用于肺结节检测和分类的两阶段深度学习方法
2020-03-25薛潺涓
贾 锋, 薛潺涓, 王 欣
(吉林大学 计算机科学与技术学院, 长春 130012)
在肺癌早期筛查中, 肺部计算机X射线断层扫描(computed X-ray tomography, CT)图像上的肺结节可为医生提供诊断依据[1]. 而计算机辅助诊断系统对肺癌的早期诊断有重要意义, 能准确高效地筛查大量CT图像, 并有效减少医生由于疲劳而导致的误诊. 近年来, 由于深度学习在图像处理中取得的优异成绩[2-7], 将深度学习算法应用在医学图像处理中被广泛关注[8-11]. 例如: Roth等[12]采用卷积网络进行肺结节的检测; Ciompi等[13]采用深度学习方法进行肺裂隙周围结节的分类, 为提高准确率, 同时采用了轴向面、 冠状面和矢状面的CT视图; Kumar等[14]使用自编码器的方法进行肺结节的分类. 上述研究尽管都取得了较好的效果, 但都只采用二维卷积进行特征提取, 不仅未使用结节的周长、 尺寸等固有特征, 还忽略了肺部CT实际上是三维数据的特性. 针对该问题, Kim等[15]提出了使用深度学习寻找CT影像中潜在特征的方法; Zhu等[16]提出了使用三维卷积的肺结节检测和分类方法.
使用三维数据对提高肺结节检测和分类的准确率有重要意义, 但提高了数据处理的压力, 且肺结节的检测和分类任务所需的模型容量较大, 进一步增加了基于深度学习, 尤其是使用三维卷积方法所需模型的规模和内存. 常见的解决方案是采用大窗口、 小步长的密集裁剪方法降低网络的单次数据吞吐量[11,16], 但盲目地进行密集裁剪会导致样本量的激增, 降低训练效率, 且容易破坏结节特征. 基于此, 本文提出一种基于语义分割和空间金字塔池化[17]的多尺度深度学习方法, 用于CT影像中肺结节的检测和分类. 实验结果表明, 本文提出的模型在LUNA16[18]公开数据集上表现出了对肺结节检测和分类的良好性能, 同时避免了对数据的盲目裁剪, 提高了特征的利用率和训练效率.
1 目标检测
从CT图像中确定肺结节的位置, 属于图形学中的“目标检测”任务. Faster-RCNN[19]是具有代表性的基于深度学习的目标检测方法. 该方法首先使用一个卷积网络进行特征提取, 卷积网络可以是VGG-16[20]或ResNet101[21]等合适的模型, 再使用区域建议网络(region proposal networks, RPN)进行候选区域提名, 最后使用ROI Pooling综合卷积网络提取特征和候选区域, 并统一多尺度输入, 提供给分类后端进行分类和输出. Faster-RCNN的候选区域提名采用“anchor+偏移量”的描述方法, 其中anchor表示给定的一系列标识位置的矩形框, 通过对这些矩形框施加一个网络预测产生的偏移量框定目标区域, 避免了选择性搜索[22]等方法的大量时间开销. 本文借鉴这种方法, 针对肺结节检测任务的特点, 在肺结节检测中采用尺度为5,10,20的三种anchor以及x,y,z,d四个偏移量描述一个候选结节的位置和直径.
2 语义分割
语义分割任务是对输入图像中每个像素进行分类的过程, 与其他图像任务相比, 语义分割最显著的特征是输出结果为一张图片, 每个像素值表示输入图片对应位置的分类结果. 基于深度学习的语义分割有全卷积网络(fully convolutional network, FCN)[23]、 Tiramisu[24]和U-Net[25]等方法. 考虑到U-Net的网络结构有较大设计空间, 且可广泛应用于医学图像的处理, 因此本文使用基于U-Net的三维卷积模型进行肺结节的检测. 语义分割的优势为除了能给出定位和分类结果外, 还能提供对输入场景的语义分割结果. 本文使用语义分割结果对分类器的输出进行预处理, 用以屏蔽非结节区域并突出候选结节区域, 以提高分类的灵敏度.
3 算法设计
3.1 预处理
对肺部CT图像进行预处理的目的主要有两个: 首先, 肺部周围的一些结构, 如血管或支气管的横断面在结构上相似, 这些肺部外的结构不但会增加无关数据量, 还会对检测结构产生干扰, 因此需将肺部以外的区域去除; 其次, CT图像具有较大的位深度, 使得其数值范围很大, 不利于神经网络的收敛, 因此需要对图像进行归一化.
CT值反映物质的密度, 肺部的CT值为-450~600 HU. 本文基于文献[11]的工作对肺部CT图像进行了预处理, 取-400 HU为窗位, 1 500为窗宽, 该状态下的原始肺部图像如图1(A)所示. 然后对图像依次进行二值化、 清除外部边界、 取最大连通区域、 模板大小为2×2的腐蚀以及模板大小为10×10的闭操作后, 再通过空洞进行填充, 得到完整的肺部区域掩码, 最后将肺实质掩码与原图像相乘, 得到最终分割的肺实质图像, 分别如图1(B)~(H)所示.

图1 肺部CT图像的预处理
预处理中窗宽和窗位的选取是为了便于掩码生成以及展示效果, 在实际应用中, 掩码会作用于原始的CT数据, 原始数据的动态范围并未被压缩, 因此需要对原始数据进行归一化操作以加快网络训练的收敛. 对于肺部CT, CT值大于600 HU则说明不是肺部组织, 由于本文不需考虑骨组织, 因此选取归一化阈值为[-1 200,600], 将该范围归一化到[0,255]区间. 本文采用的归一化公式如下:

(1)
其中: pixelCT表示肺部图像的CT值; pixelnormal表示归一化后的值.
经过上述处理后, 原始数据中只保留了肺部数据. 为充分利用CT数据中的三维信息, 网络模型采用三维卷积结构, 因此需将数据也处理成三维形式. 由于数据集中含有的CT图像是由不同仪器设备采集的, 其原始空间坐标系与像素间隔并不完全一致, 因此必须统一坐标系统. 本文首先将原始数据所采用的世界坐标系转换为统一的图像坐标系, 并通过平移变换将原点的位置统一. 然后利用尺度变换和三次样条插值将像素间隔统一为每个像素表示世界坐标系中的1 mm×1 mm大小. 最后, 为提高训练时的读取效率, 将所有训练数据都预先裁剪为96×96×96的三维数据块并进行磁盘缓存, 裁剪步长为4, 延拓时采用水对应的CT值170 HU进行填充.
3.2 模 型
本文使用的模型分为检测器和分类器两部分. 检测器以U-Net为基础结构, 编码阶段采用14层三维卷积, 将尺寸为[N,1,96,96,96]的输入编码为尺寸[N,512,3,3,3]的特征(尺寸含义为[batch size,channels,W,H,D], 其中batch size和N表示数据中含有的图片数量, channels为通道数,W,H,D分别表示输入数据在x,y,z方向上的尺寸). 解码阶段采用相同深度的三维反卷积层, 每隔两层编码器将编码特征与解码特征进行连接, 最后得到[N,15,96,96,96]的输出特征, 其中包含[96,96,96]的语义信息和对应三种anchor(尺度为5,10,20)的四个偏移量(分别为坐标x,y,z的偏移量和直径d)以及置信度p.
对检测器的输出进行多尺度处理. 首先, 将检测到的所有置信度大于80%的候选结节按检测器预测出的中心坐标和直径从原始数据中进行裁剪; 然后将裁剪所得数据块与检测器给出的语义信息中心重合, 以语义信息为掩码, 作用于原始数据, 将候选结节外的像素屏蔽, 起到突出候选结节并减少外部干扰的作用; 最后将处理后的候选结节输入到一个五级的池化金字塔, 如图2所示, 池化尺度分别为1,3,4,6,8, 无论输入尺寸多大, 最终输出的特征都是126维(126=12+32+42+62+82), 该特征将作为分类器的输入.

图2 金字塔池化
分类器接受池化金字塔的输出, 并最终给出该候选结节是恶性结节的概率. 分类器网络的构造单元为双路径网络(dual path network, DPN)[26], 它将输入特征分为两部分, 分别通过密集链接块和残差块, 在输出端重新拼合成一个特征向量. 残差结构能将特征传递到更深的结构, 便于通过加深网络层次获取更好的效果, 而密集连接结构能有效防止由于网络加深而导致的梯度消失问题, DPN能将两种结构相结合. 由于分类器要处理的特征向量较大, DPN使得模型能使用更多的层以更平缓的方式进行特征收缩, 相比于更激进、 更快速的收缩, 本文采用的方式有效减少了特征的损失. 同时, 由于残差结构的加入, 模型的可训练参数被控制在合理范围内, 对加速训练过程和防止过拟合也有一定的意义. 图3为网络结构, 图中矩形高度和宽度的变化分别表示特征张量的尺寸和通道数. 在4个DPN层中分别使用了3层、 4层、 20层和3层的DPN块, 最后通过最大池化层和全连接线性层输出二分类结果.

图3 网络结构
3.3 损失函数
由于本文采用两阶段的模型方案, 因此损失函数由两部分组成: 回归损失和分类损失. 其中回归损失用于训练检测器, 而分类损失用于训练分类器.


(2)
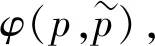
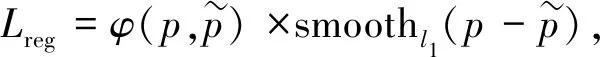
(3)
其中smoothl1函数定义为

(4)

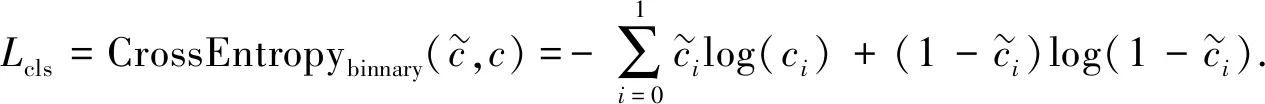
(5)
在回归损失和分类损失的基础上将总损失定义为
Ltotal=αLcls+Lreg,
(6)
其中α为权重系数, 在实验中取α=0.5.
3.4 算法流程
用于肺结节检测和分类的两阶段深度学习方法的算法流程如图4所示. 数据集经过预处理后, 构成(数据,标签)的形式. 其中, 数据为边长512像素的立方体数据, 标签中标识有结节的位置、 尺寸和良恶性. 训练阶段, 通过随机采样获取边长为96像素的立方体作为训练样本, 在测试阶段, 通过步长为4的密集采样获取相同尺寸的样本. 检测网络能根据输入的样本给出其中候选结节的位置、 置信度和语义信息. 在训练阶段, 检测网络的输出用于参与回归损失的计算, 分类网络的输入通过标签中的位置和尺寸信息完成采样, 而在测试阶段, 使用检测网络输出的候选结节位置进行采样, 并使用语义信息进行掩码处理, 以便充分利用原始数据的特征信息. 最后, 经过空间金字塔池化, 统一维度的特征信息被输入到分类网络, 得到良恶性的分类结果.

图4 训练和测试阶段的算法流程
4 实 验
本文采用LUNA16数据集进行训练和测试. LUNA16共有888个CT序列, 实际上是一个更大的数据集LIDC-IDRI的子集, 本文在训练和测试中使用LUNA16数据集的CT数据和标签以及对应的LIDC-IDRI标签. 888张CT中, 共有36 378个结节被标出, 在LUNA16数据集中, 只有直径>3 mm的结节作为样本, 直径<3 mm的结节和非结节都不选入, 而直径<3 mm的结节有11 509个, 非结节区域有19 004个, 剩余5 765个. 此外, 若两个结节的中心距离小于半径之和, 则对这两个结节进行合并, 合并的中心和半径是两个结节的均值. 经过上述处理, 剩余2 290个结节. 结节的恶性程度标注来自4位专家, 对于每个结节, 给出标注的专家可能是1~4个, 标注的方式是给出一个[1,5]的整数表示恶性程度, 本文对该值取平均值, 排除所有等于3 mm的情况, 小于3 mm的认为是良性结节, 大于3 mm的认为是恶性结节. 最终有1 186个结节进入训练集.
将筛选得到的数据通过沿3个轴反转和随机选取4×4×4大小的区域填充为水的CT值170 HU的方式进行数据扩充. 采用随机梯度下降进行训练, 动量参数设置为0.9, batch size=16, 学习率初始化为0.1, 每经过70个epoch(使用所有数据训练一次称为一个epoch)将学习率调整为原来的1/10, 网络在训练200个epoch时收敛.
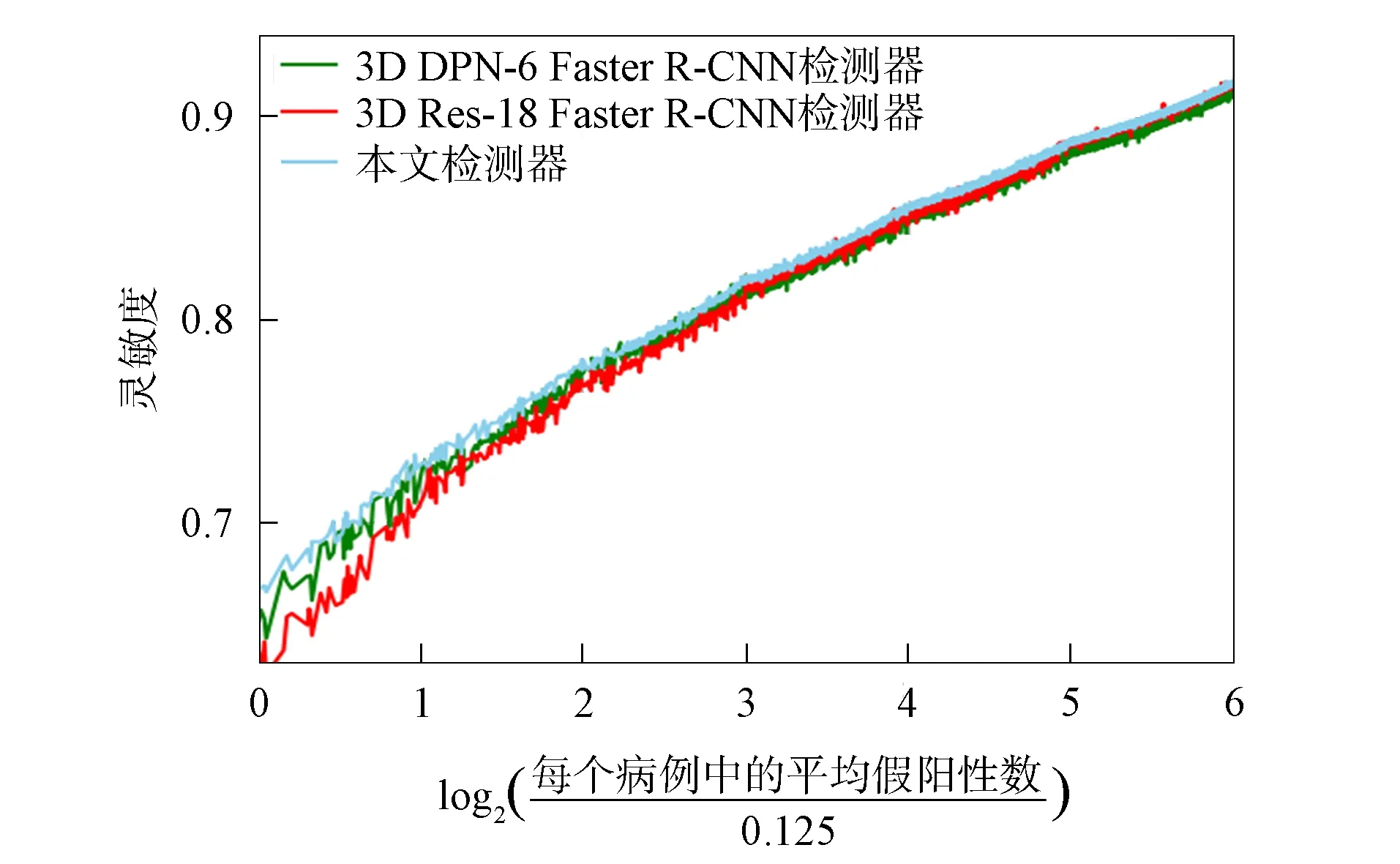
图5 灵敏度曲线
为衡量检测器的性能, 将本文的检测器与3D DPN-26 Faster R-CNN和3D Res-18 Faster R-CN[16]检测器进行对比实验. 对比指标采用LUNA16数据集的官方评价标准, 即无限接收特性曲线(free-response receiver operating characteristic curves, FROC). 图5为假阳性率为0.125,0.25,0.5,1,4,8时的灵敏度. 由图5可见, 本文检测器的性能优于作为比较基线的检测器, 并且本文检测器具有更少的可训练参数(3D DPN-26 Faster R-CNN检测器有超过9×107的可训练参数, 而本文检测器只有不到2×106的可训练参数), 能更快地训练.
表1列出了不同网络模型对LUNA16中结节的分类结果. 由表1可见: 由于充分利用了CT的三维信息, 3D结构的模型要优于2D结构的模型, 使用3D DPN对结节图像进行分类取得了比多尺度CNN(卷积神经网络)[25],2D CNN,3D CNN以及更高的分类准确率; 本文提出的模型中使用空间金字塔池化对不同尺度的候选结节进行尺度统一, 并利用检测器的输出对分类器的输入进行处理, 且由于DPN的特性, 本文分类器能以更合理的速度进行维度收缩, 从而提升了分类的效果.

表1 不同网络模型对LUNA16上的结节分类准确率
本文还与LIDC-IDRI数据集中4名医生的标注结果进行了对比, 选取所有被4名医生标注的测试数据. 对于一个样本, 4名医生会对其恶性程度给出1~5的评分, 本文对4名医生的评分进行平均, 将平均结果作为真实值, 剔除平均结果为3的样本, 平均值在3以上的视为恶性, 否则视为良性. 如果一个医生给出的良恶性结果与真实值不符, 则认为这名医生对该样本给出了错误标注. 根据以上原则, 统计出4名医生在测试集上的分类准确率, 并进行对比实验, 对比结果列于表2.

表2 分类准确率(%)对比
本文的分类器输出二分类结果, 对于良性和恶性, 分别给出分类概率, 采用大于50%的类别作为最终分类结果. 表3列出了预测概率占总体数据的比例. 由表3可见, 63.92%的样本能给出接近0或1的分类结果, 表明模型受到了有效的训练, 分类效果明确.
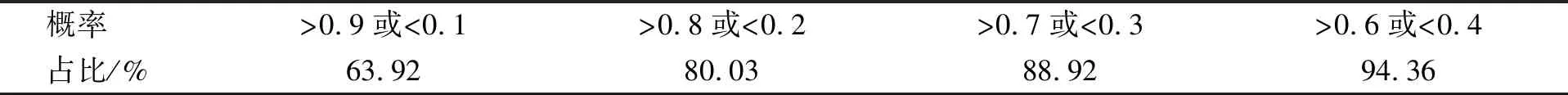
表3 预测概率占总体数据的比例
综上所述, 本文提出了一种用于肺部CT图像中肺结节检测和分类的深度学习模型, 使用两阶段方法, 先使用基于U-Net的三维卷积网络进行结节的检测, 得到候选结节的语义信息和位置信息, 再根据检测结果对原始数据进行处理, 使用空间金字塔池化进行多尺度操作, 然后使用基于DPN的分类器进行分类, 最后给出良恶性分类结果. 在LUNA16数据集上对肺结节检测和分类模型进行测试的结果表明, 本文方法准确度较高.
