基于混合神经网络和注意力机制的软件缺陷自动分派方法
2020-03-21黄金筱马于涛
刘 烨 黄金筱 马于涛
(武汉大学计算机学院 武汉 430072)(ye_liu@whu.edu.cn)
当前,以GitHub(1)https://github.com为代表的互联网上开源、开放的社交化软件开发环境已然成形并逐渐流行起来.在这种环境下以社群(community)为主体的群智化软件开发方法[1],通过自由竞争与合作创新,有望真正释放软件开发者乃至软件用户的生产力和创造力(也有学者称之为“群智之力量”[2]),正在改变或将重塑商业软件的传统开发方式[3].例如,继将.NET框架在GitHub上开源后,微软公司还计划把Windows操作系统发布为开源软件.
互联网上的群体协作被认为是这种新型开发方法的主要特点[4].然而,在网络社群松散的组织结构(相对于公司的严格管理)下,如何通过群体协作来确保软件质量就成为一个重要的研究问题.软件缺陷修复作为软件演化与维护中的重要一环,是目前软件质量保证常用的一种手段.随着软件项目规模的日益增长(生态化发展趋势),如何提升缺陷修复的效率和效果已成为群智化软件开发与维护亟待解决的问题,受到了学术界和工业界的共同关注.
绝大多数的软件项目通常会采用缺陷跟踪系统(bug tracking system, BTS)来追踪和管理缺陷的修复过程[5],如Bugzilla(2)https://www.bugzilla.org.BTS为追踪缺陷报告的状态提供了一个公共平台.当开发者或用户发现缺陷后,便可以在BTS中创建相应的缺陷报告并进行提交,一旦该缺陷报告被确认,它就开始了其生命周期,直至最后被修复而关闭(closed).在这个过程中,缺陷分派(bug triaging)是指将一个新的缺陷报告分配给一个合适的开发者进行修复的活动[6].考虑在此期间缺陷报告会被开发者评论、重新分配(reassign)乃至修改,缺陷分派在本质上是一个集群体智慧进行协作的过程,最后提供修复者(fixer)推荐服务.
2001-10—2010-12期间,知名开源项目Eclipse(3)https://www.eclipse.org在Bugzilla上提交的缺陷报告超过33万个,平均每天有90个缺陷报告等待处理,而参与Eclipse项目的开发者超过1 800人.人工分配不仅耗时耗力,而且容易造成缺陷的重新分配(主要是因为指派的开发者不合适).在过去的数年中,基于机器学习的自动分派方法已取代人工分配方法,减少了缺陷修复所耗费的人力成本和时间成本.根据文献[7]的分析,已有的缺陷自动分派方法主要分为3类:基于文本分类(text classification)的方法、基于再分配图(tossing graph)的方法以及混合方法.其中,基于文本分类的自动分派方法已成为主流技术,其主要思路是从已修复的缺陷报告中学习表征缺陷与修复者之间关系的文本特征,再针对新的缺陷报告预测可能的开发者.近年来,随着深度学习在自然语言处理(natural language processing, NLP)领域的成功应用,研究者开始尝试利用词向量化(embedding)和深度学习技术来进一步提高缺陷自动分派的准确率.
然而,在这些方法中常用的卷积神经网络(con-volutional neural network, CNN)和循环神经网络(recurrent neural network, RNN)也存在一定的局限性.一方面,CNN利用卷积核捕捉文本的局部信息来构建特征,但容易丢失文本的序列信息;另一方面,RNN能捕捉文本的序列信息,但缺乏捕捉文本的局部信息的能力.针对上述问题,本文提出了一种基于混合神经网络和注意力机制的缺陷自动分派方法Atten-CRNN.该方法利用CNN与RNN各自的优点来充分地学习缺陷报告中的(局部)文本特征与序列特征.此外,该方法也利用注意力机制学习CNN抽取的各个文本特征的权重,用于加强文本特征对最终分类效果的影响,从而提高缺陷报告分配的准确率.
本文的主要贡献有3个方面:
1) 针对缺陷报告包含的文本信息,我们提出了一种结合CNN和RNN各自优势的混合神经网络模型,用于更全面地捕获文本特征和序列特征;
2) 在混合神经网络模型中引入注意力机制,通过学习获得的文本特征对于分类的贡献程度(权重),进一步提高文本分类的效果;
3) 在2个大型开源软件项目(本质上是包含众多子项目的2个软件生态系统)Eclipse和Mozilla(4)https://www.mozilla.org的数据集(分别包含20万和22万个已修复的缺陷报告)上进行了验证,实验结果表明Atten-CRNN在预测准确率方面优于选定的基准模型.
1 相关工作
缺陷自动分派常用的方法是将缺陷分派问题转换为文本分类问题,再利用机器学习的方法预测可能的开发者.Cubranic等人[8]率先从缺陷报告的标题以及评论字段的文本内容中提取关键字作为特征,用词袋模型(bag of words, BOW)来表示每个缺陷报告,然后训练出基于条件独立假设的朴素贝叶斯(naïve Bayes, NB)模型.因此,对于新提交的缺陷报告,可以将其分配给后验概率最大的开发者.随后,Anivk等人[6]在Cubranic等人的工作上进行了改进,他们过滤掉训练集中无效的缺陷报告和修复缺陷次数低于9次的开发者,并通过实验证明了支持向量机(support vector machine, SVM)模型能够取得更好的结果.Xuan等人[9]提出了一种基于半监督学习的缺陷自动分派方法,将最大期望算法(expectation maximization, EM)与NB模型相结合,用以提升分类的性能.此外,基于主题模型(topic model)的方法则利用抽取的主题来衡量缺陷报告之间以及缺陷报告与开发者技能之间的相似性,进而给出预测结果.文献[10-12]对隐狄利克雷分配(latent Dirichlet allocation, LDA)模型[13]进行了改进,在Eclipse等项目上取得了不错的预测效果.
虽然基于传统机器学习算法的缺陷自动分派方法能够在一定程度上提升工作效率,但仍存在人工构建特征、文本表示能力有限等问题.近几年随着深度学习的飞速发展,研究者开始将深度学习引入到缺陷分派领域,取得了优于传统机器学习算法的效果.胡星等人[14]提出了一种基于深度学习的缺陷分派方法,选取缺陷报告中的标题、描述、所属产品及组件字段的内容作为文本信息,分别利用CNN模型以及长短期记忆模型(long short term memory,LSTM)进行开发者预测.Lee等人[15]也将CNN模型应用于缺陷自动分派中,并从工业应用的角度解决了多语言问题;与胡星等人工作不同的是,Lee等人考虑了开发者的活跃度,进一步提高了预测准确率.类似地,宋化志等人[16]也提出了基于CNN模型的缺陷自动分配方法,并验证了其效果优于SVM和LSTM.Florea等人[17]则采用并行的CNN与RNN来解决该问题,与前面方法不同的是,该方法采用了Paragraph2Vec对文本进行分布式词袋表示(简称PV-DBOW),并利用并行方式加速模型的学习.
另一方面,席圣渠等人[18]提出了一种基于RNN模型的缺陷分派方法,该方法利用双向长短期记忆模型(bi-directional long short term memory,Bi-LSTM)和池化(pooling)的方法来提取缺陷报告中的文本特征,再利用LSTM模型提取特定时刻的开发者的活跃度特征.结合上述2种特征,使用监督学习算法进行学习.Mani等人[19]提出了一种基于Bi-LSTM 和注意力机制的DBRNN-A模型,将缺陷报告的标题与描述作为缺陷报告的文本内容,使用未分配的缺陷报告作为训练集来训练特征器,使用已分配的缺陷报告训练分类器,以此来提高模型的泛化能力.Xi等人[20]提出了一种SeqTriage模型来进行开发者的预测,该模型是一种Seq2Seq模型,利用缺陷报告的文本内容作为编码器(encoder)的输入,得到相应的文本特征,再将该文本特征、缺陷报告提交者、上下文特征作为解码器(decoder)的输入,预测可能的修复者.
基于上述分析,与本研究相关的基于深度学习的缺陷自动分派相关工作的总结如表1所示:
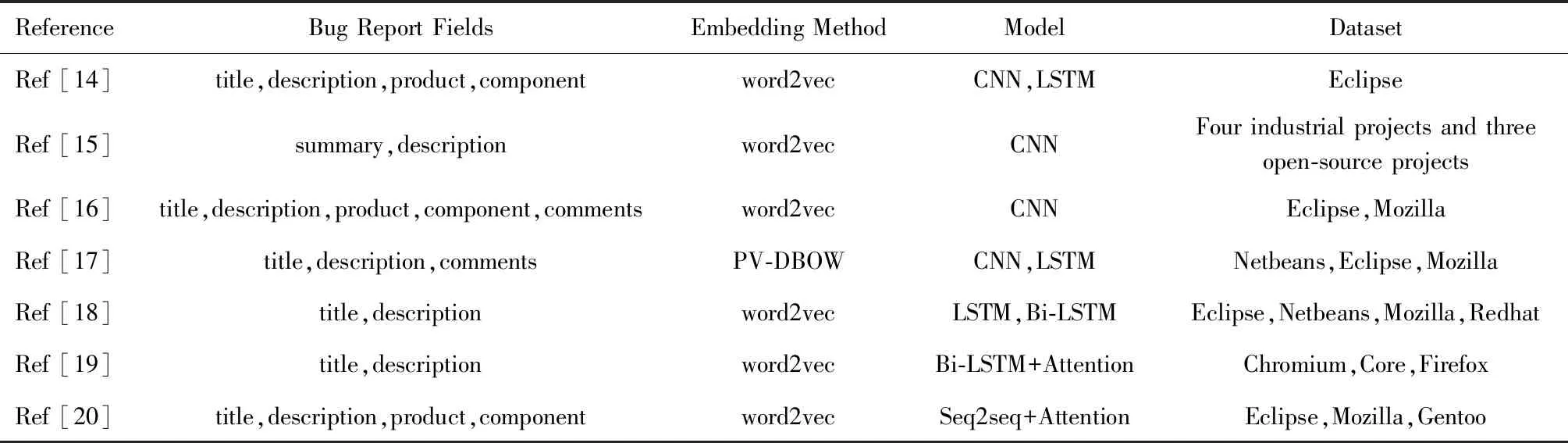
Table 1 Summary of Related Work Based on Deep Learning表1 基于深度学习的相关研究工作总结
2 预备知识
2.1 缺陷报告
如引言所述,Bugzilla作为一种缺陷跟踪系统,常被一些软件项目用于追踪和管理缺陷的修复过程.例如在Eclipse项目中,当一个软件缺陷被发现时,开发者会使用缺陷报告来记录软件缺陷的详细信息,并将其提交到Bugzilla系统中.一个正规的缺陷报告(如6807号(5)https://bugs.eclipse.org/bugs/show_bug.cgi?id=6807)主要包括预定义字段、缺陷描述字段、缺陷修复历史记录、评论字段和相关附件字段.
缺陷报告的预定义字段主要包含bug ID(编号)、title(标题)、status(状态)、reported(提交者及提交时间)、product(所属产品)、component(所属组件)、version(版本)、importance(优先级与重要性)等属性.这些字段描述了软件缺陷的属性信息以及状态信息,其中部分字段在软件缺陷生命周期的不同时段会发生改变.
缺陷报告的描述字段主要包括description(详细描述)和comments(评论),用于对软件缺陷进行详细描述,以及记录开发者对解决该缺陷所进行的讨论与建议.从以往的研究工作来看,这部分内容对于分配给合适的开发者来解决给定的软件缺陷起着重要作用,因而需要加以利用和分析.
缺陷修复历史记录字段主要记录了缺陷的处理情况及状态变化.每条记录包含Who,When,What,Removed和Added 5个属性,描述了开发者对某一个软件缺陷实施操作的历史行为.从该历史记录中可以获得软件缺陷的最终修复者,以及该缺陷被成功修复的时间.此外,相关附件字段为attachments(附件),主要是用于管理开发者提交的与该软件缺陷有关的其他信息.
2.2 注意力机制
近年来,注意力机制被广泛应用于基于深度学习的NLP和计算机视觉各个任务中.例如,Google在2017年提出了针对NLP翻译任务的Multi-head self-attention模型[21],该模型是一种摒弃了RNN架构的Self-Attention,Scaled-Attention作为该模型的一部分(其具体使用情况讨论见4.6节),其计算:
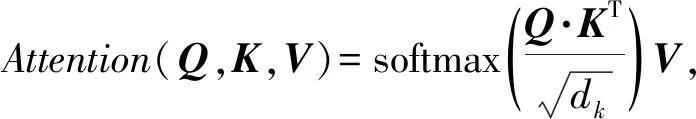
(1)
在计算机视觉领域,Chen等人对常用的Soft-Attention进行了改进,提出了Channel-wise-Attention(CWA)和Spatial-Attention(SA)[22]2种新的注意力机制,并在图像描述(image captioning)任务中取得了良好的效果.在该工作中,CWA模块和SA模块被添加在CNN模型的池化层和全连接层之间.对于N个同样大小的卷积核而言,经过卷积与池化后,从图像中抽取的是不同的特征(一种卷积核抽取一种特征).通过对不同特征以及目标结果(如通道和位置)进行学习,能得到不同特征图的贡献值(即注意力权重).再将注意力权重与特征图进行相乘,对有积极作用的特征图进行强化,对无积极作用的特征图进行弱化,从而达到提高模型效果的目的.CWA模块的实现表示:
b=tanh((Wc⊗v+bc)⊕Whcht-1),
(2)

(3)

不同于CWA计算各个通道上特征图的注意力权重,SA(其具体使用情况讨论见4.6节)计算同一特征图中不同像素点(位置)的注意力权重.通过将特征图中不同通道对应位置的值进行相乘并求和,将特征图从三维结构压缩到二维结构,再将各个位置元素的值映射到0-1之间,即为特征图中基于位置的注意力权重.类似地,SA模块的实现:
a=tanh((WsV+bs)⊕Whsht-1),
(4)
α=softmax(Wia+bi),
(5)
最后,将该注意力权重与原始特征图进行相乘,得到对应的新的特征图.
3 缺陷自动分派方法
3.1 方法框架
本文所提出的基于混合神经网络模型与注意力机制的缺陷自动分派方法,其整体流程主要包含3个步骤:
步骤1.数据预处理.对收集到的缺陷报告数据集进行清洗与整理,包含从原始数据集中提取每个缺陷的修复时间、修复者、所属产品、所属组件、标题、描述以及评论.实施的预处理工作主要包括:
① 在数据集中的缺陷所属产品与所属组件字段存在大量的专业术语缩略词,如UI,API等.本文对上述缩略词进行了替换,如使用user interface替换UI.
② 对缺陷修复时间进行了时区转换,便于在统一的时间标尺上进行分析.
③ 将每个缺陷的标题、描述以及评论整合成一个文本,并对其进行分词、去除停用词、去除数字与非字母、提取词干等操作.此外,将所属产品和所属组件信息与上述预处理后的文本进行合并,形成最终的缺陷报告文本内容.
步骤2.增量学习(incremental learning)与验证.按照缺陷修复时间对数据集进行升序排序,并将数据均分为11份,并采用“十折增量学习”[23]的方法进行训练与验证.在第1轮时,使用第1份数据作为训练集,第2份数据作为测试集;在第2轮时,使用第1份和第2份数据作为训练集,第3份数据作为测试集;依此类推,到第10轮时,以第1份到第10份数据作为训练集,第11份数据作为测试集.该部分包含4步:
① 利用给定的训练集对分类模型进行训练.主要通过CNN模型提取缺陷报告的文本特征,以及利用RNN模型提取缺陷报告的序列特征,具体内容见3.2.1节.
② 利用注意力机制对CNN模型提取出来的文本特征进行进一步学习与加强,并将加强后的文本特征与序列特征结合,再使用该组合特征进行分类模型的训练,具体内容见3.2.2节和3.2.3节.
③ 使用测试集进行预测.将测试集进行同样的文本处理后作为分类模型的输入,得到所有开发者的概率值排名,然后推荐前k个开发者作为给定缺陷的候选修复者.
④ 计算分类模型的评价指标值.
步骤3.对分类模型的预测效果进行评价.由于使用了“十折增量学习”方法对分类模型进行训练,使用10轮预测结果的均值作为该分类模型的最终评价效果.
3.2 分类模型
本文所提方法的核心是基于混合神经网络模型与注意力机制的缺陷修复者分类模型Atten-CRNN,主要是基于深度学习中的卷积神经网络CNN与循环神经网络RNN以及注意力机制CWA模块,其结构如图1所示.
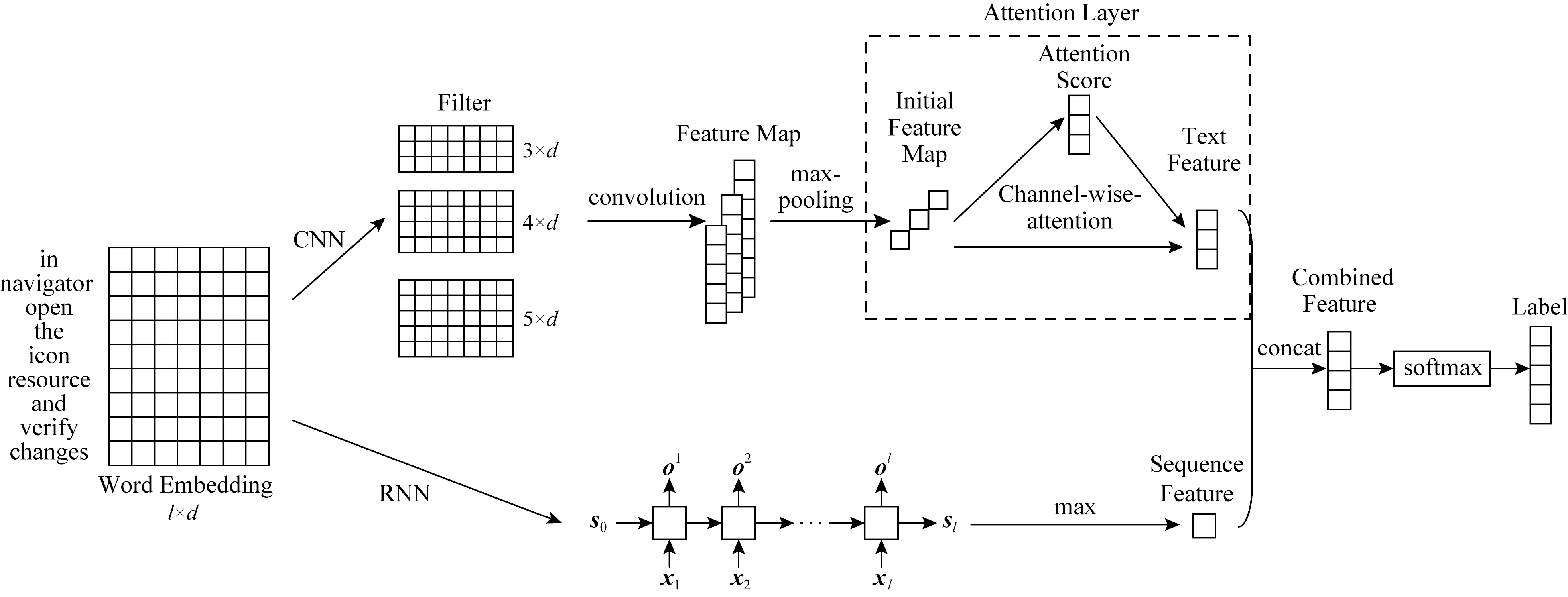
Fig.1 Diagram of the Atten-CRNN model图1 Atten-CRNN模型的结构图
3.2.1 文本特征抽取
CNN具有善于捕捉文本局部特征(类似于N-gram语言模型)的优势,却很难获取文本的长距离语义特征以及文本的序列特征.另一方面,RNN作为一种循环递归模型,能够捕获文本的序列特征和进行长距离记忆.因此,本文利用CNN与RNN抽取缺陷报告的(局部)文本特征以及序列特征.文本特征与序列特征的抽取主要包含3个步骤:
步骤1.和表1中列举的方法一样,本文也利用word2vec[24]进行词向量化.假设一个文本的长度为l,缺陷报告文本词汇表大小为D,使用one-hot编码对文本进行表示,则文本可用0-1矩阵l×D表示.在经过word2vec进行词向量化后(词向量维度设置为d),该文本便可使用一个维度为l×d的矩阵表示.
① 卷积操作.使用3×d,4×d,5×d大小的卷积核对文本矩阵S进行卷积操作,即使用参数矩阵Wj×d(j=3,4,5)从上向下滑动并与文本矩阵进行相乘,表示为
Sj=Wj×d·S[i:i+j-1],
(6)
② 池化操作.对卷积操作后得到的文本特征向量进行池化,即对于每一个特征向量,保留向量中的最大值作为对应的文本特征:
vj=max(Sj),
(7)
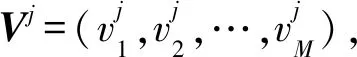
(8)

步骤3.利用LSTM提取序列特征.将经过word2vec词向量化后的文本向量作为LSTM模型的输入,可得到l个输出结果{o1,o2,…,ol},选取每个输出向量中的最大值来构成LSTM模型抽取的序列特征向量z:
z=(max(o1),max(o2),…,max(ol)).
(9)
3.2.2 利用注意力机制强化文本特征
CNN模型特有的卷积结构使得不同的卷积核能从文本内容中学习到不同的文本特征,类似于图像的特征图.借鉴CWA对不同通道的特征图及其关系进行学习的思想,本文希望得到各个文本特征对于分类结果的贡献程度,将其作为权重加入到文本特征中,从而通过强化对于分类结果有积极作用的文本特征来提高最终的修复者分配准确率.因此,在CNN模型的最后一层加入改进后的CWA来学习文本特征的注意力权重.该过程主要分为2个步骤:
传统生物课堂教学主要是以教为中心,教师以知识传授者的身份出现,是学生学习的主要信息源,并且教师在整个教育过程中控制着学生的学习过程。在传统教学中,教师的教学行为主要表现以下几个方面。
1) 权重(重要程度)的学习.针对M个大小为j的卷积核抽取的文本特征,学习各个文本特征影响分类效果的重要程度(即权重向量aj),由于这里没有同时使用LSTM进行序列特征提取,改进后的CWA模块:
cj=tanh(Wj⊗Vj+bj),
(10)
aj=sigmoid(cj),
(11)
2) 更新文本特征.利用注意力模型学习各个文本特征的重要程度,并将其与原来的文本特征进行相乘,从而获得更新后的文本特征.
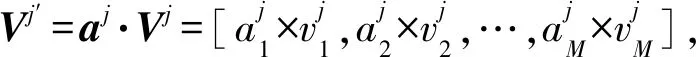
(12)
3.2.3 特征融合与分类
进一步地,将强化后的文本特征V′=[V3′,V4′,V5′]与序列特征z进行融合,输入到分类模型中进行预测,具体操作:
t=concat(V′,z).
(13)

(14)
(15)
最后,将最小化分类的交叉信息熵作为损失函数(如式(15)所示),利用给定的训练集按照算法1训练分类模型.
算法1.基于混合神经网络模型与注意力机制的缺陷自动分派算法.
输入:训练集TrainingText、训练集标签TrainingLabel;
输出:Atten-CRNN模型的参数集合.
/*生成batch样本集*/
① {(Batch_Xs,Batch_Ys)}=batches_
generator(TrainingText,TrainingLabel);
② FORBatch_X,Batch_YIN {(Batch_Xs,Batch_Ys)}
/*词嵌入操作*/
③X=embedding(Batch_X);
/*CNN模型提取文本特征*/
④Conv_X=relu(W1⊗X+B1);
⑤Pool_X=max_pool(Conv_X);
/*CWA学习文本特征权重*/
⑥Tmp_C=tanh(W2⊗Pool_X+B2);
⑦Weight_C=sigmoid(Tmp_C);
⑧Weight_X=Wight_C·Pool_X;
⑨Feature_CNN=concatenate(Weight_X);
/*RNN模型(LSTM)提取序列特征*/
⑩Outputs=LSTM(X);
/*特征组合*/
Feature_RNN);
/*分类器训练*/
Function并更新变量:W1,B1,W2,
B2,W3,B3;
4 实验设计与结果分析
4.1 数据收集
本文使用Bugzilla中关于Eclipse与Mozilla两个大型软件项目(软件生态系统)的历史缺陷报告数据进行验证,原始的实验数据集(6)https://github.com/ssea-lab/BugTriage来源于文献[25],其概要情况如表2所示.在该数据集中,所有收集的缺陷报告均为已修复的,即状态为VERIFIED、决议(resolution)为FIXED.

Table 2 Experimental Dataset Used for Bug Fixer Classification表2 缺陷修复者分类实验数据集
该数据集中包含关于Eclipse与Mozilla两个项目的缺陷描述信息(包括缺陷编号、缺陷所属组件、缺陷所属产品等信息),文本信息(包括标题、描述与评论),以及缺陷修复历史记录(包括修复时间、修复者、缺陷状态变化等).对于缺陷报告的类别设定,本文将最后一个解决缺陷的开发者作为最终的类别标签(即修复者),而不是考虑所有在缺陷分派过程中出现的开发者以及发表过评论的开发者.虽然这是一个群体协作的过程,但最终的修复者是唯一的.此外,开源软件社区中的开发者流失现象是普遍存在的,会对缺陷修复者的推荐效果造成一定的影响.因此,为规避这种影响带来的风险,本研究做了假设:这2个大型项目有长期稳定的核心开发和维护人员.
4.2 基准方法
根据表1的分析,深度学习模型在Eclipse等数据集上的分类效果要明显优于NB,SVM等传统的机器学习算法[6,8,25].此外,word2vec在抽取文本特征方面要优于LDA和词频-反文档频率(term frequency-inverse document frequency, tf-idf)[26]技术.因此,我们将近3年提出的基于CNN,RNN和注意力机制的缺陷自动分派方法作为基准方法(主要包括3类)来验证本文所提方法的有效性.
1) 基于CNN模型的缺陷自动分派方法.这类方法的核心是设计CNN架构的(文本)分类模型,相关工作主要包括文献[14-17],而它们之间最大的区别在于CNN模型的具体实现,如卷积层、池化层、参数调优等.因此,在本文中我们将CNN模型作为一类基准方法,而不再特指某篇具体的文献.
2) 基于RNN模型的缺陷自动分派方法.RNN因其链式递归结构能够处理序列数据,并且能够捕获文本的序列特征和进行长距离记忆,在NLP任务中具有天然的优势.于是,文献[14,17-18]都提出了使用LSTM架构的分类模型来解决缺陷分派问题.由于文本中包含的上下文信息也在一定程度上影响模型的分类效果,一些已有工作[18-19]尝试使用Bi-LSTM架构的分类模型,并在相关任务中被证明其效果优于LSTM模型.
3) 基于深度学习和注意力机制的缺陷自动分派方法.例如文献[19]利用Bi-LSTM架构和注意力机制训练预测模型,而文献[20]则使用Encoder-Decoder架构和注意力机制来提取对分类更有用的文本特征.如本节所述,我们也将不同类型的神经网络架构和注意力机制组成的模型作为一类基准方法.
4.3 评价指标
参考文献[8,16,27-28],本文采用准确率(命中率)作为缺陷自动分派方法分类结果的评价指标.在这里准确率是指,对于给定的测试数据集,缺陷自动分派方法正确分类的缺陷报告数与总缺陷报告数之比,定义:

(16)
其中,Accuracyk表示Top-k的准确率,Nk表示缺陷报告中分类正确的缺陷报告数,N表示缺陷报告总数.选取预测分数排名前k的开发者作为候选修复者,如果其中存在与真实标签相同的结果,那么分类正确.例如,Top-5是指为某个缺陷选取预测出的前5名开发者,若其中存在实际修复者,则分类正确.
此外,本文也使用浮点运算次数(floating point operations,FLOPs)和参数量#Parameters这2个常用量化指标来评估不同方法的(时间)效率.在确定的硬件资源条件下,方法的效率与计算开销成反比.相关结果使用TensorFlow(7)https://www.tensorflow.org中相应的函数计算得到.
4.4 实验环境及参数设置
本文所有实验是在Dell T5810 Precision工作站上进行的.该工作站硬件配置如下:8核Intel Xeon E5-1620 V3 处理器、16 GB内存、华硕GTX 1080显卡;其软件环境配置为:Ubuntu 16.04(64位)操作系统,Python 3.6.7语言及编程环境,TensorFlow 1.1.0、CUDA(Compute Unified Device Architecture)8.0深度学习工具集,以及NLTK(8)https://www.nltk.org3.2.2 NLP工具.
为保证对比实验的一致性和公平性,实验中采用word2vec模型作为词向量模型,并设置词向量维度为300;CNN架构模型的卷积核的大小均设置为3,4,5,每种大小的卷积核的个数设置为150[16];对于RNN架构模型,设置其隐藏神经元个数为150;各种模型均采用Dropout方法进行正则化处理,取值为0.5;激活函数采用线性整流函数(rectified linear unit, ReLU);其他参数均为所使用软件工具的默认设置.
4.5 实验结果
4.5.1 不考虑注意力机制的对比结果
根据4.2节的分析,选取CNN,LSTM,Bi-LSTM 3种架构的分类模型作为基准模型,与CRNN(Atten-CRNN不考虑注意力的变体)进行对比实验.对4种模型均采用“十折增量学习”的模式进行训练,并使用10轮预测准确率的均值作为最终的评价结果,如表3所示.由于篇幅限制,这里只展示CRNN模型在10轮中的所有预测结果,如表4所示.
从表3可以看出,在Eclipse和Mozilla项目中,CRNN模型在Top-1~Top-5上的预测准确率均高于3种基准模型.相对于Bi-LSTM模型而言,CRNN模型准确率的提升幅度最大.在Eclipse项目中,CRNN模型在Top-1~Top-5上比Bi-LSTM模型分别提升了31.94%,30.74%,29.70%,29.49%和17.72%;在Mozilla项目中,前者比后者的预测准确率,提升了59.42%,49.03%,45.02%,38.21%和35.47%.

Table 3 Performance Comparison of Four Classification Models on the Experimental Dataset表3 4种模型在实验数据集上的效果比较
Note: Numbers shown in bold font indicate the best prediction results.

Table 4 Prediction Results of CRNN in the ten-fold Incremental Learning Process表4 CRNN模型在“十折增量学习”中的预测结果 %
此外,就方法的效率而言,从FLOPs和参数量2个指标(值越小越好)来看,CRNN模型要优于Bi-LSTM模型,但比LSTM模型略差,也不如CNN模型.考虑到上述这些模型使用了相同的词向量方法(word2vec),在计算表3中的参数量时并没有包含嵌入层的参数量(14.180×106).
虽然文献[14,18]的实验结果表明,在解决基于文本分类的缺陷自动分派问题上,RNN架构的分类模型能取得优于传统机器学习算法的预测效果,并且与CNN架构分类模型的效果没有明显的差别.然而,根据本文的实验结果,LSTM模型的预测效果要明显劣于CNN模型,但仍然优于Bi-LSTM模型.这可能是因为数据集中缺陷报告的文本内容,特别是描述及评论字段,包含了大量的非正式化的语言表述,导致其上下文关联性较弱,在一定程度上削弱了文本的序列特征.
上述推断也可以在CRNN模型与CNN模型分类效果的对比中得到验证.相对于CNN模型而言,CRNN模型还抽取了文本的序列特征,但在Top-1~Top-5上准确率的提升幅度,在Eclipse中的范围变化从Top-4的4.80%到Top-5的6.81%,在Mozilla中的范围变化从Top-5的4.09%到Top-1的10.01%.上述结果表明抽取的序列特征会影响最终的预测结果,但是对分类效果的影响有限.
4.5.2 基于注意力机制的对比结果
进一步地,为了验证注意力机制是否有助于提升分类模型的预测效果,仍旧选取CNN,LSTM,Bi-LSTM 3种架构的分类模型作为骨架(backbone),然后引入注意力机制,与本文所提出的Atten-CRNN模型进行对比实验,评价方法与4.5.1节中的一致.4种基于注意力机制的分类模型在实验数据集上的效果对比结果表5所示.由于篇幅限制,这里也只展示本文所提出的Atten-CRNN模型在10轮中的所有预测结果,如表6所示.

Table 5 Performance Comparison of Four Attention-based Classification Models on the Experimental Dataset表5 4种基于注意力机制的模型在实验数据集上的效果对比
Note: Numbers shown in bold font indicate the best prediction results.
从表5可以看出,本文所提出的Atten-CRNN模型在2个项目中的准确率(Top-1~Top-5)均明显高于3种基准模型.比较而言,Atten-CRNN模型的准确率明显高于Bi-LSTM+Attention模型,并且在Eclipse项目中,Atten-CRNN模型的准确率在Top-1~Top-5上较Bi-LSTM+Attention模型分别提升了108.09%,77.47%,61.81%,53.79%和48.63%;在Mozilla项目中,前者比后者的预测准确率提升了170.30%,135.21%,116.92%,105.26%和97.08%.对于CNN+Attention而言,Atten-CRNN的准确率也仍有提升.其中,在Eclipse项目中,Atten-CRNN模型在Top1~Top-5上的提升幅度分别为5.31%,3.69%,5.72%,4.70%和4.88%;在Mozilla项目中,该模型的预测准确率分别提升了3.31%,5.54%,5.95%,5.53%和4.99%.因此,引入注意力机制后,Atten-CRNN模型可以更好地捕捉对分类任务有积极作用的文本特征,通过对有积极作用的文本特征进行加强,从而提升预测的准确率.
通过比较表3和表5可以发现,引入注意力机制后,所有模型的FLOPs和参数量2个指标的值都出现了不同程度的增长.这表明使用注意力机制会增加算力和时间的开销,在一定程度上降低效率.总的来说,Atten-CRNN模型在效率方面要优于使用注意力机制的Bi-LSTM模型,但比使用注意力机制的LSTM模型略差,也不如使用注意力机制的CNN模型,这与4.5.1节中的结果是吻合的.
4.6 讨 论
本节主要用于讨论注意力机制的位置选择(即使用注意力机制用于加强文本特征还是序列特征)和种类选择对缺陷自动分派方法准确率的影响.为保证实验的一致性,这里采用了与4.4节相同的参数配置.
4.6.1 注意力机制的位置选择
理论上,注意力机制可用于单独加强文本特征、单独加强序列特征,或者同时加强二者.分别对混合模型CRNN中的CNN层添加CWA机制(图2中用“Text feature”表示),对RNN层添加CWA机制(图2中用“Sequence feature”表示),同时对CNN层与RNN层添加CWA机制(图2中用“Both”表示),在Top-5上的预测结果如图2所示:

Fig.2 Effect of the location of attention on the Top-5 prediction results图2 注意力机制的位置对Top-5预测结果的影响
如图2所示,不论是在Eclipse项目中还是在Mozilla项目中,单独使用CWA注意力机制用于强化文本特征的分类效果最好(分别达到了63.31%和49.00%),但是单独强化序列特征的分类效果相对较差,而同时强化文本特征与序列特征的分类效果与单独强化序列特征的效果相当(61.80%对61.46%和48.25%对48.47%).由于缺陷报告中存在大量的专业术语以及非正规语法,使得缺陷报告文本内容的序列特征较弱,使用注意力机制对其进行加强的效果并不明显.然而,使用注意力机制对文本特征进行学习并加强,能够进一步提高缺陷自动分派的预测准确率.
4.6.2 注意力机制的种类选择
可用于强化文本特征的注意力机制主要包括Self-Attention,Spatial-Attention以及CWA,不同的注意力机制可能对预测准确率产生不同的影响,在2个项目中Top-5上的效果分析结果如图3所示:
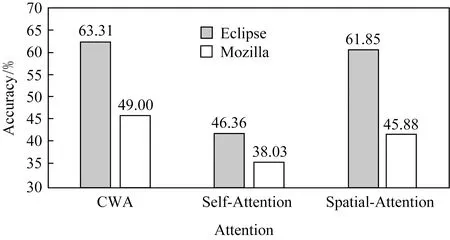
Fig.3 Effects of three attention mechanisms on the Top-5 prediction results图3 3种注意力机制对Top-5预测结果的影响
在2个项目中,Atten-CRNN模型在使用CWA时的准确率最高、在使用Self-Attention时的准确率最低,前者比后者在2个项目上分别提高了40.83%与28.85%,而在使用Spatial-Attention时的效果稍逊于使用CWA.通过对3种注意力机制进行分析可知,CWA用于对不同文本特征进行注意力权重的学习;Self-Attention侧重于学习文本特征之间的相关关系,而这种关系对于分类效果并无明显促进作用;Spatial-Attention主要是学习同一个文本特征内的位置关系.在序列特征对预测结果影响不大的情况下,文本特征内的位置关系对于模型的分类效果也有较大影响(接近使用CWA的效果),在后续的研究中应加以利用.
4.7 效度分析
本文结合CNN,RNN和注意力机制的优点,提出了一种基于混合神经网络模型与注意力机制的缺陷自动分类模型Atten-CRNN,并在Eclipse和Mozilla两个大型软件项目中验证了其有效性.但是,本文所提出的方法及相关结论仍旧存在一些潜在的威胁(threat).
对于内部效度(internal validity)的威胁主要包括模型的构建和注意力机制的使用.Atten-CRNN模型中的CNN层结构较为简单,仅使用了一层的卷积结构,而近年来深度CNN凭借其深层结构能够更好地捕获特征,在计算机视觉和NLP各个任务中均有着良好的表现.因此,Atten-CRNN模型的CNN层还有进一步的提升空间.对于强化文本特征的注意力机制,本文仅选取了3种流行的注意力模型进行实验验证,不能否认除了这3种模型外,可能存在其他效果更好的注意力模型.此外,实验中各类参数的设置也是一个不容忽视的内部效度威胁.在本文中,部分参数是参考以往文献的结果,部分参数是基于所使用软件工具的默认设置,还有部分参数是针对给定数据集进行了微调(fine-tuning).这些参数的改变可能会影响实验结果.
对于外部效度(external validity)的威胁主要包括所提方法的通用性.由于本文仅使用了Eclipse与Mozilla两个项目的数据进行实验,无法保证所提方法在解决其他项目的缺陷分派问题时同样也具有最好的效果,其通用性还有待进一步验证.此外,在缺陷修复过程中存在由多个开发者共同完成修复工作的情况,文献[20,23]采用了再分配图[28-29]的方式进行多个开发者的预测,且预测召回率(recall)明显高于纯文本分类方法.这类工作的主要思路是将缺陷分派看作是由多个开发者协作完成的一个过程,从而归结为多标签分类问题.考虑到相关的开发者在找到最终修复者的过程中都发挥了作用,因此通常一次性推荐一群可能的开发者(有可能是修复者,也有可能是负责再分配给修复者的开发者),而从确保获得较高的召回率.但是,这种做法不同于本文的研究思路,即直接推荐可能的修复者(单标签分类).这也是本文没有将文献[20]提出的方法作为基准方法的原因.但是,未来可将本文方法与再分配图进行结合,来进一步提高预测的准确率.
5 总 结
在群智化软件开发时代,提高缺陷修复效率与效果是确保软件质量的一种重要手段.其中,缺陷自动分派是一种典型的群体协作活动,其输出是修复者推荐服务,蕴含了专家智慧和机器智能.已有研究虽然尝试使用不同的深度学习模型来解决缺陷自动分派中的文本特征提取问题,但也存在各自的不足.因此,本文提出了一种基于混合神经网络与注意力机制的缺陷自动分派方法Atten-CRNN,充分利用CNN、RNN和注意力机制的优点,更全面、更合理地捕获缺陷报告中的文本特征,用于预测可能的开发者进行缺陷修复.在Eclipse和Mozilla两个大型的知名软件开源项目中进行了实证研究,实验结果表明,Atten-CRNN模型的预测准确率高于基于CNN架构和RNN架构的分类模型,从而验证了该模型在处理缺陷自动分派问题上的有效性.
未来的研究工作主要包括2个方面:1)在更多的生态化开源软件项目中验证本文所提方法的通用性和有效性.2)充分利用开发者之间的各种协作或社交关系,如再分配关系、邮件通信关系、GitHub上的关注(follow)关系等,构建基于文本分类和关系网络的混合模型,并综合考虑开发者的活跃程度、工作状态等特征,从而进一步提高缺陷分派的准确率.
致谢在此向对本文工作提出宝贵评审意见的审稿专家和编辑表示衷心地感谢,并向在本文实验过程中给予技术支持的宋化志同学、耿啸同学表示感谢!
