基于关联网络和层次聚类的中药社团发现算法的设计与应用*
2020-03-13陶妍心谢佳东董海艳胡孔法
陶妍心,杨 涛**,谢佳东,赵 静,董海艳,胡孔法
(1. 南京中医药大学人工智能与信息技术学院 南京 210023;2. 南京大经中医药信息技术有限公司 南京 210023)
处方用药是中医临床诊疗的核心与基础。用药是否准确、配伍是否精当将直接影响临床疗效。长期以来,名老中医的临床用药规律是中医临床研究的热点之一。如何从大量医案中挖掘名老中医的治疗经验,已经成为中医传承与发展的重要方向。随着信息技术的发展,越来越多的算法(如关联规则、聚类分析、复杂网络等)被应用到医案挖掘中,极大地提高了医案分析和整理的效率。在众多方法中,复杂网络以其处理复杂问题的独特优势,得到中医学术界越来越多的关注。社团发现作为复杂网络范围内的一种社团检测方法,可以通过聚集具有相同特点或表现出协调性的节点,从而挖掘网络中的隐含知识[1-2]。将社团发现运用到中药社团发现上,可以从医案数据中挖掘有价值的中药组合,进而总结名老中医的临床用药规律,将对名老中医经验传承提供技术支撑。
1 国内外研究现状
复杂网络是目前中医病证用药规律研究不可或缺的一种强有力工具,其中社团发现算法是根据“高内聚、低耦合”原则,从复杂网络中寻找联系相对紧密的节点的方法。目前,社团发现在生物医学、管理学、社会学等诸多领域均得到广泛应用。学者们针对不同结构的复杂网络,提出了多种社团发现算法,例如基于谱分析的算法[3-4]、基于模块度优化的算法[5-6]、层次聚类算法[7-8]、Girvan-Newman(GN)分裂法[9-10]等。
近年来,社团发现逐渐被引入到中医药领域,学者们通过将社团发现技术应用到对中药社团提取中,极大地提高了中医学病症用药规律发现效率。例如,李昕[11]等利用社团发现算法分析中药治疗肝炎肝硬化的用药规律,发现代偿期的治法以健脾益气、养血疏肝、化瘀软坚为主,失代偿期的治法以健脾益气、行气利水、化瘀软坚为主,为进一步指导临床用药提供了一定的理论指导;杜宁林[12]等利用社团发现算法分析中医临床的新药组成,并构建平台集成算法实现基于临床实际数据的中药安全性分析、混淆因素分析、中药七情分析和核心有效复方发现等新药发现分析应用;史琦[13]等利用社团发现算法分析冠心病患者四诊信息分布模式,并以1 480 例经冠状动脉造影确诊为冠心病患者的70项四诊信息为数据集进行实验,发现网络以度值较大的“倦怠乏力”、“健忘”和“腰膝酸软”为中心,周围辐射状依次排列着反映气虚、阴虚、血瘀、痰浊、阳虚、热蕴、气滞、脾虚的四诊信息节点的组合网络等。
在众多的社团发现算法中,GN 算法是最常用的方法之一[14]。其通过分类统计所有出现在同一对象中的元素,两两相连构造完全图,在图中通过循环剔除边介数高的边对初始社团进行划分。利用GN 算法分析中药数据,能够发现部分中药社团,但由于采用了全连接组网方式,将所有出现在同一方剂中的中药两两相连,导致计算复杂度的提升,冗余连接增加,影响后续社团发现效果。
鉴于此,本文提出一种综合运用关联网络与层次聚类的中药社团发现算法HCD,运用关联网络改进了传统中药组网方式,并运用自顶向下分裂的层次聚类划分社团。在降低传统算法时间复杂度的同时,增强了中药社团发现结果的准确度。为了验证算法的有效性,本文将HCD 应用到结肠癌医案分析,提取名老中医诊治结肠癌的核心中药社团,并对结果进行分析和讨论。
2 基于关联网络和层次聚类的中药社团发现算法HCD
2.1 概念提出与相关定义
(1)关联度(Double Confidence Relation,DCR)
假设存在两个中药节点X,Y,则节点X,Y间的关联度定义如下:


图1 算法流程
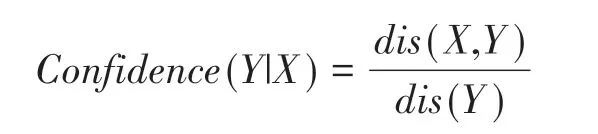
其中,dis(X,Y)是中药对(X,Y)的出现频率,dis(X)和dis(Y)则分别是单独中药X和Y的出现频率。
(2)边权比(Betweenness Value,BV)
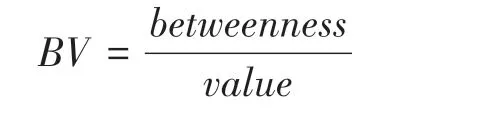
其中betweenness为边介数,value为边权值。

其中σst(v)表示经过节点v 的s →t 的最短路径条数,σst表示s →t的最短路径条数。
2.2 HCD算法流程
HCD 算法包括中药矩阵构建、关联网络构造、边权比网络转换、社团分裂四个核心步骤(如图1所示)。
①中药矩阵构建
扫描中药数据,得到不含重复的总中药集合。遍历原数据集,对比总中药集,取行为中药,列为方剂号。在同一方剂中,中药出现则置1,未出现则置0,构成中药0-1矩阵,以此作为计算准备。
②关联网络构造
利用矩阵运算分别计算两味中药的分别出现次数以及其共同出现次数,按照关联度计算公式得到两味中药节点间关联度,重复上述步骤得到所有节点两两之间的关联度,为组网作准备;通过遍历所有的中药组合,将中药输入节点集、取关联度与阈值进行比对,大于阈值者将两节点构成的边输入边集并将关联度作为该边权值,小于或等于阈值则排除,构成关联网络。
③边权比网络转换
首先,将关联网络的边集与节点集作为数据集输入,为边权比网络转换做准备;其次,将网络中各节点分别作为源节点,计算各边从节点到源节点的经过最短路径的次数之和,即各边边介数的计算;最后,将边介数除以对应权值计算出各边的边权比,并将其作为权值构成边权比网络。
④社团分裂
层次聚类即对数据集采用某种方法逐层地进行分解或者汇聚,直到分出的最后一层的所有的类别数据满足要求为止。本文采用自顶向下分裂的层次聚类划分社团。首先,将边权比网络的带权边集与节点集作为数据集输入,为社团划分做准备;其次,找出所有边中边权比最高的边并将其从网络中移除;然后,重复上述过程直到网络中所有边都被删除,即每个节点都是一个社团为止,得到最终的分裂树即为划分结果。最后,通过计算不同阈值下社团划分的模块度,选择模块度最高的划分作为最优结果。
2.3 算法伪代码
HCD(data,confidence)
INPUT:原始方剂数据集,阈值
OUTPUT:不同中药社团
DISCRIPTION:输入原始方剂数据集,将其转化为由中药编号为行,方剂编号为列构成的中药0-1 矩阵,以便计算单种中药出现频数与组合中药出现频数。再通过计算两两节点间的DCR并与阈值作比较,大于阈值者以DCR作权值输入边集,其余剔除。依据带权边数据集与节点集构建中药网络,再通过不断剔除边权比高的边并循环,得出最终分裂树,即社团划分结果
PROCESS:
1: import numpy as np
2: import pandas as pd
3: for foo in data:#data为原始方剂数据集
4: clean.append( foo)
5: clean = list(set(clean)) #clean 为无重复中药种类集
6: for i in range(len(data)):
7: for j in range(len(clean[ j])):
8: if clean[j]in data[i]:
9: fangji.append("1")
10: else:
11: fangji.append("0")
12: array.append( fangji) #fangji 为单个方剂的临时集合
13: array = np.array(array,dtype = 'int') #array为中药0-1矩阵
14: for x,y in range(len(array)): #单次分别取x,y两种中药
15: numberx = np.sum(arrayx[:,x]) #numberx为矩阵中x列中药的出现次数
16: numbery = np.sum(arrayy[:,y]) #numbery为矩阵中y列中药的出现次数
17: numberxy = np.sum(np.multiply(arrayx[:,x],arrayy[:,y]))#numberxy 为中药0-1 阵中x 和y 列中药共同出现的次数
18: Confidencex = numberxy/numberx
19: Confidencey = numberxy/numbery
20: if Confidencex > Confidencey:
21: DCRxy = Confidencex
22: else:
23: DCRxy = Confidencey
24: if DCRxy > confidence#DCRxy为xy关联度
25: value = DCRxy#value为边的权值集
26:add nodes into vertex
27:add edge and value into edges #使用边集edge与权值集value逐步创建带权边集edges
28:vertex = list(set(vertex))#vertex为去重节点集
29:create network with vertex and edges#依据边和节点集创建中药节点网络
30:do{
31: caculate betweenness in edges #计算所有边的边介数betweenness
32: caculate BV in edges #计算所有边的边权比BV
33: select maxBV#选择最大边权比
34: remove edges[index(maxBV)]#移除边权比最高的边

图2 GN划分模块度变化曲线
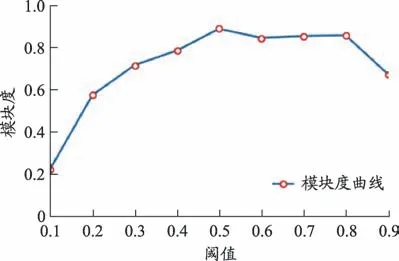
图3 HCD划分模块度变化曲线
35: k = len(edges)#k为边集中剩余边数
36:}while(k!= 0)#k为0时跳出循环
3 实验
3.1 数据准备
本研究纳入的病案资料为国医大师周仲瑛工作室数据库中记录的结肠癌显效及有效医案969 诊次,涉及269例患者。医案采集时间为2005年1月至2015年12月。为了更好地进行分析,本文对医案中的中药数据进行了清洗,过程如下:
第一步,参照《中国药典》对病案中的中药进行规范化处理,包括药名拆分、药名规范化等,例如“丹皮参”拆分为“丹皮”和“丹参”两味药,“南北沙参”拆分为“南沙参”和“北沙参”,“白夕利”改为“白蒺藜”,“蛇舌草石上柏”拆分为“蛇舌草”和“石上柏”等。
第二步,运用正则表达式对数据进行过滤。首先,按照逗号对各方剂进行拆分,其次,将方剂中所用中药名与别名表进行比对,统一规范化药名,去空值、异常值。
3.2 实验步骤
为了验证本文算法的有效性,将HCD 算法与经典的社团发现算法GN进行比较,具体如下:
①使用GN算法进行社团划分。
提取数据集中中药节点,选取所有出现在同一药方中的药对进行共现概率计算,大于阈值则该边保留并将其共现概率作为权值加入边集,其余剔除。将组建的网络图输出为节点集与边集。通过不断从边集中剔除边权比最高的边进行中药社团发现。阈值自0.1-1 以步长0.1 作自增长(若结果过低则将范围缩小至原给定区域的1/10,即阈值自0.01-0.1 以步长0.01作自增长),比较不同阈值下的GN 社团划分结果并依据模块度对结果进行评判。
②使用HCD算法进行社团划分。
依据3.2 中的HCD 算法流程对数据集进行划分,得到社团划分结果。设定阈值自0.1-1 以步长0.1 作自增长,比较不同阈值下的HCD 划分结果并依据模块度对结果进行评判。
③分别选取步骤①和②中模块度最高的结果进行横向比较并给出评价。
3.3 实验结果
①阈值自0.1-1 以步长0.1 作自增长变化情况下GN算法划分社团模块度变化如图2(a)所示。
从图2(a)中可以看出:GN 划分社团的模块度随阈值变化总体幅度较小,难以辨别明显特征,故选择将阈值变化范围缩小至1/10,即阈值自0.01 起,以步长0.01 作增长,0.1 为封顶进行观察,结果如图2(b)所示。从图2(b)中可以看出:GN 划分社团的模块度最大值低于0.006,且模块度曲线取值整体偏低。
②阈值自0.1-1 以步长0.1 作自增长变化情况下HCD算法划分社团模块度变化(见图3)。
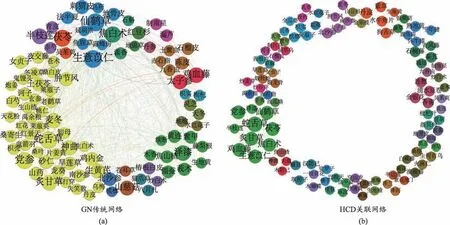
图4 GN算法与HCD算法组网结果对比
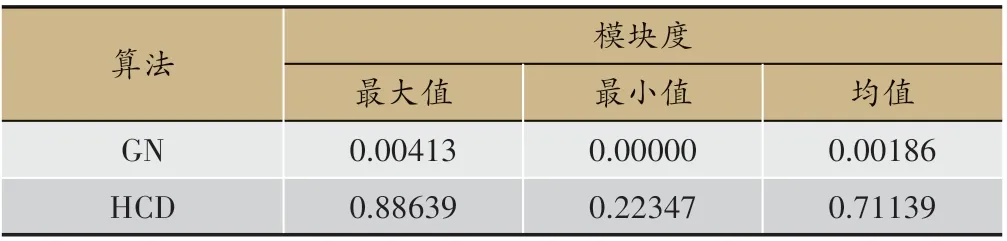
表1 GN与HCD划分社团结果模块度对比

表2 中药社团划分情况Top 10
从图3 中可以看出:HCD 划分社团的模块度曲线在阈值区间[0.5,0.8]内取值持续高于0.8,且模块度曲线取值整体较高,并于阈值区间[0.1,0.8]表现出随阈值增长趋于稳定。进一步对比HCD 和GN 模块度(见表1),可以看出HCD模块度较GN有大幅度提升。
③最高模块度时GN算法与HCD算法组网结果分别如图4(a)及图4(b)所示。
从图4(a)中可以看出:由GN 划分的传统网络存在边数过多、各节点间联系较为凌乱、社团内部联系不紧密、社团外部联系不稀疏等现象,整体而言社团划分合理性较差[15];从图4(b)中可以看出,由HCD 划分的关联网络边数较少,各节点间联系清晰,同一社团内部节点联系较为紧密,不同社团外部联系较为稀疏,社团划分较为合理[16]。
④最高模块度下HCD 算法划分社团结果中药物最多的社团有10 味中药,较少的为2 位中药,其中中药数量排在前10的社团如表2所示。
3.4 分析及讨论
从不同阈值情况下GN 算法划分社团模块度变化曲线(见图2)可以看出,由于GN 算法采用全连接组网方式,将所有出现在同一方剂内的中药节点两两相连,并未剔除误差节点与出现概率过小的边,虽然增加了所成完全图网络中的边数与节点数,但也导致了时间复杂度的提升与误差概率的增高,故采用GN 算法划分社团的模块度存在整体偏低的现象。从不同阈值情况下HCD 算法划分社团模块度变化曲线(见图3)以及GN 与HCD 划分社团结果模块度对比(见表1)可以看出,HCD 采用关联组网方式,择取关联度大于阈值的边加入网络,故所成关联网络中不存在关联过小的边,整体而言降低了所成网络的误差率,因此社团划分模块度较高,且随阈值增大曲线起伏逐渐平缓,不存在起伏过大或模块度整体结果偏低的问题。此外,从GN 算法取最高模块度时构建的网络(见图4(a))中可以看出,所有存在联系的节点全部在内,导致中药节点与边过于繁密且较为凌乱,难以找到清晰的中药社团结构,并存在大多数中药被划分入同一社团的问题。而从最高模块度下HCD 所划分社团网络(见图4(b))中可以看出,中药社团结构清晰,存在联系的节点大多被划分入同一社团,不存在中药节点与边过于繁密的问题。
在表1 最高模块度下HCD 算法的社团划分结果中,如社团1“党参,焦白术,茯苓,炙甘草,生薏苡仁,泽漆,半枝莲,蛇舌草,鸡血藤,仙鹤草”中的“党参,焦白术,茯苓,炙甘草”为补气健脾四君子汤,生薏苡仁健脾祛湿,泽漆行水消肿,半枝莲,蛇舌草清热解毒,药理研究有抗癌作用,鸡血藤补血活血,仙鹤草收敛止血、截疟止痢,整方攻补兼施,病证结合用药;社团2生地黄,丹皮,水牛角片,紫草,狗舌草”中的“水牛角,生地黄,丹皮”即为《外台秘要》中记载犀角地黄汤主要配比,水牛角清热解毒,生地黄,赤芍清热滋阴,丹皮凉血止血,加之“紫草,狗舌草”,整方清热解毒,凉血化瘀,且具抗肿瘤功效;社团8“半夏,陈皮”即为化痰基础方二陈汤的基本配比。二陈汤被宋代《太平惠民和剂局方》记录在内,具有燥湿化痰、理气和中的功效;社团9“黄连,吴茱萸”为左金丸的药物组成,黄连多而吴茱萸少,辛开苦降,可泻肝经痞热,使热从下达,有清泻肝火之效,同时可治疗肝火横逆,胁痛吞酸嗳腐,湿热下痢、泄泻。社团4、5、6 中,“紫花地丁,半边莲”内两味药便常相辅为用,为半边莲地丁茶中标准配比。半边莲地丁茶出自《中医良药良方》,其性味甘平,可利水消肿解毒,而“商陆,黑丑”亦可渗湿行水,使腹水由小便外解,从而达到治疗肝硬化腹水一症的效用,此外“诃子,石榴皮”两者皆为收敛固涩类药,有中医专家认为诃子、石榴皮除有收敛固涩之功外,尚有苦泄下气之效,不仅可用于虚证腹泻,亦可用于实证腹泻,临床只要配伍得当,对于各种腹泻均可起到良好的止泻效果[17],皆可达到防治结肠癌的功效。
综上所述,运用HCD 算法进行的中药社团发现结果符合中医评价标准,且符合专家经验。HCD 算法将关联网络和层次聚类相结合,通过计算节点间基于双向置信度的关联度构造关联网络,解决了不均衡情况下的单向依赖关系,在保证中药初始网络精简有效的基础上,运用基于边权比的层次聚类方法对网络进行划分,能够较好地解决中药社团划分问题。
4 结语
本文通过对过往人们所使用的探索中医用药规律的方法进行思考,分析复杂网络社团发现方法对探索用药规律的重要意义,探究传统社团发现方法应用于中药社团发现上的种种不足,提出了一种新型的中药社团发现算法HCD,从医案中的中药配伍规律分析入手,通过矩阵运算、关联网络、层次聚类等方法,建立相应的中药社团发现算法HCD,利用模块度对各阈值下的结果进行评价,选择模块度最高的中药网络,最后对社团划分的结果进行评价。利用该算法对中医医案方药进行分析,成功提取了不同中药社团,结果符合专家经验。本文提出的中药社团发现算法HCD 具有原理简单、易于实现等特点,可以为广大中医药临床和科研工作者提供便捷、高效、易用的中药社团发现工具,提高中医临床医案研究的效率,为名老中医用药经验传承提供方法学参考。
