人工智能深度强化学习的原理与核心技术探究
2020-03-24吴英萍耿江涛
吴英萍 耿江涛


【摘 要】应用大数据技术的深度学习及深度强化学习是人工智能领域的一场革命,深度学习使强化学习能够处理以前难以解决的问题,取得了令人瞩目的进步,特别是在游戏和棋类竞技等领域都超过了人类的表现。本文介绍了强化学习的一般领域,然后介绍了基于价值和基于策略的方法和深度强化学习中的核心算法,进一步表现了深层神经网络融入强化学习的独特优势。
【关键词】强化学习;深度学习;深度强化学习;人工智能
引言
近期的人工智能(Artificial Intelligence, AI)研究为机器学习(Machine Learning,ML)提供了强大的技术。作为解决人工智能问题通用框架的强化学习(Reinforcement learning,RL)也与深度学习(Deep Learning,DL)相结合,产生的深度强化学习(Deep Reinforcement Learning,DRL)也在近年取得了令人兴奋的成就。
强化学习(RL)是关于一个智能体与环境相互作用,通过试验和错误的方法,为自然科学、社会科学和工程等领域的顺序决策问题学习一个最优策略。
强化学习和神经网络的整合有着悠久的历史。近期深度学习取得了令人振奋的成果,得益于大数据、强大计算力、新算法技术、成熟的软件包和架构以及强大的资金支持,强化学习也开始复兴,尤其是深层神经网络与强化学习的结合,即深度强化学习。
在过去的几年里,深度学习在游戏、机器人、自然语言处理等领域的强化学习中一直很流行,也取得了一些突破,比如Deep Q-network和AlphaGo;以及新颖的架构和应用,如可微神经计算机、异步方法、价值迭代网络、无监督强化和辅助学习、神经结构设计,机器翻译的双重学习、口语对话系统、信息提取、引导策略搜索和生成性对手模仿学习,进一步推动创新的核心要素和机制等。
为什么深度学习有助于强化学习取得如此巨大的成就?基于深度学习的表示学习通过梯度下降实现自动特征工程和端到端学习,从而大大减少甚至消除了对领域知识的依赖。特征工程过去是手工完成的,通常耗时、过多且不完整。深层次的分布式表示利用数据中因子的分层组合来对抗维度指数级爆炸的挑战。深层神经网络的通用性、表达性和灵活性使一些任务变得更容易或可能,例如,在上面谈到的突破和新的体系结构和应用。
深度学习作为机器学习的一个特定类别,并非没有局限性,例如,它是一个缺乏可解释性的黑匣子,没有清晰而充分的科学原理,没有人类的智慧,在某些任务上无法与婴儿竞争。因此,对于深度学习、机器学习和人工智能,还有很多探索性的工作要做。
深度学习和强化学习分别被选为2013年和2017年麻省理工学院技术评论十大突破性技术之一,将在实现人工通用智能方面发挥关键作用。AlphaGo的主要贡献者David Silver甚至提出了一个公式:人工智能=强化学习+深度学习。
1.深度學习
以下简要介绍机器学习和深度学习的概念和基本原理。
1.1机器学习
机器学习是从数据中学习并做出预测和决策。通常可分为监督学习、无监督学习和强化学习。
在监督学习中,使用标记的数据。分类和回归是两类监督学习研究的问题,分别是分类输出和数值输出。
无监督学习试图从没有标签的数据中提取信息,例如聚类和密度估计。表征学习是一种典型的无监督学习。表征学习寻找一种表示方法,以尽可能多地保留原始数据的信息,同时保持表示比原始数据更简单或更易访问,具有低维、稀疏和独立的表示。
强化学习使用评价性反馈,但没有监督信号。
机器学习基于概率论、统计和优化理论,是大数据、数据科学、预测建模、数据挖掘和信息检索的基础,并成为计算机视觉、自然语言处理和机器人技术等的重要组成部分。机器学习是人工智能(AI)的一个子集,并且正在发展成为人工智能各个领域的关键。
1.2深度学习
深度学习与浅层学习形成鲜明对比。对于许多机器学习算法,如线性回归、逻辑回归、支持向量机、决策树、boosting集成提升算法等,都有输入层和输出层,在训练前可以用人工特征工程对输入进行转换。在深度学习中,在输入和输出层之间,则有一个或多个隐藏层。在除输入层之外的每一层,都计算每个单元的输入,作为前一层单元的加权和;然后使用非线性变换或激活函数,如对数处理、三角函数处理或最近更流行的校正线性单元(Rectified Linear Unit, ReLU)应用于单元的输入,以获得输入的新表示从上一层开始。在各个层的单元之间的链接上标有权重。在计算从输入到输出后,在输出层和每个隐藏层,都可以向后计算误差导数,并向输入层反向传播梯度,从而更新权重以优化某些损失函数。
前向深层神经网络或多层感知器(Multi-Layer Perceptron, MLP)是将一组输入值映射到输出值,该数学函数由每一层的许多简单函数组成。卷积神经网络(Convolutional Neural Network, CNN)设计用于处理具有多个阵列的数据,如彩色图像、语言、音频频谱图和视频,受益于这些信号的特性:局部连接、共享权重、池和多层的使用,并受到视觉神经科学中简单细胞和复杂细胞的启发。残差网络(Residual Networks, ResNets)旨在通过添加快捷连接来学习参考层输入的残差函数来简化深层神经网络的训练。为解决这些问题,提出了长短时记忆网络(Long Short Term Memory networks, LSTM)和门控递归单元(Gated Recurrent Unit, GRU),并通过门控机制通过递归细胞操纵信息。
2.强化学习与深度强化学习
为了更好地理解深度强化学习,首先要对强化学习有一个很好的理解。以下简要介绍强化学习的背景,并介绍值函数、时间差分学习、函数逼近、策略优化、深度强化学习等术语。
2.1问题背景
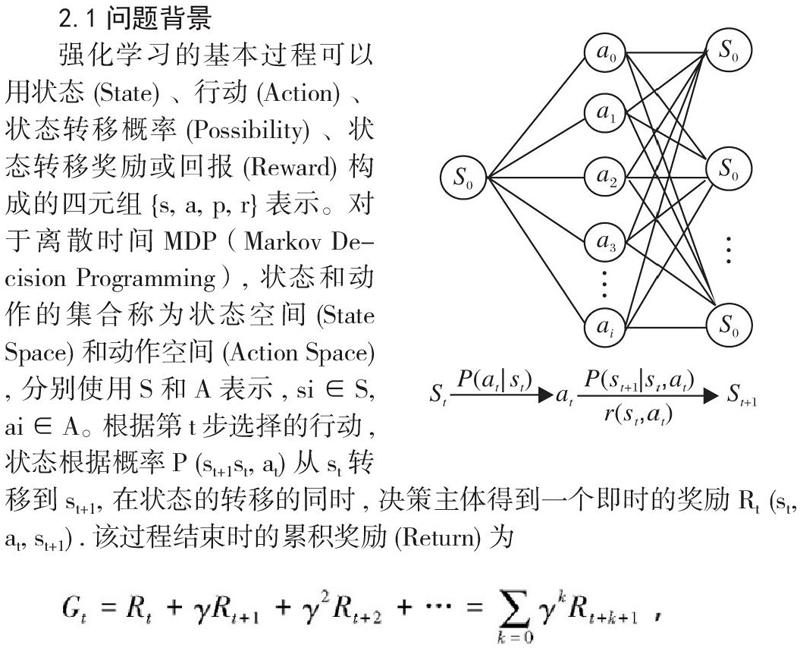
强化学习的基本过程可以用状态 (State) 、行动 (Action) 、状态转移概率 (Possibility) 、状态转移奖励或回报 (Reward) 构成的四元组{s, a, p, r}表示。对于离散时间MDP(Markov Decision Programming), 状态和动作的集合称为状态空间 (State Space) 和动作空间 (Action Space) , 分别使用S和A表示, si∈S, ai∈A。根据第t步选择的行动, 状态根据概率P (st+1st, at) 从st转移到st+1, 在状态的转移的同时, 决策主体得到一个即时的奖励Rt (st, at, st+1) .该过程结束时的累积奖励 (Return) 为
其中, γ∈(0,1]为折扣因子。该智能体决策的目标是使每个状态下的这种累计奖励的期望值最大化。问题设定为离散状态和动作空间,但很容易将其扩展到连续空间。
2.2探索与应用
探索(Exploration)是使用多种探索技术找到关于环境的更多信息。
应用(Exploitation)是利用已知信息应用多种手段来得到最多的奖励。
2.3值函数
值函数是对预期的、累积的、折扣的、未来奖励的预测,用于衡量每个状态或状态行动对的好坏。
状态值vπ (s) = E[Rt|st = s] 是指从状态s出发,按照策略函数π (a|s)采取动作a的状态期望值。
最优状态值 v*(s) = maxπ vπ (s) = maxa qπ* (s, a) 是采用行动策略函数π对状态s所能达到的最大状态值。
行动值qπ (s, a) = E[Rt|st = s, at = a] 是指在状态s中选择行动a,然后遵循策略函数π的奖励期望值。
最优行动值函数q*(s, a) = maxπ qπ (s, a)是状态s和行动a的任何策略所能达到的最大行动值,使用π*表示最优策略。
2.4时间差分学习
当强化学习问题满足马尔科夫性质,即未来状态只取决于当前状态和行动,而不取决于过去时,将其表述为马尔科夫决策过程(Markov Decision Process, MDP),由5元组(S, A, P, R, γ)定义。当有系统模型时,采用动态编程方法:策略评估来计算策略的价值/行动价值函数,价值迭代和策略迭代来寻找最优策略。当没有模型时,则采用强化学习方法。当有模型时,强化学习方法也能发挥作用。
时间差分(Temporal Difference, TD)学习是强化学习的核心。时间差分学习通常是指值函数评价的学习方法。Q-learning也被认为是时差学习。
TD学习以无模型、在线、完全增量的方式,直接从TD误差的經验中学习价值函数V(s),并进行引导。TD学习是一个预测问题。迭代规则是:
V (s) ← V (s) + α[r + γV (st) -V (s)],
其中: α是学习率,而[r + γV (st) - V (s)] 称为TD误差。
引导方法和TD迭代规则一样,根据后续的估计来估计状态或动作值,这在强化学习中很常见,比如TD学习、Q学习、动作者-评判者算法。引导方法通常学习速度较快,并且可以实现在线和持续学习。
2.5函数逼近
当状态和/或动作空间很大、很复杂或连续时,函数近似是一种泛化的方法。函数逼近旨在从函数的实例中概括出一个函数,以构造出整个函数的一个近似值。这通常是监督学习中的一个概念,用于机器学习和统计曲线拟合等研究领域。函数逼近通常选择线性函数,部分原因是其理想的理论特性。
2.6深度强化学习
当使用深度神经网络来进行深度强化学习(deep reinforcement learning)时,就得到深度强化学习(deep RL)方法。此时,使用深度神经网络来近似逼近强化学习的值函数、策略和模型(状态转移函数和奖励函数)。
3.深度强化学习核心技术
强化学习智能体主要由值函数、策略和模型组成。探索与应用是强化学习的一个基本权衡。知识对强化学习至关重要。
3.1值函数
价值函数是强化学习中的一个基本概念,时间差分(Temporal Difference, TD)学习及其扩展Q-learning分别是学习状态和动作价值函数的经典算法。
Q-learning 算法伪代码如下:
然而,当动作值函数被类似神经网络的非线性函数逼近时,强化学习是不稳定甚至发散的。由此,提出了深度强化学习模型(Deep Q-Network, DQN)。DQN做出了以下重要贡献:利用经验重演和目标网络,稳定了用深层神经网络(CNN)进行动作值函数逼近的训练;设计了一种仅以像素和游戏分数为输入的端到端增强学习方法,从而只需要最小的领域知识;训练一个具有相同算法、网络架构和超参数的灵活网络,能够在许多不同的任务上表现出色,其性能优于以前的算法,性能与人类专业测试人员相当。
3.2策略
策略将状态映射到动作上,策略优化就是要找到一个最优映射。策略搜索法将策略参数化, 以累积回报的期望作为目标函数。
目标函数同时也是参数θ的函数, 原问题变成基于θ的最优化问题, 求解该优化问题的方法又称为策略梯度法。
相对而言,值函数Q-learning算法更有效率,而策略梯度法则是稳定收敛的。
异步动作者-评判者算法 (Asynchronous Actor Critic, A3C)同时学习策略和状态值函数,值函数用于引导,即从后续估计中更新状态,以减少方差和加快学习速度。
在A3C中,并行动作参与者采用不同的探索策略来稳定训练,从而避免了经验重演。与大多数深度学习算法不同,异步方法可以在单个多核CPU上运行。对于Atari游戏,A3C运行速度快得多,但表现优于DQN、D-DQN和优先D-DQN。A3C还成功地解决了连续的电机控制问题:TORCS赛车游戏和MujoCo物理操作和移动,以及迷宫,一个使用视觉输入的随机3D迷宫导航任务,在这个任务中,每一个新的场景中,每个智能体都将面对一个新的迷宫,因此它需要学习一个探索随机迷宫的一般策略。
3.3奖励
奖励为增强学习智能体提供评估性的反馈以做出决策。奖励可能是稀疏的,因此对学习算法是有挑战性的,例如,在计算机围棋中,奖励发生在游戏结束时。有无监督的方式来利用環境信号。奖励函数是奖励的数学公式。奖励形成是指在保持最优策略的同时,修改奖励函数,以促进学习。奖励功能可能不适用于某些增强学习问题。
在模仿学习中,智能体通过专家演示学习执行任务,从专家那里获取轨迹样本,不需要强化信号,也不需要训练时专家提供额外的数据;模仿学习的两种主要方法是行为克隆和逆强化学习。行为克隆,或称学徒学习,或示范学习,被定义为一个有监督的学习问题,用于将状态-行为对从专家轨迹映射到政策,而无需学习奖励函数。逆强化学习(Inverse Reinforcement Learning IRL)是在观察到最优行为的情况下确定奖励函数的问题,通过IRL探讨学徒制学习。
(1)从示范中学习。
深度Q-示范学习(Deep Q-learning from Demonstrations, DQfD),试图通过利用示范数据,结合时间差分(TD)、监督损失和正则化损失来加速学习。在这种方法中,示范数据没有奖励信号,但Q学习中有奖励信号。有监督的大边际分类损失使从学习值函数导出的策略能够模仿演示者;TD损失使值函数根据Bellman方程有效,并进一步用于强化学习;网络权重和偏差的正则化损失函数可防止过度拟合小型演示数据集。在预训练阶段,DQfD只对演示数据进行训练,以获得模仿演示者的策略和用于持续学习RL的值函数。然后,DQfD自生成样本,并按一定比例与演示数据混合,得到训练数据。在Atari游戏中,DQfD通常比DQN具有更好的初始性能、更高的平均回报和更快的学习速度。
监督学习策略网络是从专家的行动中学习的,如同从演示中的学习一样,用结果初始化强化学习策略网络。
(2)生成性对抗性模仿学习。
在IRL中,智能体首先学习一个奖励函数,然后从中得到最优策略。许多IRL算法都有很高的时间复杂度,内环存在RL问题。生成性对抗性模仿学习算法,绕过中间IRL步骤,直接从数据中学习策略。生成性对抗训练是为了适应辨别器,定义专家行为的状态和行为的分布,以及生成器和策略。
生成性对抗模仿学习发现了一种策略,使得判别器DR无法区分遵循专家策略的状态和遵循仿真器策略的状态,从而迫使DR在所有情况下都取0.5,而在等式中无法区分。通过将两者都表示为深度神经网络,并通过反复对每一个进行梯度更新来找到一个最优解。DR可以通过监督学习来训练,数据集由当前的和专家的记录组成。对于一个固定的DR,寻找一个最优的DR。因此,这是一个以 -logDR(s)为奖励的策略优化问题。
(3)第三人称模仿学习。
上述模仿学习中,具有第一人称示范的局限性,因此可以从无监督的第三人称示范中学习,通过观察其他人实现目标来模仿人类的学习。
3.4模型与计划
模型是一个智能体对环境的表示,包括转移概率模型和奖励模型。通常假设奖励模型是已知的。无模型强化学习方法处理未知的动力学系统,但通常需要大量的样本,这对于实际的物理系统来说可能是昂贵的或难以获得的。基于模型的强化学习方法以数据高效的方式学习价值函数和/或策略,但存在模型辨识问题,估计的模型可能不精确,性能受到估计模型的限制。规划通常用模型来构造价值函数或策略,因此规划通常与基于模型的强化学习方法相关。
价值迭代网络(Value Iteration Networks,VIN),是一个完全可微的CNN规划模块,可用于近似值迭代算法,以学习计划,例如强化学习中的策略。与传统规划不同,车辆识别号是无模型的,其中奖励和转移概率是神经网络的一部分,因此可以避免系统辨识问题。利用反向传播技术可以对车辆识别码进行端到端的训练。价值迭代网络为强化学习问题设计了新的深层神经网络结构。
3.5探索
强化学习智能体通常使用探索来减少其对奖励函数和转移概率的不确定性。这种不确定性可以量化为置信区间或环境参数的后验概率,这些参数与其行动访问次数有关。使用基于计数的探索,强化学习智能体使用访问计数来指导其行为,以减少不确定性。然而,基于计数的方法在大型域中并不直接有用。内在动机方法建议探索令人惊讶的东西,典型的是在学习过程中基于预测误差的变化。内在动机方法并不像基于计数的方法那样需要马尔科夫属性和表格表示。状态空间上的密度模型pseudo count,通过引入信息增益,将基于计数的探索和内在动机统一起来,在基于计数的探索中与置信区间相关,在内在动机中与学习进度相关联。
另一种奖励探索技术,以避免以往奖励的无效、无方向的探索策略,如贪婪和熵正则化算法,并促进对区域的定向探索,其中当前策略下行动序列的对数概率低估了最终的奖励。未充分奖励的探索策略是由最优策略的重要性抽样而来,并结合模式寻优和均值寻优两个条件来权衡探索与应用。
3.6知识
知识对于深度强化学习的进一步发展至关重要。知识可以通过值函数、奖励、策略、模式、探索技术等多种方式融入强化学习。然而如何将知识融入强化学习仍然是一个很大的需要进一步研究的问题。
4.结语
深度强化学习方法推动了人工智能领域鼓舞人心的进步。目前深度强化学习的研究集中在表征学习和目标导向行为的研究上,克服了样本效率低下的明显问题,使深度强化学习能够有效的工作。
参考文献
[1]SILVER D, HUANG A, MADDISON C J, et al. Mastering the game of Go with deep neural networks and tree search [J]. Nature, 2016, 529(7587): 484-+.
[2]萬里鹏, 兰旭光, 张翰博, et al. 深度强化学习理论及其应用综述 [J]. 模式识别与人工智能, 2019, 32(01): 67-81.
[3]SILVER D, SCHRITTWIESER J, SIMONYAN K, et al. Mastering the game of Go without human knowledge [J]. Nature, 2017, 550(7676): 354-+.
[4]SILVER D, HUBERT T, SCHRITTWIESER J, et al. A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play [J]. Science, 2018, 362(6419): 1140-+.
[5]ARULKUMARAN K, DEISENROTH M P, BRUNDAGE M, et al. Deep Reinforcement Learning A brief survey [J]. Ieee Signal Processing Magazine, 2017, 34(6): 26-38.
[6]赵星宇,丁世飞. 深度强化学习研究综述 [J]. 计算机科学, 2018, 45(07): 1-6.
[7]唐平中,朱军,俞扬等. 动态不确定条件下的人工智能 [J]. 中国科学基金, 2018, 32(03): 266-70.
[8]孙路明,张少敏,姬涛等. 人工智能赋能的数据管理技术研究 [J]. 软件学报, 2020, 31(03): 600-19.
[9]刘全,翟建伟,章宗长等. 深度强化学习综述 [J]. 计算机学报, 2018, 41(01): 1-27.
基金项目:(1)广东省教育厅2019年度普通高校特色创新类项目(2019GKTSCX152); (2)广东省教育厅2018年度重点平台及科研项目特色创新项目(2018GWTSCX030);(3)广东省教育厅2018年度省高等职业教育教学质量与教学改革工程教育教学改革研究与实践项目(GDJG2019309);(4)广州涉外经济职业技术学院2020年校级质量工程重点项目(SWZL202001)。
作者简介:吴英萍(1982.10-),讲师,学士,广州涉外经济职业技术学院计算机应用与软件技术教研室专任教师。研究方向为软件技术,人工智能。
*通讯作者:耿江涛(1965.12-),教授,高级工程师,华南师范大学博士生,广州涉外经济职业技术学院教育研究院教授。研究方向为大数据应用技术,高职教育管理与国际化。
1.广州涉外经济职业技术学院 广东广州 510540
2.华南师范大学 广东广州 510631
