基于人工智能的跨媒体感知与分析技术研究*
2020-03-25张正强张家亮周世杰刘建新
李 斌,张正强,张家亮,周世杰,刘建新
(1.成都三零凯天通信实业有限公司,四川 成都 610041;2.电子科技大学,四川 成都 610054)
0 引 言
随着新媒体技术的飞速发展,媒体广泛存在于互联网、广播电视以及视频监控等各个领域。跨媒体既表现为包括文本、语音、图像以及视频等混合介质形态,又表现为跨越不同媒介的传播和表达方式,还表现为覆盖网络空间和物理空间的媒体融合的复杂关联关系[1]。如何从形态多样、分布广泛、关系复杂的海量跨媒体资源中快速获取和准确表达有价值的知识,已成为亟待解决的问题。
为抢抓人工智能发展的重大战略机遇,加快建设创新型国家和世界科技强国,国务院在2017年发布了《新一代人工智能发展规划》(国发〔2017〕35号)[2],其中16次提到跨媒体相关内容,包括“跨媒体协同”“跨媒体智能”“跨媒体感知计算”等,充分表明跨媒体感知与分析已经成为新一代人工智能应用的重要领域。人工智能技术为跨越文本、语音、图像以及视频的媒体知识表征,跨越时间和空间的媒体分析推理,为形成涵盖数十亿实体规模的多源、多学科和多数据类型的跨媒体智能应用指出了方向。
1 跨媒体智能感知与分析技术
1.1 跨媒体智能感知技术
1.1.1 并行文本数据采集与感知
文本数据源大规模并行采集技术针对全球的开放数据源,包括主流媒体与自媒体(如国内的微信、微博、知乎,国外的Twitter、Facebook等)的多语种文本数据进行分布式、实时化和增量化采集。
1.1.2 多通道视频数据爬取与感知
多通道分布式爬取技术针对种子地址URL进行多通道建立,包括登录验证、DNS解析缓存、打码、解析以及下载等,实现互联网海量视图像数据的分布式集群采集。大规模视频流拉取技术对主流视频监控厂商的终端接入方式、流媒体格式及解码技术等进行研究,实现在线视频码流拉取与解码。
1.1.3 跨媒体数据知识统一表征
深度神经网络在大数据分析中不断取得突破性成功,给跨媒体关联表征带来了新思路。针对不同的跨媒体数据表现形式,构建基于规则的知识图谱,使用统一的结构化数据进行表征学习,通过深度神经网络提取出高度抽象的特征,并基于此抽象特征进行跨媒体智能感知与分析任务。
1.2 跨媒体智能分析技术
1.2.1 文本语义分析
文本、语音以及音乐等时序数据通过深度神经网络模型,利用文本数值化表达、文本关键词提取、上下文关联信息获取、全文信息化检索、多语种语音识别和习惯性表达等,抽象形成基于神经网络的文本大数据,从而实现高效的语义识别。
1.2.2 视频内容理解
在不断累积的训练样本数据中抽取关键帧,将长视频分割为短视频或图像,对深度学习目标检测算法进行训练,形成视图像智能识别模型引擎,然后通过视频内容分段、内容归类、同主题跟踪等技术自动识别视图像数据,并生成视频内容类型属性(如色情、暴恐、政治有害等不良内容)[3]。
1.2.3 目标及场景识别
深层神经网络模型具有强大的特征提取能力、表达能力和泛化能力,可实现非约束场景下监控视频中的目标搜索和场景识别。以最常见的人脸识别为例,提取人脸的面部拓扑几何关系和深层特征表达,有效应对化妆整形、俯拍角度、戴口罩以及戴墨镜等局部遮挡和有效目标偏小、光照不足、分辨率低带来的环境干扰。
1.2.4 融合纠错的媒体要素标记
基于深度神经网络的卷积层级网络结构和回复式网络结构,充分挖掘媒体内部、媒体之间的多级关联关系,同时利用多任务学习框架平衡媒体内语义类别约束和媒体间成对相似性约束学习过程,发现媒体中存在的中断、突变、跳转以及翻转等错误,对跨媒体的媒体要素标记进行融合纠错。
2 技术体系设计
传统的多媒体处理技术已无法应对暴恐、欺诈、虚假新闻以及政治有害等不良内容通过文本、视频和图像进行肆意传播。为应对现实应用中产生的海量多媒体数据,迫切需要一种跨媒体技术体系能够使用相同的特征感知、处理和应用不同的媒体数据,并应用于舆情分析、新闻追踪、情报获取、预警预报以及远程教育等领域[3-4]。
整合文本和视图像感知与分析、跨媒体数据知识表征、跨媒体智能描述与检索、跨媒体知识挖掘与推理等技术,使技术体系具有跨媒体知识特征标记和关联展示能力、多种直观可视化呈现智能分析结果能力,核心在于跨媒体智能感知与分析平台设计[5],如图1所示。平台从架构方面设计,至下而上划分为基础设施层、跨媒体数据感知层、跨媒体数据分析层和应用展示层4层。平台从功能上设计,划分为网络空间媒体感知子系统、物理空间媒体感知子系统、跨媒体一体化智能分析子系统和跨媒体统一展示子系统4大子系统。
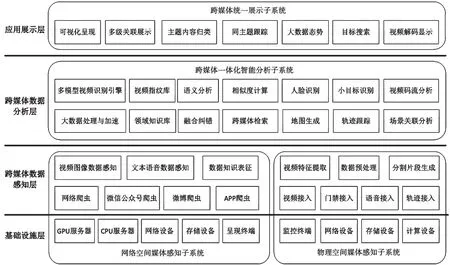
图1 跨媒体智能感知与分析平台设计
(1)网络空间媒体感知子系统:实现对网络空间尤其是互联网新媒体数据的获取和感知,包括针对不同信息源(如网站、APP、微信、微博等)的多通道建立和数据爬取,以及网络、存储、计算等硬件资源利用,并完成数据知识表征工作。
(2)物理空间媒体感知子系统:实现对物理空间尤其是视频监控系统数据的获取和感知,包括监控视频、门禁报警、车辆定位等基础设施数据接入,以及视频特征提取、视频结构化、轨迹生成等数据预处理任务。
(3)跨媒体一体化智能分析子系统:实现对网络空间和物理空间跨媒体数据的知识图谱构建和智能分析推理,包括多模型视图像识别引擎、视频指纹库、领域知识库、相似度计算、场景关联分析和视频码流分析等任务。
(4)跨媒体统一展示子系统:直接面向用户实现跨媒体数据的各类应用,包括态势呈现、内容归类、同主题跟踪、目标搜索、视频解码大屏幕显示以及人机交互界面等任务。
3 基于人工智能的技术实现
3.1 多通道网络数据爬取与感知
基于远程字典服务(Remote Dictionary Server,Redis)作为基础数据的分布式应用,扩展跨媒体数据内容获取的广度和深度,与分布式并行爬取技术进行融合,将数据采集从单纯的网页来源扩展到网站、APP、公众号、监控视频以及车辆轨迹等多通道订阅/发布。
面向频道的信息采集与感知。Redis可以实现客户端通过订阅需要的频道获取对应信息,一旦有新的信息出现,就会自动通过该频道发送到指定位置,适用于对实时性、完整性要求较高的媒体数据感知,如广播电台、有线电视以及视频监控等领域,如图2所示。
面向模式的信息爬取与感知。Redis可以通过模式匹配,不仅仅爬取已订阅频道的信息,更能够爬取与已订阅频道直接或间接关联的对应信息,还可以定制不同的爬取深度和广度,适用于分布广泛、信息零散的媒体数据感知,如网站、自媒体以及网购平台等媒体数据感知,如图3所示。

图2 面向频道的采集与感知

图3 面向模式的爬取与感知
3.2 基于长短时记忆网络的文本、语音数据分析
对于文本、语音等具有单一时间维度的多媒体数据,不仅需要提取时间维度上的特征,还要深度挖掘时序数据的上下文输入和依赖关系。双向长短时记忆网络(Bidirectional Long Short Term Memory,BiLSTM)是一种变种的长短时记忆(Long Short Term Memory,LSTM)网络模型。作为特殊的回复式神经网络,它通过前向LSTM与后向LSTM模块进行双向表达,能长时间记住上下文输入信息,实现长期记忆和后续任务预测。BiLSTM模型已在无约束手写识别、语音识别以及机器翻译等诸多领域取得重大成功,模型结构如图4所示。
设t时刻时序数据的向量表达为xt,前向和后向LSTM层的输出分别记为h_ ft,h_bt,则双向表达层在t时刻对时序数据xt的表达为yt=[h_ ft;h_bt]。
经过T个时刻对时序数据的特征提取,BiLSTM模型挖掘这段时间范围内上下文输入的相互依赖关系,捕获前后时序媒体数据的相关性特征,并从两个方向上排除噪声对神经网络模型的影响,提取出对跨媒体感知与分析至关重要的高层抽象特征。
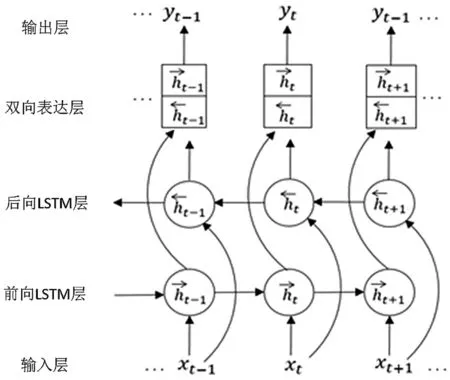
图4 用于时序数据识别的BiLSTM模型
3.3 基于卷积神经网络的图像、视频数据分析
对于图像、视频等具有二维/三维特征的多媒体数据,建立相应的卷积神经网络(Convolutional Neural Network,CNN)模型,通过局部特征感知全局特征,提取图像视频的高层抽象表达。采用3D卷积方法提取图像和短视频特征,长视频需要进行片段分割后处理,利用3D卷积网络提取出特征向量,送入LSTM进行序列识别,循环执行直至所有的图像、短视频全部识别完成,最终输出视图像分类结果[6]。CNN模型已在机器视觉、视图像处理领域有十分出色的表现,如图5所示。

图5 用于视图像分类的卷积神经网络模型
设x为某一张图像或一段短视频,wj与bj为卷积层的权值参数,f为一特定激活函数,当x经过卷积层时,将会执行卷积数学运算:

卷积数学运算提取的特征进一步执行池化操作,pooling为取最大值max()或平均average()等选择函数,最后获得图片的平移不变性:

经过多轮卷积层和池化层处理后,由1~2个全连接层和Softmax函数给出最后的分类结果。
3.4 基于知识图谱的跨媒体实体统一表征
通过跨媒体智能描述技术将语音、视频和轨迹等多媒体数据统一成实体世界中语义一致的文本数据,在文本描述基础上构建知识图谱,然后进一步分析知识图谱中的实体与属性,从而完成跨媒体知识挖掘与推理[4]。构建知识图谱需要把跨媒体数据从不同的数据源中抽取出来。结构化数据可以直接使用,非结构化数据需要通过自然语言处理技术进行结构化后使用。知识图谱构建的主要流程包括命名实体识别、关系抽取、实体统一表征以及指代消解等。
实体统一表征作为其中的关键环节,可以有效控制实体的种类和数量,还可以降低知识图谱的稀疏性。采用神经网络注意力机制抽取文本描述的实体,完成命名和属性设置,并使用BiLSTM进行编码,再通过递归神经网络视图像分类结果,提取文本中的实体关系,计算多个实体的语义匹配度来判断两个实体是否表示同一个对象,并决定生成独立实体或合并相似实体,从而实现实体统一表征。实现流程如图6所示。

图6 跨媒体实体统一表征流程
4 结 语
高文院士在《转向跨媒体智能》一文中提到“跨媒体智能是新一代人工智能的重要组成部分”[7],本文基于人工智能的深度学习方法符合人类大脑对跨媒体数据的认知规律,设计出一种覆盖物理空间和网络空间的跨媒体感知和分析技术体系,能够在海量多变的跨媒体数据中自动提取有价值的知识,研究成果已经在网络大数据情报分析平台、网络视听节目监测平台、重点场所违规行为预警系统等方面得到应用。实践证明,深度神经网络在特征提取以及多种媒体数据感知与分析方面具有强大的能力,跨媒体智能引擎也将会在网络空间内容安全与态势分析、跨时空协同感知和综合推理等领域发挥更加重要的作用。
