车前小型障碍物图像检测与分类方法
2020-03-25陈炳煌12
陈炳煌12
(1. 福建工程学院 信息科学与工程学院, 福建 福州 350118;2. 福建省汽车电子与电驱动技术重点实验室, 福建 福州 350118)
感知和理解环境的能力是汽车智能系统的基础和前提[1]。智能车辆通过感知周围环境并做出分析后,将信息提供给控制系统,引导车辆避开障碍物行驶。例如谷歌和德国的无人驾驶汽车配备先进的智能识别、自动驾驶和导航系统,可以探测到行人和其他车辆[2-5]。然而,对于高度明显低于车辆高度的障碍物或者目标较小的障碍物,如小石子和道路坑洞等小型障碍物,车载系统在图像检测和识别上仍有一些不足之处[6]。这些小障碍物体积和几何尺寸都较小,导致车辆在快速行驶过程中很难检测到,从而造成车辆受损甚至人员受伤[7]。而车载视频检测小障碍物的低检出率和实时性低的问题将不能保障车辆安全行驶。对于车辆前方障碍物的视频图像检测,最重要的是图像检测算法的实时性和鲁棒性[8]。
在图像目标检测领域,Girshick、Ren 等[9-10]分别提出了快速区域卷积神经网络(fast regional convolutional neural network, Fast R-CNN)和更快速区域卷积神经网络(Faster R-CNN),可以提高图像检测的准确率。但这些算法检测速度较慢,不适合实时检测车前障碍物。Redmon等[11]提出YOLO (you only look once)可以满足检测速度的要求,其视频检测速度达到45fps。而且YOLO对于小型目标的识别精度也较高,这对于实时的车前小型障碍物的图像检测与识别是个优势。
为了使驾驶辅助系统能快速地并且实时地识别小型障碍物,提出一种优化车载视频图像检测车辆前方小障碍物和新增分类计数的方法,将优化后的YOLO(optimized YOLO,O-YOLO)应用于道路坑洞和小石子等小障碍物的图像检测。
1 小型障碍物图像检测与分类
为了能实时并有效地检测小型障碍物,并给车辆驾驶员发出相应警示信息,需要对车前小型障碍物的图像和视频进行检测识别和分类计数。整体步骤如下:
(1)建立小型障碍物图像数据库,并标注。
(2)采用k-Means+对数据库进行聚类,找到最优k值。
(3)针对最优k值和小型障碍物图像数据库进行针对性分析计算,得到训练所需的Anchor值。
(4)通过O-YOLO对图像数据库的训练集进行训练,得到最优训练权重。
(5)将该训练权重应用到测试集,并根据图像特点设定感兴趣区域(region of interest,ROI),对目标进行检测识别和分类计数,输出结果。
1.1 YOLO算法原理
YOLO是一种使用深度卷积神经网络学习的特征来检测对象的对象检测器,有3个版本。YOLO v3[12]使用了新的网络Darknet-53,其结构如图1所示(以416×416为例)。该模型使用了大量性能良好的3×3和1×1卷积层,有53个卷积层。YOLO v3从输入图像中提取出特征,然后将输入图像分割成13×13的网格单元。如果ground truth中的对象的中心坐标位于网格单元中,则将对该对象进行预测。每个网格单元预测3个大小不同的边界框(13×13、26×26、52×52)。目标检测预测了ground truth与所提出的边界框之间的IOU(Intersection over Union)。而类别检测预测的是该类别是目标的概率。输出特征图中有两个维度(宽、高),如13×13。另一个维度(深度)是
Box×(5 + Class)
(1)
式中,Box表示每个网格单元预测的边界框数,Class表示目标类别数,5表示为4个坐标和1个客观分值。

图1 YOLO v3的网络框架Fig.1 Network of YOLO v3
YOLOv3采用类似SSD(single shot multiBox detector)的多尺度策略,以类似于特征金字塔网络的方式从不同尺度提取特征,使用13×13、26×26、52×52三个尺度的特征图进行预测,使得预测鲁棒性更强。
1.2 k值与Anchor值的优化
通过YOLO v3可实现高速的特征提取和高速的对象检测,但是车前障碍物需要实时准确地检测出来,对检测精度的要求也很高。为解决车前的小型障碍物检测精度较低的问题,研究对原始的YOLO v3进行优化。
YOLO借鉴区域卷积神经网络(regional convolutional neural network,R-CNN)的思想,引入Anchor值,它是一组k个簇中心框的宽高值,影响目标检测速度和分类识别精度[13]。通过k-Means+对数据集中标记的目标框进行维度聚类可以确定k值和Anchor值,找到目标框的统计规律。原始YOLO v3的Anchor值是由微软COCO(common objects in context)图像数据集聚类确定的。因COCO图像数据集中有80个类别,其Anchor值是由这80个类别生成的,但这并不适用于前方小障碍物数据集。因此,为了提高图像检测识别和分类的精度,聚类的k值和Anchor值需要重新计算确定。小障碍物数据集目标框的宽高经过k-Means+聚类的最优k值由样本聚类误差平方和方法确定[14]。
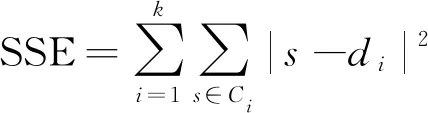
(2)
式中,误差平方和(SSE)是样本聚类误差平方和方法的核心指标,s是样本,di是第i个聚类的中心点。k越大,SSE越小,说明样本聚合程度越高。通过对小障碍物图像数据集的训练样本进行聚类得到SSE曲线,最先趋于平缓的点即为合适的k值,如图2所示,k为3。从表1可发现小障碍物数据集的宽高维度值基本表征了小石子和坑洞的几何尺寸。

图2 SSE聚类曲线Fig.2 SSE clustering curve
1.3 ROI的确定
在实际应用中,车前图像的获取是由设置在车内的摄像头完成,摄像头可以记录行车视频,拍摄事故过程中的重要照片。绝大多数情况下图像的上半部分是距离车辆较远的区域,因此将图像的下半部分确定ROI有利于图像检测和分类计数、提高检测效果,如图3所示。而摄像头的分辨率不同,导致图像的输入源不同,因此根据图像的比例来确定ROI。
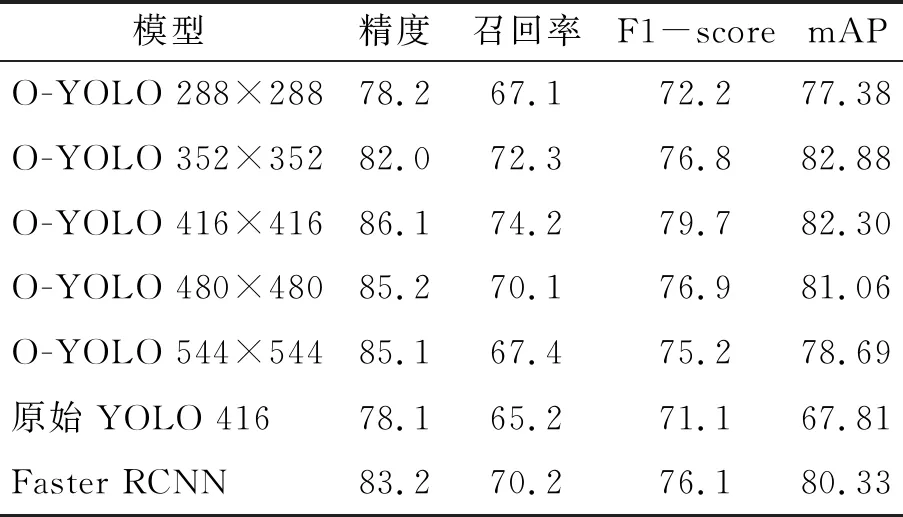
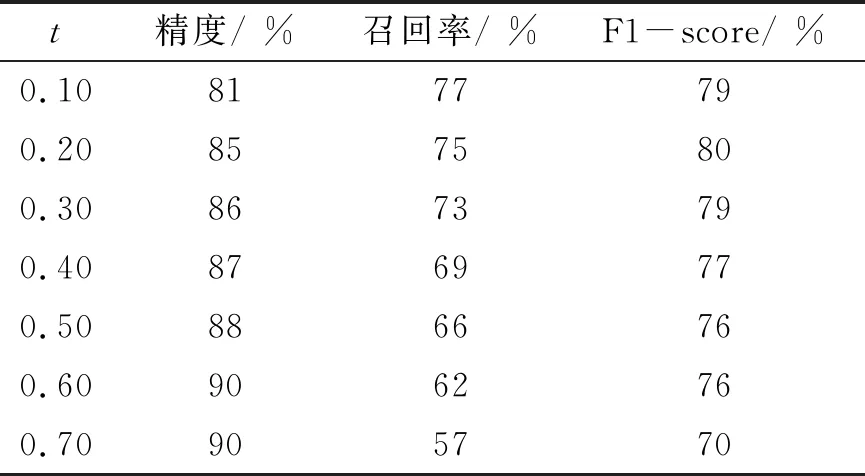
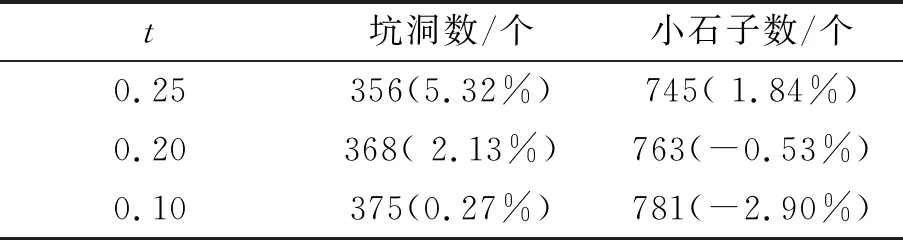
0.03 0.46 (3) 表1 不同数据集的Anchor值 式中,X_center和Y_center分别为图像目标框的x轴和y轴中心的坐标位置。0.03和0.97分别为宽度比例,0.46和1.00分别为高度比例,当图像分辨率是1 920×1 080时,按比例其宽度为70~1 850,高度为500~1 080,从而匹配任何大小的图像。 图3 ROI的确定Fig.3 Setting ROI 图像检测目标对象的计数一般比较简单,原始YOLO v3可以检测图像中物体的总数。但是每一类对象不能被原始YOLO v3单独计数。因此,提出一种分类计数算法,并自动生成报表。 Counting and classification algorithm STEP 1:The counter and the count cache are initialized: js=0, buf=0 STEP 2: Detect small obstacles byO-YOLO. The total number and class of objects can be detected. STEP 3: For i=0 to num If (0.03 Then js=js+1, copy class name to buf End for. STEP 4: Calculate the number of the same name and output to the TXT document. 从STEP 3可得到相应的缓存数据如:stone hole stone. STEP 4 中TXT文本保存格式为:002345.jpg图像中有3个目标: 小石子2个, 坑洞1个。 数据集训练和测试的实验环境为:Windows 10系统,内存64G,显卡Nvidia Quadro M4000 (8GB RAM)一张。同时使用Faster R-CNN对同一数据集进行训练和测试与本算法进行对比。 由于没有的小石子和道路坑洞的图像数据集,本文收集了一些不同大小的小型障碍物图片(jpg格式),并利用车载摄像头采集到小型障碍物1 080p高清视频,通过视频转换器获得高清序列图像。针对小石子和坑洞原始图像较少的情况,利用图像剪切、对比度增强、微角度旋转、图像平移、图像翻转、加噪声等方法增大图像数据,共得到3 575张图片,形成小型障碍物图像数据库。其中用于O-YOLO训练3 217张,测试358张。设置2个类别,按小石子(stone)和坑洞(hole)标注,如图4所示。 图4 车前小型障碍物数据集Fig.4 Dataset of small obstacles in front of a vehicle 针对小障碍物图像没有预先训练的模型,训练过程较费时,训练前需要根据式(1),设定O-YOLO的关键训练参数“filters”。实验中,Box取3,Class取2,则filters是21。 其他训练参数主要包括:学习率、动量和衰减。在这个实验中,动量是0.9,衰减是0.000 5。实验的学习率策略是阶段性的。根据迭代次数,其具体的变更过程如表2所示。在迭代次数为20 000次时,学习率降低到0.000 1,可以加快训练速度。O-YOLO 416×416模型的损失曲线如图5所示。最终的平均损失值是0.367 7。图像输入分辨率的大小影响检测的精度[8],因此使用5种不同分辨率图像模型(O-YOLO 288×288、352×352、416×416、480×480、544×544)来训练。 表2 学习率变化策略 图5 O-YOLO 416×416模型的损失曲线Fig.5 Loss curve of O-YOLO 416×416 本实验针对2个类别分别计算其精度(precision)和召回率(recall)。图像检测分析中,阈值t设置为0.25,以保证检测精度较高。表3显示了O-YOLO下5个模型的精度、召回率、基于精度与召回率的调和平均值(F1-score)和平均精度均值(mAP)。图6显示了精度-召回率(P-R)曲线。从表3可见O-YOLO 352×352模型的mAP为最好 (82.88%)。但是在精度相差不多的情况下,O-YOLO 416×416模型的精度(86.1%)、召回率(74.2%)和F1-score值(79.7%)都优于O-YOLO 352×352模型。 表3 7种模型的测试结果 图6 O-YOLO 5种模型的P-R曲线Fig.6 P-R curves of 5 models of O-YOLO 为进一步说明图像检测识别与分类方法的有效性和实时性,针对同一个小障碍物图像数据集采用原始YOLO和Faster RCNN算法进行检测分析和对比,如表3所示。O-YOLO 416×416模型的mAP值和F1-score值分别比Faster RCNN算法高1.97%和3.60%,而且分别比原始YOLO算法高10.24%和12.10%,说明经过优化,该算法对于小型障碍物图像检测的精度较为优秀。 针对O-YOLO 416×416模型在不同阈值影响下测试的精度和召回率如表4所示。随着阈值的增加,精度越来越高,召回率越来越小。当t= 0.20时,F1-score指标是最好的,数值为0.80,表示416×416模型的鲁棒性很好。 表4 精度和召回率的测试数值 实验使用O-YOLO 416×416模型来测试358张图像。图7为障碍物检测结果图。检测结果可以通过分类计数算法输出到TXT文档中。一个文档对应一个识别任务,每个TXT文档包含图像名称、障碍物名称和计数结果。 图7 障碍物检测结果Fig.7 Obstacle detection results 表5显示了实际数据为376个坑洞和759个小石子时不同阈值下的测试数据和相对误差。由表5可知,当t=0.10时,O-YOLO对道路坑洞的检测效果较好;而t=0.20时,O-YOLO对小石子的检测效果较好;但是总体统计,当阈值t=0.20时O-YOLO的检测效果较好。这一组358张图像在O-YOLO的测试用时为35 s,平均一张图像检测用时为0.097 s;而在同一测试平台上使用Faster RCNN来测试用时为125.3 s,平均一张图像检测用时为0.350 s,远远低于O-YOLO的检测速度,因此该方法在检测速度和精度上均有上佳表现,能够胜任车载实时检测。 表5 测试数据与实际数据的对比 小型障碍物图像检测还存在一些误差,如图7(a)的右下角没有发现一些小石子,主要是由于目标物过小,O-YOLO的检测精度还不够高。在此方法的研究基础上增加更多的数据集,并且修改O-YOLO的网络结构以提高小障碍物的检测精度。 针对车辆前方的小型障碍物检测识别困难、无有效分类和实时性差的问题,本文提出了一种基于YOLO的车辆前方小障碍物图像检测优化与分类计数的方法。为提高检测精度,O-YOLO的k值使用k-Means+方法进行优化,并对Anchor值进行针对性的计算。为了对小石子和道路坑洞这2类小型障碍物进行准确的分类计数,提出了一种特殊的计数分类方法。实验分析和对比,该算法的检测精度为0.86,检测速度优于Faster RCNN算法,验证了方法的有效性。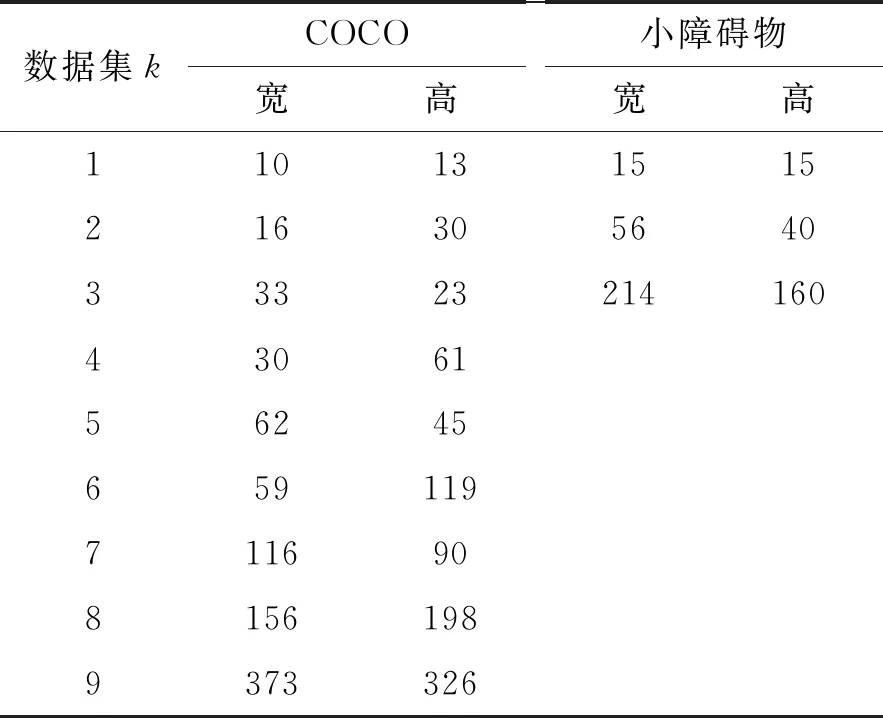

1.4 计数与分类
2 实验
2.1 图像数据库

2.2 训练

2.3 图像检测和对比分析


2.4 分类及计数测试分析

3 结论
