结合语义概念和双流特征模型的复杂事件检测
2020-03-24张建明黄伟康詹永照
张建明, 黄伟康, 詹永照
(江苏大学 计算机科学与通信工程学院, 江苏 镇江 212013)
随着互联网中视频数量的爆发式增长,视频类型趋于多元化,视频事件识别在视频点播、智能监控和视频挖掘等方面有着广泛的应用.视频事件识别是一种以检测为目标的检索任务,视频事件理解过程主要为以图像序列作为输入,抽取特征,将结果传入事件模型中使用,以确定是否发生了感兴趣的事件.视频事件的输出理解过程可能是对某一特定事件是否发生或对事件的总结.不同于传统的视频识别任务,如目标检测、场景识别和动作识别,此类任务所对应的数据集镜头相对单一,目标较少,基本不存在光线和噪声的影响.复杂视频事件场景目标更多变,如生日聚会视频中可能包含着“切蛋糕”、“吹蜡烛”、“唱生日歌”等多种场景,而每个场景又由不同的人和物构成.相应的视频检测识别方法可以分为传统方法和深度学习方法.
传统方法从原始数据中提取出模式和结构上的信息,依赖于从业人员的经验和直觉.起始阶段,研究人员从图像帧中应用颜色直方图和形状直方图进行特征提取,运用于均衡和比较两幅图像之间的全局差.随后,时空兴趣点运用拓展到了视频领域以提取帧内特征,进而聚类生成码本,最后训练分类器分类.传统事件检测方法多关注于视频低层语义信息,对视频中包含的丰富的静动态语义概念信息(如信息人物)、背景和行为交互没有充分利用.
近些年来,随着深度学习的火热,其在静态图像的识别、分割和检测上取得了巨大的成功.传统的检测方法也称作浅层学习方法,工作更注重于特征的设计;而深度学习方法则更注重于网络结构的设计和优化.基于深度学习的特征提取并非针对某一类视频设计,具有良好的普适性,区别于传统手工设计样本特征方法,其能从图像中自动获取特征,不受限于专业知识领域,极大地扩宽了应用领域.视频由一系列图像帧构成,因此深度学习方法也广泛应用于视频识别领域.单一的静态照片处理时一般视为二维矩阵,但简单地将视频处理为多帧图形进行识别忽略了视频中的时序信息.为了更好地利用视频中的时间信息,研究人员将视频帧视作三维图像,利用3D卷积神经网络模型从不同模态的图像中提取特征,在动作识别任务中取得了不错的效果.另一种方法是采用递归神经网络模型(recurrent neural network,RNN),RNN最主要的特征是隐状态,保留了帧与帧之间的绝大部分信息.长短时记忆网络(long short-term memory, LSTM)是RNN的改进,在RNN基础上加入了存储单元,具有长期记忆性,有效运用于复杂动态建模[1].此外,H. GAMMULLE等[2]采用多流深度融合框架以提取视频中的时空信息,在小数据集上取得了良好的效果.此外,通过模拟人眼视觉原理,在LSTM网络模型中加入关注区域的移动、缩放机制,使得模型能够学习到视频的关键区域信息,为视频识别开启了新的思路[3].
虽然深度学习在视频识别方向取得了一定进展,但复杂事件视频多为多个片段组成,视频目标和背景会存在遮挡的情况,小目标物体容易被忽视.虽然深度学习可以学习到视频中出现语义信息,但是利用深度学习方法需要大量的数据集进行训练,这些数据通常昂贵,并且获取耗时,现有包含复杂事件的视频数量远未能达到要求.因此如何最大化地利用现有数据中丰富的概念语义信息,建立更好的视频复杂事件分类模型有待解决.
为了解决以上问题,文中提出基于语义概念和双流特征模型融合的视频复杂事件检测方法,采用相应的概念探测器对视频帧进行概念检测,以生成优选概念子集,依据选取出的概念子集,构建出基于优选概念子集的视频事件分类器;同时构建光流图像和空间流序列的双流特征卷积神经网络模型和LSTM事件分析表达模型,进而将两流事件分析结果进行融合分类检测;最后两网络分析结果进行决策融合,并达到复杂事件视频识别的目的.
1 复杂事件检测框架
复杂事件学习框架如图1所示.识别框架主要分为如下两个部分.
第1部分为构建基于概念子集的事件分类器,针对训练集中的视频进行帧间采样后,采用颜色直方图的方法进行镜头分割,以镜头组方式分别进行动作和行为概念检测,以镜头帧方式进行场景和目标概念检测,对检测到的概念进行视频级概念得分统计,并针对每个事件优化生成概念子集.生成适当概念子集后,将输入视频与事件对应概念子集进行相似度计算,得到基于语义概念的事件检测器的输出得分.
第2部分为构建双流特征权重融合事件分类器.将视频帧和光流图像分别进行空间流特征提取和时间流特征提取,之后输入到长LSTM网络中进行长时间建模,得到双流特征权重融合事件检测器.
最后将两检测器结果进行决策融合得到最终的事件分类器.
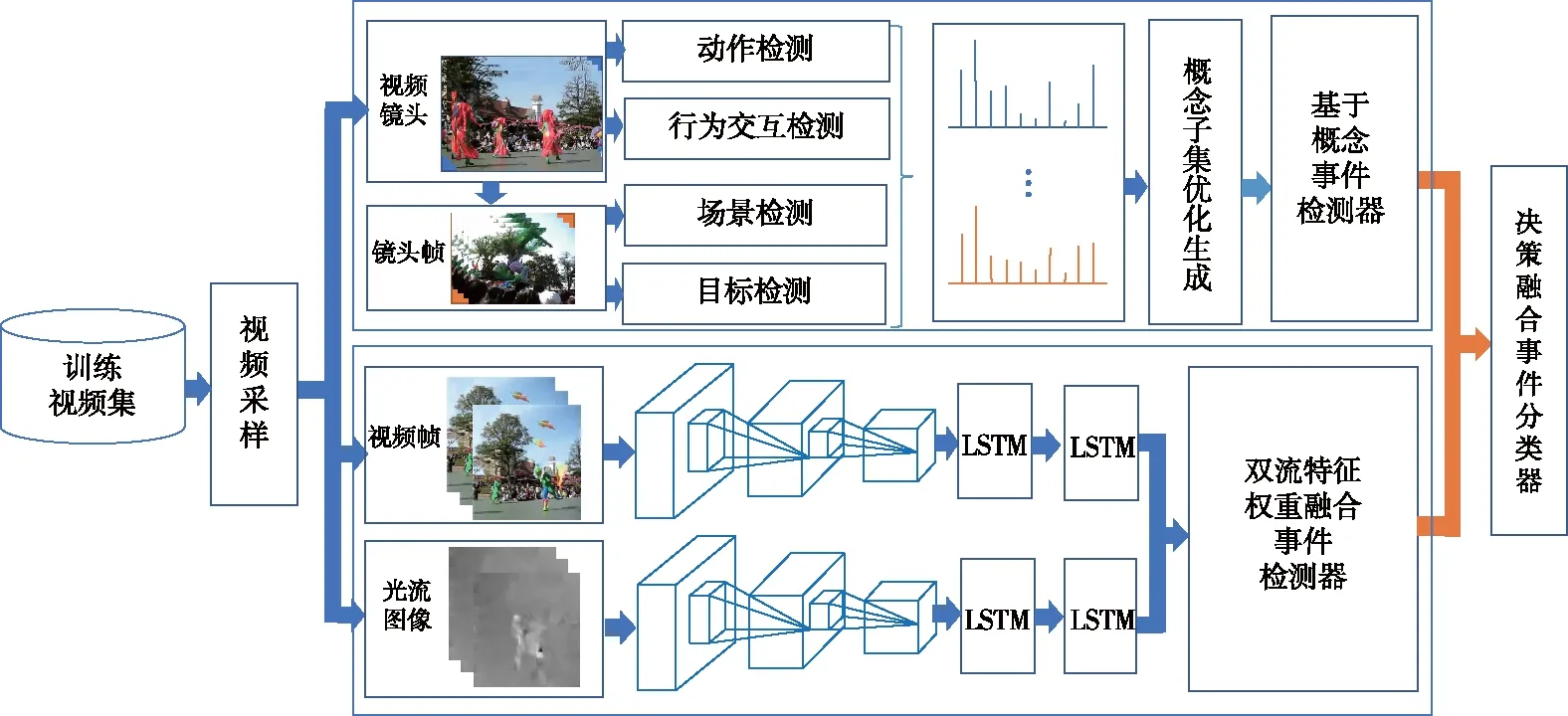
图1 复杂事件学习框架
1.1 基于语义概念的事件检测
文中将从3个角度探究如何优选生成概念子集,即如何创建最适合表示事件的概念探测器,如何总结出视频级概念得分与如何针对每个事件生成适当的概念子集.
1.1.1检测器选取
事件本质上是由包括人和物体在内的关键实体之间的相互作用来定义的.通常而言,1个事件描述包含目标、场景、行为交互、视觉属性和非视觉属性5种不同的概念类型,但视觉属性一般为主观描述,比如“美丽的”、“幸福的”之类的形容词,而非视觉属性难以检测,因此文中着重于前3种属性的研究.视频事件识别本质为处理分析出视频中所包含的这3种属性,从而判定事件的类别.在描述视频事件时,具有不同概括的术语,有些属于一般术语,涉及更广泛的概念,如“人”,而有些则为专业术语,具有明确的指向,如“警察”和“篮球运动员”,专业的术语更能有效地区分不同的事件,其包含的信息量越大.文中将在原有基础概念基础上,加入更深层次的概念,选用的概念子集从以下数据集中生成适当的集合,采用不同的方法训练生成概念探测器模型进行概念检测.这4个数据集与所采用的训练方式,如下所示:
1) UCF101: 选取UCF101数据集作为动作检测的基本概念集,因为它在动作类的数量和各种动作种类之间是一个很好的折衷.该数据集包含101个动作类,每个类至少有100个视频剪辑,包括运动、乐器和人物交互等.整个数据集包含13 320个视频剪辑,每个操作类别分为25组.采用三维卷积网络进行训练,以考虑帧间的运动信息.网络中卷积核大小均为3×3×3,步长为1×1×1;池化核大小为2×2×2,步长为2×2×2.每次输入16张图片,大小为32×32.
2) TV-Interaction: TV-Interaction数据集包含从20多个不同电视节目收集的300个视频剪辑,包含4种互动行为,即晃手、击掌、拥抱和亲吻.针对该数据集,采用InceptionV3网络[4]进行训练.
3) Place365: Places365是Places2数据库的子集,拥有来自365个场景类别的约180万个图像数据集,包括不同类别的卧室或街道等,能有效地区分不同类别的场景背景.针对该数据,采用VGG[5]的卷积模型进行训练.
4) MS-COCO: MS-COCO是由微软创建的普通物体检测数据集,包括33万张图像.相比于SUN数据集类目较少,但MS-COCO数据集单幅图片中包含多目标对象,且物体大多非中心分布,拍摄角度多变,背景较复杂,且包含大量的边界框,更有利于获得的每个目标类别位于某特定场景的能力.为了获得更多样的识别结果,文中在该数据集基础上加入部分从网络收集的数据,并采用R-FCN(region-based fully convolutional networks)网络[6]进行训练.
1.1.2视频级概念分数生成
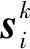
(1)
式中q为第k段所包含的帧数.因此,整段视频的预测得分为
(2)
图2为不同方法下视频级概念得分,可知采用取最大值的方法所得分数噪声较多,采用均值所得分数虽然能抑制噪声,但有用的概念得分被抑制,易导致识别效果不佳.文中所采用的基于镜头级别的混合选取方法具有较好的鲁棒性,能有效表示视频级得分.
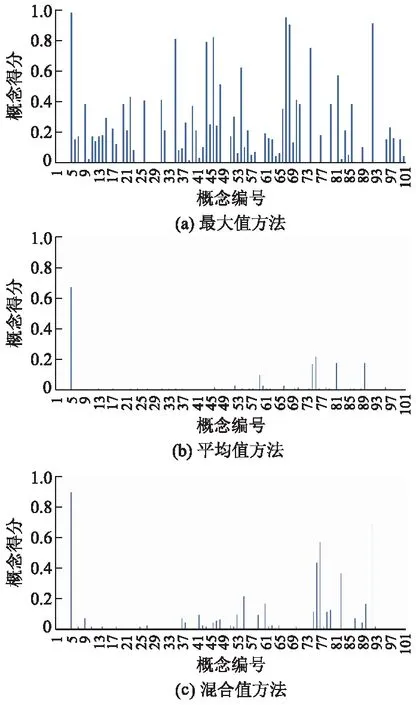
图2 不同方法下的视频级概念得分
1.1.3概念子集优化与事件检测
文中为每个事件构建合适的概念子集λ*,概念子集为对复杂事件的多样化描述,例如,描述一件事时,多分开表述为正面积极的关键词合集.使得每一个事件都有正确的概念子集相对应,是文中着力研究的点.在概念空间中,若概念子集用较少数量的概念进行事件表示容易受噪声的影响.换言之,采用更多的相关性概念去描述事件能有效提升识别结果.但试验证明,过多的概念会使得事件与概念子集之间更难匹配,相识度下降,从而导致识别结果不佳.通过人工筛选生成的方式费时费力,且容易忽视一些边缘概念,而这些概念通常具有较大的信息熵.文中希望能通过现有的视频训练集自动选择适当概念数量建立概念子集,以映射事件,保持最佳匹配来实现语义查询,它既可以从具有更多概念的表示中受益,又可以抵制不太相关甚至不相关概念的负面影响.
为每个事件生成优选概念子集,该问题的常见解法为蒙特卡洛模拟.但是当参数空间很大时,例如定义m个概念,那么就存在2m个组合,通过随机抽样很难找到最优解或良好的近似值.文中采用交叉熵解决优化问题.
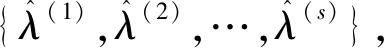
(3)
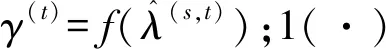
T次迭代后,依据θ(T)可得最优概念子集λ*.
以颜色值a*为自变量,分别以姜黄素、去甲氧基姜黄素、双去甲氧基姜黄素及总姜黄素含量作为因变量,得到模型3、4、5、6,回归分析结果见表7~9。
在得到的第i类事件最优概念子集λ*的基础上,形成概念类别向量ci,设输入视频的视频概念类别得分为c,则可得关于第i类事件的得分为
(4)
式中sim为度量相似度的函数.
1.2 基于双流特征融合的事件检测
为了提取空间和短期的运动特征,模型前期分为空间流特征提取和时间流特征提取.空间流建立在所采集提取的单帧上,这与基于卷积神经网络的图像分类方法相同,可以捕获到视频中的静态信息.时间流用于计算视频帧间的运动特征,作为时间流的输入,文中在每对相邻帧之间计算光流(位移矢量场),在位移矢量的水平分量和垂直分量形成两个光流图像,采用堆叠的光流图像作为输入.视频事件之间的时间联系较为紧密,长短时记忆网络是一种新型的递归神经网络,适合于处理和预测时间序列中间隔和延迟相对较长的重要事件,能够依据前文来预测之后内容,具有时序建模能力.文中在双流网络全连接层加入长短期记忆网络,先在双流网络中学习局部时空信息,之后将特征序列传入长短期记忆网络中获取全局时间信息,其中的每个时间单位的隐藏层将被传给下一层,以综合各个时间输出对于分类结果的影响.
设空间流网络提取到的特征为xs,经LSTM处理LLSTM可得到特征序列为
hs=LLSTM(xs).
(5)
可得复杂事件类别得分为
ys=Softmax(hs).
(6)
同理,时间流网络提取到的特征为xt,经LSTM所得特征序列为
ht=LLSTM(xt).
(7)
可得复杂事件类别得分为
yt=Softmax(ht).
(8)
在之后对双通道的Softmax层的输出进行平均融合,得到基于双流LSTM的事件检测输出得分为
(9)
1.3 决策融合事件分类
uj=ωjy1,j+(1-ωj)y2,j.
(10)
在此基础上,选择得分最高者所对应的事件类别作为测试视频类别,最终事件类别表达式为
(11)
2 试验与分析
2.1 详细试验
试验选用CCV[7]数据集以评估模型的有效性,CCV数据集包含从YouTube收集来的9 317个视频,其中4 659视频用作训练数据,另外4 658个视频用作测试数据,视频平均长度为80 s.该视频集包含多样的内容,仅有少量的文本标签和描述.视频集由20个语义类别组成,语义范畴包含诸如“棒球”、“游行”和“生日派对”之类的复杂事件.
在概念子集优选生成阶段,概念空间S中的概念设为590个;针对每个概念,迭代次数T取值50,每次迭代生成概念子集数n取1 000.φ(1)初始化为0.2,优选子集N设置为300.
构建双流长短时记忆模型中,针对输入的视频,每帧大小截取为224×224.对于特征提取网络结构,采用VGG[5]和CNNM[8]提取空间和短时运动特征.在双流网络后进行长时间建模,采用两层LSTM结构,每个LSTM底层有1 024个隐藏单元,第2层拥有512个隐藏单元.Dropout 是深度学习中防止过拟合的方法,通过在网络的某层节点中设置一个被消除的概率,在每一轮权值更新时从网络架构中随机将某些节点删除,从而降低模型复杂度LSTM 层都应用 Dropout 机制以改善性能.最终的决策融合选取权重过程中步长设为0.1.
2.2 试验结果
图3为利用语义概念模型生成的部分概念.
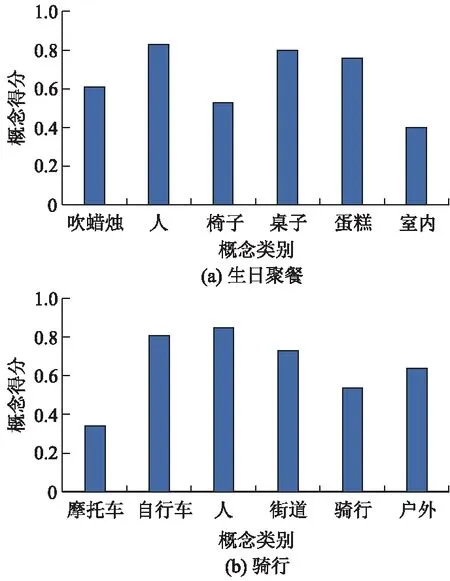
图3 语义概念模型所生成的部分概念
由图3可知这些概念在某种程度上都与事件有着高度相关,表明该方法能有效地选出适当概念以映射事件.试验可得出文献[9-12]中算法精确度分别为68.2%,70.6%,75.4%,75.6%;语义概念模型、双流特征模型、融合模型的精确度分别为39.7%,78.4%,81.1%.
针对提出的复杂视频事件识别框架,试验中采用平均精度计算每个事件类别得分,最后采用宏平均精度(macro average precision, MAP)作为评价标准.试验结果表明,采用双流特征模型能有效地对视频进行时序建模,相比采用SSLF与SIFT的传统算法,有了较大的提升,与现有深度学习模型相比,准确率也有显著的提升.采用文中提出的基于语义概念和双流特征模型融合方法,与单独采用双流特征网络相比,有3.74%的提升.试验表明,双流特征模型与语义概念模型相融合能有效利用语义信息,建立更好的视频事件分类模型.图4为CCV数据集每类的表现.
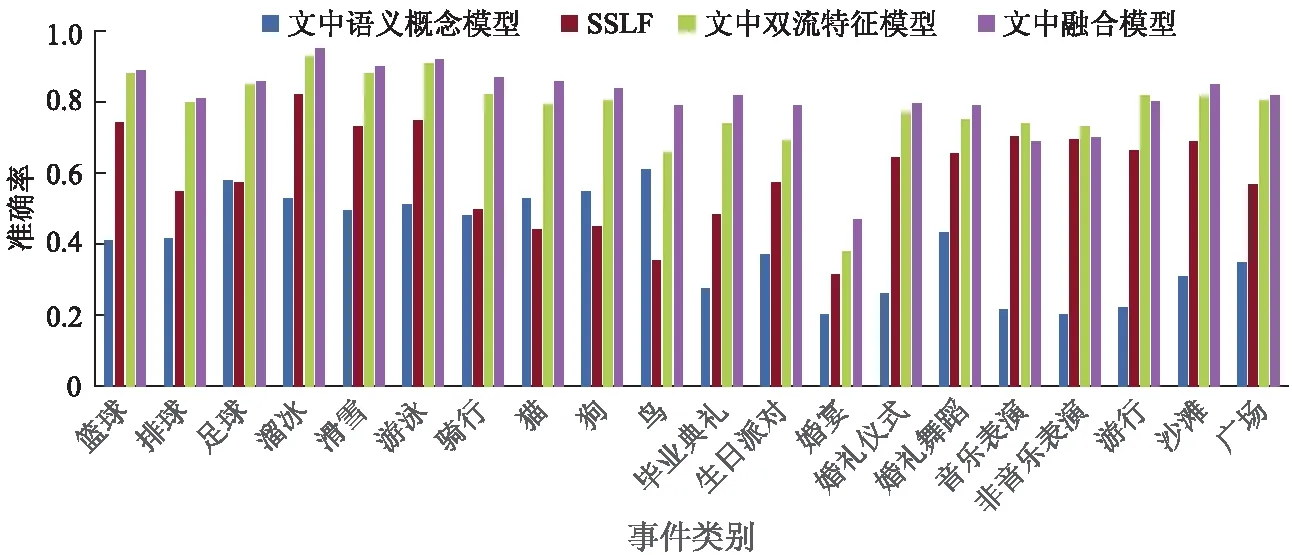
图4 CCV数据集每类表现
通过分析图4可知,语义概念模型能较好地识别出具有区别性概念的事件,但当事件之间比较相似时,识别率不佳.双流特征模型在与语义概念模型融合后,大部分事件的识别率得到了提升,但少许事件识别率没有改变或出现下降.分析如下:传统事件(如“篮球”、“滑冰”等)背景较为单一,行为区分度明显,视频训练集数量较多,双流长短时记忆模型能有效地对视频特征进行学习,加入概念后识别结果提升不太明显.而对于较复杂的事件,视频数量较少,因而深度神经网络识别效果一般,结合语义概念能在一定程度上识别效果.在“生日派对”、“婚礼”事件中,因视频帧存在具有区分度的概念(如“蛋糕”、“婚礼”等),识别率有所提升.但若视频清晰度不佳,目标物体存在遮挡,导致漏检或误检都会使得识别效果不佳.在部分事件中前景目标过多或动作幅度不明显,都易使得相应语义概念失效.一些概念虽然与感兴趣的事件相关,但该概念所携带的信息量不多,如“音乐表演”件中常出现的众人大合唱,概念检测探测到人出现在视频中,但该概念却普遍存在于其他事件,且该类视频难以用已有概念进行合理描述,因而对这类视频识别不够理想.
3 结 论
文中提出了基于语义概念和双流特征模型融合的视频复杂事件检测方法,相较于传统算法,避免了对大量训练样本的依赖;在典型复杂视频事件数据集上与其他算法进行对比测试,准确率达到了81.1%,为所有算法中最优,证实了所提方法能有效地利用视频中的语义概念信息,提升视频事件分析的准确性.
将事件分解成不同的概念,不仅在语义上可解释,而且有助于在视频库中按关键字检索视频.视频事件识别是一项具有挑战性的任务,文中没有考虑长视频计算量的问题,下一步可以在扩充概念空间和优化处理时间上进一步优化处理.
