基于Docker的Spark云计算实验教学平台搭建与应用
2020-03-11贺释千张海涛王宇宾李可强
贺释千,张海涛,王宇宾,李可强
(河北科技师范学院数学与信息科技学院,河北 秦皇岛,066004)
Spark是UC Berkeley AMP lab开发的计算引擎[1],由Scala 语言编写。处理大规模数据往往需要使用Spark,如大规模分布式机器学习[2],社交网络分析及其相关算法[3,4]。该引擎的开发和测试均是在Linux上完成的。虽然可以勉强在Windows上运行,但使用中存在诸多问题,如软件包依赖问题、防火墙问题、端口冲突等。所以,无论是商业应用还是科研工作大都是将Spark部署在Linux上运行。但是,目前大多数学校实验室机器都使用Windows系统,这为实际教学带来了困难。而使用Docker可以解决这一难题。Docker是一个开源的应用容器引擎[5,6,7],类似一个轻量级的虚拟机,但比虚拟机更轻。可以运行在Linux和Windows 10(Windows 7通过虚拟机运行)上。Docker支持将精心裁剪后的Linux及其软件打包成为一个容器,然后将该容器的镜像发布到网上(如DockerHub)供用户下载。因为,该容器的镜像在发布前已经将所有的运行环境、软件及依赖都打包完成。所以,用户下载该容器的镜像后,可以像运行普通软件一般,通过命令运行该容器。这极大简化了软件的部署。
虽然目前已经有一些文献介绍了基于Docker的应用,如基于Docker的Hadoop平台[8],但这不是针对实验教学。为此,笔者基于Docker为Spark搭建所需的Linux实验环境,并结合Jupyterhub,Anaconda等开源项目搭建该实验平台,以期解决计算机实验面临的一些实验困难问题。
1 工作原理
该平台是B/S架构的。客户端只需要一个浏览器访问服务器即可。服务器上平台主要部分的架构见图1。

图1 基于Docker的Spark云计算实验教学平台的架构
最下面是服务器操作系统,其上是Docker,再其上是容器的操作系统Ubuntu,最上面两层就是容器里主要安装的软件和库。其中的JVM是Java虚拟机,因为Spark的运行需要Java虚拟机。Anaconda是一个包管理器,负责安装和管理Python,Jupyterhub,PySpark。
PySpark是Spark官方支持的Python调用接口(库),Jupyterhub是一个支持多用户在浏览器中直接编写Python代码的项目。采用这样的平台架构配置方案其原因有两点:(1)虽然Spark官方支持Scala,Java,Python和R等4种语言的API调用。但目前官方对Scala,Python两种语言的API支持的最好。(2)现在学校大多开设Python课程,学生对Python的接受程度更高。所以,接下来将搭建一个支持多用户在浏览器中直接编写Python代码调用Spark的云计算实验教学平台。
2 平台搭建
2.1 安装Docker
Docker的设计是将软件的运行环境,即操作系统OS(operating system),视为一个货轮。每个在其基础上的软件或库如同货轮上的集装箱。用户可自行安装软件和配运行环境,如同在货轮上放置一个个集装箱。最后,交付的成品包括软件和运行环境,就好像将整个货轮及货物一起交付。
使用Docker的过程中会遇到镜像、容器和仓库这几个概念,其中镜像和容器的关系类似于面向对象编程中的对象与类。 镜像是静态的由上游开发者提供的OS镜像,包括已经安装的软件或库。容器是根据镜像生成的,可以由用户更改,比如更改安装新软件。但与面向对象编程不同的是,由用户更改后的容器可以生成新镜像,供他人使用,而仓库则是这些镜像的存放地。
一般的流程是:首先,由上游开发者提供镜像,并将其push到仓库中;然后用户从仓库pull镜像到本地并运行;最后用户可能会根据自己的需求安装新软件调试后运行。
Docker可以在Windows或Linux上安装,Windows上安装Docker的过程极为简单,在此不赘述。
Linux的安装较为复杂,下面以Linux的开源免费版centos 7为例安装Docker,其中使用的是Docker CE (即社区免费版)。
首先安装一些必要的系统工具,命令为:
yum install -y yum-utils device-mapper-persistent-data lvm2
使用yum安装软件的过程中需要下载软件包,如果发现下载的速度慢可以添加yum软件源(命令为yum-config-manager --add-repo 一个yum源),然后更新 yum 缓存即可(命令为yum makecache fast)。
安装 Docker命令为:yum -y install docker-ce
启动服务命令为:systemctl start docker
2.2 配置Jupyterhub
该教学平台使用的是Jupyterhub开源项目。该项目支持多用户在浏览器中直接编写Python代码,Jupyterhub的依赖包括Python,Notejs,Jupyter等,如果从零开始安装,这些依赖都可以通过包管理器Anaconda(其命令为conda)安装。但Jupyterhub开源项目在Doucker仓库(DouckerHub)提供了一个镜像(该镜像是基于Ubuntu的)可以通过如下命令下载:
docker pull jupyterhub/jupyterhub
运行该镜像的命令如下:
docker run -t -i --name spark_ container -p 8000:8000 jupyterhub/jupyterhub /bin/bash
其中
run 是基于镜像新建容器并运行的意思。
-t选项是分配容器一个为总断并绑定到当前宿主机的标准输入输出上。
-i选项是保持容器的标准输入输出状态为打开。
--name spark_container 是新建容器名称为spark_container。
-p 8000:8000 是映射端口,将宿主机器(centos)的8000端口和容器(Ubuntu)的8000端口映射。
jupyterhub/jupyterhub是要运行的镜像名称。
/bin/bash是容器开始运行后要执行的命令。
接下来会用包管理器Anaconda(其命令为conda)安装软件,过程中需要下载软件包,如果发现下载的速度慢可以设置conda软件源。设置conda的源(命令为conda config --add channels https://一个conda的url源)后要设置conda的url源状态为yes(命令为conda config --set show_channel_urls yes)。
Jupyterhub依赖于jupyter 和notebook。更新jupyter和notebook的命令如下:
conda update jupyter
conda update notebook
某些Jupyterhub/Jupyterhub版本的镜像可能没有安装jupyter 和notebook,这时需要通过下述命令安装jupyter 和notebook:
conda install jupyter
conda install notebook
因为Jupyterhub使用了PAM(Pluggable authentication module)来管理用户,所以需要用下属命令和配置文件完成Jupyterhub的多用户配置。
添加测试用户命令如下:
adduser u1
adduser u2
输入记住的用户名和密码,之后配置和登录都需要。
用下属命令可以生成Jupyterhub的配置文件jupyterhub_config.py:
jupyterhub--generate-config
生成配置文件jupyterhub_config.py后在文件里添加如下配置:
c.Authenticator.admin_users = {‘u1’}
c.Authenticator.whitelist = {′u2′ }
上述配置设置了u1为管理员,u2为普通用户。
注意当运行jupyterhub -f jupyterhub_config.py命令时,如果工作目录中有名为jupyterhub_config.py的配置文件,则该命令会自动读取该配置文件,那么该命令可略写为jupyterhub。因此,最好将该配置文件放到容器内运行的工作目录中。
这样做的主要原因是简化后面启动项目命令,否则在容器外很难用一条命令启动Jupyterhub。
启动后可以通过浏览器访问,输入管理员u1的用户名和密码后可以进入Jupyterhub管理界面见图2。
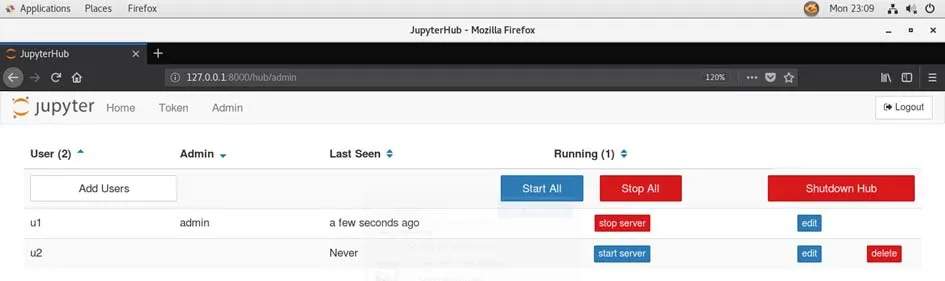
图2 基于Docker的Spark云计算实验教学平台的Jupyterhub管理界面
至此支持多用户在浏览器中直接编写Python代码的Jupyterhub已经配置完成,但如果在其中希望直接调用Spark还需要继续安装Spark及其依赖。
2.3 安装Spark
PySpark是一个Spark官方提供的库,该库让python 可以调用Spark。安装命令如下:
conda install pyspark
上述命令可以将PySpark和Spark以及它们大多数依赖都会自动安装上,但jdk的不会自动安装。
因为Spark是运行在JVM(Java Virtual Machine即Java虚拟机)上,所以需要另外再安装jdk。
但因为Jupyterhub 官网提供的Docker 镜像是基于Ubuntu的,而该镜像中没有安装jdk,所以需要另外安装,安装的命令如下:
apt-get install default-jdk
另外,为了加快下载软件的速度,可以在安装前添加apt软件源到/etc/apt/sources.list中,然后更新apt缓存即可(更新的命令为:apt-get update)
需要说明的是,目前Spark有如下几种运行模式:
Local模式,用于开发调试Spark应用程序。
Standalone模式,Spark自身进行资源管理、任务调度和计算,采用Master/Slave结构。
Mesos模式和Hadoop YARN模式,这两个模式分别运行在Mesos和Hadoop YARN资源管理框架基础之上,将资源管理交给Mesos和Hadoop YARN,Spark只负责运行任务调度和计算。
考虑到学生的接受程度和学校机器的负载能力,本平台使用的是Local模式。
最后将spark_container保存成一个镜像,命令如下:
docker commit spark_container spark_teaching_platform_img
3 演示运行
该平台的测试环境为centos7,平台运行使用如下命令:
docker run -it -p 8000:8000 spark_teaching_platform_img jupyterhub
启动后可以通过浏览器访问http://127.0.0.1:8000,进入登录界面,输入用户名和密码后可以进入编程界面(图3)。
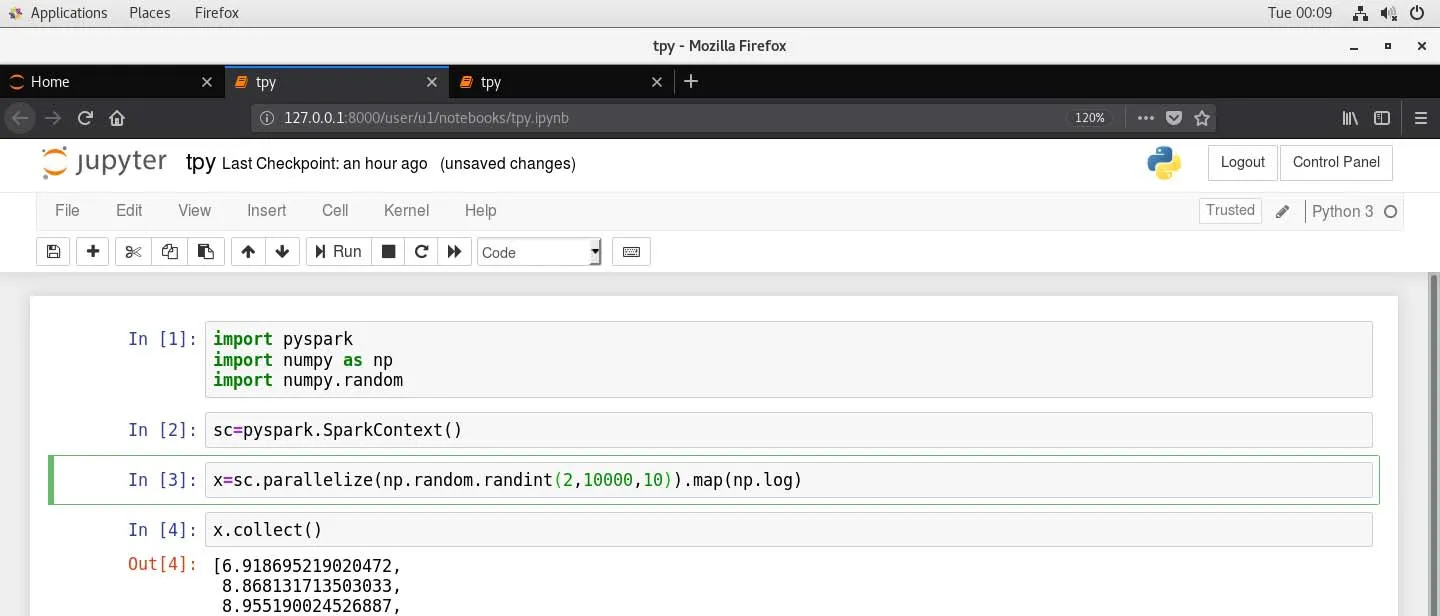
图3 基于Docker的Spark云计算实验教学平台的编程界面
4 实验设计
实验课之前任课教师需要提前搭建好基于Docker的Spark云计算实验教学平台,在此平台上学生就可以进行Spark这门课程中的各个实验了。下面以“Spark数据读取与查询实验”这个内容为例介绍一下整个实验。
实验题目:Spark数据读取与查询实验
实验目的:通过Spark数据读取与查询实验,使学生了解Spark数据读取与查询基本知识,掌握 Spark的数据读取与查询方法。实验结合 Spark与SQL进行编程,查询数据,培养和锻炼学生编程能力,为进一步的大数据分析学习做准备。
实验环境:本实验所需要的实验环境为提前搭建好的Spark云计算实验教学平台,其中主要使用的软件库有Docker,Spark,PySpark。
实验教学内容:(1)教师讲解Spark 支持的文件格式,如最基本的 txt,csv,json等,介绍Spark 的读取函数spark.read.csv() , spark.read.json(), spark.read.text()。(2)教师演示编程过程,使用Spark读取文件得到DataFrame 对象,使用createOrReplaceTempView()函数创建临时表 ,使用spark.sql()执行查询语句,使用show()显示结果。
实验过程:(1)把参与实验的学生分为若干小组,每组 4~5 人。(2)要求每组学生下载实验数据和API文档。(3)让学生根据教师演示过程进行基本的数据读取与查询实验。(4)让学生结合学过的SQL语句,通过编程完成数据筛选。(5)让学生总结实验的收获以及应当改进的地方。
实验效果:实验教学前教师先行搭建好基于Docker的Spark云计算实验教学平台,为学生完成实验做好了充分的准备。学生完成上述实验项目后,对Spark数据读取与查询基本知识有了更加深入的了解,掌握了 Spark的数据读取与查询方法,锻炼了学生的编程能力,为进一步的大数据分析学习奠定了一定的基础。
5 总 结
本次研究首先介绍了Spark云计算教学中遇到的问题,其次介绍了如何通过Docker解决该问题,并详细介绍了通过Docker搭建Spark云计算实验教学平台的方法,演示了该平台的使用,最后在所搭建的基于Docker的Spark云计算实验教学平台上顺利进行了“Spark数据读取与查询实验”的实验教学。
