基于变量混合特征的分支启发式策略①
2020-03-18艾森阳宋振明
艾森阳,宋振明,沈 雪
(西南交通大学 数学学院,成都 611756)
(西南交通大学 系统可信性自动验证国家地方联合工程实验室,成都 611756)
可满足性问题(SATisfiability problem,SAT 问题)是判断一个以合取范式(Conjunctive Normal Form,CNF)形式给出的命题逻辑公式,在多项式时间内是否存在一组真值赋值,使得该公式为真.可满足SAT 问题,是世界上第一个被证明的NP-Complete 问题[1].同时SAT 问题被广泛地应用在人工智能、密码系统、计算机科学等实际领域,因此当前寻找求解SAT 问题的有效算法以提升SAT 求解技术的健壮性和综合性能极其重要.近年来很多学者对SAT 问题进行了广泛深入的研究,目前的SAT 算法大致可以分为两大类:完备性算法和不完备算法.完备性算法采取穷举和回溯思想,它的优点是能保证找到对应SAT 问题的解,在无解的情况下能给出完备证明,但不适用于求解大规模的SAT 问题.不完备算法基于局部搜索思想,在处理可满足的大规模随机类问题时,往往能比确定性算法更快得到一个解,但绝大多数随机搜索算法不能判断SAT 实例是不满足的.
本文主要介绍完备性算法,目前流行的完备性算法几乎都是基于DPLL[2]算法衍生而来,CDCL(Conflict-Driven Clause Learning,CDCL)[3]算法是在DPLL 算法的基础上添加了高效的启发式分支策略[4]、冲突分析与子句学习机制[5,6]以及周期性重启[7]等技术,使得完备算法处理可解决的SAT 问题越来越多.近年来发展出很多冲突驱动型的CDCL 求解器,如Chaff[8]、Zchaff[9]、Minisat[10]、Glucose[11]等,这些求解器已经在大规模实际领域的问题中得到广泛应用.
本文结构如下:第1 节介绍SAT 问题的相关知识;第2 节介绍了几种分支启发式策略;第3 节引出新的决策启发式及其具体算法;第4 节对比测试与实验分析;最后总结全文.
1 预备知识
1.1 相关定义
定义1[12].变量集合.用X表示命题变量的集合,用x1,x2,x3,···,xn代表任意的命题,称为命题变量,简称变量,则X=x1,x2,x3,···,xn用 |X|表 示集合X中含有命题变量的个数.
定义2[12].赋值.从变量集合X到真假值集合{0,1}的函数叫做真值赋值,简称赋值.即v(x):X→{0,1}.如果v(xi)=1,则称xi在赋值下取真值,否则为取假值.若只有部分变量具有真假值,称为部分赋值;若全部变量具有真假值,称为完全赋值.
定义3[12].文字.对任意的变量xi(i=1,2,···,n),xi和 ¬xi叫做变量的文字,其中叫做xi正 文字,¬xi叫做负文字.
定义4[12].子句.若干个文字的析取(或,∨)称之为子句,用字母C表示,即C=l1∨l2∨···∨ln,|C|表示子句C中文字的个数.在同一个子句中,文字是不同的.特别地,单个文字也是子句,称为单元子句,没有文字的子句称为空子句.
定义5[12].合取范式.一些子句的合取(与,∧)称之为合取范式,F(X)=C1∧C2∧···∧Cm,其通式表达为
1.2 相关过程
(1)布尔约束传播过程(Boolean Constraint Propagation,BCP)
BCP 过程也称为单元推导.BCP 过程即是反复利用单元子句规则对子句集里的合取范式不断地化简,直到子句集中不再存在单元子句或者出现冲突子句为止.随着搜索的不断进行,一个合取范式想要被满足,则要求其所组成的子句都是可满足的,所以通过单元规则会导致一些变量必须被赋值为真(子句中除了一个未赋值的变量外,其余变量都被赋值为0),通过单元规则导致的变量赋值被称之为蕴涵[12,13].因为子句集中变量的蕴涵关系,所以BCP 过程又可以通过蕴涵图直观地表示出来.
例1.若有子句集:
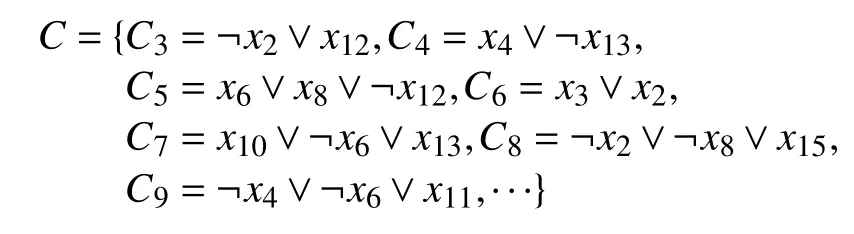
则可得到蕴含图,如图1 所示.
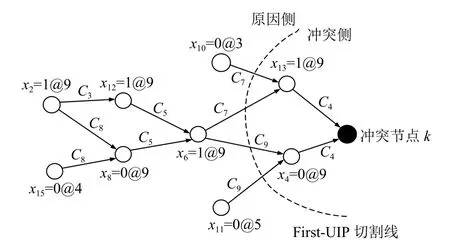
图1 蕴涵图
(2)学习子句形成过程
若布尔传播过程中产生冲突,则求解器进入冲突分析过程,冲突分析结束后将会产生一个学习子句.经证明认为,在冲突分析过程中根据第一唯一蕴含点(First Unit Implication Point,First-UIP)学习得到的子句是最有效的[14].根据First-UIP 切割方法,通常把蕴含图被分为两个部分:冲突侧和原因侧.如图1 所示,包含冲突节点的一侧为冲突侧,另一侧为原因侧.First-UIP 切割线周围包含了构成此次冲突的所有原因,学习子句是这些参与冲突分析的子句通过消解规则产生.图1 中参与冲突分析的子句集 φ={C4,C7,C9},生成的学习子句为 ¬x6∨x10∨x11.通过学习子句知在任何时候x10和x11被 赋值为0,文字x6必须赋值为0,即求解器不会进入x6=1的搜索空间,避免了进入相同的冲突.
2 现有分支启发策略
Chaff 算法表明整个搜索过程中布尔约束传播占用大部分时间,一个好的分支策略可以快速找到决策变量,减少冲突次数,加速BCP 过程,因此好的分支决策对提高整个SAT 求解器的运行效率意义重大.
2.1 VSIDS 策略
VSIDS(Variable State Independent Decaying Sum)分支变量启发式策略,该策略由Moskewic 等于2001 年提出[8].相比早期的分支启发式,VSIDS 分支变量启发式策略很好地结合了冲突分析过程.
(1)每一个变量的正、负文字都分配一个计数器s,并且初始值设置为0;
(2)当学习子句加入到子句集时,该子句中所有的文字活性;
(3)每次分支决策时选择计数器分值最高未赋值的文字进行赋值,在有多个相等计数器的情况下,随机选择一个文字进行赋值;
(4)所有文字的得分周期性地除以一个常数.
2.2 VSIDS 策略的有效变体
近年来,随着SAT 问题研究的深入,VSIDS 算法得到了不断的改进.NVSIDS(Normalized VSIDS)策略是由Armin 等于2008 年提出[15].该策略为每个变量设置一个计数器,其中涉及冲突的变量以s′=f·s+(1-f)更新得分,f为衰减因子;未涉及冲突的变量其活性仍被“重新计分”s′=f·s.即在每次冲突中NVSIDS 策略需要更新所有变量的得分.EVSIDS(Exponential VSIDS)策略则是其更有效的实现,最初由MiniSAT 的作者提出[10],EVSID 策略仅对涉及冲突的变量通过添加指数增量的方式来更新变量的得分s′=s+(1/f)i,其中f为衰减因子,i表示冲突次数,未涉及冲突的变量得分不变,由证明得EVSIDS 策略与NVSIDS 策略得分线性相关.
ACIDS(Average Conflict-Index Decision Score)[16],ACIDS 策略与EVSIDS 一样,对每个变元不区分正负方向,只保留一个计数器.变元活跃度累加方式为s′=(s+i)/2 ,式中i为冲突次数.ACIDS 策略不仅给后来的涉及冲突的变量赋予更大的权重,而且随着冲突次数的增加较早发生的冲突对搜索的影响呈指数下降.同时ACIDS 中变量的得分仅受冲突次数i的限制,因此,ACIDS 策略比EVSIDS 策略更加平滑.
除了上述两种分支策略,目前还发展出一些其他高效的VSIDS 的变体策略,2016 年Liang JH 等提出的了CHB(Conflict History Based Branching Heuristic)策略[17]及同年提出的LRB(Learning Rate Branching)策略[18]等.这些启发式分支策略都是尽可能优先满足学习子句来加速搜索过程,在很大程度提高了求解速度.
3 基于变量混合特征分支策略
上述启发式策略有两方面的优势:(1)仅对参与冲突分析的子句所包含的变量,即参与冲突分析的变量进行活性更新.如图1 的实例,变量x4,x6,x10,x11,x13的活性值会被更新,即变量参与冲突越多,活跃度越大,相应地活性值也就越高;(2)满足学习子句优先原则,变量活跃度的增加方式与冲突次数i有关,随着冲突的发生,越往后发生的冲突,活跃度增加的越大.
我们发现基于冲突分析的活性增长方式并不是完善的,因为对每个参与冲突分析的变量,其活跃度的增量是一致的,没有根据变量的所携带的一些特性来区分变量的重要性,而在实际求解阶段变量所携带的信息是多方面的,如:(1)变量的决策层,在非时序性回溯阶段,我们认为当回溯到较低的决策层时,搜素过程对二叉树的剪枝能力越强;(2)变量最近一次参与冲突分析时的总冲突次数,变量参与冲突分析的冲突差(当前冲突次数-变量最近一次参与冲突分析时的总冲突次数)越小,我们认为该变量最近越活跃,可以适当给予更高的活性.
针对此问题,本文提出了一种基于变量特性的有效混合策略称为混合特征分支策略(Mixed Feature Branching Strategy,MFBS),此策略不仅加入了变量最近一次参与冲突分析的总冲突次数,还考虑了参与冲突分析变量所在的原因子句的文字块距离(Literal Block Distance,LBD).LBD 值指子句中变量所在的不同决策层数目,Audemard 等证明具有较小LBD 值的子句比具有较高LBD 值的子句更有用[17].实际上LBD 较小,则表明子句需要单位传播中的决策数量更少,子句中的变量分布相对更集中,更有利于布尔传播过程.综上,我们分析了影响变量决策的两个因素,为了平衡冲突次数与LBD 对分支决策影响程度的大小,我们设置调节因子来适当地平衡分析.本文的策略具体表述如下:
(1)为每个变量设置一个计数器,初始为0;
(2)对于参与冲突分析的变量,活跃度增长方式为s′=s+Hyb(v)·Inc;
(3)每次分之决策时,挑选计数器分值最大的为赋值的变量,作为下一个决策变量.若多变量值相同,则随机挑选一个文字赋值.
在步骤(2)的等式中:

其中,α为调节因子,lastcon flict为变量最近一次参与冲突分析的总冲突次数,nconflicts为当前冲突次数.Inc为活性增长因子,初始值取1,每次冲突更新Inc/Decay,Decay是一个(0,1)区间的实数,在Minisat中,Decay=0.95 .由Hyb(v)的定义值,频繁参与冲突分析的变量其活性增长速度比长时间未参与冲突分析的变量快,且具有较小的子句LBD 的变量更有优势.基于此我们可以生成MFBS 的伪代码,在算法1 中第7 行,本文用MFBS 策略代替了原版分支策略,即当变量出现在冲突分析中,变量的活性以新的策略更新.每次进行分支时,总是选择活性值最大的变量作为下一个分支变量,如算法1 所示.

?
4 实验分析
Glucose 作为国际先进的求解器,近些年部分优秀的求解器都是在此基础上的改进,2009 年Glucose 3.0 获得SAT Main Track 组竞赛冠军,2017 年其并行版本求解器Syrup 获得冠军等,本文则选取最新的Glucose4.1 求解器为基础,把MFBS 分支策略嵌入Glucose4.1 生成Glucose4.1+MFBS 版本,下一步将两版本进行实验对比分析.
4.1 实验环境
本文选取的实验机器配置为Windows 64 位操作系统,Intel(R)Core(TM)i3-3240 CPU 3.40 GHz 8 GB内存.
4.2 实验方法
两个版本的求解器都在4.1 的实验配置下,分别对2017 年SAT 竞赛Main Track 组实进行测试.2017年实例总体可分为两大类:g2 和mp1,本文首先在每类中随机选取一个小类别共(108 个),其中包括:g2-T(40)、g2-test(2)、g2-UGG(3)、g2-UR(2)、g2-UTI(2)和mp1 构成第1 步的测试例.实验第2 步选取第1 步表现较好的求解器,对2017 年SAT 竞赛的350 个实例,进行综合测试.两个过程中每个实例均限时3600 s,若超时未解决自动终止.
4.3 实验结果分析
本文首先在理论上提出的两个特征因素,但对于每个特征因素的对分支决策的影响还需要进一步通过实验说明.因此为了综合评估MFBS 算法的求解性能,充分探究各个特征因素对分支的影响,本次实验首先对调节因子 α设置了3 个参数,实验中α 取值分别为α={0.4,0.5,0.6,0.7}.表1 则为Glucose4.1+MFBS 的4 个版本与Glucose4.1 原版的对比,在不可满足问题上Glucose4.1+MFBS 4 个版本与原版求解器实力相当,在可满足性问题上Glucose4.1+MFBS 4 个版本中有2 个版本较优于原版求解器,0.5 版本求解效果最好,相对于Glucose4.1 求解实例增加了9.4%.
图2 表示不同版本的4 个求解器与原策略对108 个实例求解时间对比.黑色实心三角代表原版求解器,图中曲线上每个点代表一个实例,曲线越靠近x 轴,则表明曲线所代表的求解器求解时间越少,求解个数越多.从图中可以看出是4 个版本中有3 个版本的求解时间均优于原版求解器,其中α =0.5和 α =0.6最有求解优势,求解时间明显小于原版.
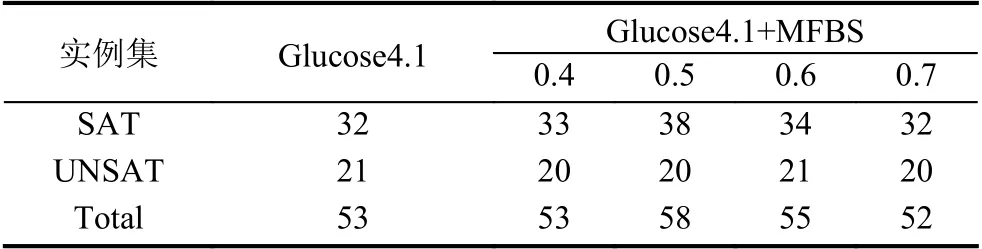
表1 Glucose 与Glucose4.1+MFBS 求解个数对比(108 个)

图2 Glucose 与Glucose_4.1+MFBS 的求解性能对比
为了更深一步探究求解器的性能,以下的实验,将针对本文第一步测试的较优的两个求解器:α =0.5和α=0.6进行更深入的测试.实验选取2017 年剩余的实例242 个(共350 个)进行测试,实验结果如表2 所示,可以看出,α =0.5的版本在求解不可满足性问题的能力要弱于可满足性问题,α =0.6版本表现相对比较稳定,对于不可满足实例和原版求解器求解能力相当.但两个改进版本求解实例总个数均多于原版,说明MFBS策略对于求解可满足性问题具有一定的优势,整体在求解能力上有所提高,同时也进一步说明本文所提出的两个影响因子对分支决策,有一定的促进作用,且LBD 值相比冲突次数对分支决策影响更大.

表2 Glucose 与Glucose4.1+MFBS 求解个数对比(350 个)
图3 列出了两个版本的求解器与原版求解器的求解个数与求解时间的关系,实心三角代表原版,空心图形代表MFBS 版本.因MFBS 策略倾向于求解可满足性问题,所以针对2017 年350 个实例的总体求解时间表现有所减弱.可以看出前一段实例3 个求解器求解时间高度重合,在中间部分原版求解器的求解性能要高于本文提出的两个版本,但在求解较难问题时,本文的两个版本又表现出优于原版的性能,尤其对于多求解出来的实例,每个实例用时接近于3600,因此也会增加总体的平均求解时间.
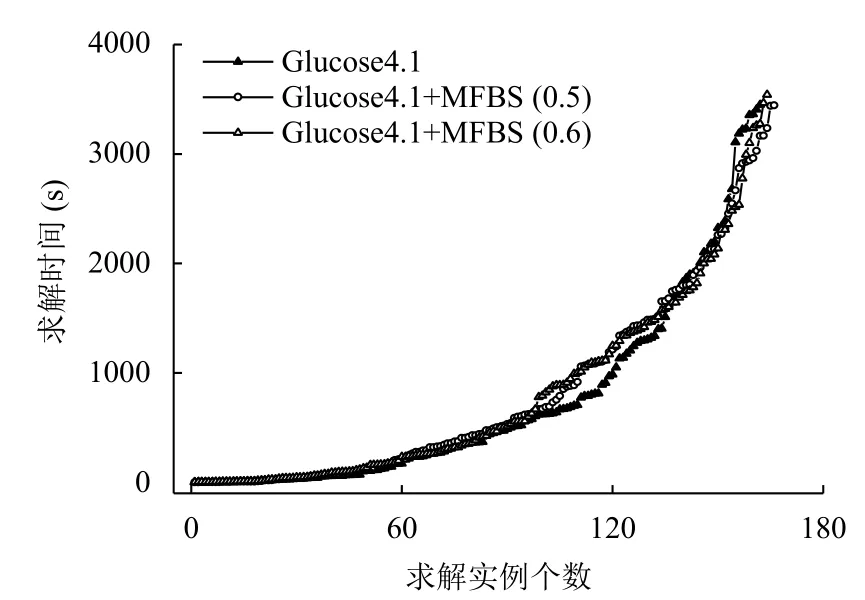
图3 Glucose4.1 与Glucose4.1+MFBS(α )求解性能对比
5 结论与展望
因求解实际的SAT 问题的多样性和复杂性,使SAT 问题求解难度提高.本文所提出的混合启发式策略,不仅考虑了变量在参与冲突分析的次数,还加入了变量所在冲突子句的LBD 值,相比传统单一的启发式策略,具有一定的优势,测试结果表明混合策略在一定程度上要优于原始策略.
后续将对混合启发式策略进一步测试,从中探究不同实验参数对整体求解性能的影响,发现不同因素之间的联系,进而更好地提高求解器的求解性能.
