基于卷积神经网络的注意力机制研究
2020-03-23王浩天
王浩天 王 璇
(重庆邮电大学通信与信息工程学院 重庆 400065)
引言
注意力机制对卷积神经网络的性能提升具有重要意义[1-2]。卷积神经网络通过多层的卷积—激活—池化操作提取图像中的深层特征,在各种图像识别、理解、生成任务中起到了至关重要的作用。然而,在一副图像中,有用信息出现的地方往往只占整幅图像的一小部分。注意力机制可以引导卷积神经网络去关注这些有用的信息而抑制其他非关键的信息。因此,加强注意力机制对卷积神经网络的研究是非常有意义的。
建立合理的注意力机制模型[3]对提升现有卷积神经网络的性能具有重要作用。现有的注意力机制已使卷积神经网络在诸多任务中的性能有所提升。然而,现有的注意力机制利用最大池化或平均池化对特征图进行压缩,该池化层因缺乏参数回传而在梯度下降的过程中不具备学习功能。这样存在一定的局限性:该池化层不能根据特征图来进行调整,从而导致特征图压缩不是最优的结果。因此,研究一个具有可以学习的池化层注意力机制的卷积神经网络是很有意义的。
一、具有可学习池化层的注意力机制
一般而言,卷积神经网络中的注意力机制分为通道注意力机制和空间注意力机制两种。通道注意力机制具有如下形式:

其中,Vpool是卷积神经网络某一层输出的特征图经过池化后得到的向量,大小为1*1*C。其中C是通道数。W1和b1是第一个全连接层的参数,大小分别为k*C和1*k,用来压缩通道数以减少计算量。为激活函数,一般为tanh或ReLU,W2和b2是第二个全连接层的参数,大小分别为C*k和1*C,用来将通道数恢复为C。σ将输出值限制在[0,1]之间,一般选用softmax函数或sigmoid函数。输出α的是大小为1*1*C的概率向量,第i个值代表第i个特征图的权重。
空间注意力机制具有如下形式:
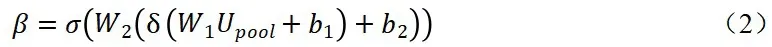
其中,Upool是将维度为H*W*C的特征图以某种方式池化为H*W*1之后的矩阵;W1和b1是第一个全连接层或卷积层的参数;W2和b2是第二个全连接层或卷积层的参数。δ与σ为激活函数,与空间注意力中的类似。输出的β是大小为H*W*1的概率矩阵,矩阵中的每一个位置都代表着对应特征图位置上的像素点的权重。
然而,在这两种注意力机制中,卷积神经网络的输出都是通过池化进行压缩,再作为全连接层和卷积层的输入。此过程会丢失信息且无参数可以学习,在一定程度上会造成其后的全连接层或卷积层学习到的注意力信息不为最优。但是,如果直接将之前的特征图展开进行输入,则会导致参数过多,容易发生过拟合现象。因此,本文提出一种利用卷积层代替池化层的方法,将特征图的池化过程变成一个可以学习的过程。
对于通道注意力机制而言,为了将特征图的空间特征压缩,我们首先把大小为H*W*C的特征图的大小变为1*C*(H*W),然后利用卷积核大小为1的卷积层将特征图的大小压缩为1*C*1,之后交换通道顺序得到大小为1*1*C的向量。这一步操作可以表示为:
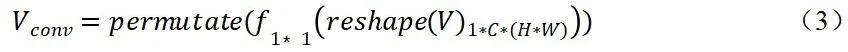
用代替即可得到可学习的向量。则改进后的通道注意力机制可以表示为:
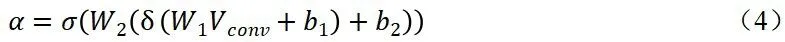
对于空间注意力机制而言,则可以使用全卷积神经网络改进。对于大小为H*W*C的特征图,可利用多层卷积将其降维为H*W*1的特征图,之后经过sigmoid函数将值压限在(0,1)之间。例如,可以先经过一个卷积核大小为1的卷积层将维数降为2,然后经过卷积核大小为7的卷积层输出H*W*1的特征图。该过程可以表示为:
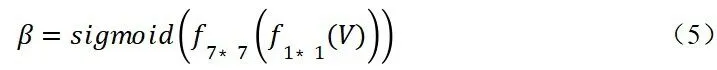
二、改进注意力机制效果分析
利用上述的改进方法对[4]中的卷积神经网络ResNet50-CBAM的通道注意力机制和空间注意力机制进行了改进,并在ImageNet-1k数据集上训练了100代。训练集和验证集的图像的最小边都被缩放到了256,并且在训练过程中仅使用对称和随机裁剪变换(RandomResizedCrop)进行数据增强。在验证时使用中心裁剪将图片大小变为224*244,得到的分类结果的top-1和top-5准确率如下:

表1 不同卷积神经网络在验证集上top-1和top-5的分类准确率
从表1可以看出,具有改进注意力机制的卷积神经网络得到的分类准确率相较于原先的神经网络具有一定的提升。这表明提出的改进方法是有效的。
三、结束语
本研究针对现有注意力机制中池化层不具有可学习参数的问题,通过使用具有可学习参数的卷积层替换池化层,使得网络可以学习如何压缩特征图以最优化注意力机制带来的效果。实验表明,相较于原来具有不可学习的池化层的注意力机制而言,本研究提出的改进注意力机制可以给卷积神经网络带来更好的分类效果。
