多源融合格点实况数据在四川高温过程的适用性分析
2020-03-30王佳津龙柯吉黄晓龙
丛 芳,王佳津,龙柯吉,黄晓龙
(1.四川省气象台,成都 610072;2.中国气象局成都高原气象研究所/高原与盆地暴雨旱涝灾害四川省重点实验室,成都 610072;3.四川省气象探测数据中心,成都 610072)
引言
多源融合格点实况数据是运用多重网格变分同化技术将地面站点观测数据和数值模式预报场或者卫星资料融合所得到的,时间分辨率为1h,空间分辨率可达1km,包含2m气温、地面气压、2m比湿、风速、小时降水量等产品[1]。随着精细化智能网格预报的发展,对高质量格点实况数据的要求越来越高[2]。无论是模式的检验或是订正模型的建立,都需要一个无限接近于实况的且与模式预报场分辨率一致的格点实况数据。格点实况是精细化网格预报发展的基础[3,4]。国内多家单位先后研发了多种高分辨率的地面格点实况产品[5-7],数据精度逐步提升,2020年7月国家气象信息中心下发1×1km分辨率实况格点产品,包括降水、2m气温、比湿、10m风共计4个要素,14种产品。
四川地处青藏高原东部边缘,地形复杂,西为川西高原,南为川南山地,东为盆地及盆缘山地,海拔高差在2000m以上[8]。吴薇等[9]对两套融合降水产品在四川的适用性进行了评估,发现三源融合降水产品优于二源。龙柯吉等[1]在针对温度格点实况数据在全国适用情况进行了质量评估,发现实况数据随海拔高度的增加而变差。面对如此复杂的地形,亟待分析新下发的高精度多源融合格点实况数据中2m温度对于四川夏季高温过程的适用性[10],以及不同分辨率下融合格点数据的检验结果。为解决上述问题,本文基于高温过程对多源融合格点实况数据开展了检验。
1 资料与方法
1.1 资料
2017年6月国家气象信息中心下发5×5km实况格点产品[1,3,7],包括降水、2m气温、相对湿度、10m风、能见度、总云量共6个要素,18种产品。2020年7月下发1×1km分辨率实况格点产品,包括降水、2m气温、比湿、10m风共计4个要素,14种产品。本文主要针对国家气象信息中心下发的5km、1km的2m气温最高温度进行检验。所运用到的实况站点资料为四川国家站和加密自动站共计3613站的温度数据,站点分布如图 1所示。
1.2 插值方法
为了检验多源融合格点实况数据最高温度质量,将不同分辨率的格点数据插值到站点再与站点实况进行比较评估。所使用的插值方法为邻近插值和双线性插值。邻近插值是选取距离站点最近的格点值作为站点对应格点值;双线性插值方法是先经(纬)向后纬(经)向进行一元一次线性插值[1]。
1.3 检验方法
检验评估用到的统计量有5个[11],分别是预报准确率(T)、平均误差(ME)、平均绝对误差(MAE)、均方根误差(RMSE)、Alpha Index(AI)。具体公式如下:
(1)预报准确率
2m温度 |Fi-Oi|≤1℃或|Fi-Oi|≤2℃
(1)
(2)平均误差
(2)
理想分为0,代表模式的系统误差,正值表示预报值高于实况值,负值表示预报值低于实况值,是订正模式产品时最为有用的参考值,再结合平均绝对误差MAE,可以进一步判断偏差订正的可信度,二者接近时(相关性较好)说明系统误差明显[12]。
(3)平均绝对误差
(3)
(4)均方根误差
(4)
(5)Alpha Index
(5)
其中,Fi代表模式预报值,Oi代表实况观测值。AI指数量化了随机误差的技巧,取值意义如表 1所示,取值范围为0~2:理想值为0,表示模式预报值与实况观测值差异小且随机误差小;取值接近1,表示模式预报值与实况观测值差异大且随机误差大;取值接近2,表示模式预报值与实况观测值趋于负相关,但随机误差小[13-14]。
2 过程实况
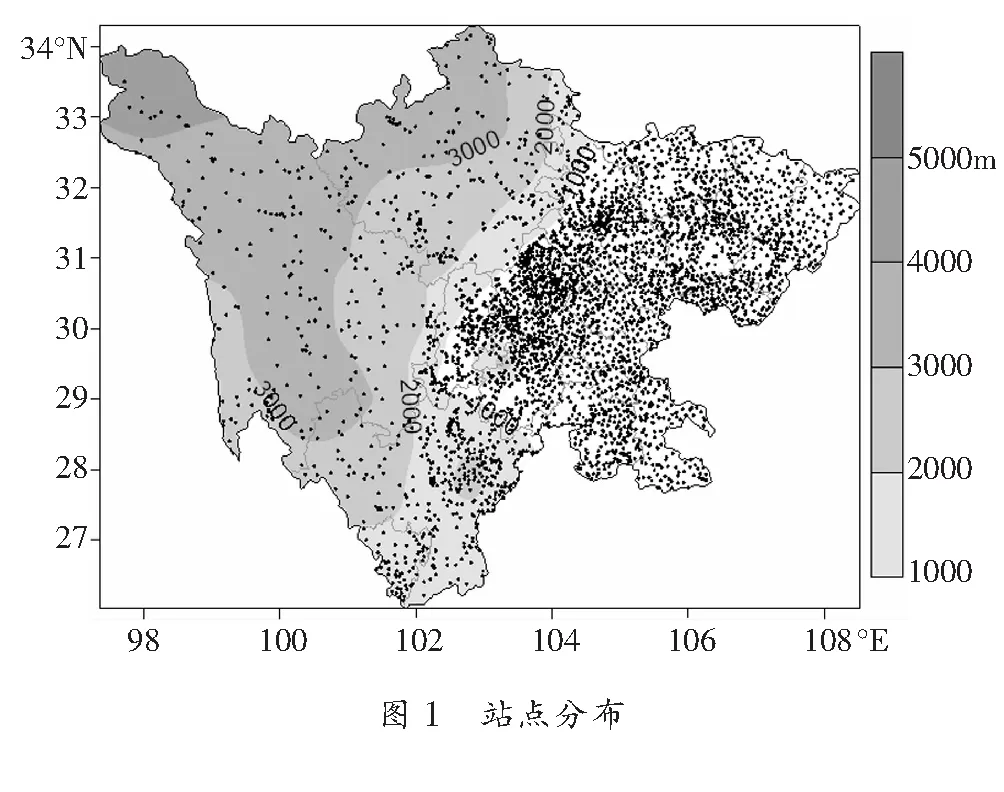
受青藏高压的影响,2020年8月四川盆地出现了两次高温过程,分别为8月9、10日(过程一)和8月27、28日(过程二)。图 1给出了两次高温过程最高温度实况。从图中可以看出,两次过程最高温度出现35℃以上区域主要位于在盆地内(低海拔区),个别站点温度超过40℃,过程一出现40℃以上高温站点皆为31站,主要分布在盆地东北部、南部以及凉山州东北部,而过程二出现40℃以上高温站点分别为28站,主要集中在盆地东北部。
3 最高温度误差空间分布
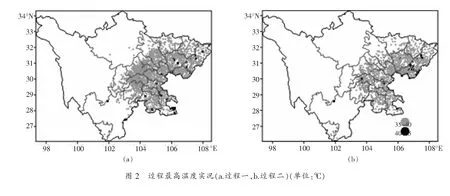
本文在格点到站点的算法上选择了邻近插值法和双线性插值法,为了对比不同插值方法的释用效果,分别计算了两次过程不同插值方法不同分辨率的平均绝对误差。从表 1中不难发现,邻近插值方法下的平均绝对误差皆小于双线性插值方法,即邻近插值的评估结果优于双线性插值,这与龙柯吉等[1]研究结果一致。此外,对比两次过程之间的平均绝对误差可以发现,不同分辨率下过程二的误差小于过程一。

表1 两次高温过程最高温度不同插值方法的平均绝对误差
接下来基于邻近插值方法,分析一下两次过程最高温度误差分布的空间特征(图 3)。过程一,1km分辨率的融合格点资料98%的站点误差在±2℃之间,误差≥2℃的站点为11站,误差≤-6℃的站点两天都为10站,误差比较大的站点主要出现在甘孜州、凉山州东部;5km分辨率的融合格点资料84%的站点误差在±2℃之间,误差≥2℃的站点为150站,误差≤-6℃的站点为11站,误差比较大的站点出现在盆周山区、川西高原和攀西地区。过程二,1km分辨率的融合格点资料同样是98%的站点误差在±2℃之间,误差≥2℃的站点为13站,误差≤-6℃的站点两天都为10站,误差比较大的站点主要出现在盆地西部沿山一带和凉山州北部;5km分辨率的融合格点资料85%的站点误差在±2℃之间,误差≥2℃的站点为152站,误差≤-6℃的站点为13站,误差比较大的站点同样出现在盆周山区、川西高原和攀西地区。总体来说,1km分辨率多源融合格点实况数据98%的站点误差在2℃以内,而5km分辨率数据只有84%的站点在2℃以内。综上分析可以看出气温误差分布跟地形和下垫面有一定的关系,格点实况气温产品反演时应该关注地形差异,这与俞剑蔚等[3]研究结论一致。师春香等[7]在阐述多源气象数据融合格点实况产品研制进展中也提到,复杂地形、下垫面下资料的多源资料偏差订正技术是产品研制中的关键技术,需要后续深入研究。
4 最高温度质量评估
表 2是基于过程一的多源融合格点实况最高温度预报准确率、均方根误差和AI指数的检验结果。从预报准确率来看,1km分辨率误差≤2℃的准确率达98%,误差≤1℃为90%;5km分辨率误差≤2℃的准确率为84%,误差≤1℃的准确率为55%,与1km分辨率数据相比,1km分辨率多源融合格点实况数据的适用性更好,能够监测高温天气。从AI指数上来看,1km分辨率为0.02,5km分辨率为0.07,都较为接近于0,说明多源融合格点实况数据随机误差小,接近真实值。从RMSE来看,1km分辨率为0.88,5km分辨率为1.56,因 RMSE反映的是误差幅度的平均情况[13],检验结果表明1km分辨率数据的误差平均幅度<5km分辨率。国家气象信息中心的多源融合格点实况数据融合了地面、探空、雷达、GPS/MET、风云2G卫星、葵花8卫星等观测资料[7],产品分辨率越高,越能体现出稠密观测数据信息,数据表现上更接近实况,所以总体来说1km分辨率格点实况数据的误差平均幅度<5km分辨率。

表2 基于过程一的多源融合格点实况资料过程最高温度质量评估
表 3是基于过程二的多源融合格点实况最高温度预报准确率、均方根误差和AI指数的检验结果。从预报准确率来看,1km分辨率误差≤2℃的准确率达98%,误差≤1℃为91%;5km分辨率误差≤2℃的准确率为85%,误差≤1℃的准确率为58%,检验结果仍然表明1km分辨率多源融合格点实况数据的适用性更好。从AI指数上来看,1km分辨率为0.02,5km分辨率为0.04,都接近于0,说明多源融合格点实况数据接近真实值。从RMSE来看,1km分辨率为0.91,5km分辨率为1.56,同样表明1km分辨率数据的误差平均幅度<5km分辨率。

表3 基于过程二的多源融合格点实况资料过程最高温度质量评估
总体来说,多源融合格点实况数据能够很好反应出高温过程。对于发生在四川盆地8月的这2次过程,≤2℃的准确率5km分辨率数据达到80%以上,1km分辨率高达98%。龙柯吉等[1]对1km高分辨率温度融合格点产品进行质量评估时也提到融合格点实况数据能很好的表现出高温落区的变化,其35℃以上的落区与实况基本一致,但38℃以上的落区较实况偏小。
5 结论
本文基于2020年夏季两次高温天气过程,对1km和5km的多源融合格点实况资料在四川应用的准确性进行了检验评估,为该产品的合理应用和进一步改进提供依据。主要结论如下:
(1)不同插值方法比较上来看,邻近插值法优于双线性插值方法。
(2)从两次高温过程的最高温度误差空间分布上看,正误差大值区主要分布在盆周山区、川西高原和攀西地区;而负误差大值区主要分布在川西高原和凉山州东北部。
(3)多源融合格点实况数据的最高温度几乎无随机误差,但1km分辨率数据适用性优于5km,1km分辨率多源融合格点实况误差≤2℃的准确率可达98%以上,均方根绝对误差<1。
