其他网络那样很厚很宽很复杂。而且,这种连接方式的特征和梯度的传递更加有效,这就导致网络训练收敛速度加快[2]。
DenseNet网络提高了信息和梯度在的传输效率,每层都能直接从损失函数中得到梯度值,并且直接获得输入信息,这样就能训练更厚更深的网络。然而有一些网络是从深度和宽度来提升网络效率,但是DenseNet是从特征重用的来提升网络效率的。DenseNet包含以下几个优点:
①减轻了梯度消失
②加强了网络层map的传递
③更加有效利用map
④较少参数数量
DenseNet和ResNet有一个明显区别是,ResNet是残差网络求和,而DenseNet是做拼接,每一层网络的输入值包括了前面所有层的输出。Dense结构如图1[3]。

图1 DenseNet结构
ShuffleNet和MobileNet以及SqueezeNet等网络一样主要是想应用在移动端设备上,得到速度快精度高的结果。ShuffleNet的核心思想是在有限的计算资源下获得最好的模型精度[4]。ShuffleNet的核心是采用了两种操作:逐点群卷积和通道混洗,这既能保证精度又能减低计算复杂度。模型结构设计和模型压缩是在App端很典型的两个优化点。ShuffleNet是通过设计更高效的网络结构来实现模型精度高并且计算快,不是压缩。这里的两个操作,逐点群卷积和通道混洗,逐点群卷积会导致通道变得约束,这大大地影响了精度。从而,应该通道稀疏连接。组卷积可以大大地降低计算损失。这会有副作用,通道的信息流通变弱,表达能力变弱,这时就需要了通道混洗的操作。shuffle unit单元结构如图2。
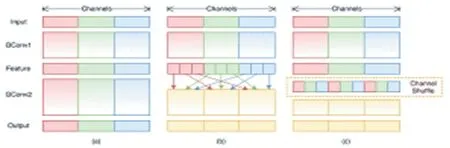
图2 shuffleunit单元
2.2 创新点
借助shuffle的功效来辅助DenseNet在加大深度的同时混洗通道,将图三分别替代图一中的H1,H2,H3,H4。并且用固定的方式一部分与ResNet相加模型相同,一部分与shuffle过程一样。此规定设置一个参数k,可以调整顺序,需要是等比数列。可以设ResNet残差部分是R,shuffle部分为S,中间部分的S的数量是等比数列,用系数k控制,因为到后来需要混洗,但是又不能失去S直接相加的作用。借助此模型改造方法,可以有效的使建模的模型更加轻量级,同时增加了数据识别处理的精确度,但是也存在一定的弊端,需要手动调整更多的参数,并且控制变量不是非常明确。
2.3 交通大数据的获取
(1)开源数据介绍PASCAL VOC-2007
PASCAL VOC-2007为数据识别和分类提供了一整套标准化的优秀的数据集。VOC数据集共包含:训练集(5011),测试集(4952),共计9963,共包含20个种类。Annotations为目标真值区域,ImageSets为类别标签,JPEGImages为真实数据。
JPEGImages文件夹中包含了PASCAL VOC所提供的所有的数据信息,包括了各种训练数据和各种测试数据。Annotations文件夹中存放的是xml格式的标签文件,每一个xml文件都对应于JPEGImages文件夹中的一份数据,ImageSets存放的是每一种类型的chal⁃lenge对应的数据。在ImageSets下有几个文件夹,Seg⁃mentationClass和SegmentationObject这两个文件夹下保存了物体分割后的数据。
(2)SimGAN造带标注的仿真数据
SimGAN是一种深度学习网络,但是它继承于GAN网络,也是一种对抗性生成网络。SimGAN比GAN更加稳定,更加便于增加自己想要的内容。在调用SimGAN的时候,可以写丰富的Python脚本搭配。
本文利用了深度学习“对抗训练”方法,可以使用合成的和未标记的数据训练先进的神经网络。通过自正则化损失项使精确和合成数据之间的差异最小化来保留标注。使合成数据看起来是真实的(GAN的标准概念)。精炼网络(refiner)将合成数据样本作为输入,输出相同维度的改进数据样本。判别网络(discrimina⁃tor)将数据样本作为输入,并将其分类为改进的或真实的。
改善器RR:输入合成数据,输出改善结果。鉴别器DD:判断输入是真实数据还是经过改善的合成数据。相关的代价有三种:代价1:鉴别器识别改善图像的错误率。代价2:鉴别器识别真实图像的错误率。代价3:改善图像和原始图像的逐像素差。其中,代价3保证改善图像和原始图像的类标相同。例如,保证手势姿态不变保证视线方向不变。除了直接比较像素,还可以提取图像特征之后在做差。在每一轮迭代中:最大化代价1,最小化代价3,优化改善器RR的参数。共执行KrKr次SGD。最小化代价1,最小化代价2,优化鉴别器DD的参数。共执KdKd次SGD。经过若干次迭代得到的改善器RR,可以将合成样本加工成具有以下两个性质的样本:品质和真实图像难以分辨,保持合成样本原有类标不变。
随着迭代不断进行中,鉴别器DD会过分利用一些错误的全局特征信号进行分类从而使得改善图像出现不自然。举例:真实图像中可能只包含一些固定视线方向的样本,但合成图像的视线方向则均匀而连续。于是鉴别器“以偏概全”地以视线方向作为真假样本的判别标准。解决办法是:在训练鉴别器DD时,将图像分割成小块分别输入;在利用DD进行分类时,以各个小块的分类结果只和作为该图像的结果。除了避免全局信息引artift之外,这种方法还能够增加训练样本的数量。SimGAN结构如图3。
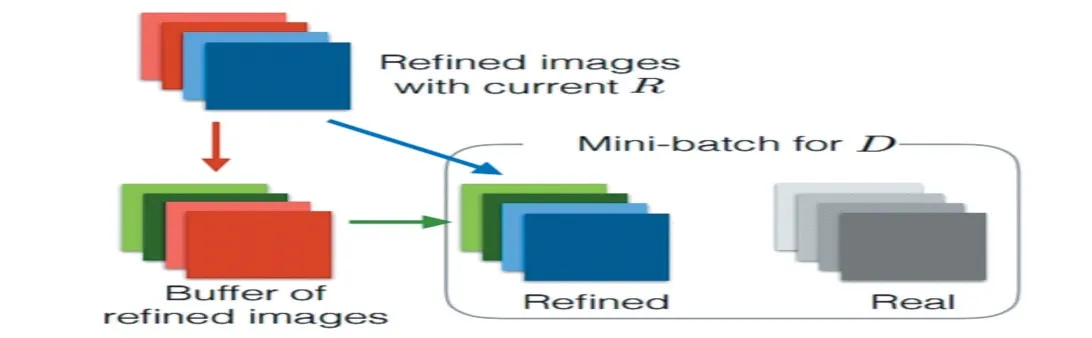
图3 SIMGAN精炼结构
3 实验设计及结果分析
实验是利用DenseNet和ShuffleNet的结合模型,来将文章核心模型SimGAN生成的仿真数据以及VOC2007开源数据进行多阶段的混合实验。通过此实验,可以提高交通路径规划准确率和降低建模的重量级,利用识别出来路径MAP,来进行对比实验,并且规划出更佳的路线。实验采用的是Python编程语言、深度学习框架TensorFlow和基于并行编程模型和指令集架构的通用计算架构CUDA8.0,通过torch.cuda调用GPU来提升计算速度[8]。本文使用在线质量度量工具moba通过路径规划轻量级别和路径规划MAP得分来评价实验结果。实验中测试了几种模型DenseNet和ShuffleNet以及MobileNet对路径规划的预测,迭代次数为50000次[9]。
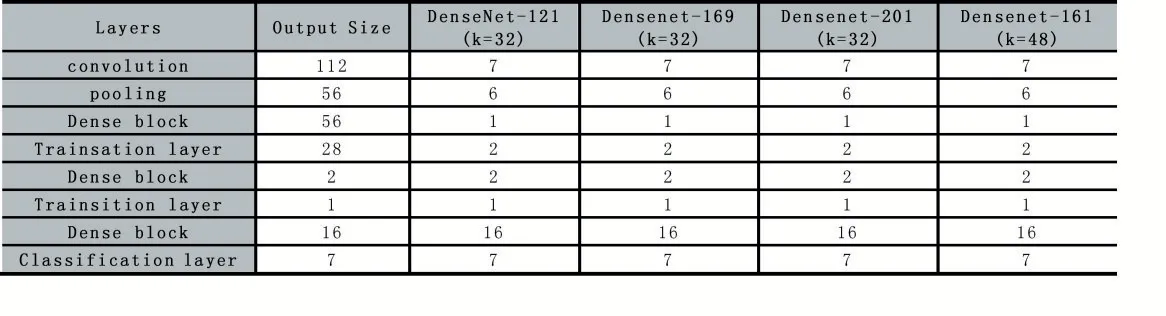
表1 DenseNet的完整实验

表2 ShuffleNet的完整实验
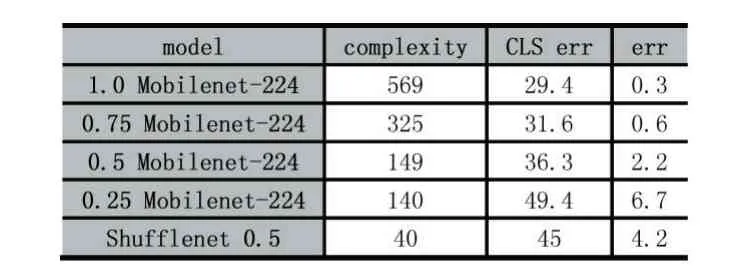
表3 两种模型对比实验与MobileNet和其他模型相比

表4 DenseNet不同比例下实验结果展示
4 结语
本文提出了一种生成仿真数据的方法,此方法利用SimGAN深度学习模型生成大量带有标注交通方面的数据,交通数据具有多样性和仿真性,所以在真实数据不足的情况下,可以利用SimGAN模型达到目的,以此来丰富训练内容,多个角度训练模型,使路径规划效果精确和普适性。同时,本文利用了DenseNet和Shuf⁃fleNet来建模分析数据,由于这两类模型本身具有的特点,所以将其结合达到了轻量化和精确率高的目的。实验证明SimGAN很适合应用于道路交通路径规划的数据获取方面研究,与传统数据建模相比,SimGAN应用数据种类更多,能够提升针对大量交通大数据信息挖掘和分析的效率。
在将来的工作中,可以将此模型应用于离线端口,这就需要将模型结构压缩和量化,量化后的模型可以更加方便地嵌入到终端App中,使交通数据分析更加实时性,路径规划更加便捷。
