基于组合优化算法的短期风电功率预测
2020-03-11孙海蓉王瑞珈
孙海蓉, 张 鸽,2, 王瑞珈,2
(1.华北电力大学 控制与计算机工程学院,河北 保定 071003; 2.华北电力大学 河北省发电过程仿真与优化控制工程技术研究中心,河北 保定 071003)
0 引 言
风能是一种公认的清洁无公害的可再生能源,也是一种潜力很大的新能源。在我国,随着环保意识的加强,风力发电取得了较大的进展,但也面临着运行状况的频繁改变、发电不稳定等问题,威胁着电网的安全运行。因此,从风力发电的安全性、经济性的角度考虑,对风电功率进行预测,其意义十分重大[1]。
风电功率序列是非平稳信号,会受到随机因素的影响。为此,国内外学者对风电功率的预测进行了广泛的研究,并提出了多种数据分解方法,但预测结果都达不到令人满意的程度,例如:傅里叶分解法自适应效果差[2];小波分解法的分解能力受基函数的影响较大且分解结果含有残留噪声[3];经验模态分解法(Empirical mode decomposition,EMD)利用自身信号驱动建立基函数,虽提高了时频分辨力,但是分解过程产生的模态混叠现象影响EMD分解性能,降低了准确性[4],采用集成经验模态分解(Ensemble empirical mode decomposition,EEMD)可以解决此现象,但其重构分量残留噪声较大[5]。文献[6]提出的基于互补自适应噪声的集合经验模式分解算法(EEMD with complementary adaptive noise,EEMDCAN),可以大大提高信号的分解效率。EEMDCAN算法对每一阶段的余量信号进行EMD分解,并在分解阶段添加正负噪声时,大大降低了重构误差以及筛选次数。
自回归分数积分移动平均模型(Autoregressive fractionally integrated moving average,ARFIMA)常常被用来预测序列的线性分量。该模型具有很强的时间预测能力。然而,风电功率序列具有很强的波动性和不可替代性,用线性分量不能精确描述。故还需对残差序列进行风电功率的非线性分量预测[7]。而广泛应用的神经网络适应性强,但初始值的选取对模型的精度影响较大[8]。支持向量机(Support vector machines,SVM)算法简单易于训练,不易陷入局部最优,对于非线性数据的预测,取得了比神经网络更好的预测效果。
基于以上研究内容,本文提出一种风电功率组合预测算法(EEMDCAN-ARFIMA-PSOSVM)。首先采用EEMDCAN方法分解风电功率时间序列,然后对分解过后的序列使用ARFIMA模型进行单独的预测。残差序列采用一种改进的粒子群寻优算法优化的SVM模型来进行预测。用该组合算法对风电功率进行预测,有效的提高了预测精度,并通过对比实验证明了其性能指标均优于其他预测方法。
1 EEMDCAN分解原理
风电功率序列具有非线性非平稳的特征,EMD方法具有很强的适应性能够有效的分解此类型的时间序列,但易于出现模态混叠现象。EEMD方法向原信号增加随机的白噪声来平衡信号中的极值点分布,并分别进行EMD分解,最终的实际分量是对数次 EMD分解的模态分量进行集成平均而得。增加集成平均次数在一定程度上能减小重构误差,但信号重构时残留的剩余噪声较大且加重计算负担[9]。
EEMDCAN方法在EEMD方法基础上,对分解过程添加经EMD自适应分割的噪声分量和正负噪声对,克服了由于集合平均次数限制下重构误差较大的问题。使用该方法对风电功率序列进行预处理,使得分解后的序列较为平稳,可以突出原始风电功率序列的局部信息。
EEMDCAN算法描述如下:
(1)令s(n)表示原始风电功率序列,对信号s(n)添加标准的白噪声和正负噪声对,第i次的信号序列表示为
si(n)=s(n)+(-1)qε0vi(n)
(1)
式中:q=1,2,i=1,2,…,I;I表示添加白噪声和正负噪声次数;vi(n)代表第i次实验中增加的具有标准正态分布的白噪声序列;εk为增加噪声序列的幅值。
(2)经过EMD分解后得到的第1个模态分量:
(2)
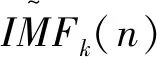
(3)在第k=1阶段,获取第一个余量信号
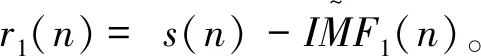
(3)
式中:Ek(·)为序列分解的第k阶模态分量;E1(vi(n))为白噪声vi(n)分解的第一阶模态分量。
(4)类似地,对其余每个阶段,即k=2,…,K,对第k个剩余分量加正负噪声对并进行EMD分解,对I个固有模态分量集合平均后得到第k+1个模态分量,即有
(4)
(5)
(5)重复执行步骤(4),直到信号不能再被分解,最终的余量信号为
(6)
原始风电功率序列s(n)的分解结果可以表示为
(7)
EEMDCAN一定程度上抑制了模态混叠现象,算法降低筛选次数,减少重构误差。
2 ARFIMA模型
由于风电功率的长记忆特性,引入ARFIMA模型进行风电功率序列线性部分的预测。
若序列ρ~ck2d-1(k),c>0满足方程:
(1-B)dφ(B)Xt=θ(B)at
(8)
则称{Xt}服从ARFIMA(p,d,q)。其中B为滞后算子,{at}是白噪声序列,|d|<0.5,(1-B)d为分数差分算子,φ(B)为p阶的平稳滞后多项算子,θ(B)为q阶的平稳滞后多项算子。
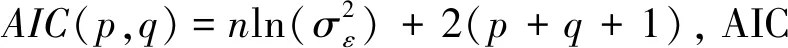
3 优化SVM模型
单独使用ARFIMA模型对风电功率进行预测往往精度不高,适应性不强,因此本文将风电功率序列分为线性部分和非线性部分分别进行预测。
SVM模型有较强的理论支撑[10],可以很好地预测风电功率序列的非线性部分,本文在SVM模型的基础上引入粒子群算法[11],避免了参数选取的盲目性,提高了系统建模的精确性。
基于SVM的优势,本文设计的粒子群优化的SVM模型描述如下:
训练数据是{(xi,yi)|i=1,2,...,N},N为风电训练样本数。xi∈RN为第i个风电数据样本输入,yi∈R为对应输出。预测模型表达式为
f(x)=ωTφ(x)+b
(9)
式中:ω为权值;b为偏差;φ(x)为非线性映射。
SVM优化目标可由式(10)表示:
(10)
式中:C为惩罚因子;ξ,ξ*分别为松弛变量;ε为不敏感损失参数。
SVM优化目标问题是一个非线性规划的问题,可以通过加入拉格朗日乘子,可将问题转变为对偶问题。由式(11)来表示预测模型。
(11)
式中:ai,ai*≥0为拉格朗日乘子;K(xi,xj)为满足Mercer条件的核函数。
核函数参数是影响SVM预测效果的关键因素[12,13],使用优化粒子群算法得到其参数的最优值[14],提高预测精度。
基本PSO算法是用Vi=(vi1,vi2,…,viD)表示第i个粒子的速度,在搜索空间中对应的位置表示为Xi=(xi1,xi2,…,xiD)。其速度更新方程为
(12)
式中:d=1,2,…,D;i=1,2…,n;D为搜索空间维度;n为粒子总数;k为当前的迭代次数;Vid为粒子的速度;ω为惯性权重系数;c1、c2为加速度因子,均是非负的常数;r1、r2为分布在0到1之间的随机数。
基本PSO算法的缺点是算法有时得不到最优解,粒子陷入在某一区域而得到局部最优的结果[15]。为了使得粒子均衡分布,可以对基本PSO算法进行优化,如每计算一次粒子的位置,就计算一次粒子与其他粒子的距离,进行粒子的位置更新,这样可以改善粒子在空间的分布特性,得到全局最优解[16]。

(13)
式中:Δlk表示设定粒子间最小的允许距离。
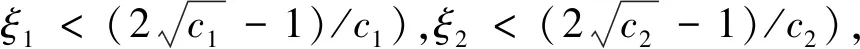
SVM优化算法可以达到在初始阶段时较为快速地全局寻优,在后期较为精确地局部寻优。
4 建立组合预测模型
风电功率序列值存在较大的波动性,首先要对风电功率序列进行数据处理包括归一化处理和坏值剔除。式(14)对原始风电数据进行处理,限制在一定的范围内:
(14)
式中:xmax和xmin分别为样本中历史风电功率的最大值和最小值。
(15)

4.1 预测模型评价标准
为了验证所建模型的准确性,选取广泛使用的三种性能指标对模型进行评价。
(1)相对误差[17](Relative Error,RE)
(16)
(2)平均绝对百分误差 (Mean Absolute Percent Error,MAPE)
(17)
(3)均方误差(Mean Square Error,MSE)
(18)
4.2 建立组合预测模型步骤
选用EEMDCAN-ARFIMA-PSOSVM组合方法对短期风电功率预测,步骤如下:
(1)对风电功率数据进行预处理[18];
(2)采用EEMDCAN算法分解预处理后的风电功率数据,得到模态分量;
(3)对分量使用ARFIMA模型进行线性预测;
(4)对各个IMF分量残差序列建立相应的SVM预测模型,模型最优参数采用改进粒子群算法获得,得到每个分量信号的最佳预测值;
(5)线性预测的结果加上非线性预测结果得到最终预测结果;
(6)采用滚动预测方法[19],将预测出的数据加入到训练数据中,组成新的训练样本集;
(7)重复(3)~(6)直到得出待预测时段的结果;
(8)各个分量的最终预测值相加即为最终的风电功率预测值;
(9)分析模型的性能指标[20]。
建模过程如图1所示。

图1 EEMDCAN-ARFIMA-PSOSVM建模框架Fig.1 EEMDCAN-ARFIMA-PSOSVM modeling framework
5 风电功率预测实例
5.1 实例求解分析
将EEMDCAN-ARFIMA-PSOSVM方法应用于风场的短期风电功率预测中。实验数据来自于国内某风电场2018年2月到5月的风电功率数据,共采集到65台风机的数据。选取1号风机连续20天的风电功率数据构成时间序列,采样间隔为15 min。以前19天的数据为训练集,预测第20天的风电输出功率。原始风电场输出功率序列如图2所示。

图2 原始风电场输出功率序列Fig.2 Original wind farm output power sequence
将实验样本数据进行归一化处理和坏值剔除。采用EEMDCAN方法对序列分解,加入共100组标准差为0.1的白噪声信号,分解结果分别如图3所示,重构误差如图4所示,所需迭代次数如图5所示,分解出的IMF1序列如图6所示。

图3 EEMDCAN方法的分解结果 Fig.3 Decomposition results of the EEMDCAN method
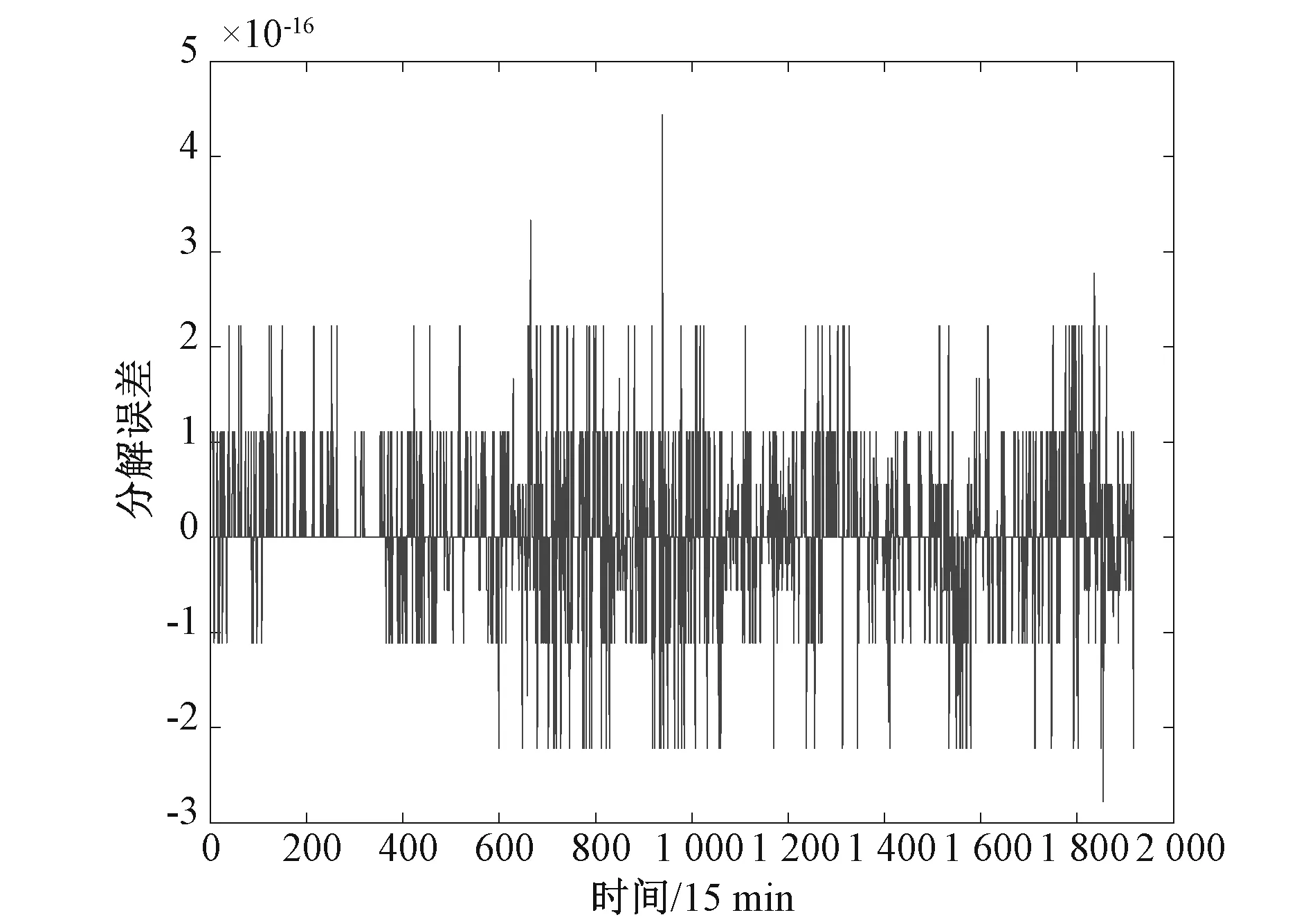
图4 EEMDCAN 方法的重构误差Fig.4 Reconstruction error of EEMDCAN method
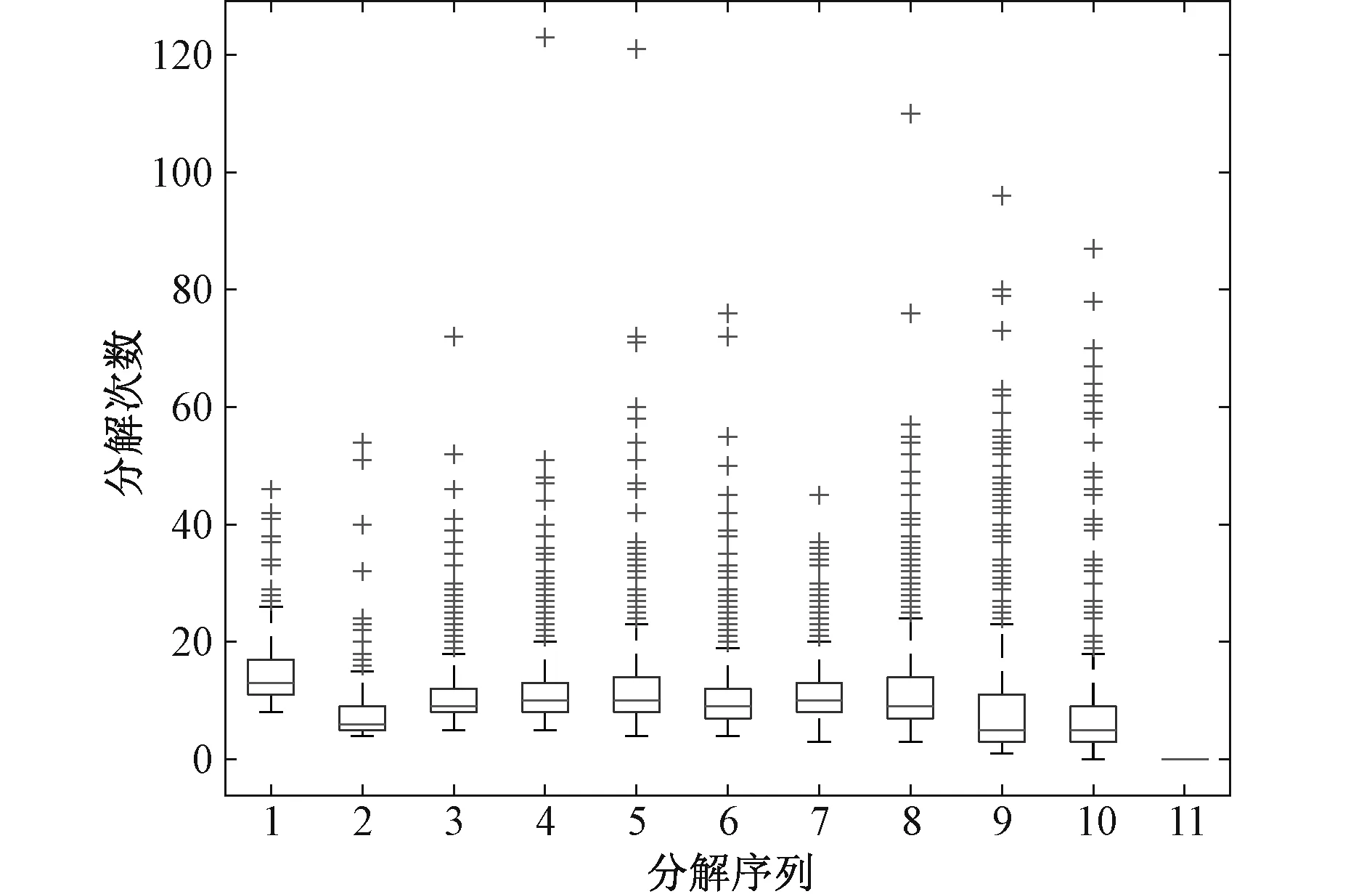
图5 各序列分解所需迭代次数(EEMDCAN)Fig.5 Number of iterations required for each sequence decomposition(EEMDCAN)

图6 IMF1分量时间序列图Fig.6 IMF1 component time series diagram
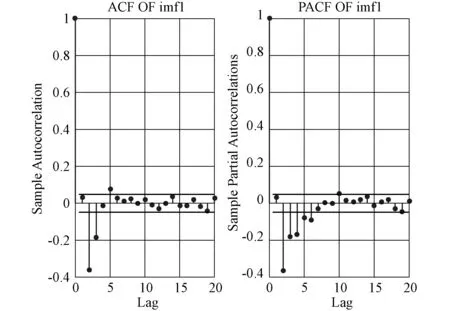
图7 IMF1分量自相关和偏自相关系数图Fig.7 IMF1 component autocorrelation and partial autocorrelation number diagrams
由图7所示的自相关和偏自相关图不难发现,IMF1序列模型的最优阶数在9阶以内。
由表1可见,当p=7,q=9时,BIC数值最小,因此确定模型为ARFIMA(7,d,9)。
对IMF1分量进行预测,将IMF1残差序列送入优化SVM预测模型,相关参数设置见表2。
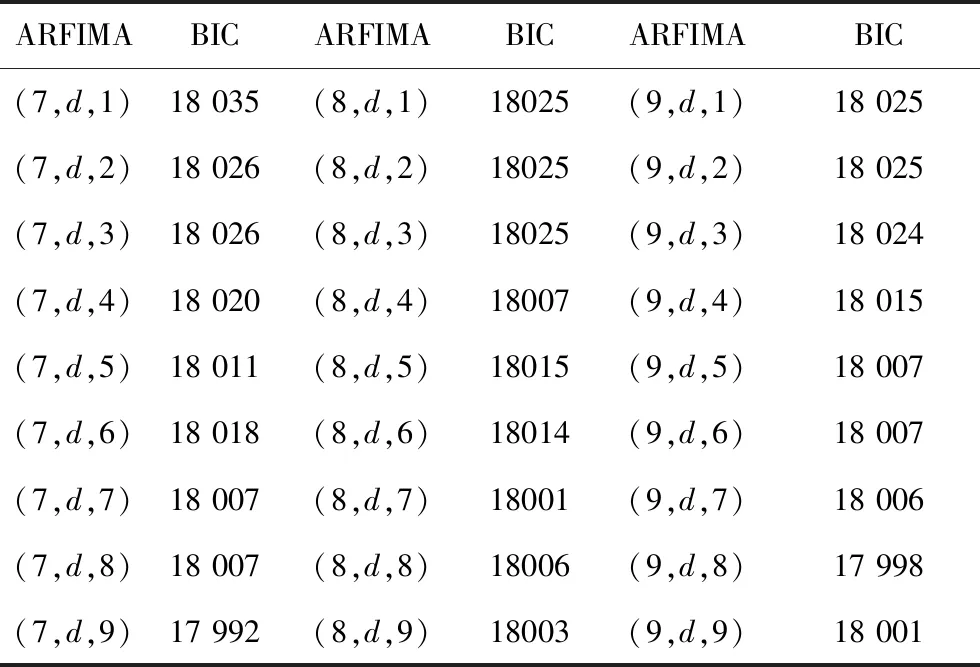
表1 部分模型对应的BIC值(d=0.4)

表2 SVM预测模型参数

图8 EEMDCAN-ARFIMA-PSOSVM预测结果Fig.8 EEMDCAN-ARFIMA-PSOSVM forecast results
5.2 模型对比
为检验该组合预测方法的有效性,采用单独SVM、EEMD-ARMA-SVM、神经网络算法、EEMDCAN-ARFIMA-SVM四种预测模型与提出的EEMDCAN-ARFIMA-PSOSVM组合预测模型进行对比。
从表3和图8~图12观察对比发现,5种模型有很大差异:
图9 单独SVM预测结果Fig.9 SVM prediction results

图10 EEMD-ARMA-SVM预测结果Fig.10 EEMD-ARMA-SVM prediction results
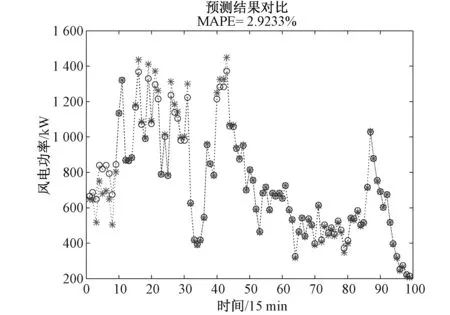
图11 EEMDCAN-ARFIMA-SVM预测结果 Fig.11 EEMDCAN-ARFIMA-SVM prediction results
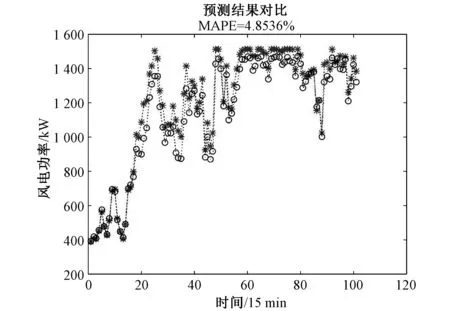
图12 神经网络算法预测结果 Fig.12 Neural network algorithms prediction results
表3 不同模型的误差指标结果对比
Tab.3 Comparison of error indices of different models

预测模型MAPE/(%)ME/MWMSE/(%)SVM20.2940.236 841.422 4EEMD-ARMA-SVM5.0112.359 714.861 2EEMDCAN-ARFIMA-SVM2.926.302 47.334 6神经网络算法4.8511.032 413.323 6EEMDCAN-ARFIMA-PSOSVM2.253.456 94.426 3
(1)基于EEMDCAN-ARFIMA-PSOSVM组合算法建立的预测模型的拟合度、准确度高且相对平稳。性能指标均优于其它预测模型。
(2)组合预测方法与单一的SVM法相比预测精度有较大的提高,这表明经验模态分解方法能有效的对风电功率时间序列进行处理,降低SVM模型对数据的依赖性,预测结果更为可靠性提高。
(3)EEMD-ARMA-SVM模型与EEMDCAN- ARFIMA-SVM模型的预测效果都比较满意,可以看出利用EEMDCAN方法可以更好地找出数据内在特性,当风电功率变化较大时,EEMDCAN对数据进行平稳处理,使得预测结果更为准确。
(4)使用神经网络算法将风向和风速作为模型输入,风电功率作为模型输出,预测精度也能达到要求,但神经网络对参数比较费时。此外,对于同一风场数据,神经网络结构和参数的不同可能产生不同的预测精度[21],提出的组合预测模型具有更好的稳定性。
(5)对比EEMDCAN-ARFIMA-SVM预测模型与EEMDCAN-ARFIMA-PSOSVM预测模型的预测结果,基于改进粒子群算法建立的预测模型拟合精度更高,模型误差指标明显低于其余模型,具有更高的预测精度和更好的预测性能。
6 结 论
EEMDCAN分解法更完整地重构了原始信号,使用ARFIMA模型对线性部分进行预测,利用改进粒子群算法优化SVM模型,避免参数选取的盲目性,实现了对系统的精确预测建模。该组合预测模型通过与其他模型在多种预测精度评判指标下进行对比,均更为准确和稳定,为短期风电功率预测研究提供了一种新的途径。
