一种分布式持久性内存文件系统的一致性机制
2020-03-21陆游游陈游旻屠要峰舒继武
陈 波 陆游游 蔡 涛 陈游旻 屠要峰 舒继武
1(江苏大学计算机科学与通信工程学院 江苏镇江 212013) 2(清华大学计算机科学与技术系 北京 100084) 3(中兴通讯股份有限公司 南京 210012)(chenbo_9312@163.com)
近年来,新兴的非易失存储器[1-3](non-volatile memory, NVM)具有字节可寻址、非易失、存储密度高和访问延迟低等特性,其通过内存总线连接CPU的NVM形态也被称为持久性内存(persistent memory, PM).NVM的出现重新定义了计算机体系结构中易失性与非易失性的界限,以往由系统软件保障的数据一致性转变为由CPU硬件保障.另一方面,远程直接内存访问(remote direct memory access, RDMA)因其高速、超低延时、零拷贝和内核旁路的网络传输特性,逐渐被应用到数据中心.RDMA可以实现应用程序间点对点的通信,同时避免了上下文切换、冗余内存拷贝和内核网络协议栈等开销.持久性内存和RDMA的出现为构建新型存储系统[4-12]提供了新的机遇.
持久性内存和RDMA具有的新特性对存储系统的一致性设计提出了2项挑战:1)现代处理器利用多核和内部缓存来提高整体运行速度,通常采用乱序执行技术,导致最终写入内存的数据并非是预期的结果,针对持久性内存会出现数据一致性的问题.此时,为了将数据顺序地写入持久性内存,CPU需要主动执行数据刷写指令,然而此过程开销高昂,降低CPU的处理能力,影响持久性内存和RDMA的性能优势;2)RDMA的通讯过程需要注册内存,且提供了单向原语可以绕过服务器端CPU直接读写已注册的内存.为了性能考虑,RDMA会将数据先写入至末级高速缓存,由于CPU不能及时将数据刷写至持久性内存,因此,一旦出现系统崩溃,原始数据将无法有效恢复.
对于数据的一致性策略,现有的存储系统要么完全不考虑数据一致性例如Octopus[13],要么使用常见的Redo/Undo[14]日志机制、Log-Structure技术或影子分页[15](shadow paging)技术等来保障操作的原子性.然而,使用Redo/Undo日志会导致数据重复写问题,在加重数据持久化开销的同时,还会浪费带宽和加速持久性内存磨损;而影子分页技术采用异地更新数据块的方法,将原有指向旧数据块的指针更新指向新的数据块,但这将有可能导致所有的数据更新蔓延到根节点[15].针对服务器端不可感知客户端写入数据的问题,一种可行的方案是采用客户端执行RDMA send原语发送数据给服务器端,服务器端将数据写到指定的地址,然后执行数据持久化操作,但此方式引入了冗余拷贝[16].
为此,本文提出并实现了一种分布式持久性内存文件系统的一致性机制CCM,该机制主要包括:首先提出并实现了一种基于操作日志的一致性保障策略,将元数据地址和数据的地址与大小写入操作日志,并原子地修改操作日志的尾指针且持久化,这样系统崩溃后,可通过持久化的操作日志进行恢复,这样可保证元数据和数据的一致性.然后,设计了一种客户端对服务器端远程写一致性策略,该策略中客户端使用RDMA write-with-imm原语远程写入服务器端内存,此原语附带客户端标识符,服务器端可以感知其携带的客户端标识符,进而服务器端CPU可以定位需要刷写的地址,对客户端写入的数据执行持久化操作,保证数据的持久化.最后,实现了一种服务器端的数据异步持久化,通过对元数据、数据和操作日志执行异步刷写,降低了持久化操作的开销.
1 相关工作
为保证系统发生故障后能恢复一致性的状态,现有的持久性内存存储系统一般使用日志的方式来保障一致性,也有不少系统未考虑一致性这个问题.下面从持久性内存文件系统一致性机制和面向RDMA的分布式持久性内存文件系统一致性机制2个方面介绍相关工作.
1) 持久性内存文件系统一致性机制
本文的一致性指的是系统断电或故障后数据仍旧一致.目前在单机上的典型的持久性内存文件系统一致性研究工作有:NOVA[17]是加利福利亚大学圣地亚哥分校提出的基于混合内存的日志结构文件系统,它巧妙地结合了日志结构组织方式与易失/非易失性内存的特性,利用日志结构修改的原子性和混合内存快速地随机访问性能设计并实现了一套强一致性的操作接口.它为每个索引节点分配一个日志,提高了文件系统读写和恢复阶段的并发性能,针对多个索引节点间的操作,它采用了Journaling的方式保障数据修改的原子性.BPFS[18]是微软公司提出的字节寻址的持久性内存文件系统,它通过修改CPU缓存控制器和内存控制器等硬件的方式来保障数据写入的顺序性,并利用硬件级别的原子写操作和影子技术实现了数据块的原地更新,保障数据的一致性.但是针对跨目录间的数据移动拷贝操作它需要较大的空间记录原子操作的更新,开销较大.PMFS[19]是英特尔公司为持久性内存设计的轻量级文件系统,针对元数据和数据分别采用Journaling和写时复制技术来保障一致性,然而不能同时保障元数据和数据修改的一致性.Ext4-DAX[20]绕过操作系统的页缓存,可以更高效地读写持久性存储设备.针对元数据的修改采用Journaling保障一致性,针对数据的修改未提供类似的机制,所以不能保障数据修改的原子性.Aerie[21]是惠普公司提出的面向持久性内存的文件系统操作接口,实现了应用程序直接读写持久性内存而无需内核的介入,然而其未考虑数据的一致性.除此之外,Wu等人[22]提出的面向持久性内存的文件系统SCMFS,构建在虚拟内存空间之上,并利用内存管理单元将文件系统的地址映射至持久性内存的物理地址,同样未考虑文件系统的一致性.这些工作均是单机的持久性内存文件系统一致性机制研究工作.
2) 面向RDMA持久性内存文件系统一致性机制
在面向RDMA的分布式持久性内存系统下,Islam等人[23]结合RDMA和持久性内存的特性在HDFS基础上实现了分布式文件系统NVFS,它利用RDMA的高性能特性设计并实现了一套高效的网络通信接口,利用字节寻址的持久性内存构建缓冲池,将写前日志和计算的中间结果保存在NVM,这极大提高了系统整体性能,然而它未考虑数据的一致性.Lu等人[13]设计并实现了分布式持久性内存文件系统Octopus,它将文件系统的读写操作与RDMA读写原语相结合起来,实现了一套高性能的远程过程调用和读写接口.同时,利用RDMA的读写和原子操作实现了分布式事务机制,充分发挥RDMA的性能优势,减少了传统事务操作中网络通信和CPU处理所带来的开销.然而,它未考虑本地的数据和元数据一致性.
上述研究工作在一致性方面的相关工作总结如表1所示:

Table 1 Related Works About Consistency表1 一致性机制相关工作
2 分布式持久性内存文件系统一致性机制框架设计
本文提出了一种分布式持久性内存文件系统的一致性机制CCM,其整体系统结构如图1所示:分为客户端和服务器端,服务器端的设计由存储管理、远程过程调用和一致性组成.
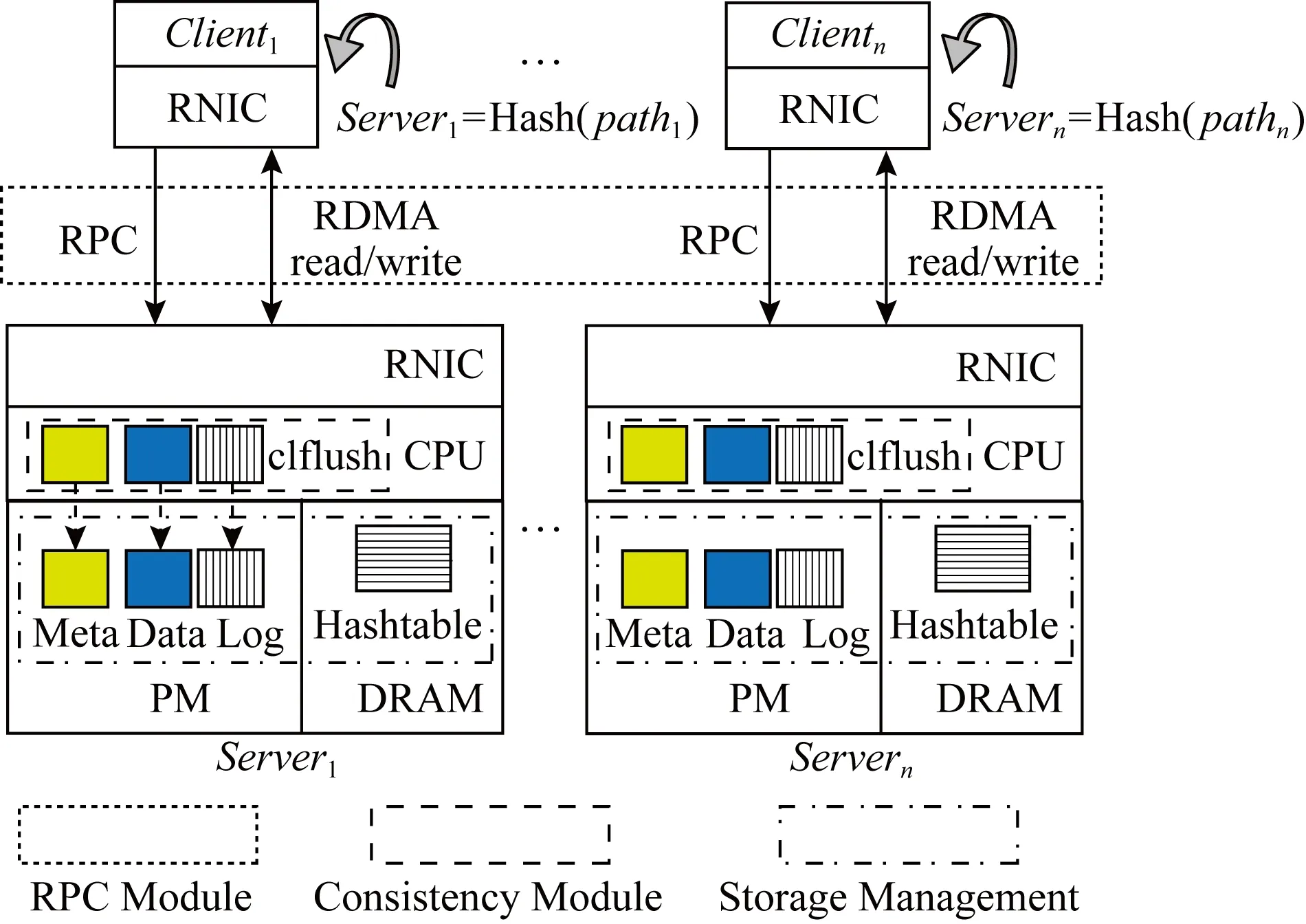
Fig.1 Architecture of CCM图1 一致性机制结构图
2.1 存储管理
服务器端存储管理主要包含元数据和数据管理、Hash索引管理和日志管理3个方面.1)元数据和数据管理:存储于持久性内存,其中元数据区存储着数据文件大小,修改时间和数据地址等信息,数据区存储着文件和目录数据块,存储方式如图2所示,采用写时复制方式,相比于Log-Structure组织方式,能减少垃圾回收的开销.服务器端各数据区组成分布式持久共享内存池,从而能不依赖本地文件系统直接管理数据对象,减少了IO请求在内存中的拷贝.2)Hash索引管理:存储于DRAM,存储着元数据的索引信息,通过Hash表索引文件或目录的元数据,其中每一个条目包含文件名,文件索引节点和指向具有相同Hash值的下一个条目,通过文件全路径可以计算出元数据的索引信息,进而得到索引节点的物理地址.3)日志管理:用于保存文件系统操作的日志,存储于持久性内存.

Fig.2 The layout of metadata and data图2 元数据和数据组织方式
2.2 远程过程调用
如图1所示,客户端与服务器端通信的方式是采用RPC机制,本文使用RDMA write_with_imm原语构建RPC机制,imm_data的内容是客户端标识符,保证全局唯一性,相比于RDMA write原语,可以减少服务器端CPU轮询消息缓存区的时间开销.在数据读写密集的场景下服务器端CPU容易出现瓶颈[16],本文将使用客户端主动读写数据的方式,即客户端发送读写请求至服务器端,服务器端将该请求的元数据(读写内存地址信息)返回给客户端,客户端主动读写服务器端内存,这种方式的好处是:利用RDMA硬件特性将服务器端CPU的处理负载均摊到客户端.
2.3 一致性
面向RDMA的分布式持久性内存文件系统的一致性问题主要来源2个方面:1)CPU不能保障将数据从高速缓存顺序持久化至持久性内存,因此,需要软件系统执行硬件指令强制刷写数据至持久性内存;2)客户端使用RDMA直写操作绕过服务器端CPU将数据直接写入服务器端的内存,此时服务器端CPU没有感知到内存的写入操作,因此也无法执行对应的持久化操作.此外,强制持久化的硬件指令开销高昂,例如,CLFLUSH指令延迟大约200 ns[24],这极大浪费了CPU的处理带宽.
针对服务器端CPU无法主动执行刷写操作的问题,本文设计了一种客户端对服务器端远程写一致性策略,可以获取客户端的写入操作.针对持久化操作开销高的问题,本文实现了一种服务器端的数据异步持久化,该方法通过对元数据、数据和操作日志执行异步持久化来降低持久化操作引入的开销.
3 一致性保障技术
我们面向分布式持久性内存文件系统实现了一致性机制CCM,其关键技术包括3个方面:1)基于操作日志的一致性保障策略;2)客户端对服务器端的远程写一致性;3)服务器端的数据异步持久化.
3.1 基于操作日志的一致性保障策略

Fig.3 Operation log图3 操作日志
操作日志记录着每一次操作的元信息,其内容如图3所示,记录着该操作的类型、日志长度、Inode号、元数据首地址和数据首地址及大小.具体执行过程是:客户端向服务器端执行读写操作,服务器端将该操作的元信息写入日志并持久化,原子更新日志尾指针并持久化,此保障此次操作的一致性.
例如追加写文件A,首先服务器端将旧版本元数据和数据拷贝至新的地址,并对新版本元数据进行修改,此时,操作日志记录操作的类型为追加写,元数据地址为新版本元数据的首地址,数据地址为新版本数据的首地址和文件A即将追加写入的数据大小,然后将待写入数据的地址信息返回给客户端,客户端根据该地址信息写入数据.本系统的一致性依赖于操作日志的尾指针是否持久化,需要保证在所有刷写操作完成之后原子更新日志尾指针并持久化.当系统崩溃时重放日志可恢复到一致性状态,如果日志写入一半,系统崩溃,由于之前的日志状态是一致的,持久性内存的分配信息可恢复,不会出现持久性内存泄漏的问题.
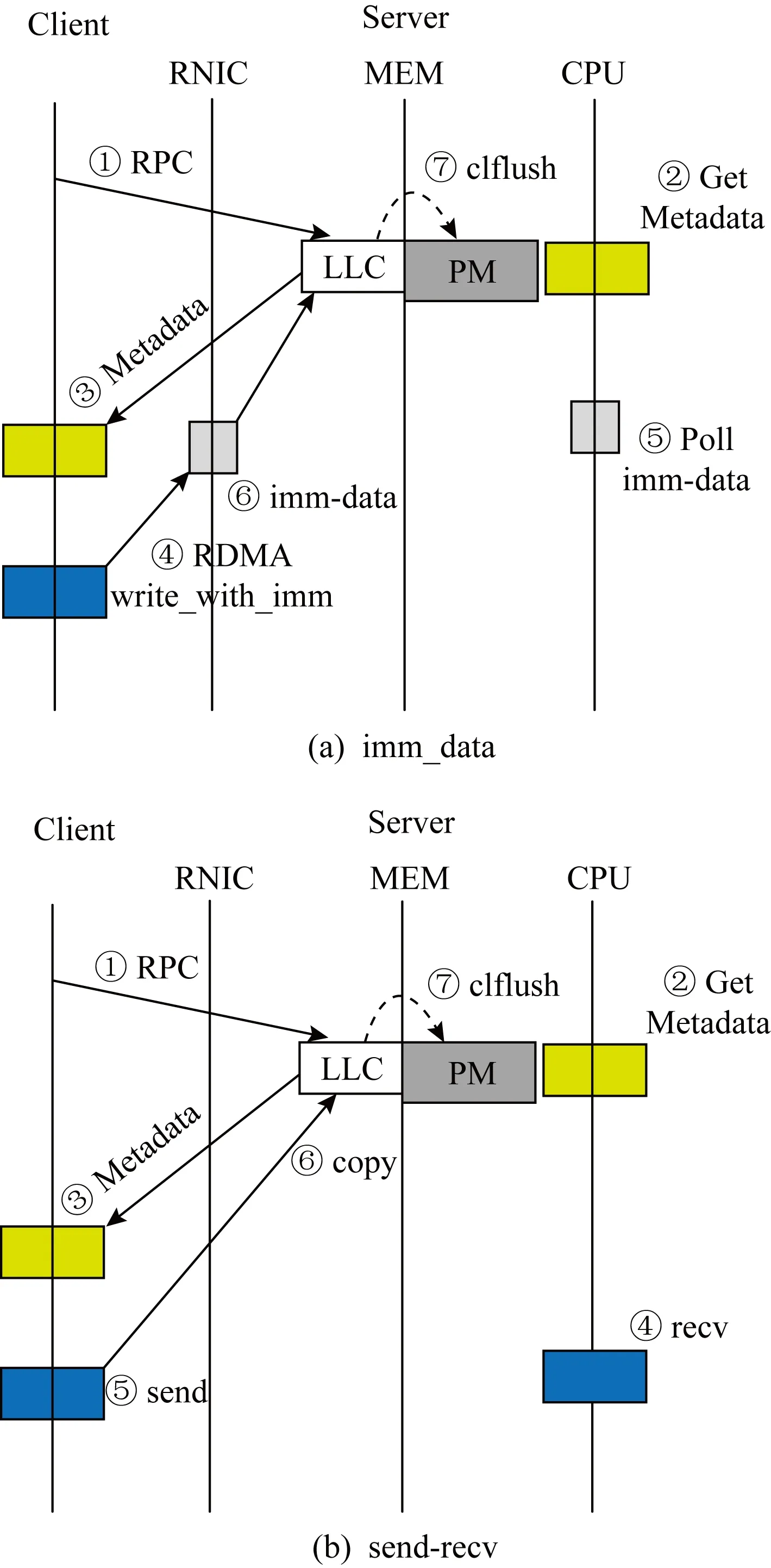
Fig.4 Remote data flushing图4 远程写感知的流程图
3.2 客户端对服务器端远程写一致性
RDMA中客户端主动写操作流程是客户端向服务器端发送写请求,服务器端接收请求后将该请求的元数据返回给客户端,客户端接收元数据后执行RDMA write原语,将数据写入服务器端对应的地址.然而,客户端执行RDMA write原语写服务器端内存的方式存在一个问题,即服务器端CPU对客户端远程写数据的不可感知性,当系统崩溃时,无法保证服务器端的数据持久化.
因此,本文设计了一种客户端对服务器端的远程写一致性策略,使服务器端能感知客户端的写入操作,其流程如图4(a)所示,客户端在接收到元数据后,使用RDMA write_with_imm原语执行远程写,该原语与RDMA write类似,不同点是当执行远程写时,服务器端接收队列消费一个接收请求,获得一个32 b的imm_data和感知客户端的写入操作,进而执行持久化操作.存在另一种方式,使得服务器端也可感知客户端的写入操作,如图4(b)所示,客户端利用RDMA send原语发送数据至服务器端,然后服务器端将数据从接收缓冲区拷贝至指定的地址.相比于RDMA send原语,使用RDMA write_with_imm原语执行远程写操作可减少1次内存拷贝开销.
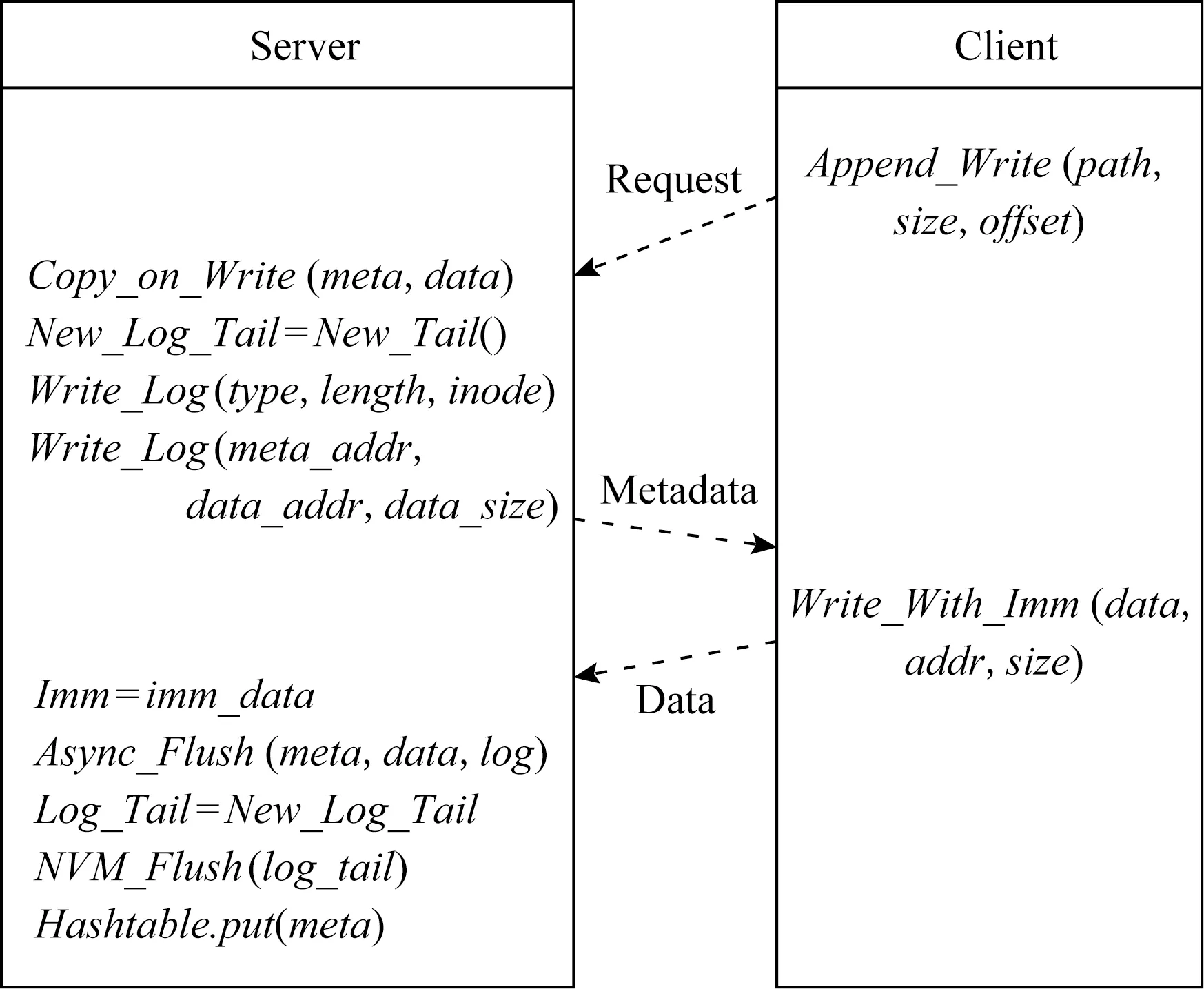
Fig.5 The detailed process of flushing data图5 数据刷写过程
3.3 服务器端数据异步持久化
在数据持久化过程中,CPU刷写操作的开销非常高昂,等待服务器端完成刷写操作会产生较高的延迟,本文不阻塞主线程的执行,通过数据异步持久化,避免了延迟的产生,提高了服务器端CPU的处理效率.异步持久化后的状态信息由客户端维护,即当客户端发起请求时,服务器端通过判断操作日志当前尾指针与上次尾指针的地址大小,将上一次异步请求的持久化状态返回给客户端,让客户端独立管理操作一致性的状态信息.
现在分析不同场景下服务器端使用异步刷写保障一致性的方法.数据刷写过程如图5所示.1)当执行至远程写数据或异步刷写数据时系统崩溃,将部分或全部元数据、数据或日志写入持久性内存,但操作日志尾指针未修改,则重放操作日志会恢复至上一次一致性状态,此次操作的所有记录无效;2)当执行完修改操作日志尾指针时系统崩溃,由于尾指针未执行持久化刷写操作,结果和步骤1相同;3)当执行完刷写操作日志尾指针或更新Hash表时系统崩溃,此时操作日志的尾指针已持久化,表明此次操作所有数据已持久化,通过重放日志可以重新执行此操作,恢复当前一致性状态.
执行异步持久化时,本文为1~16 KB的小文件实现了Batch刷写方法,即基于写入次数或写入数据量批处理优化方法,该方法的好处是可以减少异步线程的调度开销,提高系统性能.
4 实 验
由于一致性机制会影响系统的性能,本节实验将从3个方面对分布式持久性内存文件系统的一致性机制进行测试.1)对比测试客户端对服务器端的远程写带宽的性能;2)测试服务器端数据的异步持久化对写带宽的性能影响;3)同类数据一致性机制写带宽性能测试.
4.1 实验环境
在实验测试中,本文测试的IO大小为1 KB~1 MB,定义1~16 KB的文件为小文件,超过16 KB定义为大文件.使用的实验环境配置如表2所示:客户端和服务器端配置为相同运行环境,当前还缺乏商用的持久性内存设备,本文测试环境使用CLWB和PCOMMIT指令模拟持久性内存操作延迟.

Table 2 Experiment Configuration表2 实验环境配置
4.2 远程写带宽性能测试
本节主要测试客户端对服务器端的远程写带宽,并与客户端使用RDMA send原语发送数据至服务器端的一致性策略进行比较,实验结果如图6所示,客户端使用RDMA write-with-imm原语对服务器端远程写一致性策略在IO大小为1 KB~1 MB时,带宽传输速率提升9%~45%,主要原因是该策略减少一次内存拷贝开销.客户端使用RDMA send原语将数据发到给服务器端时,服务器端CPU需从缓冲区将数据拷贝到数据区,这一次的内存拷贝影响了服务器端CPU的处理能力.
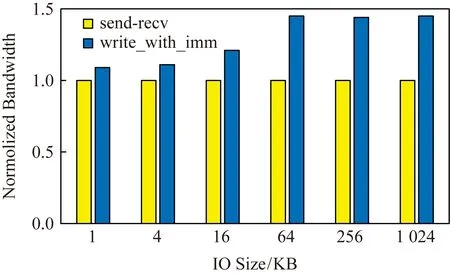
Fig.6 Write bandwidth of RDMA verbs图6 RDMA不同原语写带宽测试
4.3 数据异步持久化对写带宽性能影响测试
本节实验使用的IO大小范围为1 KB~1 MB,实验结果如图7所示,在IO大小为1 MB时,异步持久化的写带宽相比同步刷写模式提升了7倍左右,这是由于同步刷写大文件耗时长从而影响了服务器端CPU的处理能力,而异步线程刷写过程大文件并不影响主线程的执行效率.当IO大小为1~16 KB之间时,异步持久化的写带宽性能低于同步刷写,主要是异步线程占用的资源过多,为此本文设计了Batch的优化方法,明显提高了小文件刷写的性能,当IO大小为4 KB和16 KB时,写带宽性能分别提高2.5倍和1.4倍.

Fig.7 Write bandwidth of sync and async图7 同步和异步写带宽测试
综合以上优化方法,服务器端使用数据异步持久化后,实验结果如图8所示,采用write-with-imm原语的一致性机制CCM相比使用send-recv原语的一致性机制具有更高的写带宽,当IO大小为256 KB和1 MB时,前者较后者写带宽性能提升29%和35%,主要原因是前者减少1次内存拷贝,在RDMA作为网络通信方式时,该拷贝所带来的时间开销会严重影响服务器端的处理效率.在IO大小为1 MB时,分布式持久性内存文件系统的一致性机制CCM写带宽达到5 582 MBps,与Octopus(5 629 MBps)相比,性能影响控制在1%以内,相比于原生的网络带宽(6 305 MBps),写带宽性能达到88%.

Fig.8 Impact of consistency mechanism图8 一致性机制对写带宽的影响测试
4.4 同类数据一致性机制写带宽性能测试

Fig.9 Write bandwidth of consistency mechanism图9 不同一致性机制写宽带测试
本节实验的对比对象为Ordered Journaling一致性机制,实验结果如图9所示,当IO大小为1 MB时,Ordered Journaling的一致性机制写带宽为5 389 MBps,相比于Octopus,对写带宽性能的影响为5%,而本文所设计的一致性机制CCM的写带宽为5 582 MBps,相比于Octopus,对写带宽性能的影响为1%,这主要是因为Ordered Journaling机制会存在元数据重复写的开销,而CCM设计了基于操作日志的一致性保障策略,避免了多余的写操作.
5 总 结
非易失性内存具有字节寻址、低功耗和读写性能接近DRAM等特性,有望代替DRAM成为新的主存器件.RDMA能有效提高吞吐率、降低网络通信延迟,为设计高效的分布式文件系统提供了支撑.本文的工作建立在我们之前的工作Octopus之上,为分布式持久性内存文件系统提供一致性保障.本文设计了一种客户端对服务器端远程写一致性策略和实现了服务器端的数据异步持久化.实验结果表明,相比于Octopus,分布式持久性内存文件系统一致性机制对写带宽性能的影响控制在1%以内.
