一种融合语义分析特征提取的推荐算法
2020-03-21陈嘉颖杨兴耀
陈嘉颖 于 炯 杨兴耀
1(新疆大学信息科学与工程学院 乌鲁木齐 830046) 2(新疆大学软件学院 乌鲁木齐 830008)(chenjy@stu.xju.edu.cn)
近年来,互联网的蓬勃发展致使网络信息量呈指数级增长,网络大数据给人们带来严重的“信息过载”问题,导致终端用户很难准确获取与其需求相符合的信息.推荐系统能够根据用户历史行为数据,分析其潜在偏好,为用户提供个性化推荐,成为缓解“信息过载”问题的有效手段.目前,推荐系统已应用在电子商务(Amazon、阿里巴巴等)、社交网络(Face-book,Twitter等)、电影推荐(Netflix等)、音乐推荐(Last.fm等)、新闻推荐(GoogleNews等)等领域.
现有推荐系统主要以用户评分矩阵作为主要的用户偏好信息[1],用户评分具有客观性,不同用户打分标准不同.多数推荐平台为用户提供了交互接口,如点赞、评论等,在线评论是用户对项目感受的具体反馈,这些反馈信息通常以非结构文本形式存在,合理分析用户评论信息能够对项目特征及用户偏好进行精细刻画.基于用户评论[2]、基于用户隐士反馈信息的推荐算法在解决冷启动、推荐准确性以及可解释性等方面具有重要潜力,然而,受到文本信息挖掘技术等方面的限制,基于评论信息分析的推荐算法进展并不明显.
知识图谱以结构化的形式将互联网信息表示为人类易于理解的语义网络,使人们更容易组织、管理以及利用互联网信息.知识图谱的兴起,为个性化推荐系统的改进提供了新的思路.针对现有推荐系统对项目特征分析不够充分的问题,提出一种融合语义分析特征提取的推荐算法.该算法从推荐平台中非结构化文本信息入手,结合知识图谱,对项目的描述信息及真实评论数据进行相关实体提取和语义分析,提取项目细粒度特征;设计协同学习框架监督学习用户、项目的低维向量表征,并以此为目标用户推荐符合其偏好的项目.在真实数据集上的实验结果表明,本文提出新算法的推荐效果优于选取的代表性对比算法.本文主要贡献有3个方面:
1) 利用知识图谱对多源异构数据的整合性,在对项目特征提取过程中融入语义分析,提出融合语义分析的特征分析方法.
2) 定义相关实体概念对提取的特征实体进行扩展,在特征分析过程中保持项目特征多样性.
3) 设计知识感知的协同学习框架,将基于知识图谱的向量表征整合到协同过滤推荐过程中,根据学习结果进行Top-N推荐.
1 相关工作
1.1 个性化推荐
个性化推荐算法主要包括基于内容的推荐算法(content-based recommendation, CBR)、基于协同过滤的推荐算法(collaborative filtering-based reco-mmendation, CFR)和混合推荐算法(hybrid methods)3类[3].基于内容的推荐算法通过抽取各个项目的属性特征、分析用户历史行为构建用户对项目的偏好向量,然后计算用户偏好向量与候选项目特征向量的相似性,向用户推荐相似度高的项目.该方法特征抽取困难,局限于文本资源推荐,很难挖掘用户潜在兴趣[1,4].
协同过滤推荐算法的目标是将用户和项目间的二元关系转化为评分预测问题,依据用户对项目的历史评分进行协同过滤或排序,进而产生推荐列表[1,5].与基于内容的方法相比,协同过滤推荐算法不需要项目属性信息,可以根据用户与物品间点击、浏览、评分等交互信息进行推荐[6],因此被研究者广泛推崇.
基于协同过滤的推荐算法通常分为基于内存的协同过滤算法(memory-based collaborative filtering)和基于模型的协同过滤算法(model-based collabora-tive filtering).基于内存的协同过滤算法通过计算用户或项目间的相似度,评估目标用户对未打分项目的评分而进行推荐[5].此类方法主要依赖用户对项目的评分资源,适应性广,同时也面临高稀疏性、冷启动、无法有效处理大规模数据等问题[4,7].
基于模型的协同过滤推荐算法使用统计和机器学习技术,根据用户-项目打分矩阵学习包含用户隐藏特征的行为预测模型,并利用此模型进推荐.学者们将多种模型用于基于模型的协同过滤方法,如贝叶斯模型[8-9]、矩阵分解模型[10]、潜在语义分析模型[11]、深度学习模型[12]等.基于矩阵分解的方法,如SVD[13](singular value decomposition),NMF[14](non-negative matrix factorization)等,根据高维用户-项目评分矩阵学习用户、项目的低维向量表示,并将其用于推荐任务.此类方法在处理大规模数据时有杰出表现.为了缓解协同过滤算法数据稀疏性和冷启动问题,研究人员将语义知识融入推荐过程.文献[15]利用链接开放数据库中丰富的语义,提取电影相关RDF数据,计算电影资源向量空间的相似性,并进行Top-N推荐.随着深度学习算法在自然语言处理、图像识别、计算机视觉等多个领域取得了巨大的突破,研究者们将深度学习模型引入推荐领域用于隐藏特征的学习.文献[12]将2层受限玻尔兹曼机(restricted Boltzmann machines, RBM)用于协同过滤算法.该方法以用户对项目的打分矩阵为输入学习隐含层并用隐含层的数值来表示用户特征,首次提出基于深度学习的协同过滤模型.文献[16]利用用户信息、历史行为等多源异构数据,将深度神经网络用于YouTube视频推荐系统的候选集生成模块和精排模块,推荐效果显著提升.Google提出Wide&Deep学习模型[17]用于手机APP推荐,该模型联合训练一般的线性模型(wild)和多层感知机模型(deep),使其同时具有记忆能力和泛华能力,得到了广泛的应用.
1.2 知识图谱及其表示学习模型
2012年5月Google为增强互联网搜索引擎能力、优化搜索引擎结果而发布知识图谱产品.知识图谱(knowledge graph, KG)以一种接近人类认知的结构化表达形式,存储客观世界存在的复杂结构化、非结构化信息,其本质是语义网络[18].近年来,随着互联网数据规模的不断增大,多种开放知识图谱被推出,如DBpedia,YAGO,Wikidata,BabelNet,Microsoft Concept Graph、中文知识图谱百度百科、OpenKG等.合理使用知识库中的语义信息,能够解决现实生活中通过单一领域知识难以解决的问题,目前,知识图谱已在互联网语义搜索、智能问答、大数据语义分析以及智能知识服务等方面得到广泛应用.
知识图谱以结构化的形式描述概念、实体及其间的关系,多以RDF(resource describe framework)三元组的形式进行存储管理,即G=(E,R,E),其中,E={e1,e2,…,e|E|}表示知识库中|E|个实体的集合;R={r1,r2,…,r|R|}表示知识库中|R|种不同关系的集合;S⊆E×R×E表示知识库中三元组集合.每个三元组(h,r,t)包含2个实体(头实体h,尾实体t)及2个实体间的关系r.
基于三元组的知识表示方法由于其表现能力强、具有可解释性等优点被学者广泛认可,但也面临着数据稀疏、推理能力低、鲁棒性差等问题.随着自然语言处理领域词向量嵌入技术的发展,面向知识图谱的表示学习研究也取得了新进展.基于向量的知识表示方法将知识图谱中的实体和关系用低维稠密的向量表示,并使相近实体在向量空间有相近的表示,语义相关联的实体在向量空间有所关联,进而在低维向量空间中计算实体间语义相似性.基于向量的知识图谱表示可以有效地将知识图谱用与其他学习任务相结合,如知识库补全、关系抽提、实体分类等.
知识图谱的表示学习方法主要有基于张量分解的方法,如NTN[19],RESCAL[20-21];基于翻译的方法,如TransE[22],TransD[23],TransH[24],TransR[25]等.基于翻译的模型认为,对于每个三元组(h,r,t),其中关系r是头实体h到尾实体t之间的翻译[26].由于此类方法在大规模知识图谱中具有简单、高效等优点,自Bordes等人[22]提出TransE模型后,基于翻译的方法受到研究者的广泛关注.本文选用TransR模型在算法中进行表示学习.


(1)
相应的得分函数被定义为

(2)
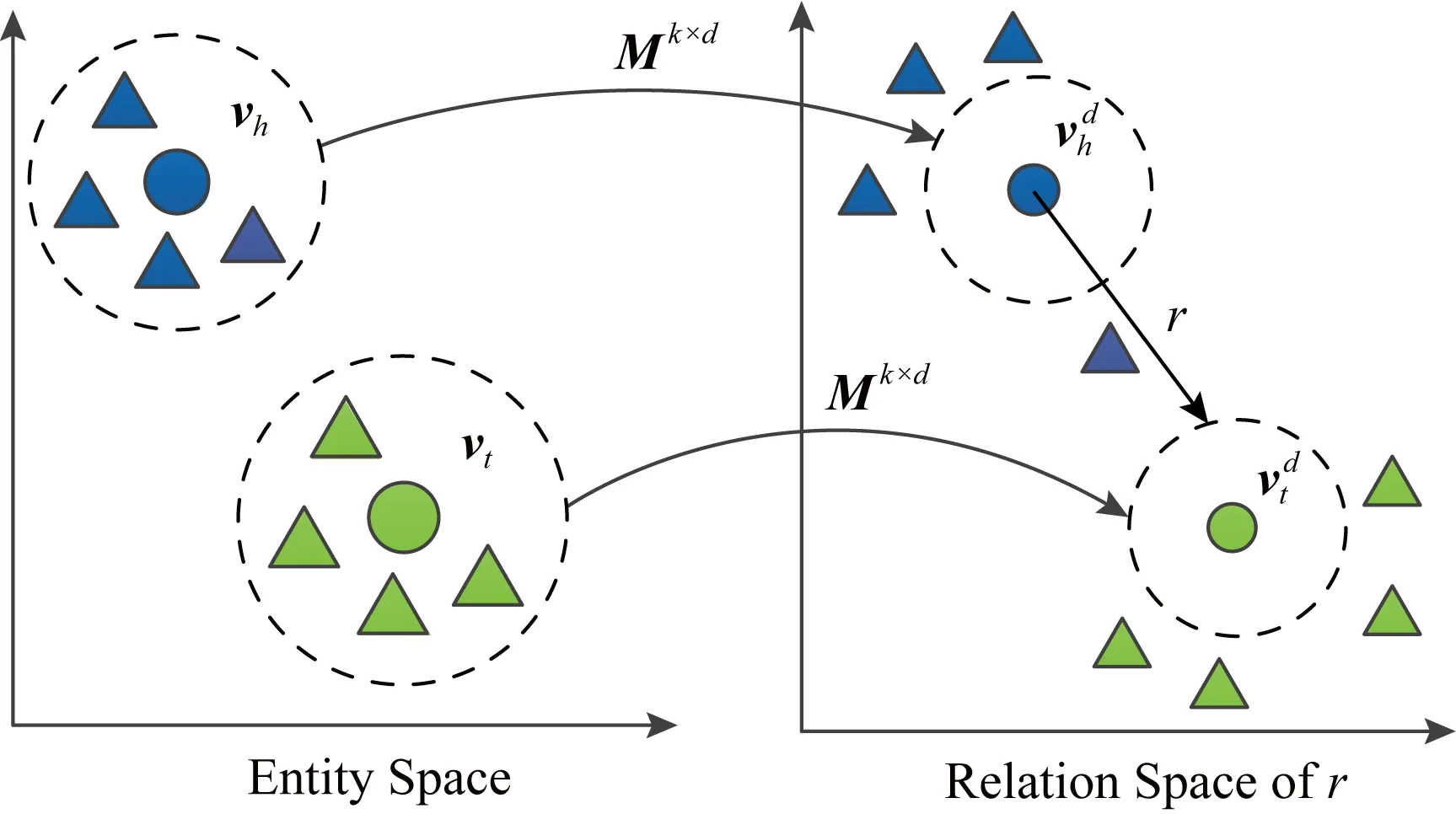
Fig.1 TransR model图1 TransR模型
1.3 基于语义分析的推荐算法
基于历史数据集的推荐算法面临数据稀疏、冷启动等问题,近年来许多研究者将语义知识融入协同过滤算法解决上述问题.文献[27]通过对描述物品的文本进行分词、提取标签等处理后,计算描述信息的词语间的相似度,进而分析物品间的相似性,预测目标用户对项目的打分;文献[28]提出一个3层知识表述方法用于新闻推荐,通过在用户层与项目层中间引入语义丰富、表达明确的知识空间,分析上下文语义信息,改进推荐系统性能;文献[29]提出一种基于标签语义相似度分析的推荐算法.该算法通过分析项目标签与项目之间的相关性,处理单词间、句子间的相似性来提升对用户兴趣分析的准确度.
由于知识图谱的语义网络特性,学者们试图将知识图谱用于推荐过程来提升效果.知识图谱在3个方面对推荐算法有促进作用:1)实体间语义相关性有助于提取异质信息网络中用户及项目的潜在特征;2)知识图谱包含大量实体及丰富的关系,复杂的链接关系能够合理扩展用户偏好,为用户做出多样性推荐;3)通过知识图谱将用户的历史行为记录连接起来,能够提升推荐系统带可解释性[30].文献[31]较早提出将DBpedia用于音乐推荐,作者首先将音乐数据集映射到知识库获取音乐潜在属性信息,然后计算各个艺术家在知识库中的语义距离并以此完成推荐;文献[32]分别构建了基于声音和基于音乐的知识图谱,从项目的标签、文本描述信息等历史数据中提取实体,并使用实体链接、同义词消歧技术将提取的实体映射到知识图谱中,以此丰富声音、音乐特征,使推荐的覆盖面更广;文献[33]将知识库中的结构知识、文本知识和图片知识分别向量化后,通过联合训练与协同过滤进行融合,实现了基于异构数据的排序推荐.其中结构知识通过知识图谱中头尾实体与实体之间的关系组成,首次将知识图谱用于推荐算法项目特征提取;文献[34]将知识图谱引入新闻推荐系统,提出一种基于内容的深度学习点击率预测算法(deep knowledge-aware network, DKN).DKN算法设计了知识感知的卷积神经网络模块和单词-实体对齐模块,关联新闻标题中的词语与知识库中的实体,将新闻语义层面表示与知识层面表示相融合,并使用注意力模块动态聚合用户历史记录;文献[30]提出RippleNet算法,RippleNet模拟水面涟漪传播的过程,在知识库中根据实体间关系自动迭代扩展用户的潜在兴趣.根据用户行为历史,可刺激用户偏好在多组实体上传播,形成用户偏好分布,预测用户对候选项目的点击概率;文献[35]提出基于知识图谱的推荐算法的通用向量化模型.在知识图谱上使用神经语言模型学习用户、项目的特征向量,针对特定属性创建用户-项目关联关系,然后利用机器学习函数生产Top-N推荐序列;文献[36]提出知识增强的序列推荐算法,该算法将知识图谱整合到一个RNN网络与Key-Value存储网络相结合的模型,来增强其语义表达,知识增强的KV-MNs能够捕获属性级别的用户偏好序列,并具有高可解释性;文献[37]将知识图谱视为一个异质信息网络,构造用户和项目的基于meta-path或者meta-graph的向量表示,挖掘项目之间属性关系,灵活使用知识图谱网络结构信息提升推荐效果.
2 问题定义及模型框架
本文提出一种融合语义分析特征提取的推荐算法,拟根据用户在网络中的历史行为及项目的评论信息,结合知识图谱对项目和用户进行细粒度特征分析,向用户推荐更符合其偏好的项目.
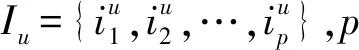
融合语义分析特征提取的推荐算法整体框架如图2所示,该模型主要包括基于知识图谱的项目表示、协同学习、推荐列表生成3个部分.基于知识图谱的项目表示模块以项目的评论信息及知识图谱为输入,提取项目相关实体组建知识子图,学习知识子图中实体低维向量表示并以此对项目进行低维表征;协同学习模块以项目的向量表示结果及用户的历史行为为输入,通过知识感知的协同学习框架,结合知识图谱向量表示及用户的偏好函数协同学习项目、用户的低维表征;推荐列表生成模块根据学习得到的用户、项目低维向量表示,对目标用户进行Top-N推荐.

Fig.2 Framework of the feature extraction based recommender algorithm fusing semantic analysis图2 融合语义分析特征提取推荐算法框架
3 基于语义分析的特征提取及推荐
3.1 相关实体提取
目前,多数视频网站为用户提供了评论通道以促进用户间交流,这些以文本形式存在的评论信息中包含了大量与视频特征相关的信息,也包含用户对该视频的态度及个人偏好.对于评论文本,实体是其承载特征信息的基本语言单位,识别评论信息中的实体及其间的相互关系,是理解评论信息的基础,也为分析视频特征及用户偏好提供新的途径.
命名实体识别(named entity recognition, NER)技术可以将非结构化文本转化为以命名实体为中心的结构化语义表示,实体链接(entity linking, EL)技术可以将识别的实体与知识库中相应的实体相连接.融合语义分析特征提取的推荐算法使用NER和EL技术,结合知识图谱在项目评论信息中提取项目相关实体及实体间的链接信息.对于一段非结构化评论文本T,T中包含多个命名实体,命名实体集合为A={a1,a2,…,an},对于A中任意实体a,在知识图谱命名实体库E中遍历实体名称,得到a的候选实体集合ε(a)={ea,1,ea,2,…,ea,k},通过实体消歧技术将a链接到知识库中相应的实体ea上[38].由于Wikipedia中包含大量表示特征的实体,因此本文在处理英文文本信息时选用Wikipedia作为基础知识库,选择百度百科作为分析中文文本信息的知识库.
图3为豆瓣网站上某用户对电影《阿凡达》的评论信息.该评论信息中包含:与电影相关的实体,如卡梅隆、佩戴等;与电影拍摄技术相关的实体,如3D、虚拟摄像、表情抓取、联合数字立体摄影机等;与电影细粒度特征相关的实体,如探险、挑战、爱情、好莱坞个人英雄主义、传奇剧式等;与电影相关联的其他实体,如泰坦尼克、塞尔达传说、游戏等.

(3)
(4)
其中,fk为特征函数,wk为特征函数的权重,Z(x)为归一化因子.
3.2 特征实体表示学习

εk={t|(h,r,t)∈Gandh∈εk-1},
(5)
其中,k=1,2,…,H,H为最大阶数.
在提取实体的过程中,实际提取实体数目受评论数量制约,Ru中实体数目变动较大,本文采用扩展相关实体的方式缓解因提取相关实体少而引起的数据稀疏、特征单一的问题.为了丰富用户u的特征实体集合,本文将通过上述方法得到的实体集合Ru视为知识图谱中种子实体,通过链接关系将其扩展为n阶相关实体集合.根据扩展后的实体集合,构建项目特征相关子知识库,并采用知识图谱表示学习模型TransR学习上述项目特征相关知识子图的低维向量表示.图4是对图3中影评信息的实体提取、建立子图及子图表征的过程.
对于项目i,其相关实体集合ri中的实体以不同程度体现项目i的特征.就图3影片评论信息而言,实体3D、卡梅隆、虚拟技术较好莱坞、泰坦尼克更能代表影片《阿凡达》的特征.因此,在知识图谱向量表征的基础上,本文为不同实体赋予不同的权重,通过权重函数表示项目与其相关实体间的关系,由此得到项目、用户基于权重函数的低维向量表征.项目i基于权重函数可表示为vi.

Fig.4 The process of relevant entities linking, sub-graph construction and embedding of a review图4 影评信息实体提取、子图建立及表征过程
(6)
因此,用户u的某个浏览历史项目i可表示为
(7)
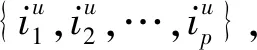
(8)

3.3 协同学习及排序预测
为了将知识图谱的表示学习过程整合到协同过滤推荐过程中,本文设计了一种知识感知的协同学习(knowledge-aware collaborative learning, KACL)框架,该框架通过定义用户偏好函数,构造知识图谱实体-关系四元组,协同学习实体、项目及用户的低维向量表征.并以此为目标用户推荐符合其偏好的项目.
推荐平台中,隐式反馈信息(如浏览、收藏、购买等)通常是对每个用户的操作数据进行收集,能够缓解显示反馈的数据稀疏性问题.本文在推荐学习过程中,借鉴BPR(Bayesian personalizes ranking)模型[40]中用户喜好商品偏序对的思想,定义用户-项目对偏好函数并用于学习过程.对于m个用户及n个项目,用户-项目隐式反馈矩阵为Rm×n,当Ru,i=1时,表示用户u与项目i之间存在可观察到的交互,如点击、浏览、收藏等.当Ru,i=0时,表示用户u与项目i之间不存在可观察到的交互,据此定义用户-项目对偏好函数.
定义2.用户-项目对偏好函数.设用户集合为U,u∈U;项目集合I,i∈I,i′∈I,用户u对项目i的偏好为Ru,i,Ru,i=1表示用户u对项目i有过交互,否则Ru,i=0.对于用户-项目三元组(u,i,i′)∈D,集合D表示用户-项目三元组集合,如果Ru,i=1,且Ru,i′=0,表示用户u对项目i的偏好程度大于该用户对项目i′的偏好[40].定义用户-项目对偏好函数p(u,i,i′)(p(u,i,i′)>0)表示用户对项目对(i,i′)的偏好:

(9)
其中,uu和vi分别代表用户u和项目i的向量表征,δ代表sigmoid函数.KACL中协同推荐学习过程认为用户对隐式反馈商品的偏好大于没有反馈的商品.
KACL框架中知识图谱表示学习过程,通过构造与知识图谱中三元组相关的实体-关系四元组,以优化知识图谱实体、关系表征为目标,采用sigmoid函数计算知识图谱中三元组对的得分,训练知识图谱表征学习模型.具体过程为:
对于知识图谱G中任意三元组(h,r,t),构建相关实体-关系四元组集合St,t′=(h,r,t,t′);四元组中实体h,t,t′及关系r满足(h,r,t)∈G∩(h,r,t′)∉G,即(h,r,t)是知识图谱中真实存在的实体,(h,r,t′)不是知识图谱中存在的实体.集合S表示实体-关系四元组集合,St,t′∈S.在知识图谱表示学习过程中,认为真实存在三元组得分大于不存在三元组的得分.因此,协同学习过程中知识图谱表征过程的监督函数可定义为
yh,r,t,t′=lnδ(fr(h,t)-fr(h,t′)).
(10)
为了得到各参数的最优解,本文采用Adam优化器迭代优化损失函数,KACL模型损失函数:
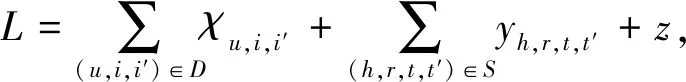
(11)
为避免学习过程中出现过度拟合现象,在损失函数式(11)中加入正则化项z,其中λ为正则化参数.
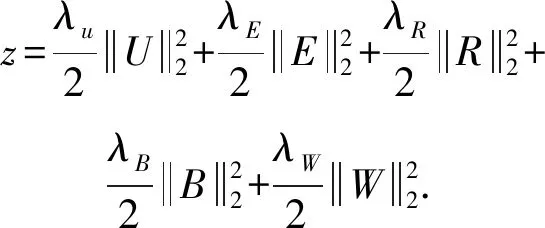
(12)
知识感知的协同学习过程如算法1所示:
算法 1.KACL算法.
输入:用户集合U={u1,u2,…,un}、项目集合I={i1,i2,…,im}、用户-项目隐式反馈矩阵Rm×n、知识图谱G;
输出:用户、项目向量表示矩阵P,Q.
① 随机初始化W,P,Q;
② 构建用户-项目对三元组集合D;
③ for (uu,vi,vi′)∈Ddo
④ 构建实体关系四元组Si,i′;
⑤ for (h,r,t,t′)∈Si,i′do
⑥ 根据式(6)~(8)对项目、用户进行向量化表示:vi,vi′,ui;
⑦ 根据式(11)计算损失函数
⑧ Maximizeχu,i,i′+yh,r,t,t′+z;
⑨ end for
⑩ end for
算法1中,通过步骤②④构建用户-项目三元组集合D,实体关系四元组Si,i′,由此对项目、用户进行表征,并根据表征结果最大化损失函数值,最终输出用户、项目的低维表征矩阵.算法2根据表征结果对目标用户和项目进行相似度预测,并将相似度结果进行排序,将Top-N的项目作为推荐结果输出.
算法2.Top-N推荐.
输入:用户、项目向量表示矩阵P,Q,推荐个数N;
输出:Top-N推荐列表.
对于任意用户u及项目i
① forum∈Udo
② forvi∈Ido
③Smi=pumqvi;
④RankList=Sorthigh→low(Smi);
⑤ end for
⑥ 输出Top-N推荐列表;
⑦ end for
4 实验与结果分析
为了证明融合语义分析特征提取的推荐算法的有效性,本文在真实数据集上进行验证实验,并将其结果与其他流行算法进行对比分析.
4.1 实验数据集及评价指标
1) 数据集
本文选用2个真实数据集:豆瓣网(Douban)爬取数据集和亚马逊提供的Movie Review数据集来验证实验性能.豆瓣数据集包含124 153个用户对电影的409 841个打分、410 254条评论信息.Amazon Movie Review数据集包含12 512个用户对210 756个项目481 457个打分.为了更好地对算法性能进行评估,实验前对数据集中评论数少于20的项目进行筛减,然后在筛选后的数据集上进行实验.实验中,我们将数据集随机划分为训练集、验证集、测试集3部分,3个集合的数据比例为7∶1.5∶1.5.
2) 评价指标
本文在实验中验证了新模型在Top-N推荐中的效果,选用Precision@k,Recall@k评估Top-N推荐结果,并使用AUC(area under the ROC)对算法进行综合评估.准确率反映了系统推荐的项目中用户感兴趣项目的比重,召回率反映出被推荐项目是用户真正感兴趣项目的比重.
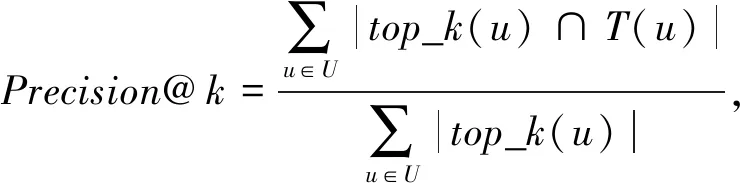
(13)
(14)
其中,U为用户集合,top_k(u)表示通过算法获取的前k个项目列表;T(u)表示测试集中用户u历史选择项目集合;top_k(u)∩T(u)表示k个推荐项目列表与测试集列表的交集,即正确推荐项目集合.为了综合评价改进算法的性能,我们在实验过程中将用户对项目的打分转换为用户对项目的反馈数据,从二分类问题角度出发,以AUC为评价指标综合评价改进算法的推荐结果.以上3评价指标的值越大,推荐效果越优[41].
4.2 实验设置
为了证明本文提出算法的优越性,我们将新算法与3个经典推荐算法进行对比.
1) Wide&Deep[17].Wide&Deep是Google 提出的用于手机APP推荐的学习模型,该模型联合训练一般的线性模型(wild)和多层感知机模型(deep),使新模型同时具有记忆能力和泛化能力,是基于深度学习的协同算法的代表.
2) CKE[33](collaborative knowledge base emb-edding).CKE模型在推荐算法中融合结构知识、文本知识、图片知识提取项目语义特征用于排序推荐,其中结构知识通过知识图谱中三元组获取.CKE是基于知识图谱的推荐算法的代表,为了保持算法的公平,对比实验中我们仅在CKE中融合结构知识.
3) NFM[42](neural factorization machine).NFM算法将矩阵分解(factorization machines, FM)模型与神经网络相结合,用于提取项目二阶线性特征及高阶非线性特征.
本文为实验搭建Wikipedia、百度百科知识图谱,采用Python为开发语言,所有实验在Python 3.7.2,tensorflow1.13.0环境下完成.对于数据集中的每个项目,我们分别在知识图谱中提取其属性实体,并将实体集合扩展到3阶相关实体集合.学习过程中,随机将数据集以7∶1.5∶1.5的比例划分为训练集、验证集、数据集3部分,进行5次实验取其平均值作为实验结果.KACL模型在训练过程中选用adam优化器进行参数优化,其初始学习率设置为0.001,迭代次数设置为10,数据集用户、项目的向量表示维度为100,并选用BatchNorm实现深度神经网络更快更稳定的训练.对比算法中向量也设置了相同的维度.
4.3 实验结果及分析
1) KACL稳定性测试
在KACL算法中,推荐个数k的设置直接影响推荐结果.为了证明模型的稳定性,我们设置k分别取值为5,10,15,20,25,30,35,40,在不同推荐个数条件下比较推荐准确性.实验结果如图5所示,从图5可以看出,在2数据集上,随着k值的增大,算法推荐结果Precision@k的值先降低,随后趋于稳定.KACL模型在不同k值条件下,推荐结果均优于对比算法,这说明KACL推荐效果不受推荐个数的影响,具有稳定性.
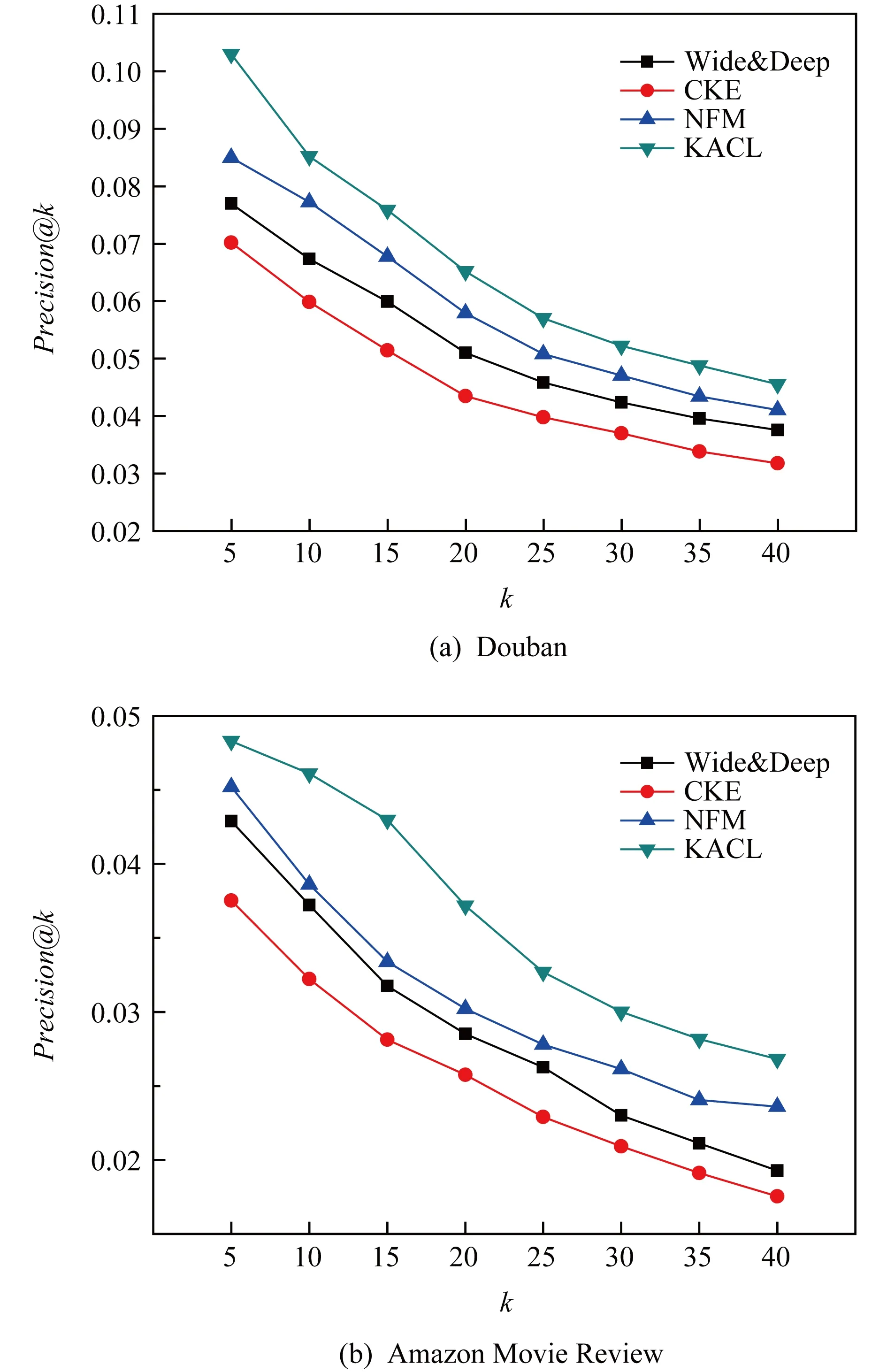
Fig.5 The comparison of accuracy with different k图5 不同k值时推荐结果准确率比较
2) 不同推荐算法比较
在同样的实验环境下,我们将本文提出的融合语义分析特征提取的推荐算法与选取的基于深度学习的推荐算法(Wide&Deep)、基于知识图谱的推荐算法(CKE)及基于矩阵分解的推荐算法(NFM)进行实验比较.各算法在Douban数据集上推荐结果Precision@k,Recall@k的值如表1所示.图6显示了精确率和召回率随着推荐个数k的变化情况.
从图6可以看出,KACL在不同k值条件下,其推荐准确率、召回率均高于对比算法.基于融合语义分析特征提取的推荐算法的Precision@k值随着推荐个数值的增加逐渐降低,当k=20时趋于稳定.当k<20时,KACL算法推荐结果的准确率较对比算法有明显优势.算法推荐结果的Recall@k值随着推荐个数的增加而增加,这是由于当推荐个数增大时,算法推荐结果会覆盖更多用户的偏好项目.当k≥30时,KACL算法推荐结果召回率较对比算法有明显的提升.当k=20时,整体推荐效果最佳,KACL较基于知识图谱的CKE算法准确率提升了32.62%,召回率提升了6.0%,由此说明KACL算法较传统基于知识图谱的方法能够更好的利用异构资源分析项目语义特征,向目标用户推荐更符合其兴趣爱好的项目.此外,KACL算法较基于深度学习的Wide&Deep算法准确率提升了27.78%,召回率提升了6.27%,较基于矩阵分解的算法准确率提升了11.20%,召回率提升了6.10%.
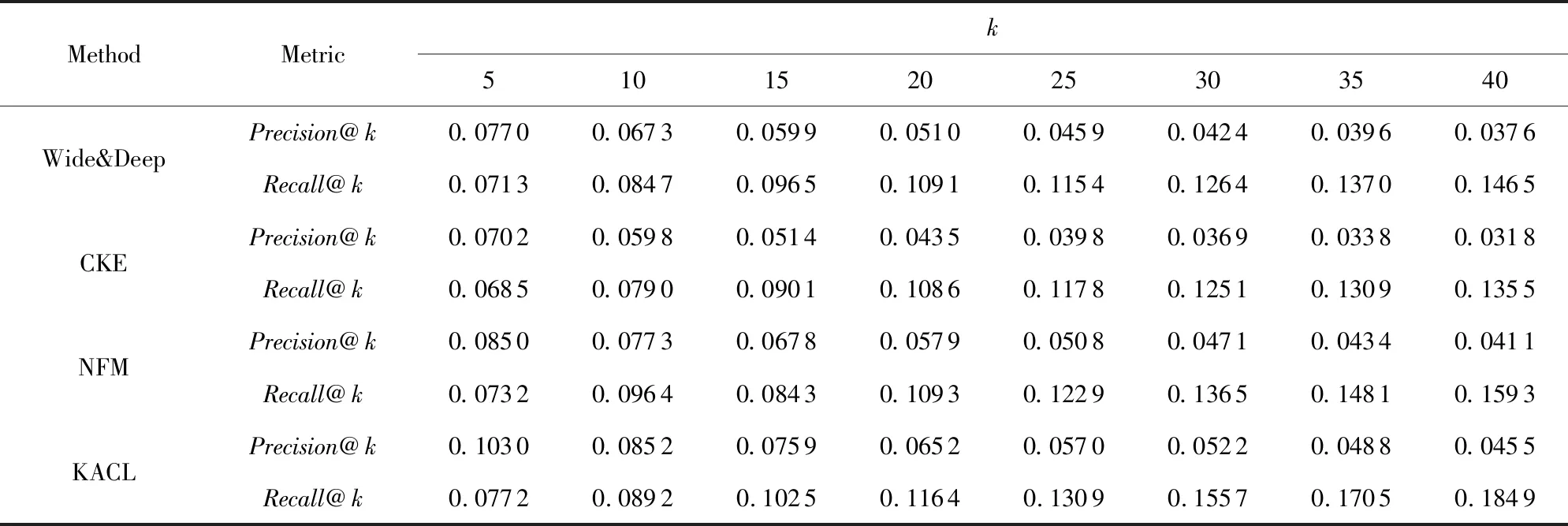
Table 1 The Evaluation Results of Different Methods with Different k on Douban表1 各算法不同k值时在Douban数据集上的推荐性能

Fig.6 The comparison results of different methods on Douban图6 在Douban数据集上不同算法性能比较
各算法在Amazon Movie Review数据集上的预测结果如表2、图7所示.从图7可以看出,在不同推荐个数下,KACL推荐结果的Precision@k,Recall@k值均高于对比算法.与豆瓣数据集相比,Amazon Movie Review数据量较少,项目评论信息偏少.尽管如此,KACL算法的推荐效果较其他推荐算法仍然具有优势.以上对各算法推荐性能的分析可以说明,本文提出的融合语义分析特征提取的推荐算法能够为用户推荐更符合其偏好的项目.
为了综合评价KACL算法与对比算法,我们将用户对项目的打分信息转化为用户对项目的反馈信息进行二分类测试,得到各算法推荐结果的AUC值.表3列出了各算法推荐结果AUC值以及KACL算法较对比算法AUC值提升程度.从表3可以看出,KACL算法的AUC结果高于所以对比算法.与基于知识图谱的CKE算法的AUC结果相比,KACL在2个数据集上的推荐结果分别提升了10.11%和8.56%.说明了本文提出的KACL算法在项目的细粒度特征提取方面更具敏感性,能够更准确的分析项目特征、用户偏好,从而做出更准确的推荐.

Table 2 The Evaluation Result of Different Methods with Different k on Amazon Movie Review表2 各算法不同k值时在Amazon Movie Review数据集上的推荐性能

Fig.7 The comparison results of different methods on Amazon Movie Review图7 在Amazon Movie Review数据集上不同算法推荐性能比较
Table 3 The AUC Results of Different Methods and the Comparison Between them on 2 Datasets
表3 2个数据集上不同算法推荐结果的AUC值及其比较

DatasetsWide&DeepCKENFMKACLImprovement Rate of KACL∕%Wide&DeepCKENFMDouban0.75210.72390.78590.80537.0711.242.47Amazon Movie Review0.66790.63560.68230.65104.079.361.88
3) 算法时间复杂度比较
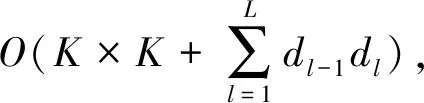
综合以上实验结果,本文提出的基于知识图谱的推荐算法在推荐效果及算法效率方面均优于具有代表性的对比算法,能够在不丢失大量理想项目的情况下将符合用户需求的项目推荐给用户.
5 结 论
基于标签等语言分析推荐算法在分析用户、项目细粒度特征等方面存在一定的局限性.推荐平台上项目描述信息、评论信息中包含大量项目特征信息以及用户偏好信息,对评论信息进行有效分析是项目细粒度特征提取、提升推荐效果的有效途径.
为了更准确地分析用户、项目特征,本文在项目评论等文本信息的基础上,结合知识图谱,对文本信息进行语义分析,提出一种基于语义分析特征提取的推荐算法.新算法通过知识图谱实体识别链接技术,根据文本信息内容在知识库中提取项目属性特征实体及与其相关联的实体,以此分析用户、项目的细粒度特征,并根据用户、项目基于特征的向量表示,完成对目标用户的推荐.在2个数据集上的实验证明了本文提出算法的有效性.在今后的工作中,我们将在语义分析的基础上,结合评分矩阵进一步对细粒度特征分析,并考虑融合社交网络等外部信息解决推荐算法中冷启动等问题.
