基于遗传算法优化的BP神经网络进行水稻氮素营养诊断
2020-03-15罗建军杨红云路艳易文龙孙爱珍
罗建军, 杨红云, 路艳, 易文龙, 孙爱珍
(1.江西农业大学计算机与信息工程学院, 南昌 330045;2.江西农业大学软件学院, 江西省高等学校农业信息技术重点实验室, 南昌 330045)
氮素是植物生长所需的必要元素之一,缺氮会造成植株叶片面积减小,降低光合作用、叶绿素浓度和生物产量[1]。施氮过量则会在土壤中残留大量的氮元素,不仅造成氮肥的浪费,而且对环境造成一定的污染[2]。近年来,由于高产品种的推广及肥料的大量使用,稻谷产量大幅提升,稻米品质却未显著改善,肥料利用率也呈下降趋势[3]。为此,对于施氮量的管理极为重要,对氮素营养快速准确诊断能够有效指导合理施氮。利用图像处理技术进行水稻氮素营养诊断,高效、便捷且无损。对此,多数研究者采用图像处理技术对水稻进行氮素营养诊断,研究结果表明,水稻冠层图像特征能够很好地表征其氮素营养状况。例如,王远等[4]研究表明,水稻冠层中的红光标准化值能够良好地进行叶片SPAD值及全氮含量的测定;李岚涛等[5]通过对水稻多个颜色特征的研究对比发现,冠层中的红光标准化值与水稻常规氮素营养指标和产量之间都体现出较好的相关性;Lee等[6]将相机中所提取的冠层绿色深度绝对值与地上部生物量、氮素累积量和叶面积指数进行分析研究发现,均可采用指数方程进行拟合,其均方误差R2分别达到0. 83、0. 83和0. 86;YAO等[7]采用活动作物冠层传感器估算水稻氮素状况,植被指数和比值植被指数2个指标能够解释水稻地上生物量和植物氮吸收量,且相对误差是可接受的(<26%)。Yuan等[8]利用图像处理技术提取出水稻生长期的红光标准化值、色调、绿色深度值等颜色特征,发现各颜色特征与SPAD值具有良好的线性相关性。在水稻氮素营养诊断的敏感叶位研究中,祝锦霞等[9]研究发现,水稻顶部第三完全展开叶叶片对颜色特征参数较为敏感,并以顶部第三完全展开叶颜色特征数据建立水稻氮素水平诊断识别模型。刘江桓[10]应用水稻叶片颜色特征参数进行拟合分析,发现不同生育期水稻顶部第三完全展开叶可体现稻株的氮素含量。孙棋[11]研究发现,水稻叶片中的顶部第三完全展开叶最能体现其氮素状况,并应用颜色参数建立回归分析模型进行氮素诊断。以上研究均可表明,水稻顶部第三完全展开叶叶片较其他叶位叶片进行水稻氮素营养诊断更为敏感。潘圣刚等[12]研究表明,水稻进行氮素高效吸收及快速累积的主要时期是在幼穗分化期、齐穗期及成熟期。与此同时,周琼等[13]研究表明,幼穗分化期水稻顶部第三完全展开叶叶片特征较齐穗期更具区分度,易于进行氮素营养诊断识别。BP神经网络是一种误差反向传播算法的学习过程,对解决非线性分类问题具有较大的优势[14],并广泛应用于计算机视觉技术中[15]。李锦卫[16]采用BP神经网络进行水稻氮素营养识别,整体识别准确率为75.7%,其高氮水平类别识别效果较差,仅为56.3%;周琼等[13]通过采用图像处理技术和BP神经网络进行水稻氮素营养识别整体识别准确率达90%,其第二类施氮水平识别准确率仅为76%。前人研究的BP神经网络模型训练均陷入了局部最小。
本研究采用图像处理技术和BP神经网络,研究水稻叶片和叶鞘颜色、几何形态等外观特征参数与水稻施氮水平之间的关系,但考虑到BP神经网络在进行非线性分类建模时容易陷入局部最小,因此引入遗传算法对BP神经网络模型进行参数优化。同时,在特征数据预处理阶段引入离散小波变换和主成分分析,以提高水稻氮素营养诊断识别模型的模型整体性能,建立更为准确的水稻氮素营养诊断识别模型,为水稻氮素营养诊断识别研究提供一种新的思路与方法,为利用计算机视觉技术进行氮素营养诊断识别奠定理论基础。
1 材料与方法
1.1 试验区概况及试验设计
2017年在江西省南昌市成新农场(116°15′E,28°92′N)进行水稻试验。稻田土壤pH 5.30、含有机质24.40 g·kg-1、全氮1.40 g·kg-1、有效磷12.70 mg·kg-1、速效钾(P2O5) 123.0 mg·kg-1[17]。
以超级杂交稻‘两优培九’(Liangyoupei 9,LYP9)作为供试品种,其最佳施氮量为纯氮210~300 kg·hm-2[17],以其高施氮量 (270 kg·hm-2以上) 为基础,设置4个梯度,氮肥(纯氮)施用量分别为N0(0 kg·hm-2)、N1(210 kg·hm-2)、N2(300 kg·hm-2)和N3(390 kg·hm-2),3次重复试验。随机区组排列,小区面积30 m2,各小区间均作埂并用塑料薄膜包裹在上面,以防小区间互相影响。氮肥使用尿素(含N 46%),按基肥:分蘖肥:穗肥4∶2∶4施用;钾肥使用钙镁磷肥(含P2O512%),按分蘖肥:穗肥7∶3施用;磷肥使用氯化钾(含K2O 60%),做基肥一次施用。各区间磷、钾肥施用等量,分别为P2O5225 kg·hm-2、K2O 300 kg·hm-2。人工移栽前1 d施用基肥,人工移栽后7 d施用分蘖肥,在叶龄余数1.5左右时施用穗肥[18]。5月25日播种,6月14日人工移栽。栽插密度为13.3 cm×26.6 cm,其他管理按照一般的高产栽培处理。
1.2 水稻数字图像的获取
在水稻幼穗分化期(2017年7月24日)进行叶片及对应叶鞘的采集,并选用顶部第三完全展开叶作为试验样本。水稻数字图像获取的设备选用MICROTEK平板扫描仪(MRS9600TFU2L,上海中晶科技有限公司生产),图像传感器为CCD,分辨率为600 ppi。采样后立即扫描,以防止叶片变形、变色,影响试验效果[19]。由于叶片过长,将每片叶片分为叶中和叶尖2部分,平铺在同一大小的白色纸张上,同时放置对应叶片的叶鞘和一个已知大小的参照物,以便后续试验处理。参照物中每个黑色方格实际边长为2.5 cm,共计8个。各施氮水平分别获取200组水稻图像(共800片,水稻图像中包含叶片以及对应叶鞘图像)作为试验样本,每一张水稻图像视为一组水稻数据。
1.3 水稻数据获取
1.3.1特征选择 在扫描图像中提取了12项颜色特征和7项几何形态特征。颜色特征包括叶片和叶鞘各6种彩色空间分量(R、G、B、H、S、I),几何形态特征包括叶片的长度、宽度、面积、周长、长宽比、面积长度比以及面积周长比。
1.3.2水稻图像颜色特征提取 水稻图像以白色纸张作为背景,水稻叶片呈绿色或深绿色,目标物体与背景颜色区分较为明显,省去图像分割步骤。本研究采用Matlab工具将RGB图像转换成HSI图像,获取R、G、B、H、S、I 6种分量的图像,如图1所示。通过对6种分量的对比发现,H分量下的水稻叶片和叶鞘与背景有较大差异,而G分量下的参照物与背景有较大差异,因此,对H分量图像和G分量图像进行二值化,分别提取出水稻叶片、叶鞘与参照物,再采用cat函数去除图像中的小面积干扰区域,如图2所示。将去除杂质后的图像与原图进行点乘操作,获取黑色背景的水稻图像。同时使用regionprops函数对水稻叶片与叶鞘定位,分割出水稻叶片和水稻叶鞘,黑色背景下的水稻图像如图3所示。对黑色背景下水稻图像进行叶片及叶鞘的R、G、B、H、S、I均值计算。

图1 6种分量分离的对比图像Fig.1 Comparison image of six components separation

图2 水稻图像二值化及去除杂质前后对比图像Fig.2 Binary image of rice image and comparison image before and after impurity removal

图3 黑色背景下水稻叶片和叶鞘图像Fig.3 Rice leaf and sheath images under black background
1.3.3水稻叶片几何形态特征提取 采用regionprops函数将叶片二值图中的叶中和叶尖分别定位出来,并通过minboundrect函数获取水稻叶中和叶尖的最小外接矩形。通过统计出的最小外接矩形长宽方向像素点个数[20],以获取叶片的实际长宽,水稻叶中和叶尖最小外接矩阵图像,如图4所示。同时,采用bwboundaries函数对叶片二值图和参照物二值图进行轮廓提取,轮廓图像包括叶中、叶尖及参照物轮廓,以获取叶片实际周长,叶中和叶尖及参照物的轮廓图像,如图5所示。

图4 水稻图像最小外接矩阵图像Fig.4 Minimum external matrix image of rice image
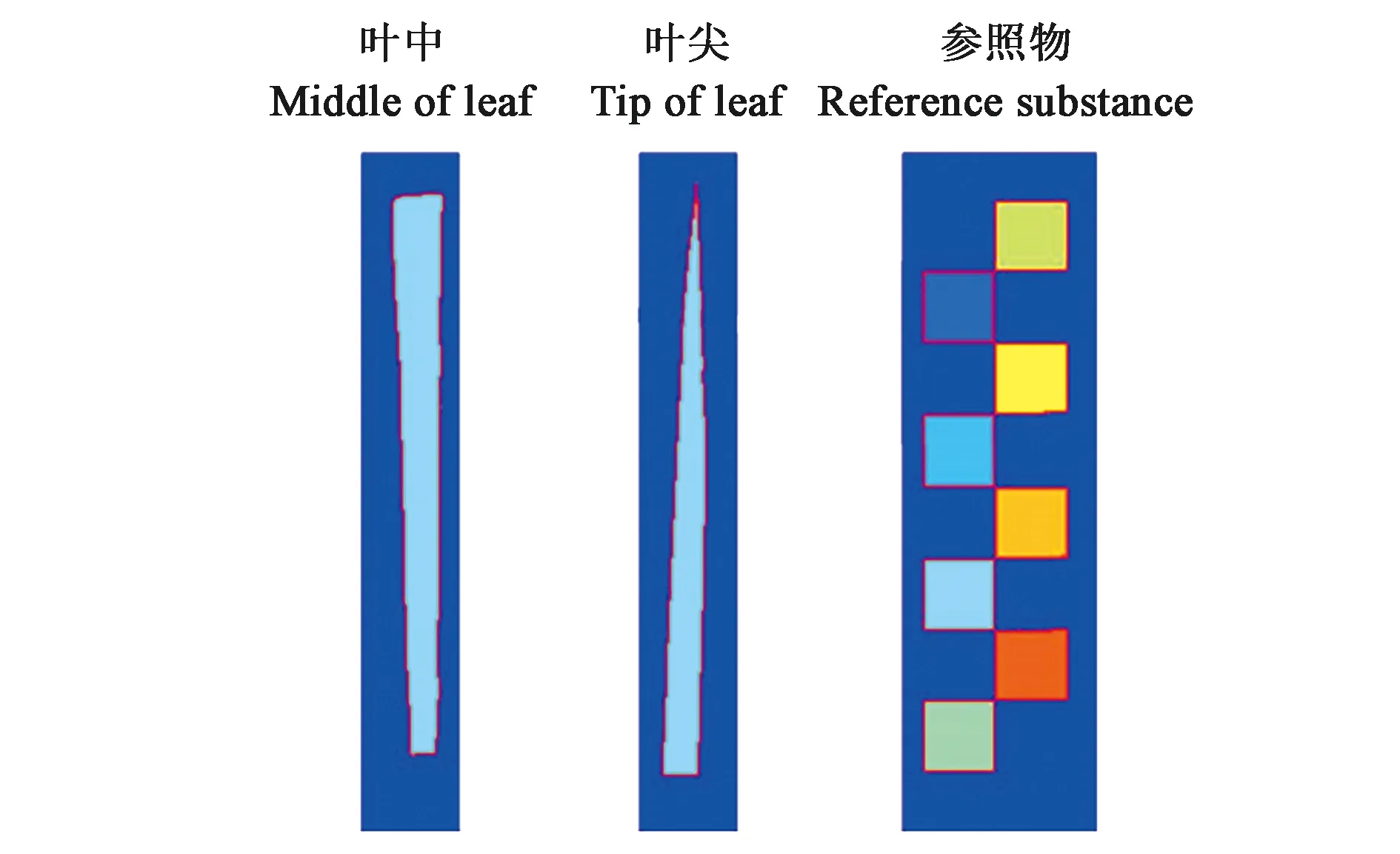
图5 水稻叶片及参照物轮廓图像Fig.5 Contour image of rice leaf and reference substance

(1)
L=k×(MLpixel+TLpixel)
(2)
W=k×max(MWpixel,TWpixel)
(3)
C=k×(MCpixel+TCpixel-MWpixel-TWpixel)
(4)
S=k×(MSpixel+TSpixel)
(5)
式中,k为比例系数;CRreal为8个参照物的实际周长;CRpixel为8个参照物轮廓总像素数;L为叶片实际长度;MLpixel为叶中最小外接矩形长度总像素数;TLpixel为叶尖最小外接矩形长度总像素数;W为叶片实际长度;MWpixel为叶中最小外接矩形宽度总像素数;TWpixel为叶尖最小外接矩形宽度总像素数;C为叶片实际周长;MCpixel为叶中轮廓总像素数;TCpixel为叶尖轮廓总像素数;MWpixel为叶中最小外接矩形宽度总像素数;TWpixel为叶尖最小外接矩形宽度总像素数;S为叶片实际面积;MSpixel为叶中轮廓内总像素数;TSpixel为叶尖轮廓内总像素数。
在采用图像处理方式的同时,随机选取20片叶片,进行人工测量叶片的长宽,并与图像处理提取的叶片长宽进行对比分析。
1.4 水稻叶片全氮含量的测定
水稻叶片扫描后,各施氮水平的200片叶片中分别随机选取100片(共400片),将叶片样品放于烘箱中,105 ℃杀青1 h,在80 ℃下进行48 h烘干至恒重。烘干后密封于干燥处保存,所有样本处理完后,将干样品粉碎、过筛、混匀,采用H2SO4-H2O2进行消煮,凯氏定氮法测定叶片全氮含量[23]。
1.5 水稻图像数据预处理
1.5.1特征数据归一化处理 由于水稻每种特征量纲有所不同,为能够提高模型运行速率和模型准确率[24],试验采用mapminmax函数对所有特征数据进行归一化处理,归一化公式如下。
(6)
式中,xmax为原始特征数据中的最大值;xmin为原始特征数据中的最小值;ymax为归一化处理后的最大值,取1;ymin为归一化处理后的最小值,取0。
1.5.2基于离散小波变换的特征数据处理 离散小波变换是一种数学分析方法,在时序信号处理中应用十分广泛[25],但在非时序且非平稳的水稻特征数据中却并未应用。因此,本研究引入离散小波变换,分别对19项特征数据的突变数据进行平滑化,消除数据间的波动性,保留数据的主要特征,将数据的特征性更为凸显,以建立理想的水稻氮素营养识别模型。试验采用Matlab小波工具箱的专用函数进行水稻特征数据处理。离散小波变换基本步骤如下:①应用wavedec函数将数据信号分解为7层,小波基采用coif5;②利用appcoef函数和detcoef函数分别获取到分离后的低频数据信号和高频数据信号,将低频数据信号进行保留,并将高频数据信号前3层置零、后4层进行软阈值处理,阈值设为0.14;③最后采用waverec函数进行数据信号重构。
1.5.3基于主成分分析的特征数据降维处理
主成分分析是采用降维思想,将多个具有相关性的原始特征转化为少数几个不相关的综合性特征[26]。本研究共提取19个特征数据,为能提高算法的运行效率,能达到理想试验效果,对19维数据进行主成分分析。
1.6 遗传算法优化BP神经网络模型建立
BP神经网络是一种按误差反向传播的多层前馈神经网络,在模式识别中应用十分广泛[27]。本研究采用BP神经网络建模,其隐含层传递函数、输出层传递函数以及训练函数分别设置为tansig、purelin和trainlm,学习速率、精度、动量因子分别设置为0.05、0.1和0.9,最大迭代次数为1 000次,并选择Levenberg-Marquardt优化算法作为模型训练函数[14]。BP神经网络的非线性映射能力虽然很强,但容易陷入局部最小。为避免训练陷入局部最小,本研究引入遗传算法,优化BP神经网络的权值与阈值。遗传算法包含5个基本要素:问题编码、初始化群体、适应度函数设计、遗传操作设计和控制参数设定(主要是指群体大小及使用遗传操作的概率等),是遗传算法的核心内容[26]。基于遗传算法优化BP神经网络基本流程如图6所示。设定种群规模为50,遗传算法最大迭代次数设为50。个体采用二进制编码,交叉概率为0.7,变异概率为0.01,代沟为0.95。
1.7 模型构成
4种施氮水平样本数据随机选取80%作为训练数据集,20%作为测试数据集(训练数据集640组,各施氮水平160组;测试数据集160组,各施氮水平40组)。采用单一BP神经网络(模型1)、遗传算法优化的BP神经网络(模型2)和应用小波分析和主成分分析的遗传算法优化BP神经网络(模型3)进行试验。模型1和模型2都以归一化特征数据作为模型输入数据,模型3选用主成分分析降维后的数据作为模型输入数据。3种模型的隐含层节点数由经验公式(7)[28]确定。由于本研究所识别氮素营养状况种类为4种,因此输出节点个数为4,采用二进制编码,模型的输出向量分为4种,分别以[0,0,0,1]、[0,0,1,0]、[0,1,0,0]、[1,0,0,0] 4种输出向量代表4种施氮水平N0、N1、N2、N3 。
n2=2n1+n3
(7)
式中,n1为输入节点数;n2为隐含层节点数;n3为输出节点数。
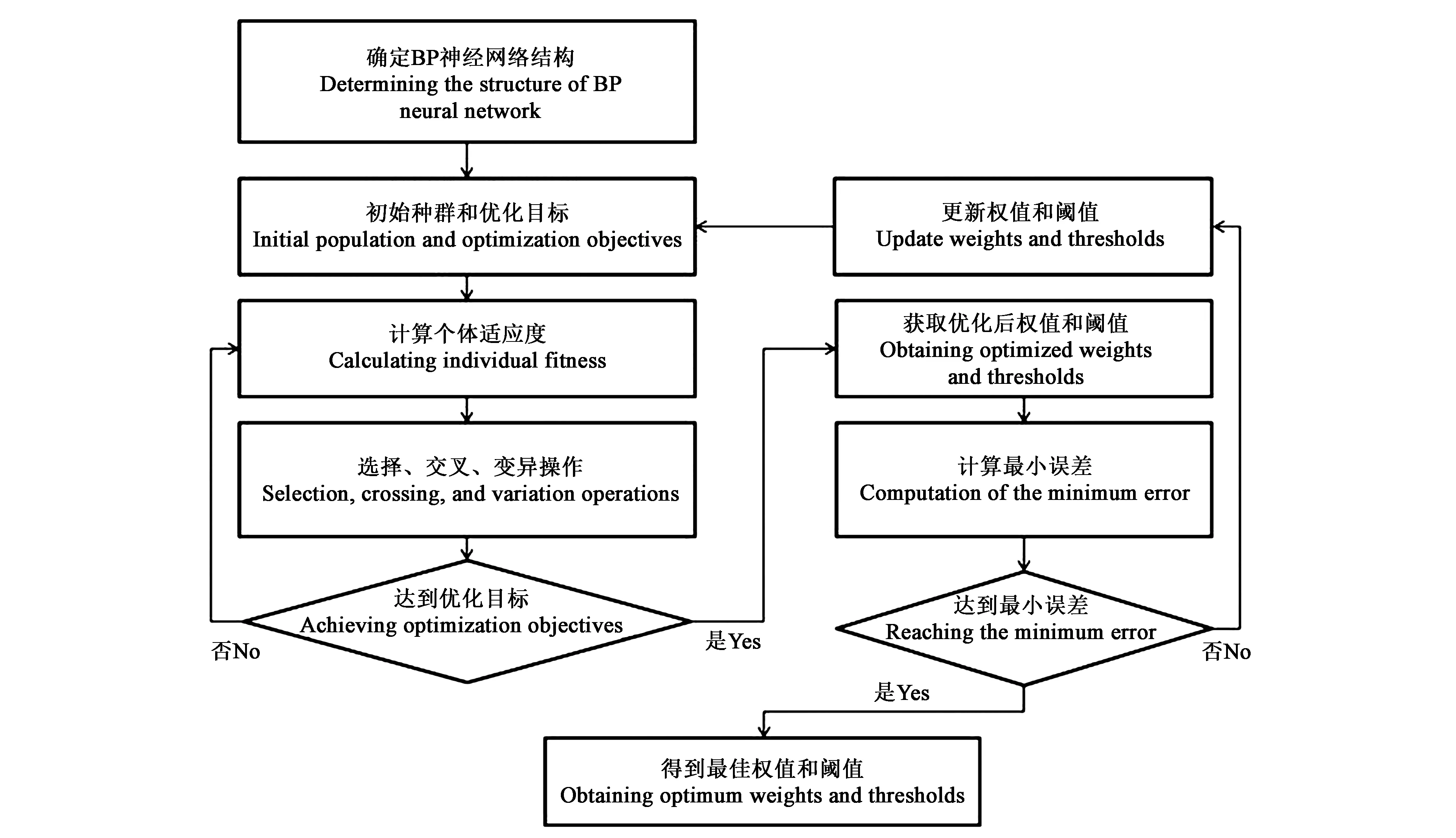
图6 遗传算法优化BP神经网络流程Fig.6 Optimizing BP neural network flow by genetic algorithms
2 结果与分析
2.1 不同施氮水平对水稻叶片全氮含量的影响
各施氮水平叶片的叶片全氮含量平均值如表1所示。在前3种施氮水平下,随施氮水平的提高,叶片全氮含量呈明显的增加趋势,但N3施氮水平下却有所下降。说明在未过量施氮的情况下,提高水稻的施氮量对叶片全氮含量的吸收具有促进作用,但过量的施氮则会使得全氮含量呈下降趋势。因此,过多的施氮不仅会降低氮肥利用效率,而且在环境上也会产生负面影响[29]。
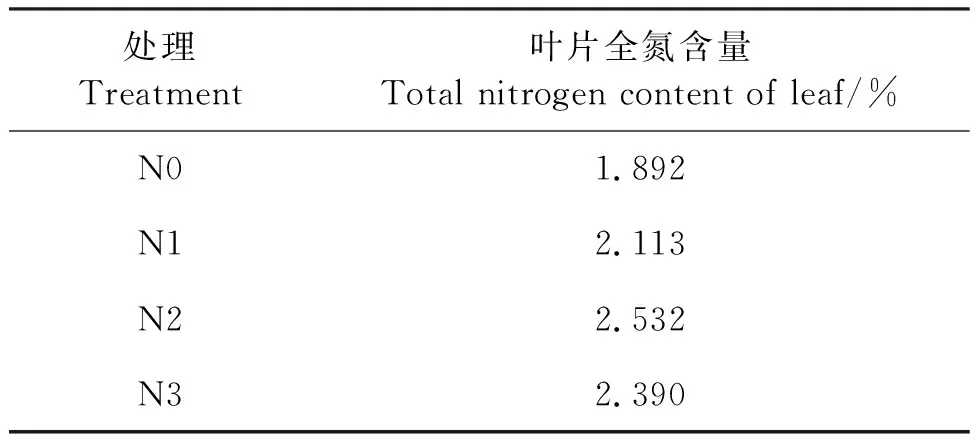
表1 不同施氮水平对水稻叶片全氮含量的影响Table 1 Effects of different nitrogen application levels on total nitrogen content in rice leaf
2.2 数字图像提取叶片几何形态特征的可行性分析
表2显示,其中图像处理提取的叶长误差在0~0.3 cm之间,最大相对误差为0.65%,平均相对误差为0.328%;叶宽误差在0~0.1 cm之间,最大相对误差为5.850%,平均相对误差为3.404%。结果表明,通过图像处理进行水稻几何形状特征的提取是能够满足本试验需求。
2.3 水稻图像数据预处理分析结果
2.3.1基于离散小波变换的特征数据处理分析结果 叶片B特征的归一化数据经离散小波变换处理前后的对比见图7。原始特征与处理后特征具有相似的变化趋势,且处理后的特征比原始特征更加光滑,最大限度地反映了原始数据本身的特性,特征向量中的“毛刺”现象基本消失。
2.3.2基于主成分分析的数据降维处理分析结果 统计学认为,一般方差累计贡献度应在80%以上[9]。因此,方差累计贡献度越高,越能反映原始数据的特征性。如图8所示,前11个主成分累计贡献度达到99.999 84%,能够很好地反映原始数据的特征性。本研究选用前11个主成分作为基于遗传算法优化参数的BP神经网络的输入向量。

表2 水稻叶长叶宽的误差分析Table 2 Error analysis of rice leaf length and width
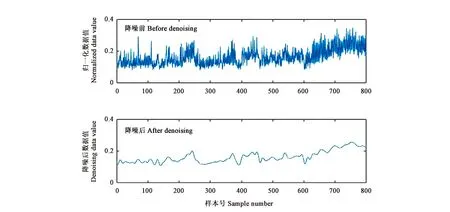
图7 颜色特征B的小波降噪对比Fig.7 Wavelet denoising contrast of color feature B

图8 主成分方差贡献率Fig.8 Variance contribution rate of principal component
2.4 模型实验结果对比
模型1和模型2都以19维归一化特征数据作为模型输入数据,模型3选用主成分分析降维后的11维数据作为模型输入数据。3种模型的隐含层节点数可通过经验公式(7)确定,分别为48、48、26。应用3种模型进行水稻氮素营养识别建模,测试集识别效果见表3。其中,模型1的平均识别率最低,为82.500%,且模型1的N1识别率较其他施氮水平明显要低,仅为55.000%,该模型在N1识别率上陷入了局部最小。模型2中引入遗传算法后,对N1识别率明显提高,达到了80.000%,平均识别率为88.125%。本研究模型(模型3)相对于前2种模型各类的识别率都有所提高,其平均识别率比模型1和模型2分别提高了15.625%、10.000%。模型3中N0和N3的识别率都达到了100.000%;N1识别率明显提高,达95.000%。模型3的诊断结果分布见图9,由图9可知,仅有第41和42组样本被误判为了N3水平;第107号样本被误判为N1水平。由此说明,本研究模型(模型3)较前2种模型对水稻氮素营养诊断识别效果较为良好。
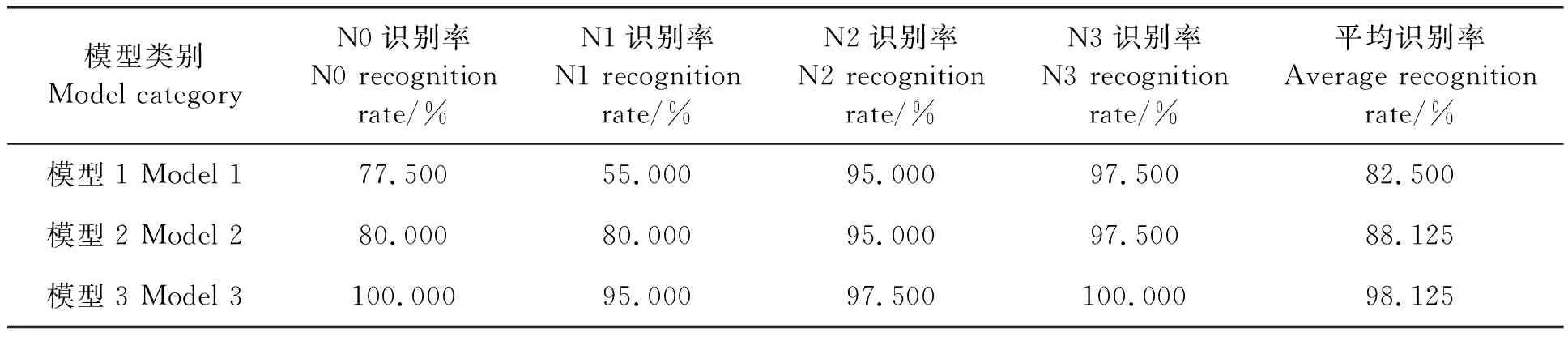
表3 3种模型的测试集识别效果Table 3 Test set recognition effect of three models

图9 模型3的氮素营养诊断识别分布Fig.9 Distribution of nitrogen nutrition diagnosis and recognition in Model 3
3 讨论
本研究对各施氮水平的水稻叶片全氮含量进行分析,应证了程慧煌等[17]中的结论(‘两优培九’最佳施氮量为纯N 210~300 kg·hm-2),N0施氮处理(施氮量低于210 kg·hm-2)为缺氮,N3施氮处理(施氮量超过300 kg·hm-2)为过氮。应用本研究试验模型进行水稻氮素营养诊断识别,虽能良好地判定其氮素含量的缺失,但水稻试验最佳施氮量仅为一个范围。因此,在后续研究中,将在最佳施氮范围内增设多个施氮水平进行诊断研究。本研究将图像处理所提取的叶长叶宽与人工测量进行对比分析,其叶片长宽平均相对误差分别为0.328%、3.404%,能够满足本试验的需求。这与杨红云等[20]的研究误差稍大一些,可能是由于水稻叶片被分为叶尖和叶中所造成的,也有可能是由于图像处理过程中没有消噪处理所造成的。且研究中所选用的水稻图特征大多为常用颜色和几何形态特征。在后续试验中,将选用完整叶片、更为良好的图像处理方式进行特征提取,以降低特征提取的误差及操作的复杂性,并引入水稻植株的其他特征,如叶茎夹角、纹理特征等与水稻氮素营养之间做相关性研究。本研究的水稻氮素营养诊断识别模型平均识别准确率高达98.125%,仅有N1的2个样本和N2的1个样本诊断识别错误。说明该研究模型能够解决BP神经网络建模容易陷入局部最小的问题,而且能够良好地进行水稻氮素营养诊断识别。大田实验中,水稻生长状况与其生长位置有关,个别样本无法正确识别主要是采集的水稻样本生长状况有所偏差而导致的。
本研究通过获取水稻扫描图像提取叶片颜色、几何形态和叶鞘颜色特征进行水稻氮素营养诊断识别,属于水稻氮素营养诊断的初步研究,改进之处尚多。研究中仅以2017年的‘两优培九’作为供试样本,所建立的水稻氮素营养识别模型在其他年限和水稻品种中的应用性还需要进一步研究。研究中仅获取水稻幼穗分化期顶部第三完全展开叶叶片及对应叶鞘,且样本数目相对较少,仅有800组。为能够使得水稻氮素营养诊断识别模型更具有通用性与实用性以及提高样本的容错率,在未来的研究中,将获取更多年份、水稻品种、水稻生长时期及叶位等的水稻图像特征进行研究,并提高模型建立的样本总量。同时,本研究选用的数据是从水稻扫描图像中所获取的,虽然基本排除了环境干扰等的影响,但扫描装置较为昂贵,操作较为复杂。若在多样性的大田环境下,环境干扰等因素是无法避免的。因此,在后续研究中探寻低成本、高便捷的方式获取水稻图像。
本研究通过图像处理技术和BP神经网络方法进行水稻施氮水平诊断识别建模,平均识别准确率达98.125%。该模型不仅能够避免训练陷入局部最小,而且能够有效地提高模型的整体性能,可用于水稻氮素营养状况分类识别,能够满足农学研究的需求。为计算机视觉技术进行氮素营养诊断识别研究提供一种新方法,也为进一步积极探索水稻氮素营养诊断的定量分析奠定基础,以指导水稻合理施氮,提高水稻产量。
