嵌入式软件编译时能耗演化优化算法①
2020-03-23姚万庆倪友聪肖如良
姚万庆, 倪友聪,2, 杜 欣, 叶 鹏, 肖如良
1(福建师范大学 数学与信息学院, 福州 350117)
2(福建师范大学 福建省公共服务大数据挖掘与应用工程技术研究中心, 福州 350117)
3(武汉纺织大学 数学与计算机学院, 武汉 430073)
能耗是嵌入式系统的关键质量属性.据报道[1], 在嵌入式系统中高达80%的能耗直接与软件执行活动密切相关.因而在电量受限的执行环境中, 降低嵌入式软件的能耗具有更为重要的价值和意义[2].通过选择一组最佳编译选项[3]在给定的执行平台下对嵌入式软件源代码进行编译, 可以获取能耗更低的可执行代码.与源代码重构[4]的能耗优化技术相比, 基于编译选项选择的优化不仅可以考虑硬件平台特性, 而且还能在不修改源代码的情况下保证功能语义一致性.因此, 编译选项的选择优化为降低嵌入式软件能耗提供了一种可行且有效的解决方案.
开源编译器GCC[5]已广泛用于嵌入式系统的开发.针对GCC 编译器的编译选项选择优化问题可描述为:对于源代码src 和执行平台platform, 搜索选项选择方案X = <x1, x2,···, xi···, xl> (xi∈{0,1}分别表示不选用或选用第i 号选项, l 为可用的选项数), 使得目标函数f(Sftsrc,X)的值最大.f 表示按X 的选项选择方案对src 进行编译和链接后得到的可执行代码在platform上从开始至结束运行所耗的电能, 较不选用任何选项的方案在能耗上的改进百分比.GCC 编译器虽已提供了若干标准优化等级用于降低可执行代码的执行时间和大小.但GCC 编译器没有提供专门针对能耗的优化等级.最近研究工作已显示了一些GCC 已有的优化等级甚至导致嵌入式软件能耗增大的情况[6,7].
近年来, 在能耗优化这一方面, GCC 编译选项的选择问题已成为一个热门的研究话题[3], 但仍面临两个公开挑战.一是GCC 编译器提供了大量的编译选项, 构成了庞大且离散的选择空间.例如针对Hoste 等[8]提出58 个常用于能耗优化的编译选项, 其对应的选择空间将高达258(大于1017).另一挑战是编译选项之间、编译选项与能耗之间存在着潜在的复杂影响, 给提高搜索效率和优化质量带来相当大的困难.一个编译选项的选用可能触发或使其它编译选项失效, 不同的编译选项对能耗所起的效用也不尽相同.目前已涌现出统计、机器学习和演化算法等3 类基于GCC 编译选项选择的嵌入式软件能耗优化方法.
统计方法[2]使用部分析因实验设计技术搜索编译选项的选择空间.正交数组被用于定义实验组和控制组, 通过曼-惠特尼检验或克鲁斯凯-沃利斯统计检验以观测能耗是否发生显著变化, 进而确定选用或不选用的选项.统计方法不仅难以识别任意多个编译选项之间的影响, 而且受限于搜索空间也难以找到最优的编译选项组.机器学习方法[3,9], 通过构建预测模型以帮助GCC 编译器或优化算法搜索出最佳编译选项组.构建预测模型分为收集训练样本和建立预测模型两个阶段.收集训练样本阶段是一个迭代过程: 在每个迭代步中, 首先选择一个嵌入式软件并计算其特征的值; 接着基于一定策略在选项选择空间中采样获得多个选项组;再利用一个选项组对所选择的嵌入式软件进行编译,并通过执行获取能耗值.基于软件的特征值、选项组和能耗值可构建出一个训练样本.利用收集的训练样本集, 建模阶段则根据选用的机器学习算法[9]构建相应的预测模型.为了增加嵌入式软件特征的有用性, 静态[10]、动态[11]和混合[12]等方法被用于确定具体的特征.然而机器学习方法的训练样本往往针对特定编译器版本和特定执行平台, 所构建的预测模型可移植性差.另外, 受制于选项的采样空间, 机器学习方法也难以获取高质量的优化结果.
为了搜索更大的编译选项选择空间, 提高能耗优化的质量, 一些演化优化算法也被纷纷提出.基因加权的遗传算法GWGA[13]将权值关联到每个基因位, 用于刻画相应的编译选项对优化目标的重要性, 并在优化过程中进行更新.与一元分布评估算法UMDA 类似,GWGA 仅考虑最优解中每个选项被选用的概率分布.GWGA 虽能一定程度地加快收敛速度, 但因没有考虑各个选项之间存在相互影响关系, 容易导致陷入局部最优.Tree-EDA[14]运用概率树模型捕获任意两个编译选项之间的影响, 能得到比遗传算法(GA)、GWGA和UMDA 更好的解质量.为了考虑多个编译选项之间潜在的影响, 我们提出了基于频繁模式挖掘的遗传算法GA-FP[15].GA-FP 在演化过程中将相对于未优化前有改进效果的个体信息(包括选用的选项编号和获得的能耗改进)存入全局事务表, 并在每代种群演化结束后基于全局事务表挖掘频繁选项模式集, 接着利用频繁选项模式集中各个选项的能耗标注作为启发式信息设计了“增添”和“删减”两种单点变异算子, 进而得到了比Tree-EDA 更好的解质量和收敛速度.
然而, GA-FP 算法还存在一些不足: (1)在演化过程中始终固定以优化前能耗值作为参考点来判断个体是否有改进, 并将有改进效果的个体信息存入全局事务表中, 容易导致事务表规模过大、存储效率不高的问题.(2)基于全局事务表挖掘频繁选项模式, 不仅存在挖掘时间长的问题, 而且挖掘出的频繁选项模式也难以体现较好的时效性.此外, 挖掘出的频繁选项模式仅给出单个频繁选项的能耗标注, 而多个频繁选项同时选用的次数和能耗标注也未予考虑.(3) “增添”和“删减”变异操作虽能充分利用单个频繁选项的能耗标注所体现的启发式信息进行单点变异, 但仍没有完全利用多个频繁选项同时选用的次数和能耗标注等启发式信息, 潜在地影响到解质量和收敛速度.针对上述问题, 文中提出一种嵌入式软件编译时能耗演化优化算法GA-MFPM.GA-MFPM 借助逐代替换参考点和事务表的机制以降低事务表大小; 在此基础上提出可获取更多启发式信息的繁编译选项挖掘算法, 并采用逐代挖掘的策略有利于保持频繁选项模式的时效性; 进一步设计最大频繁模式匹配算法进行多点变异, 以提高优化质量和收敛速度.通过与GA-FP 在5 个不同领域的8 个典型案例下实验对比的结果表明: GA-MFPM 获取了较GA-FP 更低的软件能耗(平均降低2.4%, 最高降低 16.1%)和更快的收敛速度(平均加快57.6%, 最高加快97.5%).
1 GA-MFPM 算法总体流程
GA-MFPM 算法用于求解针对GCC 编译器并用于嵌入式软件能耗优化的编译选项选择问题.其总体流程(算法1)与遗传算法GA[16]类似.但不同之处在于, GA-MFPM 算法在演化过程中需构建和更新带能耗改进标注的事务表TTE(the Transaction Table with Energe annotations of options)、挖掘和更新带能耗改进标注频繁模式集表TPSFOE+(the Table of Pattern Set of Frequent Options with Energy annotations), 并基于TPSFOE+进行多点变异.下面对它们作一简要介绍.

(1) 带能耗改进标注事务表的构建和更新
GA-MFPM 算法利用每代种群中优势个体的信息构造事务表, 并逐代更新事务表.
在构造事务表时, 首先按适应度值f(Sftsrc, X)(能耗改进百分比)从小到大对种群中各个体X 进行排序; 然后将适应度值等于或高于设定参考点值refVal 的个体作为优势个体, 并把这些个体的信息存入事务表.GAMFPM 算法借鉴了多数EDA[17]中优势个体在种群中的占比, 将refVal 设定为种群中各个体适应度值的中值.算法1 第4 行构建初始事务表.下面通过一个例子阐述事务表的构建方法.
例中, 初始种群各个体适应度的中值为8%, 即参考点值refVal=8%.初始种群中有5 个个体的适应度值等于或大于refVal, 现以其中的一个个体X, 其适应度的值f(Sftsrc, X)=10%为例说明一条事务的构建.从图1所示的个体X 可知其选用8 个选项, 其编号为: {1, 2,3, 6, 12, 13, 15, 16}.依据这些选用的选项及其出现次数, 并将个体X 的适应度值作为能耗标注附加于每个选用的选项, 可分别构建8 个三元组(选用选项, 出现次数, 能耗标注), 如表1 中第2 行的事务.类似地, 利用其它4 个优势个体可分别构建4 条事务, 进而获得表1 所示的初始事务表.

图1 个体X

表1 带能耗标注的选项事务表TTE 的例子
GA-MFPM 算法在每代演化中对事务表进行更新,如算法1 中第14 行和15 行.与对比算法GA-FP 在演化过程中始终固定以优化前能耗值作为参考点不同,GA-MFPM 在演化过程中逐代替换参考点和事务表的机制有利于依据优势种群降低事务表大小.
(2)带能耗改进标注频繁模式集表的挖掘和更新
算法1 第5 行挖掘获取初始频繁选项模式集表TPSFOE+, 而算法1 第17 行至第18 行完成在每代对模式集表TPSFOE+的更新.TPSFOE+的具体挖掘方法将在第2 节予以详细阐述.相比于GA-FP, GA-MFPM 在当前代事务表中挖掘出的频繁选项模式可较好地保持频繁选项模式的时效性.
(3)启发式多点变异方法
算法1 的第11 行给出了基于模式集表TPSFOE+并通过设计的最大匹配算法对个体Xk进行多点变异.较GA-FP 的单点启发式变异, GA-MFPM 的多点变异方法有利于提高收敛速度.最大频繁模式匹配帮助的多点变异将在第3 节进行重点阐述.
2 挖掘带能耗标注的频繁选项模式集
下面先阐述带能耗改进频繁选项模式树FPE的构建, 然后给出挖掘带能耗改进标注频繁选项模式相关的定义, 最后结合例子描述带能耗标注频繁选项模式的挖掘算法FPE-growth+.
2.1 带能耗改进频繁选项模式树FPE 的构建
GA-MFPM 中FPE树的数据结构及其构建过程与GA-FP 类似.依照表1 事务表并在最小支持度计数Cmin=3 下, 可构建出图2 所示的FPE树.为了便于理解本节内容, 下面对FPE树的数据结构作一简要介绍.
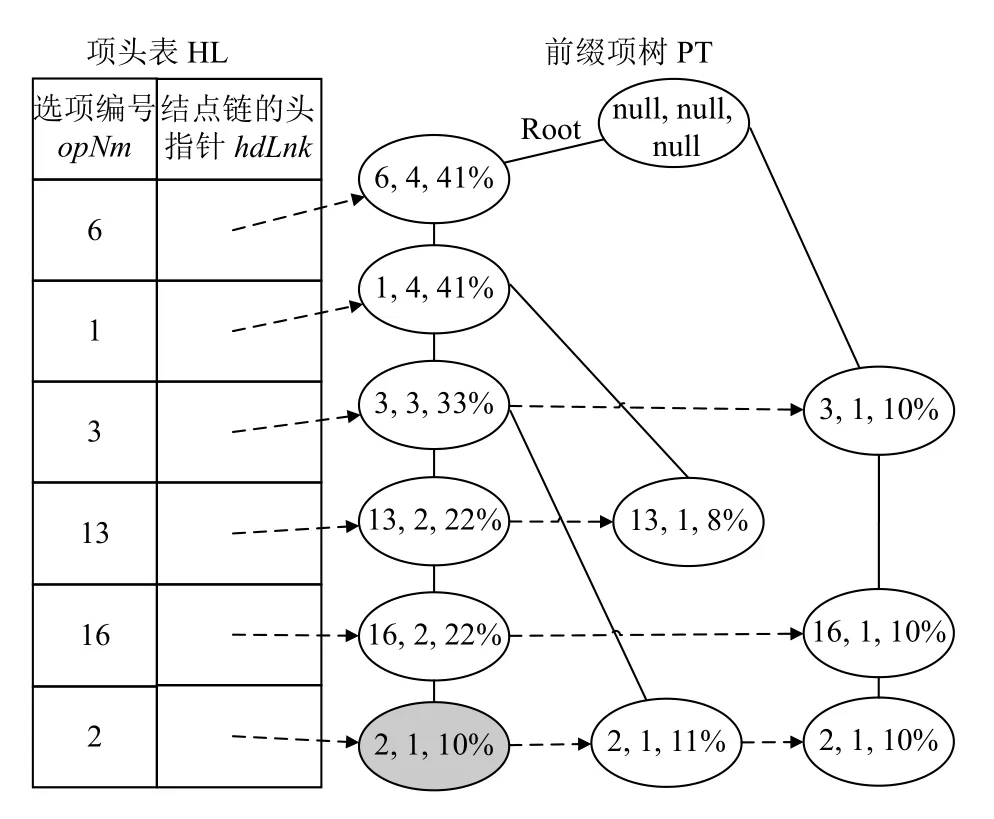
图2 基于表1 例子事务表TTE 生成的FPE 树
FPE树由前缀项树PT 和项头表HL 所构成.PT 树中各结点用选项编号opNm、出现次数count、能耗标注engAno、指向父结点的指针parNode 和指向下一个具有相同选项编号结点的指针nextNode 五个域进行描述.在图2 椭圆形结点中, 用逗号分隔的是opNm、count 和engAno 的值, 而各结点的parNode 和nextNode 的值分别由实线和虚线弧隐含表示.项头表HL 中各表项由频繁选项编号opNm 和结点链的头指针hdLnk 两个属性表示.hdLnk 可将相同选项通过结点链链接起来.图2 中项头表HL 最后一行的hdLnk 可将所有的2 号选项结点链接起来.
基于FPE树, 可挖掘出所有带能耗标注的频繁选项模式.下一小节将给出相关的定义.
2.2 挖掘带能耗改进标注频繁选项模式相关的定义
定义1.前缀路径.若node 为FPE树中的一个非根结点, 则从root 根节点到node 结点之间的一条路径称为node 的前缀路径.而node 结点称为该前缀路径的后缀结点.
前缀路径可用一个结点序列进行表示.图2 中灰色背景结点为后缀的前缀路径path1可用式(1)的结点序列表示.

定义2.条件前缀路径.设path 是后缀结点node的一条前缀路径.若将path 上各结点的支持计数和能耗标注分别修改为node 的支持计数和能耗标注, 而获得的路径被称为node 的条件前缀路径.
条件前缀路径用于表示前缀路径上各结点对应选项与后缀结点对应选项共同出现的次数及对应的能耗标注.例如: path1为图2 灰色背景结点node 的前缀路径, 用node 的支持计数1 和能耗标注10%分别更新path1上各结点对应值, 可得到式(2)表示的node 的条件前缀路径path2.它表示选项集{6,1,3,13,16}共同出现1 次且能耗标注为10%.

定义3.频繁选项的条件前缀路径集.若nodes 是FPE树中所有i 号频繁选项对应的结点集, 以nodes 中各结点为后缀所得条件前缀路径的集合, 称为选项i 的条件前缀路径集, 记为paths|i.
FPE树中i 号频繁选项对应的全部结点可沿结点链的头指针hdLnk 遍历获取.图2 中2 号选项对应的结点集, 可通过头表HL 最后一个表项的头指针hdLnk 遍历结点链得到.图2 中2 号选项的条件前缀路径集由path2, path3和path4所组成.式(2)~式(4)分别给出了path2~path4的表示.它们分别对应结点链中第1~3 个结点的条件前缀路径.

定义4.条件事务表.以i 号频繁选项的条件前缀路径集paths|i 中各路径为事务所构建的事务表, 称为i 号频繁选项的条件事务表, 记作TTFE|i.
按图2 中2 号频繁选项的条件前缀路径集{path2,path3, path4}可构建表2 所示的条件事务表.

表2 图2 中2 号频繁选项的条件事务表
定义5.条件FPE树.以i 号频繁选项的条件事务表TTE|i 作为输入所构建的FPE树被称为频繁选项i 的条件FPE树, 记为FPE|i.
按照表2 的2 号频繁选项条件事务表并在最小支持计数Cmin=3 下, 可构建出图3 所示的条件FPE树.

图3 FPE-growth+以图2 中2 选项为后缀构建的条件FPE 树
定义6.频繁选项模式.若Sop为频繁选项的编号集, count 和engAno 分别为Sop中各选项共同出现的次数及对应的能耗标注, 则频繁选项模式fopE+可用三元组(Sop, count, engAno)进行描述.其中: Sop的大小被称为fopE+的项数, 共同出现次数count 应不小于最小支持计数Cmin, 而engAno 由式(5)定义.式(5)中的函数Π(TE)表示从事务表TTFE的一条事务TE中投影出所选用选项的编号集, 而函数engImpr(TE)表示事务TE的能耗改进百分比值.当fopE+的项数为k 时, 用fopE+(k)进行表示.

对比算法GA-FP 的频繁选项模式仅给出单个频繁选项的能耗标注, 而GA-MFPM 则定义了多个频繁选项同时选用的次数和能耗标注.因而, GA-MFPM 包括了新的挖掘算法.
2.3 带能耗标注频繁选项模式的挖掘算法FP Egrowth+
FPE-growth+算法基于FPE树并采用模式项数渐增的递归挖掘方法, 其描述如算法2 所示.FPE-growth+算法包括递归出口处理和循环递归处理两部分, 分别如算法2 第2 行至第8 行、第10 行至18 行.

FPE-growth+算法的递归出口条件是当FPE树为单分支的树.当满足出口条件时, 首先依据单分支路径上非根结点的序列, 枚举获得所有非空结点序列的集合SnodeSeq; 然后对SnodeSeq中每个元素nodeSeq 重复做以下步骤: 将nodeSeq 作为头部连接到后缀结点序列postFixNodes 形成新序列newNodeSeq、计算序列newNodeSeq 中各结点支持计数和能耗标注的最小值,并用它们更新newNodeSeq 序列中各结点的支持计数和能耗标注的值、基于newNodeSeq 序列生成频繁选项模式fopE+并基于项数将fopE+存入模式集表的对应位置.
循环递归部分是依次对FPE树项头表HL 的尾行至头行进行递归处理, 如算法2 第10 行至17 行.递归调用前需要构建新后缀结点序列postFixNodes 并输出频繁选项模式、构建条件事务表、构建条件FPE树.FPE-growth+算法在挖掘频繁选项时, 采用与经典FP 挖掘算法[18]相同的递归过程挖掘获取频繁选项.仅在挖掘过程中增加了频繁选项的能耗标注的计算, 如算法2第5 行和第13 行.而该步骤时间复杂性为O(1), 故FPE-growth+算法与经典FP 算法相同.
图2 所示FPE树是一棵多分支的树, 在利用FPEgrowth+算法进行挖掘时, 由于不满足递归出口条件, 需要进入循环递归处理过程.在循环中, 首先要以图2 项头表最后一行的2 号选项为后缀和空的后缀结点序列进行挖掘.下面以此场景为例对FPE-growth+算法进行解释.
(1) 递归调用的处理
1) 构建新的后缀结点序列并输出频繁选项模式
沿图2 头表最后一行的结点链头指针进行遍历可得2 号频繁选项的支持计数和能耗标注分别为3 和31%, 进而可构造一个新结点node(2, 3, 31%).将node 连接到当前后缀结点序列postFixNodes 时, 由于postFixNodes 为空序列, 故连接后得到的postFixNodes=<(2, 3, 31%)>.根据postFixNodes 生成的频繁选项模式fopE+(1)=({2}, 3, 31%), 可将其输出到模式集表TPSFOE+的1 频繁选项集中.
2) 构建条件事务表
2 号频繁选项为后缀的条件事务表TTE| 2 已在定义4 中的例子给出, 如表2 所示.
3) 构建条件FPE树
根据条件事务表TTE|2 构建条件频繁模式树FPE|2 已在定义5 中的例子给出, 如图3 所示.以FPE|2 和postFixNodes=<(2, 3, 31%)>递归调用FPE-growth+时,由于FPE|2 树为一单路径树满足递归出口条件, 进行递归出口处理.
(2) 递归出口中的处理
1) 枚举获得所有非空结点序列的集合SnodeSeq
由于图3 的FPE|2 树中仅含一个非根结点node(3,3, 31%), 故枚举生成的SnodeSeq={<(3, 3, 31%)>}.
2) 对SnodeSeq中各元素nodeSeq 重复执行以下3 个步骤:
① nodeSeq 与后缀结点序列连接获取新序列newNodeSeq
SnodeSeq中仅包含的一个序列与postFixNodes=<(2,3, 31%)>连接后生成新序列newNodeSeq={<(3, 3,31%)>, (2, 3, 31%)}.
② 更新序列newNodeSeq 中各结点支持计数和能耗标注
由于newNodeSeq 各结点的支持计数和能耗标注相同, 故更前新后的newNodeSeq 序列相同.
③ 依据newNodeSeq 序列生成频繁选项模式并输出
根据序列newNodeSeq={<(3, 3, 31%)>, (2, 3,31%)}可生成频繁选项模式fopE+(2)=({3, 2}, 3, 31%), 可将其输出到模式集表TPSFOE+的2 频繁选项集中.
以图2 的FPE树和空的后缀结点序列为参数, 调用FPE-growth+算法最终输出表3 所示的模式集表TPSFOE+.

表3 例子带能耗标注的频繁选项模式集表TPSFOE+
3 最大频繁选项模式匹配帮助的多点变异
不同于GA-FP 中的单点变异, GA-MFPM 采用最大频繁选项模式匹配帮助的多点变异.多点变异的流程如算法3所示.其主要包括确定变异的位数和位置、最大频繁选项模式匹配、修改变异位值等3 个步骤.下面以图4 个体X2={1,1,0,0,0,0,0,0,0,0,0,1,1,0,1,1}和表3 的为例, 阐述最大频繁选项模式匹配帮助的多点变异操作流程.


图4 待变异的个体X2
(1)确定变异的位数和位置
确定变异的位数和位置如算法3 的第2 行至第4 行.为了能基于模式集表TPSFOE+提供的启发式信息进行变异, 规定最多变异的位数不超过TPSFOE+中频繁选项模式的最大项数.利用产生随机数完成变异的位数和位置的确定.每个变异位置对应于一个选项编号, 进而得到一个选项编号集S0, 假设例中得到的S0={2, 1, 6}.
(2)最大频繁选项模式匹配
最大频繁选项模式匹配是指将给定的选项编号集S0与TPSFOE+表中各模式的选项编号集进行最大匹配.通过最大匹配可发现编号集S0中频繁出现在优势个体中最长的编号集.
算法3 第5 行至第10 行描述了最大频繁选项模式匹配的匹配过程:
① 首先基于频繁选项模式所具有的向下闭包性质[18](k 频繁选项集的任何子集都应是频繁的), 在TPSFOE+表的1 频繁选项模式集SFOPE+(1)中, 将各模式的1 个编号与S0中的编号进行匹配, 并将匹配的编号放入S1 中, 进而获取S0中频繁的选项编号, 例中获取的S1={2,1,6}.
② 然后调用算法4 的最大频繁模式匹配算法MFPM.MFPM 算法将输入的选项编号集赋给Stemp后,从大小为|Stemp|的频繁选项模式集SFOPE+(|Stemp|)开始对Stemp进行最大匹配, 若能匹配上则将匹配结果放入结果频繁选项模式集Sfop中并退出匹配过程, 否则在SFOPE+(Stemp-1)中进行最大匹配; 直至Stemp为空结束匹配.例中首先在3 频繁选项模式集上对Stemp={2, 1,6}进行第1 轮最大匹配, 没有任何匹配的频繁模式.因而在2 频繁选项模式集上对Stemp={2,1,6}进行第2 轮最大匹配, 获取了频繁模式集Sfop={ ({6,1},4, 41%)}.

(3)修改变异位值
算法3 第7 行至第11 行负责完成个体中变异位值的修改.首先, 将个体X2赋给X2', 并以S0(存放随机生成的各变异位置)中各元素值为下标, 将X2'对应位的值设为0.例中由S0={2, 1, 6}, 可知X2'的第2, 1, 6 位上的值均设为0.然后, 若基于最大匹配得到频繁模式集S f o p 不空, 则按S f o p 中各元素的平均能耗标注(engAno/count), 依概率选择其中一个频繁模式fopE+,并以fopE+的选项编号集中各元素值为下标, 将X2'对应位的值设为1.
例中最大匹配获取的Sfop={({6,1},4, 41%)}不为空, 因Sfop只有一个频繁二项集, 则fopE+={{6,1},4,41%)}因而再将X2'第1 和第6 位上的值设定为1.最终X2'应如图5 所示, 本例中编号2 和6 位上的值发生变异, 即2 号选项由选用变为不选用, 而6 号选项由不选用变为选用.

图5 变异后的个体X2'
4 案例研究
本节给出了案例研究.4.1 节简介了实验案例;4.2 节提出了要验证的问题及度量标准; 4.3 节说明了实验中使用的统计方法; 4.4 节介绍了实验安装; 4.5 节展示了实验结果并进行了分析.
4.1 案例简介
本文从最新的BEEBS 平台[6]中选用了8 个案例,如表4 所示, BEEBS 是目前最大的用于嵌入式系统执行时间和能耗优化的开源基准平台.综合考虑以下3 个要素, 从BEEBS 所包含的84 个案例中选取了具有代表性的8 个案例.

表4 实验案例的应用领域、源代码的结构特性和操作特性
(1)源代码的操作特性: 案例涵盖尽可能影响运行时能耗的各种不同操作.如整型运算强度、浮点运算强度、分支频度和内存访问频度等.
(2)应用领域: 案例覆盖尽可能多的领域.如汽车、消费、网络、安全和通讯等.
(3)源代码的结构特性: 由于基准测试的编译和大量的编译选项的存在会极大地影响上述案例的编译效率, 所以在基准测试源代码中也会有一系列影响编译过程的特性.其中包括: 循环、嵌套循环、不同的算术类型(8 位、16 位和32 位整型、浮点型等)、函数调用、字符串操作、位操作和数组访问.表4 给出了选用的8 个案例的应用领域、源代码的结构特性和操作特性.
4.2 研究问题及其度量指标
问题1.解质量: 本文GA-MFPM 算法较GA-FP算法能否得到更优的编译选项组合, 使得案例的运行能耗更低? GA-FP 是目前以能耗为优化目标并可获取较优编译选项组合的一种算法.通过回答这一问题, 可以验证GA-MFPM 算法的有用性.
度量指标: 将GA-MFPM 和GA-FP 最优解对应的能耗相对改进百分比I△eng%作为度量指标.在案例源代码Sftsrc下, I△eng%的定义如式(6)所示, 其值越大越好.在式(6)中, X*GA-FP和 X*GA-MFPM 分别表示GAFP 和GA-MFPM 算法获得的最优解.f(Sftsrc, X*GA-MFPM)和f(Sftsrc, X*GA-FP)分别表示在案例源代码Sftsrc下GA-FP 和GA-MFPM 算法最优解相对于-O0 等级的能耗改进百分比.
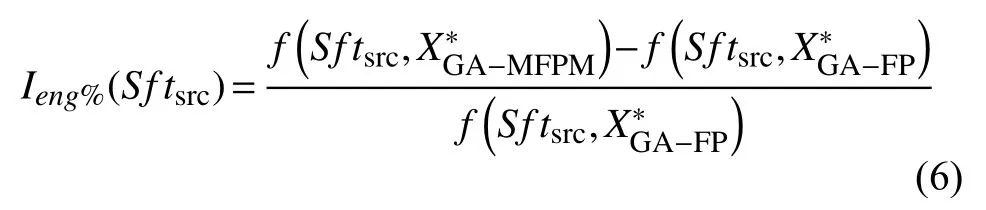
问题2.收敛速度: 与GA-FP 算法比, GA-MFPM算法能否加快收敛速度? 通过回答这一问题进一步验证GA-MFPM 算法的有效性.
度量指标: 为了公平比较两种算法的收敛速度, 将GA-MFPM 相对于GA-FP 首达最优时间的减少百分比I△t%作为度量指标.在案例源代码Sftsrc下, I△t%的定义如式(7)所示, 其值越大越好.式(7)中MinTGA-FP(Sftsrc, X*) 和MinTGA-MFPM(Sftsrc, X*)分别表示在案例源代码Sftsrc下GA-FP 和GA-MFPM 首达最优解 X*所需要的时间.

4.3 使用的统计方法
由于演化算法具有随机性, GA-MFPM 和GAFP 算法被分别独立运行20 次, 并进行统计检验.为了对实验数据进行统计分析, 本文采用了Wilcoxom 秩和检验[19]方法, 并将置信水平α 的值设置为 0.05.为了进一步观测对比数据的差异程度(effect size), 本文还使用Vargha-Delaney[19]的作为差异程度的直观度量.的值域为[0, 1], 其值越大说明差异程度越大.
4.4 实验安装
(1)实验环境
上位机的运行环境: Intel(R) Core(TM)i5-4590,3.30 GHz 处理器, 8 GB 内存及Ubuntu-16.04.1 操作系统.
能耗评估系统: 基于STM32F4 板自主研发.
案例软件优化的运行环境: STM32F103 板.
编译器和编译选项: GCC4.9.2, 并选用与GA-FP[15]相同的58 个编译选项.
(2)算法参数的设定
为了保持公平, 尽可能让GA-MFPM 采用与GAFP 相同的参数设定, 如表5 所示.但两个算法的最小支持计数设定有所不同.这是因为GA-MFPM 采用逐代替换事务表的策略.在事务表中, 若每个选项按随机方式选用, 则每个选项出现的次数应为种群大小N 的一半.而GA-MFPM 期望跟踪各代种群中优势个体选用选项的特点, 故将Cmin设定为0.6×N.而不是GAFP 中设定的0.1 倍全局事务表大小.

表5 GA-FP 和GA-MFPM 的参数设定
4.5 实验结果及分析
下面具体给出各问题的实验结果及分析.
(1)问题1(解质量)的实验结果及分析.
表6 给出了GA-MFPM 在这8 个案例下对比GAFP 的能耗改进百分比(I△eng%)的秩和检验结果.从表6中第2 列可知p-value 值都远比置信水平0.05 要小, 这表明GA-MFPM 的I△eng%指标在这8 个案例下的统计意义显著比GA-FP 的好.从表6 中第3 列可看出在这8 个案例下, GA-MFPM 算法的effect size 值以很明显的优势优于GA-FP.而从图6 所示的统计盒图也能直观反映出一致结论.从表7 的统计量结果能知道: 8 个案例下的I△eng%指标平均值为2.4%, 最大I△eng%指标值可达16.1%.
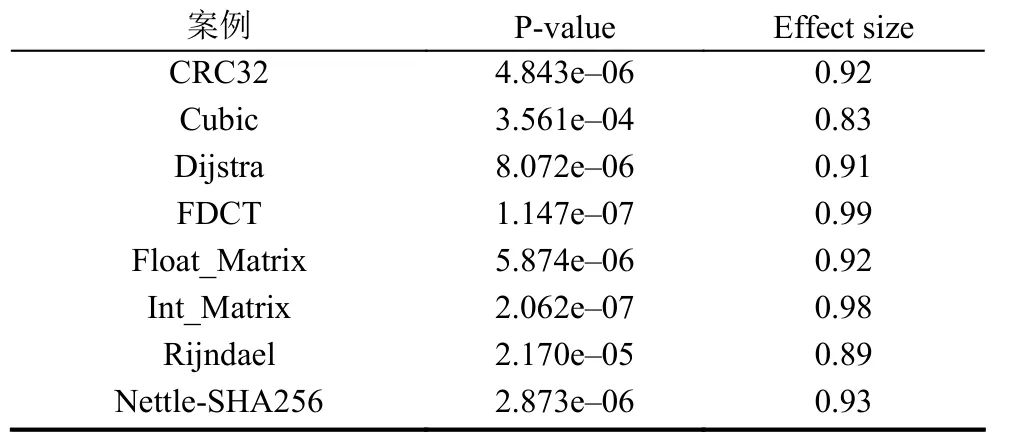
表6 GA-MFPM 较GA-FP 在8 个案例下能耗改进百分比(I△eng%)的秩和检验结果

图6 GA-MFPM 较GA-FP 在8 个案例下能耗改进百分比(I△eng%)的统计盒图

表7 GA-MFPM 较GA-FP 在8 个案例下能耗改进百分比(I△eng%)的统计量结果
GA-MFPM 较GA-FP 获取更好解质量的原因是:GA-MFPM 在逐代挖掘的频繁模式中保存了多个频繁选项, 同时标注选用次数和能耗, 可获取更完整、时效性更好的启发式信息, 有利于帮助提高解质量.
(2)问题2(收敛速度)的实验结果及分析.
表8 给出了在8 个案例下收敛速度指标I△t%(相对于GA-FP, GA-MFPM 首达最优解耗时的相对减少百分比)的秩和检验结果.表8 中第2 列p-value 值都远比置信水平0.05 要小, 表明GA-MFPM 的I△t%指标在8 个案例下的统计意义显著比GA-FP 的好.表8中GA-MFPM 首达最优解较GA-FP 在大概率上需要更少的时间.表9 可知: 8 个案例下的I△t%指标平均值为57.6%, 最大达到了97.5%.图7 所示的统计盒图也能直观反映出一致结论.
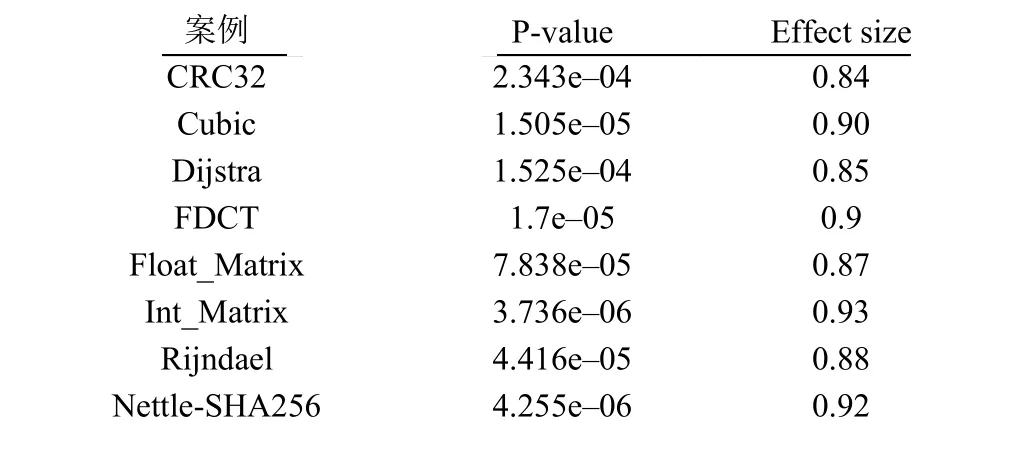
表8 在8 个案例下收敛速度指标I△t% (GA-MFPM 相对于GA-FP 首达最优解耗时的减少百分比)秩和检验结果
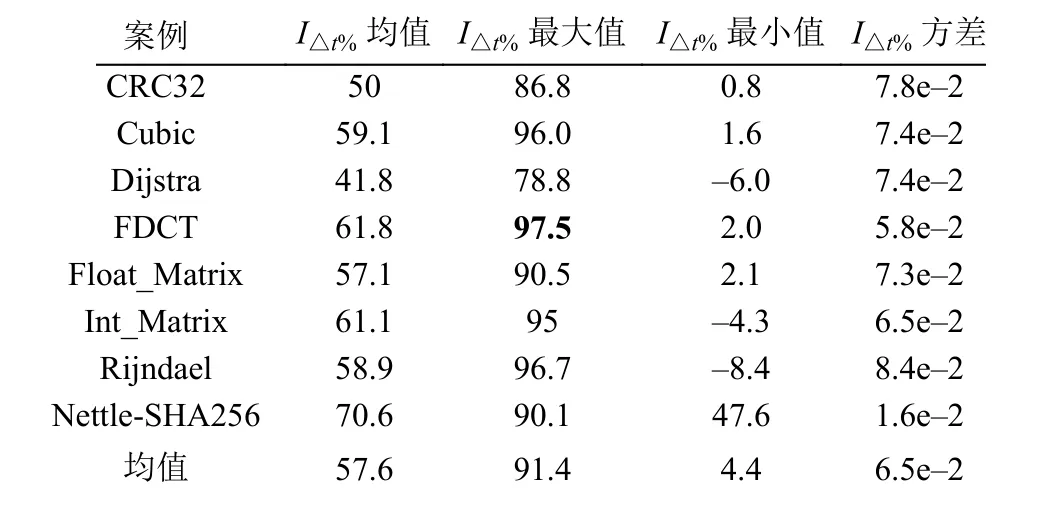
表9 在8 个案例下收敛速度指标I△t% (GA-MFPM 相对于GA-FP 首达最优解耗时的减少百分比)的统计量结果

图7 在8 个案例下收敛速度指标I△t% (GA-MFPM 相对于GA-FP 首达最优解耗时的减少百分比)的统计盒图
GA-MFPM 较GA-FP 获取更好的收敛速度的原因在于: GA-MFPM 逐代替换参考点的机制可有效降低事务表的大小、借助最大频繁模式匹配帮助的多点变异可提高变异效率, 进而有利于帮助提高收敛速度.
5 结语
本文将频繁模式挖掘和最大频繁模式匹配帮助的多点变异引入到传统遗传算法, 提出了一种用于GCC编译时能耗演化优化算法GA-MFPM.GA-MFPM 采用逐代替换判定是否有能耗改进的参考点、逐代构建事务表和逐代挖掘的策略; 在此基础上提出可获取更多启发式信息的频繁编译选项挖掘算法; 进一步设计了最大频繁模式匹配帮助的多点变异方法.通过案例研究实证了GA-MFPM 的解质量和收敛速度在统计意义上显著优于已有的GA-FP 算法.未来我们将引入代理模型解决GA-MFPM 算法中目标值计算耗时长的问题.
