基于大数据的盾构掘进与地质关联关系分析方法
2020-03-13孙振川李凤远褚长海
孙振川, 李凤远, 褚长海
(盾构及掘进技术国家重点实验室, 河南 郑州 450001)
0 引言
盾构问世至今已有近200年的历史,作为大型复杂装备,在地下空间开发、隧道建设等项目施工过程中广泛应用。受开挖面地质情况、开挖过程突发情况等不确定因素的影响,盾构掘进及选型、设计参数的选择严重依赖专家及盾构司机经验,但经验往往不够全面、准确,且个人差异化明显。对于没有经验或者疲劳操作的司机而言,一旦出现特殊情况或操作不及时,掘进参数无法得到及时修正,则可能造成掘进不平稳、卡机甚至坍塌等严重后果。因此,保障盾构掘进安全、高效成为掘进过程中的一大挑战。为解决这一问题,量化地质参数,探究不同地质参数、装备参数下的掘进经验至关重要。
目前对于盾构掘进参数与地质参数的关联分析并不多。张莹等[1]对天津地铁某标段盾构实时掘进数据和地质参数进行关联分析,提出根据掘进参数定性识别地质特征的方法。余梓[2]对常见复杂地层进行总结,相应提出盾构施工的参数建议。彭涌涛[3]以南京地铁3号线某标段施工数据为依据,提出了盾构掘进姿态参数矩阵与其他施工参数、地质条件之间的关系。田管凤等[4]应用大数据技术对盾构施工引起的地面沉降进行分析预测,阐述了一种可行的地面沉降分析预测步骤。陈孝琼[5]以某河底隧道现场地质及施工参数为基础,通过理论分析、数值计算和现场监控研究了盾构下穿河流时掘进参数与地层变形规律。占传忠[6]以广州地铁6号线2期工程数据为基础,通过曲线拟合和统计回归方法得出盾构施工时掘进参数与相应地层的相互关系。已有文献大多以少量施工数据的经验,给出盾构施工与地层参数的关系,而对不同盾构、不同地层的多参数详细对应关系研究不足。
随着我国地下空间开发以及信息化、智能化和传感网等的加速发展,盾构工程中采集到的数据越来越多,使得利用大数据对地质和盾构掘进参数进行关联分析,量化盾构在各类地质中掘进的经验关系成为可能。鉴于此,本文依托盾构及掘进技术国家重点实验室大数据平台上采集的项目施工数据,将直方图数据主要分布区间的算法[7-10]应用于自动测量的各关键掘进参数主要经验区间,研究盾构掘进及地质关联关系。这些经验区间值可以作为特定装备条件和地质条件下的工作参数参考范围。
1 盾构大数据采集与数据库建立
为探索盾构掘进和地质环境间的关联关系,需要采集完备、有效可用的盾构施工数据及相应的地质环境参数数据,建立专业数据库。
盾构大数据采集应包括设备数据、地质环境数据、掘进参数数据,采集内容见表1。

表1 大数据平台采集内容
数据库的建立应从数据规模、计算能力、稳定性、可靠性、可扩展性和安全性等方面综合考虑。本文对掘进参数数据的存储,选择了开源分布式HBase数据库,它是一种构建在HDFS(Hadoop分布式文件系统)之上的分布式、面向列的存储系统,是可以实现实时读写、随机访问的大规模和分布式数据集;设备和地质环境数据选择RDMS(关系型数据库管理系统)数据库,它使用二维表结构,易于理解和操作,可以在业务上保持高一致性[11]。
平台采用可扩展和容错性强的数据处理Lambda架构,综合考虑了实时数据和离线数据分析的双重需求。这个数据架构处理大批量数据时结合了批处理和流处理方法的优点,如图1所示。
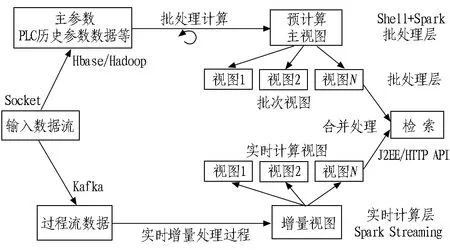
图1 实时和离线数据分析技术架构
所有进入系统的数据被分配到了批处理层和高速层。批处理层管理主数据集(一个不可修改、只能新增的原始数据集)和预计算批处理视图。服务层索引批处理视图,可以对它们进行低延时的临时查询。高速层只处理近期的数据。任何输入的查询结果都合并了批处理视图和实时视图的查询结果。大数据平台组件及说明如表2所示。
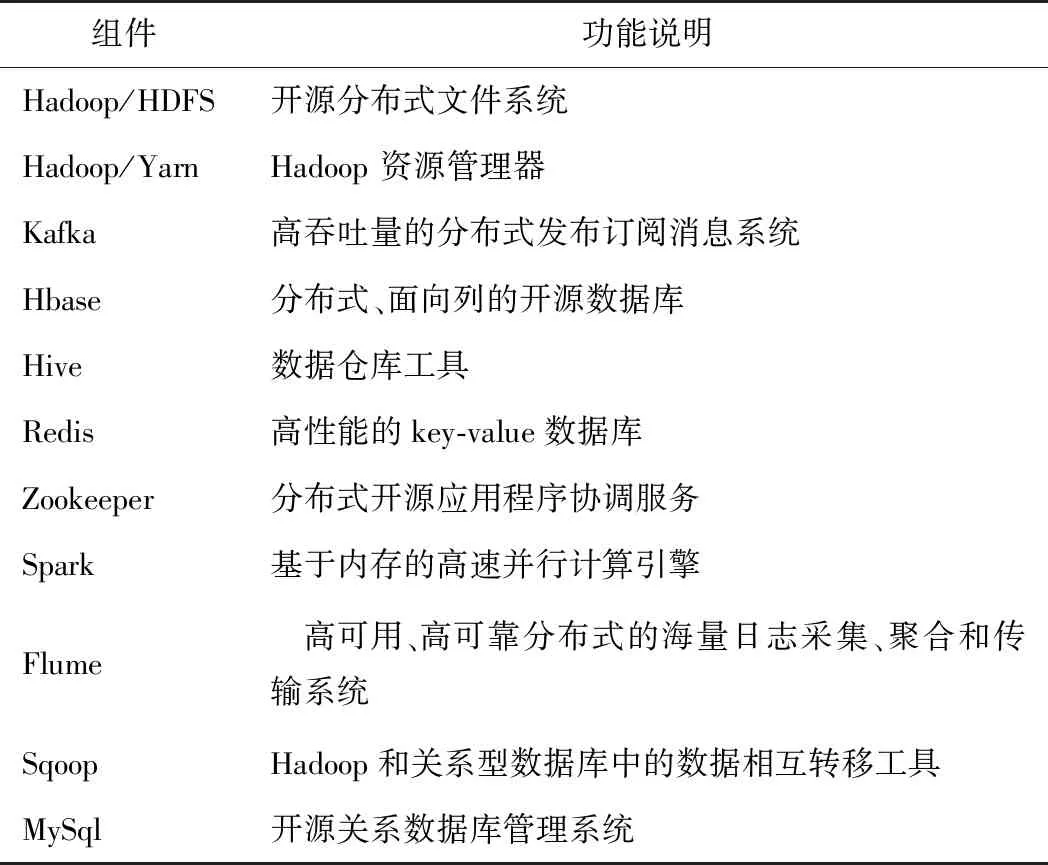
表2 大数据平台组件
2 关联分析建模和算法
2.1 关联分析的技术路线
关联分析首先要选取关联参数并分类,然后对参数进行清洗并规范采信原则,再进行大数据建模和算法选取,最后对关联分析成果指标进行可视化展示,技术路线如图2所示。
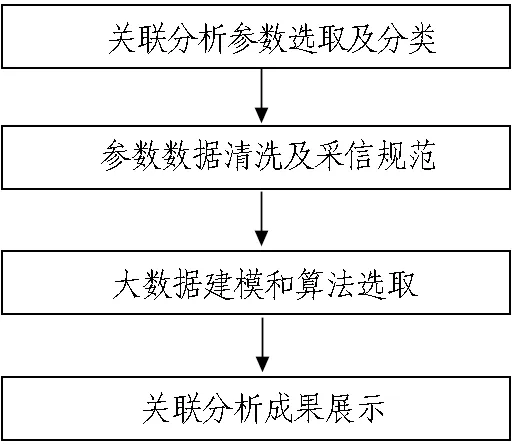
图2 关联分析技术路线图
盾构掘进过程中,参数种类众多,为挖掘掘进参数与地质关联的经验关系,需要分析地质环境参数(地区位置、岩土类型、抗压强度、完整程度,标贯值)、盾构的设备参数(直径、盾构类型等)以及掘进关键参数(掘进速度、转矩、刀盘转速、总推力等),并按照业务需要进行量化及适度分类。
盾构掘进参数由物联网和传感网采集,但由于传感器、实际工况等存在异常,会出现部分参数点位值异常,比如超大值的出现等,影响掘进指标数据的精度。因此,需要对数据库中数据加以清洗,建立采信规范,确保结果准确。
为得到不同地质和装备类型下盾构掘进参数的经验区间,需要对不同组合的参数分别建模,适度控制组合维度。对指标数据需要采用常规分布统计算法,计算关键掘进参数值分布相关指标及常规的众数、中位数、均值等,建立核心经验区域算法。为了确保指标数据实时更新,需要采用实时和离线合一的数据分析技术架构。
根据以上建模计算,在盾构TBM工程大数据平台上进行展示和检索,提供为客户优化的增值服务[12],展示指标如表3所示。
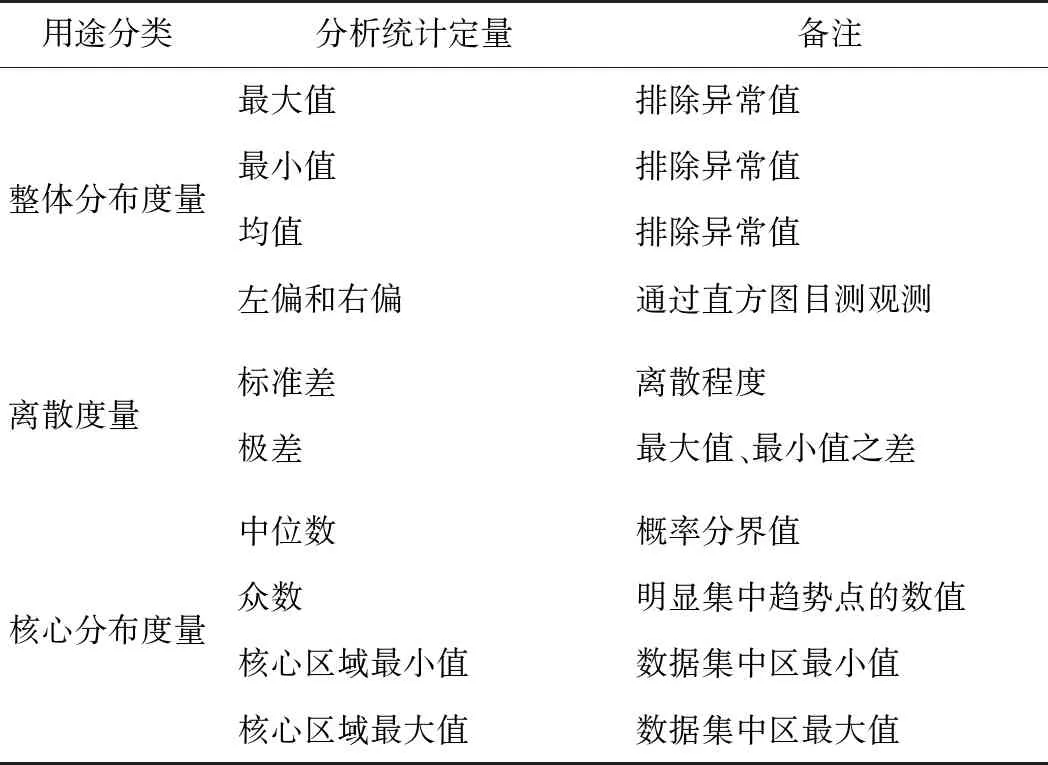
表3 分类分析指标用途
2.2 数据清洗和采信规范
对盾构采集的原始参数数据进行数据清洗、过滤,并规范采信确认的规则和方法。
2.2.1 数据清洗
根据盾构掘进模式进行初步筛选,经过分析,部分设备的掘进模式开关数据存在异常,或者进入掘进状态后到正式进入掘进工作模式之间存在一个准备时间,这部分数据的存在将影响掘进指标的计算。因此,需要指定参数阈值,剔除原始数据中过低的数据,确保后续分析数据为正式掘进模式下的数据。同时,部分老旧设备采集数据时,存在0环号的异常情况,具体表现为不定期出现0的状态(尤其是每天的前期数据),第2线路还存在例如8 000环(相当于该线路的初始0环)等异常,需要过滤。部分设备采集数据存在环号异常,出现小数、科学计数法表示的数据等,需要进一步过滤。
2.2.2 数据采信
由于数据传感器的漂变,由传感器传回的数据有时也会存在异常。对某盾构采集原始数据的环顺序进行分析,如图3所示。
方框标记的数据列为跳跃的环号,经统计这些环以及对应的数据大部分都很少,可以判定为不可采信的异常数据。针对异常问题,相应的处理措施如下:
1)部分设备采集数据存在环号异常,具体表现为不定期出现环号突然向前回跳或者向后跳跃的情况,需要根据环号和时间的关系,依据按时间顺序环号只会增加不会减少的规律排除跳跃的环数据,进行过滤,不过对于其中数据量较大的(超过100个连续数据)继续保留。
2)除了环号以外,掘进参数数值也会偶然发生异常,如表4所示。
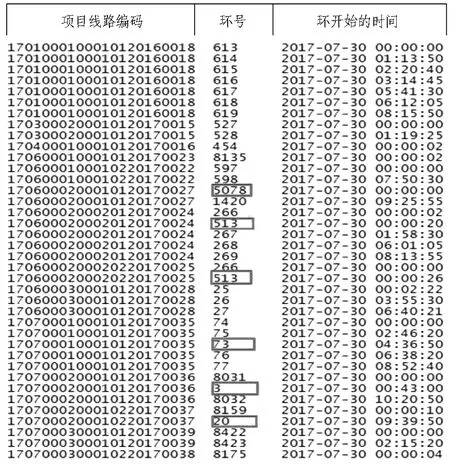
图3 某盾构采集的原始数据
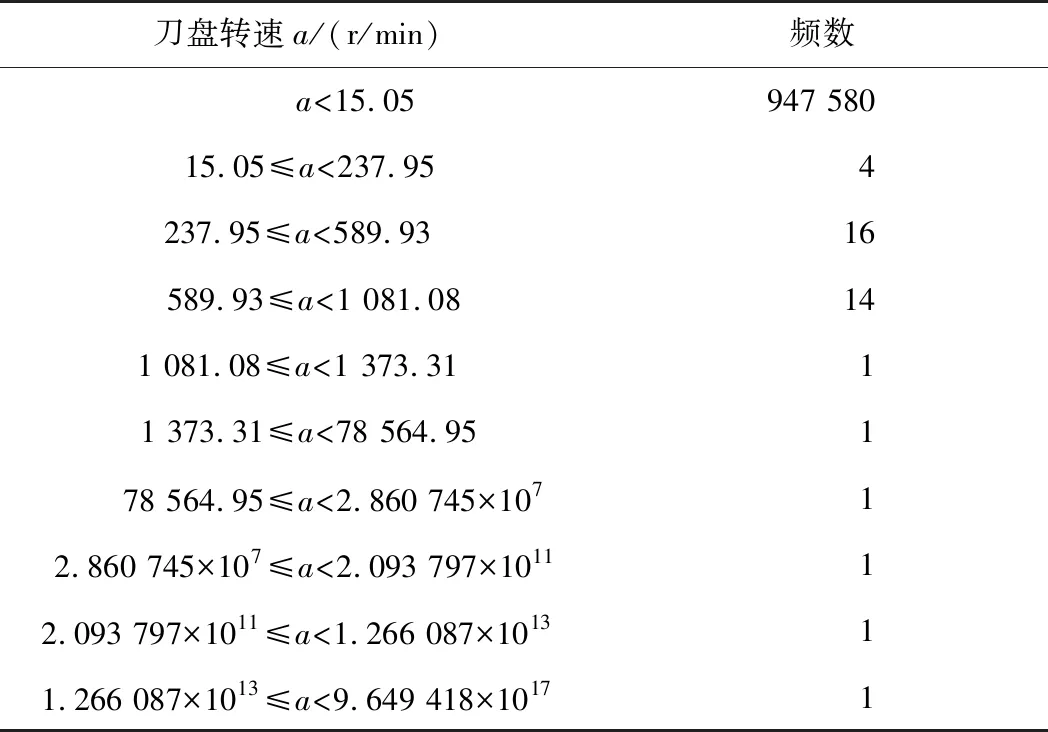
表4 掘进模式下刀盘转速
根据分析确定数据的正常范围,在数据处理过程中应过滤掉大于15的异常数据。
2.3 大数据建模和算法
2.3.1 多维度组建模分类
依据需求分析,涉及的维度包括7个参数项,分别是装备类型、装备直径、地质、公司、地区、项目、装备。排除必要维度(装备类型、装备直径、地质),共可以有16种维度组合,支持的维度构成组合如表5所示。

表5 维度组合
其中,地质组合又由4级地质编码构成,汇总每一级别的地质数据分析,则变换为16×4共64种维度组合,也就是说每一个原始数据参与运算后,最大可能产生或影响64个分析结果(假设其地质编码是4级)。产生或影响结果数量的关系如表6所示。
表6地质编码及分析结果对应关系
Table 6 Corresponding relationship between geological code and analysis results

原始数据地质编码级别产生或影响分析结果的数量464348232116
每个维组需要分析的点码目标包括掘进系统指标和导向系统指标,目前分析的点码目标如表7所示。
2.3.2 常规分布统计算法
采用常规统计学算法计算某单项点码数据分布的相关指标,如众数、中位数、均值等。由于算法是基于大数据的计算,为了保障计算性能,采用分段计算、逐步汇总的分阶段计算法。计算结果取近似众数、近似中位数、近似均值,与实际精确值有微小的偏差。例如: 对分时段平均值再汇总会有微小差异,不过作为参考值是足够精确的,这是一般大数据统计采用的原则[13]。基于经典的众数、均值、中位数算法,分布统计方法见表8。
表7 点码对应表

表8 分布统计方法
算法过程如下:
1)首先计算最大值和最小值。该过程在spark streaming实时分布计算框架下执行,实时调整最大值和最小值,这2个值是后续计算的关键参数。
2)根据最大、最小值计算频数直方图动态步长,动态步长每天调整1次。
3)根据步长将收到的每一个有效数据换算为日频数直方图上的点并累计次数。
4)按照16维度组合以及表6中对应的地质编码级别分别计算每个日频数直方图的最大值和最小值,计算最大64个日频数直方图结果。
5)每天定时通过spark和shell程序取得全天的直方图数据,分别汇总到累计直方图中并归一化直方图步长,得到新的累计直方图。如果没有累计直方图,则将日直方图直接复制为累计直方图。
6)对累计频数直方图根据频数计算众数、近似中位数、近似均值等。
7)不断重复以上过程。
2.3.3 核心经验区域算法
本研究创新性地将直方图的数据主要分布区间算法应用于自动测量各点码参数的主要经验区间,这些经验区间值可以作为特定装备条件和地质条件下的工作参数参考范围,结合均值等统计指标可以作为完整的指标结果组合。核心经验区域算法也是基于最大64种直方图,可以产生最大64种分类参考值结果。参考值范围由核心经验区域下限值和上限值构成[14]。其算法原理为,直方图将各点码参数重新归类后形成分布图,包括聚合点和频数,如图4所示。
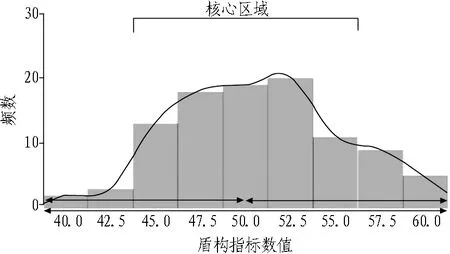
图4 参数点位值频数分布图
其中,45.0至57.5的区间为数据的主要区间,其他区间分布数据较少。这个区间是某点码参数的主要经验工作参数区间,结合装备类型和地质情况后所得的参考值区间有较大的参考价值。
算法过程为: 1)结合2.3.2算法过程步骤1—5。2)每天定时通过spark和shell程序取得累计频数直方图数据,按照一定的范围(默认60%,可在60%~80%中调整)运算直方图核心区域,当恰好存在多个符合区域时以偏右区域为准。具体算法是通过快速往复遍历算法判定核心区域。不断重复以上过程,可得掘进参数,见图5—8。
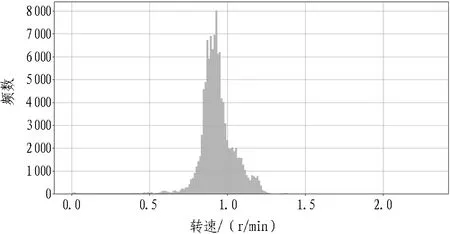
图5 刀盘转速数据频数直方图
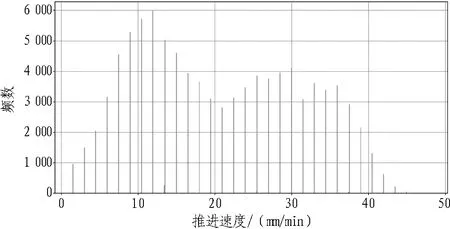
图6 推进速度数据频数直方图
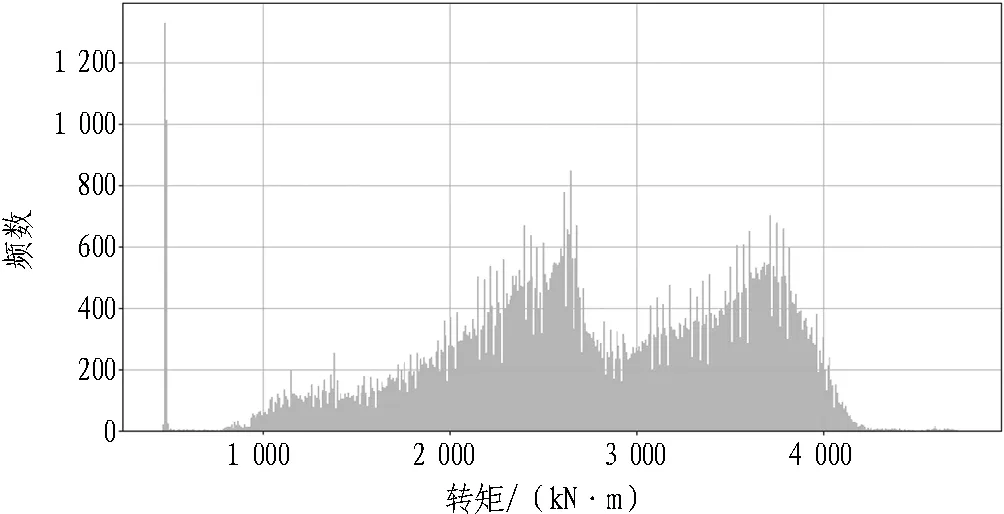
图7 刀盘转矩数据频数直方图
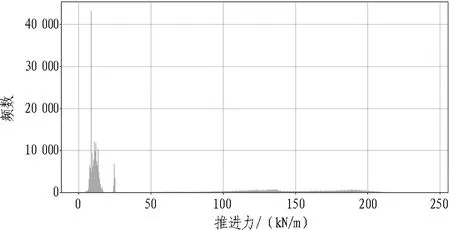
图8 推进力数据频数直方图
2.4 大数据关联分析算法详细流程
理论算法明确后,还需要考虑大数据环境下与常规抽样数据计算上的差异。常规抽样数据系统一般对全样本直接计算,但是,这对于大数据的海量数据而言是不可行的,因为数据量过于庞大,会出现数据无法装载、计算时间很长等问题。同时,随着数据增长还会出现无法对增量数据合并计算,因样本抽取方法不当引起数据扭曲等问题。所以,大数据分析算法流程需要专门设计,算法设计方案如下。
1)通过实时数据流对每一条数据立即分别按照各直方图当前的步长对归一化后的数据频次进行当日直方图频次汇总,到每日24点完成当日的直方图所有数据频次的累计计数;首个直方图作为累进直方图。
2)通过将数据按照时间切片进行累进处理,例如我们按日将各指标的当日直方图和累进直方图按照各指标当前步长做归一化处理。
3)将归一化后的2个直方图进行合并,得到新的累进直方图并保留。
4)按日展开当日的各指标直方图的维度,按照需求对项目线路上的每日装备直方图再次展开为16种维度,再按4级地质层级展开为最多10种地质编码组合,即可以生成最大160种直方图。
5)计算新得到的所有维度累进数据的以下统计指标: 中位数、众数、标准差、最大值、最小值、参考均值、核心区域范围最小值和最大值。
6)第2天继续以上过程,不断得到新的累进直方图数据和反馈修正的统计分析指标,反馈盾构施工的最新情况。
通过以上步骤,先实时对原始数据按照合理的步长做归一化处理,减少数据量,按合理精度做就近聚集,然后对数据按时间片切片累进处理并归一化合并,最后将得到的优化结果作为观测值进行统计指标分析,实现对所有原始数据的全覆盖[15]及精度可控(误差在一个合理的步长范围内),具体计算处理流程如图9所示。
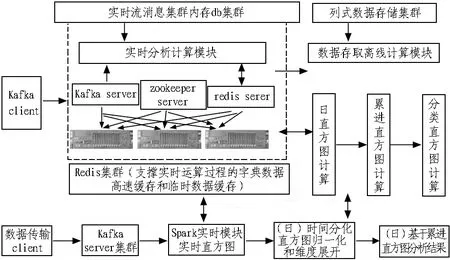
图9 实时和离线数据指标分类分析处理计算流程
Fig. 9 Calculation process of real-time and offline data index classification analysis
2.5 掘进经验指标成果展示
根据维度组合,检索各维度组合下盾构关键掘进参数的经验区间,显示最大值、最小值、平均值等指标数据。如图10所示,通过输入地质、装备类型、直径3个维度检索,利用关联分析算法得出直径6~8 m的土压平衡盾构在土层的掘进经验区间: 推进速度为16~40.02 mm/min,均值为31.05 mm/min,标准差为26.01 mm/min;刀盘转速为1.14~1.44 r/min,均值为1.27 r/min,标准差为2.82 r/min。关键参数关联分析直方分布图可示化展示如图11所示。
盾构掘进与地质关联分析系统已应用于中铁隧道局与广东省电力公司等多个项目施工中。通过对各个项目地质与掘进数据的关联分析,得出各地质条件下掘进参数的建议值,为施工提供实际的数据支撑。将盾构施工专家经验数据化,有效提高了各个项目的平均施工水平。
在盾构施工遇到突发孤石或基岩等地质变化时,需要实时关注掘进参数变化的影响。利用地质与掘进关联分析系统就可以明确获取该地质条件下最合理的掘进参数,如: 汕头苏埃隧道项目东线过基岩段时,利用该系统提取不同掘进参数配置数据,获取了适应于当时地质的掘进参数组。
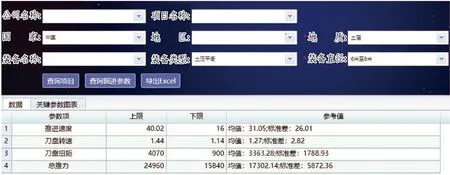
图10 关联分析维度组合检索

(a) 刀盘转速 (b) 刀盘转矩 (c) 刀盘推力
图11关联分析直方分布图可视化展示
Fig. 11 Visualization of direct distribution of association analysis
盾构掘进与地质关联分析系统在各种地质条件下积累的数据,明确了各种地质条件下盾构掘进参数的常规分布区间,为盾构订制设计提供了重要的量化数据支持,使盾构设计如刀盘布局、开口率、功率等关键参数设计有了实际项目数据支撑。
盾构掘进与地质关联分析系统在各个项目上获取的数据一方面可以作为指导该项目后续施工的经验数据;另一方面,这些带有地质、项目标签的关联数据保存在大数据平台,可以指导其他项目相似地质的施工。同时,可作为项目施工前论证阶段的盾构施工数据参考依据。
3 结论与建议
盾构掘进与地质关联关系分析方法解决了相关参数的选取及异常数据的分析清洗问题。通过分布统计处理算法,得到主要掘进参数和地质参数的关系,将传统盾构施工专家的经验转化为实际施工数据值,拓宽了经验的范围。该算法系统能根据实时数据动态调整参数经验区间值,并在中铁隧道局、广东省电力公司等25个项目上推广使用,有效地服务于项目施工,对盾构主司机和盾构从业管理人员起到了积极的指导作用。项目施工过程中积累的不同地质条件下的掘进参数经验区间能为盾构选型、设计提供明确的施工数据支撑。
因现场施工条件复杂,传感器采集的施工数据存在很多异常,且异常原因较多,本研究也只是做到了初步的数据清洗。对传感器采集数据并进一步清洗的系统算法模型研究是非常有意义的。在关联参数选取上,只是采用经验选取的方法,可能忽略了一些参数及参数关系族,因此,关联参数的相关性分析及自动选取、分类也是一个很有意义的研究方向。
