基于高光谱与在线序列极限学习机确证大米产地方法
2020-03-13王靖会曹崴冷全阳程娇娇王艳辉沈海鸥陈雷王朝辉
王靖会, 曹崴, 冷全阳, 程娇娇, 王艳辉, 沈海鸥, 陈雷, 王朝辉
(1.吉林农业大学信息技术学院,长春 130118;2.吉林省长春市净月开发区福祉街道办事处,长春 130122;3.吉林农业大学资源环境学院 长春 130118;4.吉林省长春市交警支队南关区大队,长春 130000;5.吉林农业大学食品工程技术学院,长春 130118)
大米是我国主要粮食之一,不同产地大米的口感与营养价值具有较大差异,而大米外观及品质用肉眼难以鉴别,使得低质高价、混淆真伪、产地造假等现象日益严重。传统鉴别方法包括感官识别、近红外光谱、矿物质元素等,都有一定的劣势与不足。感官评价不仅对从业人员有很高的经验要求,且容易受主观影响而错判,近红外光谱方法需要对大米进行粉碎处理,矿物质元素方法实验繁琐且周期长,均无法满足快速无损的确证需求。
近年来,高光谱图像技术在无损检测领域发展迅速,其在获取样本光谱信息的同时也可以获取样本的图像信息,具有快速、无损、准确性高等特点,被广泛应用于农产品的产地鉴别、损伤识别和品质检测中[1-9]。但其数据高维性以及相邻波长数据点存在共线性和冗余等问题,限制了在实际应用中的便利性[10]。降维是对高维度数据特征的预处理,基于高维度的数据保留下最重要的一些特征,去除噪声和不重要的特征,从而提升数据处理的速度[11-14]。多维尺度分析(multidimensional scaling,MDS)是一种在低维空间去展示高维多元数据的可视化方法,其基本目标是将原始数据“拟合”到一个低维坐标系中,使得由降维所引起的任何形变最小。在高光谱特征提取与降维中,MDS既能保留光谱所包含的维度信息,又不会对降维后的数据特征产生衰减[15]。目前,基于高光谱数据建立分类模型的相关研究多是基于支持向量机(support vector machine,SVM)、偏最小二乘判别(partial least squares discrimination analysis,PLS-DA)、多层感知机(multi-layer perceptron,MLP)等[16-18]。随着实际应用中高光谱图像数据量的不断增加,SVM、PLS-DA、MLP等方法的训练方式都存在反复迭代的问题,大大增加了训练时间。
由于高光谱数据中包含大量非线性数据,本文选择更适应于非线性数据处理的在线序列极限学习机(online sequential extreme learning machine,OS-ELM)算法[19]、极限学习机(extreme learning machine,ELM)算法[20]与多层感知机(MLP)算法[21],分别建立大米产地确证模型,并在分类准确率与训练时间上进行对比分析,探究一种适用于大米产地确证的高效、准确、稳定的方法。
1 材料与方法
1.1 样本采集
1.1.1大米样本采集 梅河口市是吉林省主要的优质粳稻生产基地,是世界黄金粮食生产带。梅河大米以其米饭特有的香、粘、滑、软而闻名,为我国地理标识保护产品。本研究样本采集于吉林省梅河口市水稻主产区和松原、辉南、大安等其他水稻产区。遵循空间采样布点原则[22],在梅河口市主产区采集成熟的水稻样本585组,非梅河产区采集水稻样本405组,具体采样区域及采样点分布如表1所示。利用JLGJ4.5砻谷机、HNMJ3碾米机(河南郑州南北仪器设备有限公司)对其进行脱壳、碾米处理后,每组样本随机选取15粒米作为高光谱检测样本。
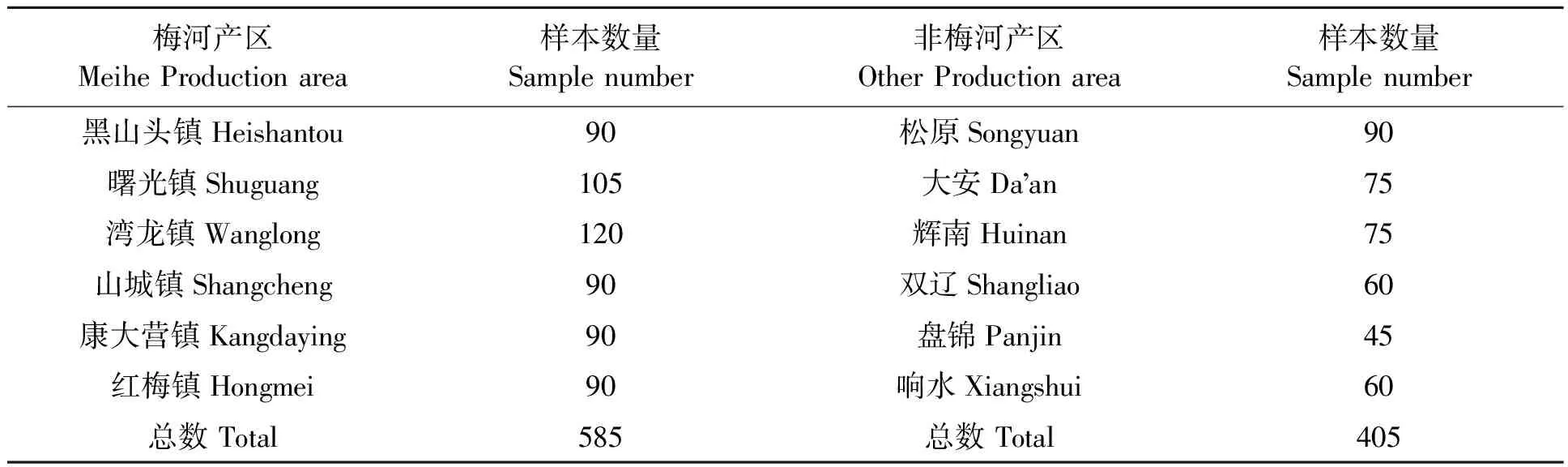
表1 大米样本采集点分布表
1.1.2高光谱图像采集及校正 利用高光谱图像采集系统(图1)采集大米原始高光谱数据,该系统波长范围为400~1 000 nm,由2×2 binning压缩方式的成像光谱仪(Imspector V10E-QE,Spectral Imaging Ltd.,Oulu,Finland)、P/N 9130线光源及2900ER控制器(Illumination Technologies,USA)、C8484-05G相机(Hamamatsu Photonics,Japan)、V23-f/2.4 030603镜头(Specim,Finland)、GZ02DS20可升降样品台(光正公司)和PSA200-11-X电控位移台(卓立汉光公司)构成,采用9589(EKE-ER,Philips公司)全光谱卤素灯为光源。在相机与镜头之间加入2 mm的近摄接圈以保证获取清晰地样品图像。为了有效获取能代表大米产地的高光谱信息,经多次试验对比后,将大米样本按照3×5网格分布,以单粒随机摆放至载物台黑板上,物距为13.5 cm,曝光时间为15 ms,位移台移动速度为1.62 mm·s-1。
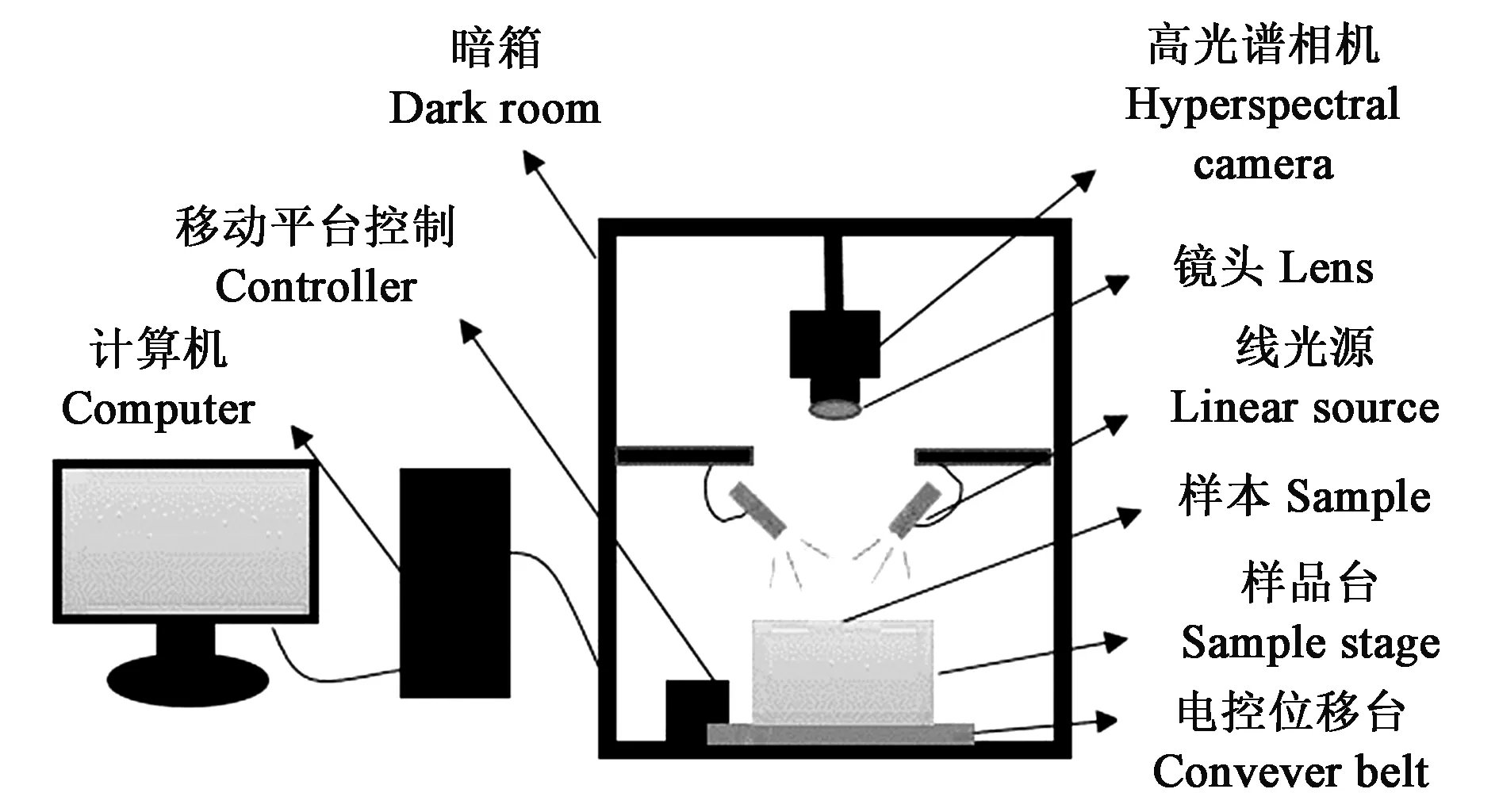
图1 高光谱图像采集系统
为避免在高光谱成像系统中暗电流的影响以及光源强度分布不均匀等情况,采用Spectracube 2.75b(spectral imaging ltd,oulu,finland)软件进行高光谱图像采集和黑白校正,再对样本进行高光谱图像采集,如式(1)所示。
(1)
式中,E0为未校正光谱图像;P为标准白板(spectral on,lab sphere lnc,USA)的全白标定图像;Z为关闭电源盖上镜头盖后的全黑标定图像。
1.2 感兴趣区域选择
感兴趣区域(region of interest,ROI)选取方法直接影响建立模型的分类精度。本文在3×5网格内所有单粒米样的中间部位选取,采用如图2所示的10×10像素的红色正方形区域作为感兴趣区域,通过计算感兴趣区域内所有像素的均值反射率得到每个样本的平均光谱数据。均值反射率计算如式(2)所示。
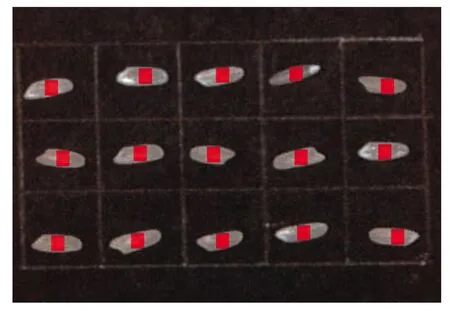
图2 感兴趣区域选择
采用ENVI 5.0对高光谱图像ROI进行选择,感兴趣区域内均值反射率由ENVI5.0计算生成。基于Python3.6软件提取高光谱图像对应的光谱数据。采集的高光谱图像共549个波段。
1.3 光谱预处理
为提高模型分类准确率与稳定性,本文分别采用标准正态变量变换(standard normal variate,SNV)、多元散射校正(multiplicative scatter correction,MSC)[23]及卷积平滑(savitzky-Golay,S-G)[24]方法对光谱进行预处理,将预处理后的数据导入MLP、ELM、OS-ELM模型,并根据模型分类性能对预处理方法进行选择,以获得最佳预处理方法。预处理软件采用Matlab.2016b。
1.4 特征波长选取
由于全波段光谱含有大量冗余信息,导致算法性能下降,本文采用Python3.6编写及运行MDS算法,从第51~499波段(468~942 nm)的光谱中提取特征波长,输入测试集与训练集样本的光谱数据和类别编号,共采用13个特征波长用于后续建模分析。
1.5 分类方法
由于高光谱数据中所包含大量非线性特征数据,本文选取能够实现复杂非线性映射的分类方法建立产地确证模型,建模过程由Python语言编程实现。本文运用Python第三方库pandas程序包中的Sample函数实现数据分层抽样以保证数据划分的随机性和一致性,在保证梅河与非梅河的大米样本比例一致的前提下将原始数据集的990个样本以7∶3的比例随机划分为训练集和测试集,其中693个训练集样本用于模型的建立和优化,297个测试集样本用于外部精度检验。
1.5.1多层感知机 多层感知机网络(MLP)是一种误差反向传播的多层前馈神经网络算法,本文采用Python语言,首先导入sklearn库中的neural_network.MLPClassifier包,加载训练数据,之后训练模型,最终输出MLP模型的测试集评价。
1.5.2极限学习机 极限学习机(ELM)是一种无需在训练过程中反复调整输入层与隐含层间的连接权值,且隐含层神经元的阈值是随机产生的算法[25-27]。本文采用Python语言,导入sklearn库中的metrics验证方法,首先输入样本集、激活函数和隐藏层节点数,之后随机设置输入权值和隐含节点偏置,计算隐藏层输出矩阵以及输出矩阵的广义逆矩阵,再计算极限学习机的隐含层到输出层的权值,最后输出权值,实现ELM模型。
1.5.3在线序列极限学习机 在线序列极限学习机(OS-ELM)是ELM的在线学习改进算法。本文采用Python语言,在ELM模型算法的基础上加入在线序列阶段,得到单个样本或者样本数据块初始阶段所学习的单隐层前馈神经网络的输出权重,实现OS-ELM模型。
1.6 模型评估
1.6.1模型性能评估 混淆矩阵(confusion matrix)是一种用可视化方式呈现算法性能的评价标准,它通过矩阵描述样本数据的真实类别属性和预测结果的关系[28]。本文模型准确率由混淆矩阵计算得出,如式(2)所示。
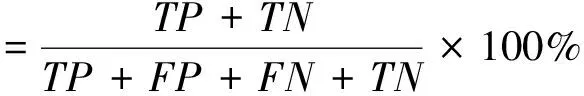
(2)
式中,TP为真正例,定义为被判定为梅河样本,事实上也是梅河样本;TN为真反例,定义为被判定为非梅河样本,事实上也是非梅河样本;FP为假正例,定义为被判定为梅河样本,事实上是非梅河样本;FN为假反例,定义为被判定为非梅河样本,事实上是梅河样本。
1.6.2模型效率评估 为了验证OS-ELM和ELM训练效率上的性能优势,本文随机选取500组样本数据分别训练3种算法,计算三种算法的训练时间。对于OS-ELM算法,设置隐含层数L为10、选取参与初始学习阶段的样本个数N0为100、数据块长度为[75,250]区间的随机数;ELM算法设置隐含层数L为10,MLP隐含层数亦为10。
1.7 训练时间对比测试
为了模拟实际应用中不断地分批次得到新数据的数据获取途径,本文假设分五次每次获得100组共500组数据进行模型训练与测试,OS-ELM在线学习数据块长度设置为20,对OS-ELM和ELM同时输入100组变量作为第一批数据进行训练,并依次加入100组训练样本作为新添加数据,分别计算OS-ELM与ELM的训练时间。
2 结果与分析
2.1 基于全波段高光谱数据的产地确证模型
为了避免光谱区间边缘响应低、噪声大对模型所造成的负面影响,本文剔除了1~50(408~467 nm)和500~549(944~100 7 nm)波段光谱,选取第51~499(468~942 nm)波段光谱进行分析。
将经标准正态变量变换(SNV)、多元散射校正(MSC)及卷积平滑(S-G)方法预处理并进行样本划分后的高光谱数据作为输入变量,计算MLP、ELM、OS-ELM三种方法的分类准确率,结果如表2所示。可以看出,SNV与S-G预处理方法对分类准确率有一定程度的负面影响,而基于MSC处理后的分类结果与全波段分类结果相比略有提高,其中所建立的MSC-OS-ELM模型的分类效果最优,分类准确率达到了98.3%,说明建立的模型具有良好的性能,利用MSC对光谱信息进行预处理可以得到良好的产地确证模型。
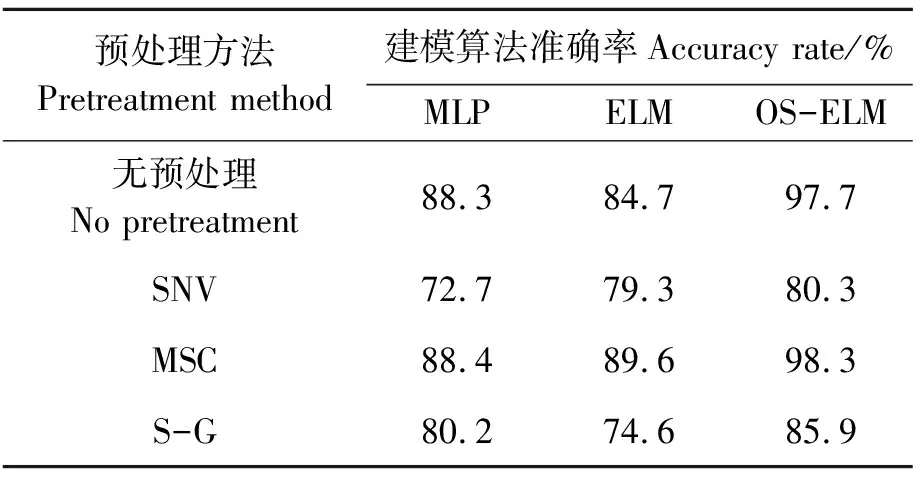
表2 基于预处理方法的全波段分类准确率对比
2.2 基于高光谱特征波长数据的产地确证模型
2.2.1特征波长分析 经MDS提取13个特征波长为484、510、536、560、608、720、750、780、841、854、899、921、932 nm。选取的特征波长位置如图4所示。据已有研究,510、560、750 nm 的吸收波段主要与大米中水分、脂肪、淀粉和蛋白质的吸收有关[29]。位于608、536 和720nm 的吸收波段与大米中直链淀粉和支链淀粉的吸收相关[35];780 nm左右的光谱吸收主要与水分子中O-H键的第二和第三倍频峰的振动和延伸相关[36]。而蛋白质、脂肪、糖等大米内部重要的化学指标均可以由高光谱信息表征,且大米颗粒中最主要的水分和淀粉等理化指标,因大米的产地不同其含量也会有一定的区别[37]。这些对应关系从大米理化指标上进一步验证MDS降维方法选取的特征波段是可靠的。
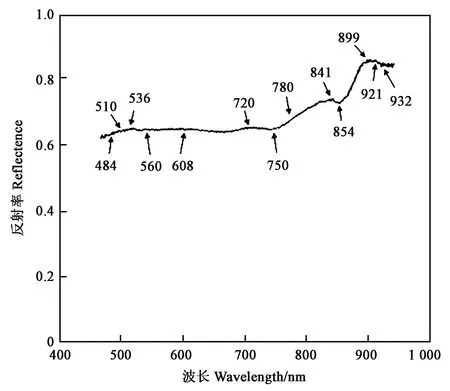
图3 特征波长选择
2.2.2模型性能评估结果 在990组高光谱样本中,将经MSC预处理与MDS降维后提取的特征波长高光谱数据按照随机划分好的693组训练集与297组测试集进行三种模型的训练与测试,测试结果如表3所示。

表3 全波段光谱数据与降维后数据分类准确率对比
通过对基于全波段光谱数据和特征波长光谱数据所建立的判别模型进行对比可知,MDS-MLP分类准确率相比较于全波段光谱数据模型下降了1.3%,MDS-ELM下降了1.1%,MDS-OS-ELM则下降了0.9%。基于特征波长数据的分类模型识别率下降均在1.3%以内,其中MDS-OS-ELM准确率能达到97%以上,而输入变量减少了96.6%,大量冗余信息被剔除。
2.3 模型运行效率评估
2.3.1全样本训练时间对比 OS-ELM、ELM、MLP三种模型训练时间如表4所示。可以看出,本文采用的OS-ELM算法在训练时间上与ELM基本相同,对比于MLP算法,在相同的参数取值下,模型训练时间极大地减少。
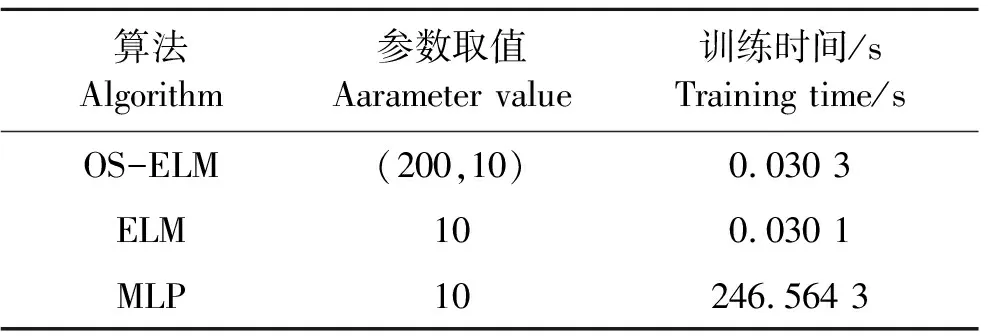
表4 三种模型训练时间对比
2.3.2累次增加样本训练时间对比 不同样本训练时间比较结果如表5所示。可以看出,在数据样本分批次获得的情况下,对于初始的100组样本,OS-ELM训练时间略高于ELM。而随着分批次数据样本的加入,ELM需要找回已经学习过的初始的100组数据与新加入的数据一起训练网络,OS-ELM由于在任何时候都仅需对新加入的样本进行学习的特点,避免了重复学习已经训练过的旧样本。另外,对于OS-ELM,数据在学习完成之后立即删除,不再占用RAM运行内存空间,因而训练时间低于ELM。同理,加入的数据样本越多,OS-ELM的优势越明显。

表5 OS-ELM与ELM按比例增加数据后模型训练时间对比
3 讨论
多层感知机网络(MLP)是一种误差反向传播的多层前馈神经网络算法,是由若干层感知机神经元组成的非线性神经网络。MLP不仅结构简单且易于实现,可以通过共同作用的多层神经元解决大多数线性不可分的问题。但训练速度较慢,有时需要通过特征工程对输入数据进行特征提取[30]。极限学习机(ELM)是一种批量学习算法,由输入层、隐含层和输出层组成,由于其无需在训练过程中反复调整输入层与隐含层间的连接权值,且隐含层神经元的阈值是随机产生的特点,近年来被广泛用于高光谱数据的分类分析[31-33]。较之传统的神经网络算法具有学习速率快和泛化性能好等优点。OS-ELM不仅保留了ELM的优点与特点,且能有效地衔接旧样本与新加入的样本,对样本进行灵活的分批处理,避免了数据重复训练所带来问题,有效的提高了模型的准确率与训练效率[34]。本文采用Python语言基于高光谱图像技术建立了MLP、ELM、OS-ELM算法的产地确证模型。
由于受电噪音、光散射、基线漂移、光程变化等因素的影响,使得高光谱数据中包含大量的干扰信息[35]。本文分别采用多元散射校正(MSC)、标准正态变量变换(SNV)、卷积平滑(S-G)方法对光谱数据进行处理。最终基于MSC处理后的数据建立的MLP、ELM、OS-ELM模型分类准确率均高于未进行预处理和经SNV、S-G预处理的。其中所建立的MSC-OS-ELM模型的分类效果最优,分类准确率达到了98.3%,证明MSC可以对数据进行良好的修正及处理。
全波段光谱数据具有很高的维数和复杂的结构,带有大量的冗余信息,使得时间和空间复杂度上升从而导致算法性能下降[36],大大影响了实际应用中的便利性。多维尺度分析(MDS)是一种非常有效的数据降维方法[37]。与上述方法不同的是,在高光谱图像技术特征提取领域,MDS能够有效的在低维数据中保留高维数据间的相对关系,减小降维引起的任何形变,既不会对降维后的数据特征产生衰减,又保留了光谱所包含的维度信息。为了简化输入变量,提升模型训练效率,应用MDS降维方法提取了13个有代表性的特征波长,降维后输入变量减少96.6%,大大减少了光谱数据信息的数量。基于特征波长数据分别建立MDS-OS-ELM、MDS-ELM和MDS-MLP模型,其中MDS-OS-ELM算法模型分类准确率稳定在97.4%,降维在保证模型分类性能的前提下提高了模型训练速度。基于特征波长光谱数据所建立的模型在分类准确率上虽略低于基于全波段光谱数据所建立的模型,但运算时间缩减效率提高,更加适合于快速无损鉴别大米产地的需求。
在模型训练效率评估试验中,ELM与OS-ELM在模型训练时间上明显优于MLP。由于MLP在模型训练过程中需反复训练和修改连接权值、阈值的原因,使得模型在训练时间上不具有优越性。而ELM相比较于MLP算法,其输入层到隐含层的权值和阈值都是随机产生的,避免了反复训练和修改连接权值阈值的过程;另一方面,隐含层到输出层的权值矩阵实质上是利用最小二乘法求取使损失函数最小化的最优解,不需要迭代过程。因此,从理论上ELM算法相比较于MLP能够大大地降低网络训练调节时间,有着极快的训练速度。而OS-ELM算法是ELM的在线序列学习改进算法,每当有新的数据块被接收,就重新运行一次ELM并得到新的输出权重,最后新旧输出权重会进行组合从而完成对神经网络的更新,避免了对已经训练过的样本重复学习,大大提升了模型效率,满足了快速无损的大米产地确证需求,在大数据背景下的地标大米产地确证领域更具有实用性。
