燃料信息数据库性能的优化方法研究
2020-03-22刘思颖陶正亮何云峰于俊清
刘思颖,陶正亮,何云峰,于俊清*
(1.广东粤电信息科技有限公司,广东 广州510630;2.华中科技大学计算机科学与技术学院,湖北 武汉430074)
0 引 言
数据库技术是当代信息科学与技术的重要组成部分之一,主要研究计算机在信息处理过程中数据组织和存储的问题,是管理信息系统的核心[1]。随着信息技术的发展,数据库系统在电力企业中得到了广泛的应用,包括燃料信息系统[2-3]、财务系统[4]、大型设备在线监测和故障诊断系统[5-6]、大数据分析系统[7-8]等。然而,随着数据库存储量的变大,数据库应用系统的性能问题也越来越突出[9-10],应用系统的用户体验越来越差,提高数据库的性能是一个亟需解决的问题。Oracle 数据库是前应用比较广泛的关系型数据库之一,据统计,在全球有93%的上市.COM 公司和65 家“财富全球100强”企业都选择Oracle 数据库来开展电子商务,中国企业也广泛采用了Oracle数据库[11],因此基于Oracle 数据库性能优化的研究具有十分重要的意义[12-14]。
通过对火力发电企业中重要的应用系统燃料信息系统的数据库结构以及Oracle 的分区特性进行分析,使用平均每条SQL语句的执行时间来衡量数据库的性能,采用多项式拟合求解出局部最优的内存参数,通过调整、记录帮助用户找到使性能最优的内存参数。结合Oracle 数据库以及系统数据的特点,制定合理的优化方案,合理分配Oracle 的内存并解决系统数据库中表的数据太多的问题,提高系统访问数据库的速度,保证系统高效且稳定地运行[15]。
1 内存参数调整策略
1.1 基于数据库访问方式的内存参数选取
燃料信息系统是一个典型B/S 架构的应用系统,利 用Java 数 据 库 连 接(Java Database Connectivity,JDBC)来访问数据库。前台界面发送数据请求传给Tomcat 应用服务器,Tomcat 通过Java 调用Oracle 数据驱动程序,数据库驱动程序将数据请求传给数据库服务器,然后从数据库返回数据,数据沿着请求顺序返回到前台界面。其中,Java 代码会被编译成字节码直接运行,Java 字节码是Java 虚拟机(Java Virtual Machine,JVM)执行的一种命令格式。Oracle 数据库的SGA 提供一块区域——Java 池,供运行的Java 代码以及JVM内的数据使用,Java 池的大小会影响Java 代码运行的效率,从而影响数据库的访问性能。Java 池由参数JAVA_POOL_SIZE 控制,调整该参数的大小会改变系统数据库的性能。
1.2 基于缓存机制的内存参数选取
缓存是数据交换的缓冲区,一般存在于内存中。当应用程序需要读取数据的时候,会优先访问缓存,如果缓存中存在相应的数据,就直接返回数据,这样就能提高应用程序的执行效率,缩短用户的等待时间。Oracle 数据库在执行一条SQL 语句的时候,会在共享池里面确定这条语句的哈希值是否存在。如果哈希值存在,Oracle 执行软解析,直接运行执行计划;如果哈希值不存在,Oracle 执行硬解析,对SQL 语句进行解析,生成解析树,包括视图替换、表达式转换等等,然后生成并运行执行计划。硬解析是很昂贵的操作,大约占整个SQL语句执行时间的70%左右。
在运行执行计划之后,返回结果数据,oracle 会在数据缓存区里查找结果数据是否存在,如果数据存在,则直接将数据从内存返回给应用程序。如果数据不存在,会将数据从硬盘加载到数据缓存区中,再返回给用户。内存的存取速度与硬盘的存取速度差异较大,数据从硬盘读取相当耗时,相对于从硬盘读取,从内存中读取数据几乎不耗时。因此如果数据存在于数据缓存区中,其返回给应用程序的时间将会很短。
由此可见,共享池和数据缓存区的大小会影响数据库的性能。在Oracle 数据库中,共享池大小由参数SHARED_POOL_SIZE决定,数据缓存区的大小由参数DB_CACHE_SIZE 决定,对这两个参数进行合理的调整,就可能提高数据库的性能。
1.3 多项式拟合求解最优内存参数
燃料信息系统是一个实时系统,并发量比较低,对于每一次操作,好的用户体验是最小时间内返回数据结果。用户的每一次操作都是后台访问数据库的一个过程,因此,可以通过SQL语句的平均执行时间来衡量系统数据库的性能,平均执行时间越短,数据库性能越好,平均执行时间越长,数据库性能问题越严重。
通过前面分析,调整Oracle的3个参数:SHARED_POOL_SIZE、DB_CACHE_SIZE 和JAVA_POOL_SIZE可以影响运行性能。每次调整都会带来不同的性能影响,依次根据每个参数(x值)以及最后的结果(平均一条SQL语句的执行时间,y值)进行多项式拟合,找到这个参数的最优值。
记录每一次调整的内存参数值以及对应的数据库性能情况,由参数的值与最终结果构成的集合(xi,yi),i=0,1,2,…,m,求出一个函数:
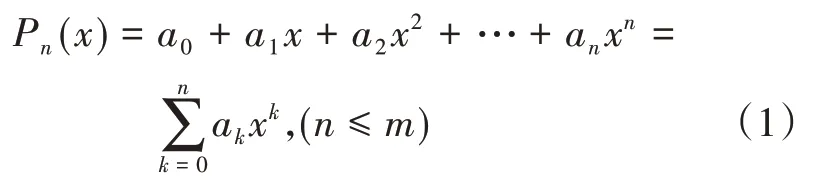
使偏差的平方和:
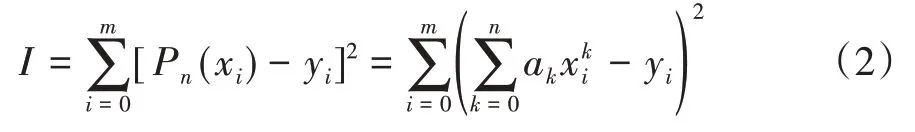
达到最小。
显然I 为a0,a1,a2,…,an的多元函数,求偏差的平方和即为求I 的极小值,根据多元函数求极值的必要条件,就是求I对a0,a1,a2,…,an的偏导数为0,即

在内存参数开始调整的时候,随着参数值的变大,最终结果y值会慢慢变小(性能变好,平均执行时间变短),当达到最合理值的时候,y值达到最小值,超过这个合理的值继续变大,y 值会慢慢变大。这符合二次曲线的变化特点,可以采用二次曲线进行拟合并求解。对于求出的二次曲线方程,找到使y 值最小的x 值,即为这个内存参数的最优值。另外,由于x 值必须大于零,并且二次曲线拟合可能带来误差,所以根据二次曲线方程求出来的x 值,必须落在给定集合中最大值与最小值之间,如果不在此区间,则该内存参数的最优值为集合中最大值与最小值之一。
多项式拟合的方法求解最优内存参数的方法在理论上能求出合理的内存参数值,如果3 个参数之间互不影响,则能求出最优值。如果3 个参数相互影响较大,则每次求出只是合理的值,多次求解会慢慢逼近最优值。另外,由于这个方法依据之前的调整结果,所以之前的结果集对求出最优内存参数速度的影响较大,即对算法的收敛速度影响较大。在实际使用中,可以先对内存参数以递增的方式进行调整,若干次调整之后就可以使用算法求解的参数进行设置,这样多项式拟合求解的效果较好。
2 数据表分区策略
2.1 基于数据特征的分区方法选取
信息系统最基本的功能是数据处理功能,包括数据采集、数据处理、数据存储、数据管理、数据检索以及数据传递等,属于数据密集型的应用系统[16]。通常,信息系统在使用初期,数据量都比较小,随着时间的累计,数据量会慢慢变大,从而引起数据库性能的问题。
作为一个典型的信息系统——燃料信息系统,数据库数据量大,数据种类比较杂,但大部分数据都具有相似的特点:近期的数据使用较频繁,时间久远的数据很少甚至不会被使用。这样的数据特点很符合Oracle表分区的应用场景,对于表分区,Oracle 给了两条建议[17]:
1)一个表的数据大小大于2 GB 时要考虑进行分区。
2)如果表中包含历史数据,并且新的数据会加到新的分区。比如一个包含一年历史数据的表,只有当前月份的数据可以被修改,而其他十一个月的数据为只读。
很多数据表符合第二条建议,对这样的表可以进行分区。使用Oracle支持的范围分区技术可以将这些数据表按照时间分为两部分,进行分区的时候指定一个分区时间,在指定时间之前的数据作为一个部分,之后的数据作为另一部分。由于对各分区的操作可以相互独立地进行,这样将数据表拆分为了两个比较小的数据表,解决大表带来的性能问题。
2.2 分区对数据库性能的影响
虽然数据表分区可以解决大表带来的问题,但是表分区也是有代价的,一个表分成几个区,对于这几个分区的维护需要时间,因此,并不是所有的表都适合被分区,分区能否带来数据库性能提升不能仅从理论方面分析,还需结合实际系统应用的场景。
下面将从两种情况——表有无索引和表的增删改查操作比例不同,通过具体的实验来测试表分区对数据库性能的影响。由于系统中对表的使用主要是查找和插入数据,删除和修改数据情况相对较少,为了简化实验,将表的使用只分为查找和插入数据两种情况。
实验选择了一个55 个字段的数据库表(HC_GHJLD),它是燃料系统的核心表之一,存储入厂煤计量数据,查询和插入操作频繁。根据HC_GHJLD 构造3 张结构完全相同的表,其中一张表(表名为HC_TEST)临时存储数据,另外两张表作为测试表,其中一个表(表名为HC_TEST_BEFORE)不做任何处理,另一个表(表名为HC_TEST_AFTER)按日期类型的字段到厂日期(DCRQ)进行分成两个区,分区时间间隔为一年,即一年前至今的数据作为一个分区,一年以前的所有数据作为另一个分区。
1)查找插入语句比例不同对表分区的影响
准备11组测试数据,每组120 000条测试语句,这120 000条语句只包含查找和插入语句,11组数据的查找和插入语句的比例分别为0∶10、1∶9、2∶8、3∶7、4∶6、5∶5、6∶4、7∶3、8∶2、9∶1、10∶0。其中,查找和插入语句比例为0∶10 表示一个表只会插入数据,而不会查找,这样的表基本不会存在;查找和插入语句比例为10∶0表示一个表的数据不会增加,这样的表中可能存放一些固定数据,基本不更新。
根据实验结果生成折线图如图1 所示,从图中可以看出,当查找与插入语句比例为0∶10到6∶4之间时,随着比例的变大,时间缩短比例也会变大。当查找与插入语句比例为6∶4 的时候,时间缩短的比例达到最大,为63.34%。当查找与插入语句比例为7∶3 到9∶1之间时,时间缩短比例很稳定,都是60%以上。当查找与插入语句比例为10∶0 时,分区并不能缩短执行时间。
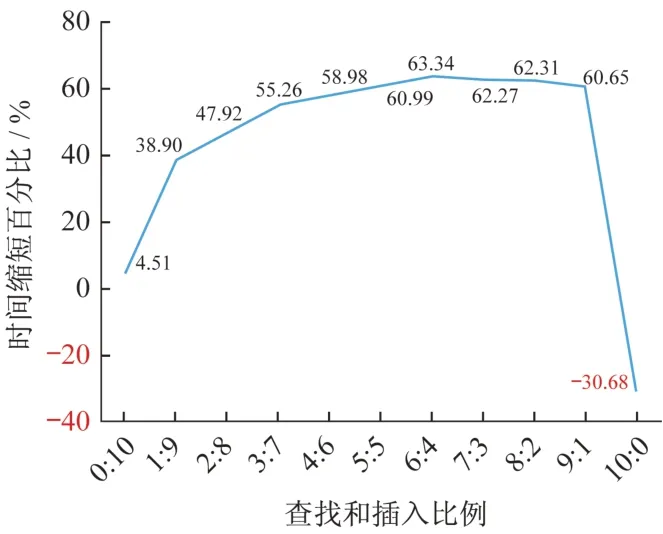
图1 分区前后不同查找与插入比例的执行时间缩短比例图Fig.1 The execution time reduction ratio of different query and insertion ratios before and after table partition
2)表索引对分区的影响
在关系型数据库中,索引是一种与表有关的数据库结构,使用索引可以加快数据查找的速度[18]。对表进行分区时,如果表本身就包含索引,表的几个分区可以共同使用一个索引,这种索引叫全局索引。每个分区也可以有自己的索引,这种索引称为本地索引,下面的实验过程与前面的相同,选择的表和测试数据完全一样,唯一的区别就是测试表(HC_TEST_BEFORE 和HC_TEST_AFTER)都不包含索引。
根据实验结果生成折线图如图2所示,可以看出,时间缩短比例基本和查找与插入语句比例呈线性关系,查找与插入语句的比例越大,时间缩短的百分比越高。
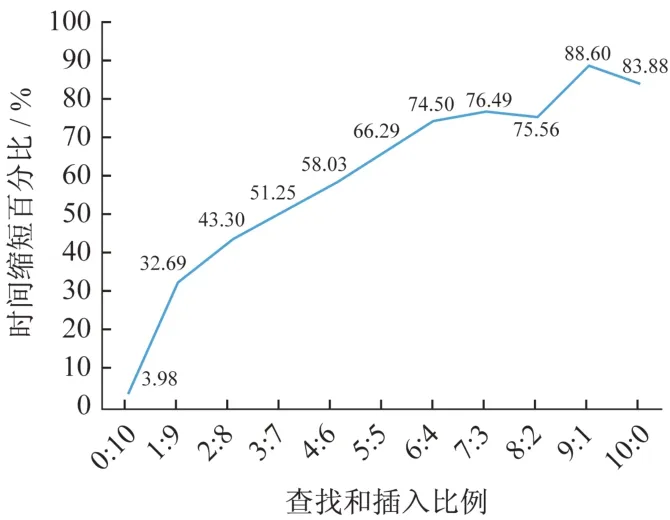
图2 表没有索引在分区前后不同查找与插入比例的执行时间缩短比例图Fig.2 The execution time reduction ratio of different query and insertion ratios before and after table(no index)partition
将两次实验结果进行对比,当查找与插入语句比例在0∶10 到4∶6 之间时,有索引和没有索引在表分区前后的时间缩短比例基本相同,有索引情况的时间缩短比例略高。当查找与插入语句比例在5∶5到10∶0之间时,没有索引情况下在表分区前后的时间缩短比例比有索引情况下的时间缩短比例更高,并且随着查找与插入语句比例增大,两者的差别也变大。
2.3 表分区策略的制定
Oracle 提供的分区建议是面向所有的数据库,没有结合实际系统的数据表和特定的分区方法。燃料信息数据库采用时间范围分区,将数据分为两个区,制定数据表分区的策略还需结合具体的情况。一般来说,数据表表中的记录越多,表的大小就越大,下面通过实验测试表中记录条数不同对分区的影响,根据实验结果来制定分区策略。
为了加快缩短每组实验的时间,在表HC_TEST_BEFORE 和HC_TEST_AFTER 同样的字段上建立唯一索引,准备两组数据:
1)准备12 组分别包含1 000 条、3 000 条、5 000条、10 000条、20 000条、50 000条、100 000条、150 000条、200 000 条、300 000 条、400 000 条、500 000 条数据作为数据库表中的原始数据。
2)准备12 组测试数据,查找与插入语句比例为6∶4,每组数据的条数为原始数据条数*0.8,即对于1 000 条原始数据准备1 000*0.8=800 条测试数据,以此类推。
根据实验结果生成折线图如图3 所示,红色字体表示负值,可以看出,20 000 条记录是一个临界点,当表中的记录条数小于20 000条时,记录条数越少,表分区带来的开销比例越大;当表中的记录条数大于20 000 条时,表分区会在不同程度上缩短执行时间。当表中的记录条数为100 000条时,表分区时间缩短比例达到最大—77.13%。
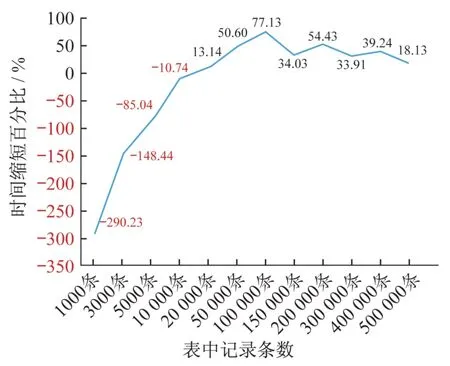
图3 不同记录条数在表分区前后的执行时间缩短比例图Fig.3 The execution time reduction ratio of different number of records before and after table partition
根据这个实验,制定数据表分区策略为:当表中包含的记录条数大于20 000 条时,如果表上执行的查找和插入操作次数在0∶10到9∶1 之间,就对这个表进行分区,分区方法为时间范围分区。
3 系统的设计与实现
3.1 系统框架描述
为了方便燃料信息系统的用户随时了解数据库的性能情况,设计了一个Oracle数据库性能监控的系统,其结构如图4所示。系统展示了数据库的四种性能信息:共享SQL 区的使用率、数据字典缓冲区的命中率、数据缓存区的命中率以及日志缓冲区的申请失败率,并实现了两种数据库性能调整与优化的方案:调整内存参数和数据表分区。在数据库性能监控的系统中,用户在发现数据库出现性能问题的时候,可以通过调整内存参数或者对表进行分区来优化数据库的性能。

图4 系统功能模块图Fig.4 System function module diagram
3.2 数据库性能监控
数据库性能监控是为了实时反映数据库的性能情况,为了能很直观地显示数据库性能情况,通过折线图来实时展示数据库性能信息,利用多线程技术,每隔5 s从数据库系统视图中读取一次性能数据,主要采集SGA的性能信息,包括共享池、数据缓冲区和日志缓冲区。用户登录系统之后,会显示性能监控界面,如图5所示。
3.3 内存参数调整策略的实现
调整内存参数只能调整3 个参数DB_CACHE_SIZE、JAVA_POOL_SIZE 和SHARED_POOL_SIZE,同时还会显示SGA 当前的大小,但SGA 的值SGA_TARGET 不可改,用户设置最小的参数值点击确定会弹出确定对话框,图6所示。
用户通过最优设定,系统后台会根据当前的SGA_TARGET 值,利用二次曲线拟合,求出每个参数的最优值,即为推荐给用户的最优内存参数。
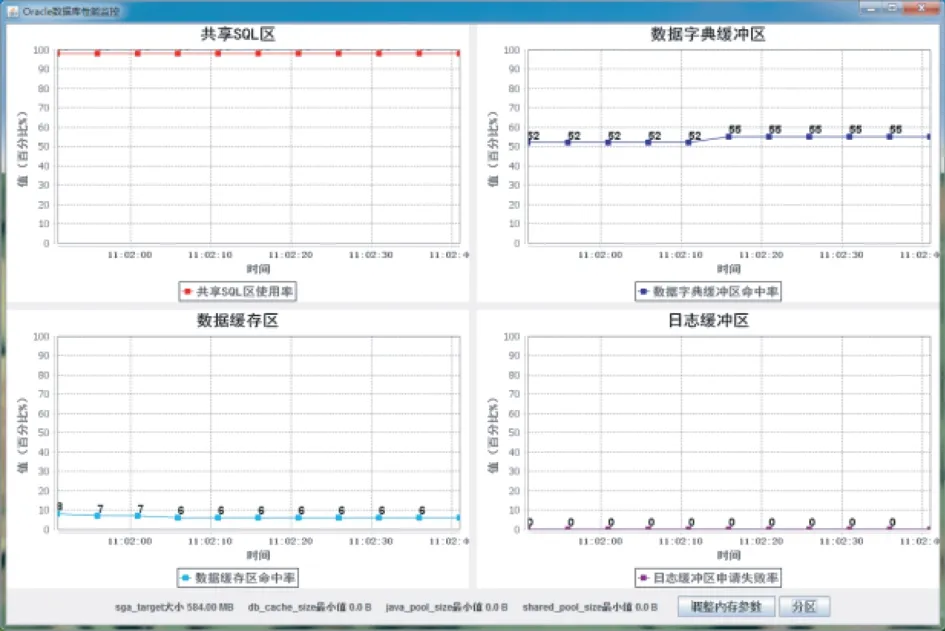
图5 数据库性能监控Fig.5 Database performance monitoring interface

图6 调整内存参数Fig.6 Interface for adjusting memory parameters
3.4 数据表分区策略的实现
数据表分区首先要根据分区策略确定需要进行分区的数据表。通过数据库的审计功能,可以获得表名、使用次数(查找和插入次数和)、查找次数、插入次数等信息。遍历AUDIT_SUMMARY中的每一条记录,如果查找和插入比例在0∶10到9∶1 之间,则根据表名从数据库系统视图USER_TAB_COLUMNS中查询表中是否包含日期字段,如果包含,则根据聚集函数COUNT(*)查询表中的记录条数,如果记录条数大于20 000,则根据表名从系统视图USER_INDEXES 中查询表上是否包含索引,根据查询的结果更新当前表的记录条数和有无索引的信息。最后得到的结果显示在界面上,如图7所示。
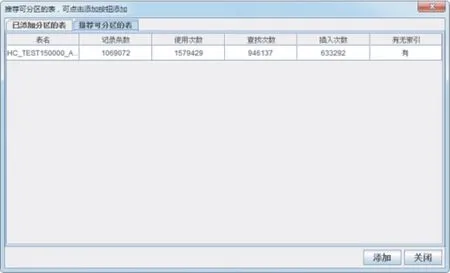
图7 根据算法求出适合分区的表Fig.7 The table suitable for partition according to the algorithm
Oracle 数据库支持分区,但是只支持在表创建的时候进行分区,对于存在数据的表不能直接分区。系统利用SQL 语句实现动态分区,即由用户选择分区的表并且指定分区时间间隔,过程对用户透明。分区的具体步骤如下:
1)根据当前时间生成字符串与待分区的表名拼成新表的临时表名。
2)按照分区字段和分区时间生成分区语句,其中分区语句包含旧表信息(表字段和字段数据类型)和旧表数据。
3)执行分区语句创建临时新表,此时临时表已分区并包含旧表的数据。
4)通过数据库提供的RENAME(重命名)操作将旧表重命名,将临时表表名重命名为旧表表名,此时旧表表名已为别名,临时表(称为新表)已命名为旧表表名。
5)从旧表的元数据中提取字段默认值、备注、约束等字段信息增加到新表。
6) 从 系 统 视 图 USER_INDEXS 和 USER_TRIGGERS 中分别提取旧表的索引、触发器等表的信息。
7)通过DROP 语句删除旧表的所有信息(数据和结构),索引、触发器等信息会同时被删除。
8)将提取的旧表索引、触发器等信息增加到新表。
9)分区结束。
4 结语
随着信息时代的发展,数据库技术的应用从传统的商务数据处理逐渐发展到许多新的领域,数据库的规模也不断扩大,数据库应用系统的性能问题也越来越突出。在对数据库优化技术的国内外研究现状以及信息系统进行深入研究分析之后,发现许多优化思想对现有的系统并不适用,数据库性能优化工具也不能很好地解决数据库的性能问题。本文结合数据库性能优化理论方面的研究,从两个方面制定优化策略对数据库进行调整以达到优化目的,并且设计了一个数据库性能监控系统。
1)结合信息系统访问数据库的原理以及缓存对SQL 语句执行的影响选择需要调整的内存参数,使用平均一条SQL 语句的执行时间来衡量数据库的性能,对内存参数和数据库性能关系构建数学模型,采用多项式拟合,并利用贪心算法,求出每个参数的局部最优解,通过不断迭代找到最适合系统的内存参数值。
2)根据数据库支持的分区技术结合信息系统数据的特点,确定分区的方法为根据时间范围分区,通过大量实验来研究不同情况下表分区对数据库性能的影响,确定合适的分区策略,给用户推荐系统数据库中所有适合分区的表,并使用程序实现分区。
3)设计了一款数据库性能监控工具,通过折线图从共享SQL区的使用率、数据字典缓冲区命中率、数据缓存区的命中率以及日志缓冲区的申请失败率4个方面实时显示系统性能情况。
[参 考 文 献](References)
[1] Marco Vieira,Henrique Madeira. Towards a security benchmark for database management systems[C]. 2005 International Conference on Dependable Systems and Networks(DSN 2005),2005.
[2] 韩鹏.某火电厂燃料全过程信息化管理系统开发与应用[D].北京:华北电力大学,2016.HAN Peng.Development and application of the fuel overall process management information system of a thermal power plant[D].Beijing:North China Electric Power University,2016.
[3] 王梦婷,马平.B/S模式火电厂燃料管理信息系统的设计与实现[J].计算机仿真,2014,31(10):137-140,169.WANG Mengting,MA Ping.B/S mode coal-fired power plant fuel management information system design and implementation[J].Computer Simulation,2014,31(10):137-140,169.
[4] 杜梓平.财务信息管理系统的设计与实现[D].北京:北京邮电大学,2009.DU Ziping. Design and implementation of the financial management information system [D]. Beijing:Beijing University of Posts and Telecommunications,2009.
[5] 王顶磊.大型发电机组转机状态智能监测[J].湖北电力,2019,43(06):61-66.WANG Dinglei.Intelligent monitoring on rotary machinery status of large generating sets[J]. Hubei Electric Power,2019,43(06):61-66.
[6] 宋宇.水轮发电机组故障诊断系统的设计与实现[J].电子技术与软件工程,2020,(19):162-163.
[7] 孙鹏,林光,邢智,等.智能电表及其数据在共享型配网中的深度应用研究[J].湖北电力,2020,44(02):58-66.SUN Peng,LIN Guang,XING Zhi,et al.Deep application research of smart meters and its data in sharing-type distribution network[J].Hubei Electric Power,2020,44(02):58-66.
[8] 刘洋.一种基于大数据分析的电力客户服务需求预测方法[J].中国新技术新产品,2020,(23):23-25.
[9] CAI Juan. Research on application of computer database technology in information management[C]. 2014 IEEE workshop on advanced research and technology in industry applications(WARTIA),2014.
[10] YAO Leiyue,JIANG Jie. Analysis and optimization for bottlenecks of database in massive management of information system[C].2010 International Conference on Computer and Communication Technologies in Agriculture Engineering,2010.
[11] 袁爱梅.Oracle 数据库性能优化研究[D].上海:华东师范大学,2007.
[12] 王文阁.信息系统Oracle 数据库性能优化研究[J].数字技术与应用,2020,38(11):59-61.WANG Wenge. Research on performance optimization of oracle database in information system[J].Digital Technology and Application,2020,38(11):59-61.
[13] 付文哲,韩震,司玉杰.关于处理数据库优化设计[J].电脑知识与技术,2020,16(32):28-29.
[14] 吴尚,张靖,徐道磊.Oracle数据库性能的优化设计思路研究[J].数字技术与应用,2019,37(12):167,169.WU Shang,ZHANG Jing,XU Daolei.Research on optimal design of oracle database performance [J]. Digital Technology and Application,2019,37(12):167,169.
[15] 陶正亮.燃料信息数据库性能的优化方法研究[D].武汉:华中科技大学,2016.TAO Zhengliang.Research on optimization method of fuel information database performance[D]. Wuhan:Huazhong University of Science and Technology,2016.
[16] 吴璇.基于信息系统的审计理论、模型及应用[D].天津:天津大学,2004.WU Xuan.Theory,model and application of auditing based on information system[D].Tianjin:Tianjin University,2004.
[17] 蒋勇.ORACLE 数据库分区技术及其应用[J].科技信息,2011,(29):53-54.
[18] GUO Wenming,HU Zhiqiang. Memory database index optimization [C]. 2010 International Conference on Computational Intelligence and Software Engineering,2010.
