基于学术博客综合指数的用户识别方法及其实证研究*
2020-03-09袁润王琦
袁 润 王 琦
(江苏大学科技信息研究所 镇江 212013)
0 引言
学术博客(Academic Blog)是一种非正式的学术交流形式,不仅可以帮助科研工作者推广学术成果,提升自身的学术影响力,还可以拓宽学术社交关系以促进更广泛的科研合作。吕鑫等[1]根据“学术”和“博客”的定义,认为“学术博客”是指用于发布和交流教学科研和科学信息的博客。
在学术社交网络环境下,博客利用平台功能满足其自身需求,尤其是学术需求所表现出的一系列行为统称为“用户行为”[2]。用户行为数据是可以获取的,通过用户行为数据分析,可以研究博客用户的行为特征和规律[3-5],对博客用户进行分类、识别和评价[6-8]。
国内外已有不少学者从不同角度对学术博客开展了较为深入的研究。例如,Lim等[9]将那些创作的内容能够对其他用户带来较大影响的用户定义为博客内容核心用户(Content Power Users,CPUs);Akritidis[10]等认为博文数量和质量是博客用户具有高影响力的两个关键指标;王曰芬等[11]将学术博客核心用户定义为:学术博客环境下,创作的内容对其他用户具有高影响力并因此能够为学术博客的发展带来巨大帮助的用户;Kiriakopoulos[12]利用网页排序策略来发掘重要的博客站点,利用主题的相似性增加隐含边,使博客空间社会网络变得更加稠密,在此基础上利用HITS和PageRank算法来评估用户影响力;张晓阳等[13]运用文献计量理论,基于博文及其点击量构建了学术博客h指数;卢露等[14]利用博客在某一主题下发布博文的数量和质量建立了博客影响力评估模型;周春雷[15]提出了链接内容分析法,建立了衡量一个用户被其他用户加为好友或添加“友情链接”次数的“被好友”指标,以评估用户影响力;郑超等[16]将博文的评论次数纳入博客影响力评估模型;曹冲[17]选取博客用户的发文数量、精选博文数量、好友数量等指标评价用户影响力;王琛[18]基于用户行为数据,利用Delphi法和层次分析法确定指标权重,构建了学术博客影响力评价模型。概括而言,这类研究的共同特点是构建指标体系,运用主题相似性分析、内容分析、用户行为分析、网络分析、计量分析和多指标综合分析等方法对学术博客进行评估或者评价,尚未发现利用评价结果进一步识别用户,尤其是识别网站核心用户的研究。
本文以用户行为数据为指标,采用熵权法计算其指标权重,并定义这些指标的加权值为博客综合指数,按照博客综合指数的值从大到小倒序排列,在人为给定阈值的基础上可以识别核心用户,并以具有代表性的中文类学术社交网络平台(科学网博客)进行了实证研究,结果表明该方法简单、有效且可靠。
1 用户行为数据指标体系
博客行为数据能直接反应博客与博文之间的关系。博客既可以发布、转载、分享博文到网络上,也可以阅读、推荐和评论自己感兴趣的博文,博客的诸如发布、阅读、搜索、发帖、回帖、推荐、评论、留言、求助、访问主页、添加好友等行为,都被网络平台记录下来形成用户行为数据。平台利用这些行为数据对用户行为和内容进行管理,例如审核、精选和推送,为用户提供开放的、公正的、互动的网络社交环境。为开展本文的研究工作,笔者从科学网博客获取了表1所示的用户行为数据。

表1 科学网博客用户行为数据项
按照行为特征,可以将用户行为分为主动行为和被动行为两大类,如图1。在此基础上,本文从主动行为与被动行为两个方面构建用户行为数据指标体系,指标体系涵盖16个数值型指标项。a1~a11为主动行为指标,可量化用户主动使用平台的活跃程度;a12~a16为被动行为数据指标,可量化评价用户的受关注度、影响力等。其中,a1属于用户基本属性特征,包含用户学历和职称两项属性数据,需转化成数值变量;a2、a10和a11为时间变量,a2指标用于描述用户资历;a10用于描述用户时隔多久依在使用博客;a11用于描述用户时隔多久依为平台贡献内容,指标a2、a10与a11同样需要转化成数值变量(天数)。需要说明的是,由于科学网博客功能设置原因,部分行为数据,例如留言、评论内容等不易获取,且设置了隐私保护的用户数据无法获取,上述指标且均为正向指标。
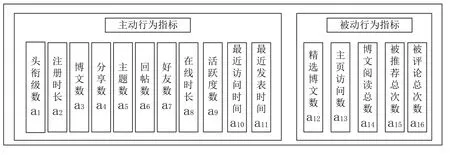
图1 学术博客行为数据指标体系
2 博客综合指数
本文提出的用户识别模型的基本思路是按照用户行为数据构建若干指标,再根据这些指标的信息熵计算其权重,并定义其加权值为“博客综合指数”(Blog Composite Index,简称BCSI),最后根据计算的BCSI值将用户信息序列倒序排列,将排在前r位的用户定义为核心用户[19-20]。
一般地,用户信息序列U当中有n条记录和m项指标,则定义:
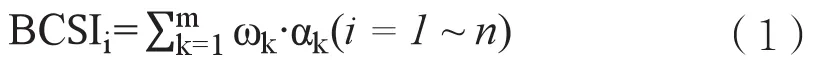
为博客综合指数,其中αk表示第k项指标的归一化值,ωk为其权重系数。将BCSI倒序排列之后,按照公式(2)可以计算得到核心用户序列的阈值r。

其中 ,τ=0.618,t=1,2,3,i=1~n。由 t=1 得到的用户集称为一区核心用户,t=2得到的用户集称为二区核心用户,t=3时得到的用户集称为三区核心用户。
考虑到每项指标值域范围相差很大,所以需要对其作归一化处理:

熵权法计算指标权重系数的方法如公式(4):

其中,为第k项指标的信息熵,计算方法如公式(5)。
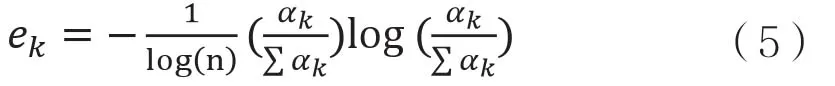
3 实证研究
本文应用R语言编程技术开展了实证研究。第一步获取数据,生成“博客”和“博文”两个数据集(BlogUsers, BlogContents);第二步统计计算各项指标并做归一化处理;第三步计算各个指标的信息熵及其权重系数并按学科分类开展对比研究;第四步计算博客综合指数(BCSI)并排序;第五步计算核心用户序列阈值。
3.1 数据的采集与处理
在注重用户隐私保护的前提下,本文通过Python语言编写程序采集学术博客用户行为数据。采集对象选择那些拥有精选博文的用户,采集时间为2018年12月12日,共采集到3 799条不重复用户url。在采集博文数据之前,对原始url数据进行简单的人工处理,剔除146条因设置隐私权限等因素造成数据缺失的url,博文数据项获取时间为2018年12月19日。
爬取数据过程中构建了BlogUsers和BlogContents两个原始数据集。采集完成后对采集到的数据进行必要的处理:BlogUsers中与博文有关的数据以BlogContents实际获取数据为准,集中统计阅读总数、被推荐总数和被评论总数等数据项;博文数据中极端异常或大量数据缺失的用户予以剔除,最终得到2 339位有效用户数据和401 472条博文数据。采集到的40万条博文记录当中,有效评论次数累计达到127万次,有效推荐次数累计达到107万次,总阅读次数超过14.29亿次,可见科学网博客具有较大的影响力,对学术交流和传播具有一定意义。
用户基本属性和时间变量需作数值化处理。①用户基本属性(头衔数据)需转化成数值型数据,未标注学历或者职称为最低等级,“院士”“教授” “研究员” “编审”为最高等级,其他用户依据实际标注情况作等级量化处理;②时间变量转化成数值型变量,指标a2按注册时长转换成对应天数,指标a10和a11以最近登录/发表时间与注册时间的间隔将该指标转换成对应天数。
3.2 计算权重系数
根据公式(3)(4)(5)计算得到的各项指标的信息熵和权重系数如表2所示。

表2 各指标的信息熵及其权重系数
主动行为指标中,a5、a4、a6和a3是反映用户生成内容活跃程度的指标,权重系数排序靠前。科学网博客属于内容生成型平台,作为管理方的科学网一直鼓励用户生成各类内容,上述指标权重系数最大意味着此类指标可以更好地将持续生成内容的活跃用户识别出来。有关时间维度(a2、a10和a11)权重最小,且权重系数整体小于0.01,对评价结果贡献最低。被动行为指标中,a12、a16、a15和a14作为量化用户博文影响力的重要指标,权重系数较大,排序靠前,对评价结果的贡献较大。博文是学术博客的核心内容,对学术博客的评估本质上是对博客内容的评估,上述指标增加了评估指标体系的合理性。
为了开展分组比较研究,本文按研究领域分别计算了各项指标的权重系数,结果如表3所示。科学网博客汇集了多个学科领域的大量科研人员,不同学科属性用户的行为偏好是否存在差异,为讨论这些差异的影响,本文在计算全部用户指标权重系数的基础上,按照科学网博客平台给定的化学科学、工程材料、地球科学、生命科学、管理综合、数理科学、医学科学和信息科学等8个研究领域分别计算了各个领域的各项指标的权重系数,91个无分类用户暂不考虑,结果如表3所示。
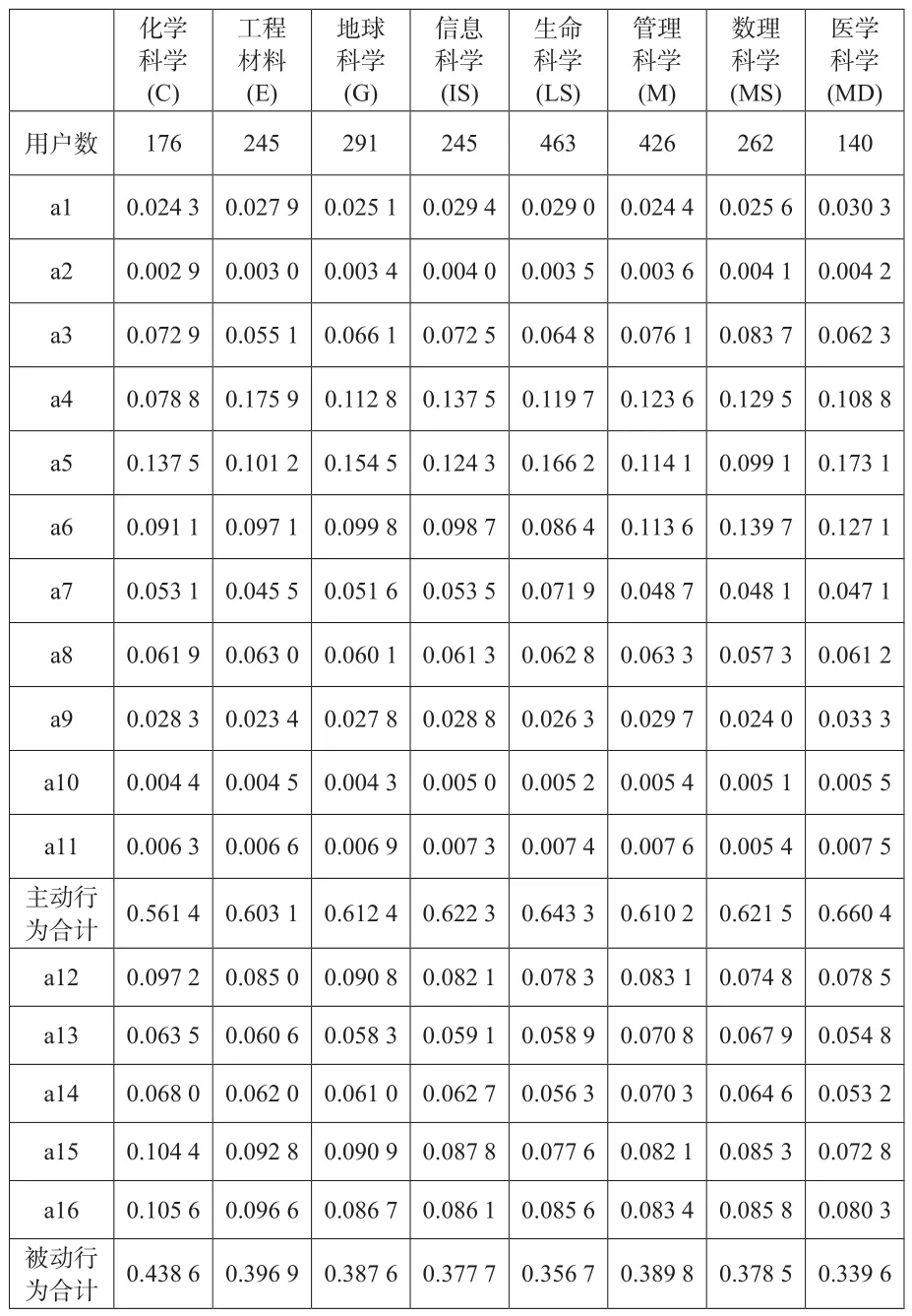
表3 不同研究领域的权重系数
依据信息熵理论,数据离散性越大则权重越大,某一学科领域内,指标权重系数越大,用户行为数据差异越大,该现象可归结为某学科用户整体行为偏好特征。在不同研究领域中,同一指标不同研究领域权重系数不同,则不同研究领域用户的该项行为偏好特征存在差异。从表2和表3发现,全部用户指标权重系数与各个学科权重系数总体趋势一致,但各个学科指标实际权重值存在明显差异。对比各研究领域指标权重系数TOP3,除了化学科学(a5〉a16〉a15),其他学科指标区分度TOP3均为a4、a5和a6(主动指标)。各研究领域指标权重系数TOP3的综合占比均超过30%,最高达到40.9%。主动行为指标是量化用户主动使用平台的积极性指标,a4、a5和a6项权重系数最大,说明大部分学科用户这三项指标对应的行为表现存在较大差异。统计主动行为所有指标的权重系数和,发现除化学科学(0.57)以外,其他学科主动行为指标项的权重系数和均超过了0.6,医学学科主动行为权重系数之和最大与化学学科相差0.099。该结果表明,医学学科用户主动行为的偏好特征与其他学科(尤其是化学学科)用户主动行为的偏好特征存在显著的差异,其他学科相比,医学学科用户的主动行为数据更具离散性。
3.3 计算博客综合指数
运用R语言data.table()包可以方便地实现各项计算。为了验证用户识别模型,本文将TOPSIS方法计算结果整合在同一表中,按BCSI值从大到小排序,结果如表4所示,其中BP为博客相对接近度(Blog Proximity,简称BP)。

表4 博客综合指数TOP30及其排序
为了进一步观察BCSI值总体分布特征,本文绘制如图2的小提琴图,该图将箱线图与核密度图整合在一起,展示分位数位置的同时也可以展示任意位置的密度,可以较为直观地呈现BCSI取值分布情况。结合表4和图2可以看出,BCSI值存在明显的区分度,可以有效区分用户。BCSI的值域为[0,1],但最大值小于0.5,只有6位用户BCSI取值在[0.3,0.5]之间,89.14%用户的BCSI值分布在[0, 0.0500 1]之间,BCSI存在整体取值水平较低的情况。

图2 BCSI取值分布
经过分析,上述现象的出现可主要归结为以下三个原因:①依据熵权法的特征,如果权重系数较大的指标(如主题、分享和回帖等指标),用户行为数据整体表现不佳可能会造成取值水平偏低。②作为非正式学术社交平台,学术博客用户行为具有较强的随意性和不确定性。受到用户偏好和平台功能设置的影响,少部分用户单项指标缺失或表现突出,会造成BCSI整体取值水平偏低的情况。③平台上只有少部分用户主动行为和被动行为指标均表现较好,该类用户是我们希望识别出来的核心用户群体,这也意味着大部分用户主动或被动行为表现一般。上述结果表明,虽然BCSI总体取值水平偏低,但仍有少部分用户取值相对较大,因此BCSI可以用来识别博客用户。
3.4 计算核心用户序列阈值
核心用户序列阈值r利用R语言编写代码计算,结果是:t=1,r=329; t=2,r=63; t=3,r=15。表示一区核心用户329位,二区核心用户63位,三区核心用户15位。一区核心用户中:化学科学23位、工程材料34位、地球科学40位、信息科学32位、生命科学57位、管理综合67位、医学科学20位、数理科学50位、无学科分类6位,其中地球学科入选核心用户占本学科总人数比例最高为22.35%,无学科分类用户比例最低为2.97%,入选核心用户的比例与该学科人数无关,但未设置学科分类的用户很少能贡献较高的BCSI值。阈值的确定可以依据网站实际需求调整,BCSI曲线如图3所示。

图3 核心用户分布图
3.5 用户分组识别
为了进一步分析不同学科领域用户主动行为偏好的特征差异对BCSI值和用户识别结果的影响,本文依据各学科的指标权重系数分别计算了各学科的BCSI值,并识别各自领域的核心用户。各研究领域计算结果如表5所示,按BCSI值从大到小排序。为了进一步观察BCSI值总体分布特征,绘制各研究领域BCSI值的小提琴图,如图4所示。

图4 各学科BCSI分布图
从BCSI值的分布情况看,各学科BCSI值域分布显著变化,整体取值水平较分类前有所提升,核心用户与非核心用户间的区分度更加明显。平台上只有少部分用户主动行为和被动行为指标均表现较好,积累出高BCSI值,但大部分用户的取值范围仍在[0,0.05001]之间。这一现象表明分学科评估与识别用户能够取得更好的效果,但整体取值水平仍然偏低。识别出的一区核心用户248位,二区核心用户54位,三区核心用户为19位,识别结果较分组前有明显变化。分组识别后入选本领域核心用户的人数明显减少,各个学科识别出的一区核心用户情况:化学科学16位、工程材料27位、地球科学36位、信息科学27位、生命科学54位、管理综合40位、医学科学18位、数理科学30位。地球科学入选核心用户的比例最高,达20.11%,化学科学入选比例最低为9.09%。由此可见,各研究领域用户主动行为偏好的特征差异对BCSI的取值范围和用户识别的结果均产生了显著的影响。

表5 不同研究领域TOP5博客综合指数及其排序
4 讨论
对评估和识别结果的合理性和可靠性验证一直是相关研究的难题之一。本文应用TOPSIS方法对博客核心用户识别模型作了验证,结果参见表4。两种方法的排序结果显示,Rank(BP)与Rank(BCSI)呈高度正相关关系(r=0.891 7),其中一区重合度为76.9%,二区核心用户重合度为84.13%,三区核心用户重合度达到86.7%,具有较为一致的重合度。表明博客综合指数能够反映博客用户行为特征,可以据此识别核心用户。此处重合度只考虑用户所属区间,不考虑排名顺序,即不同评价结果中,同一用户同属于一个核心区域则重合,重合度越高,表明两种方法识别核心用户效果越接近。
为了进一步验证评价结果的合理性,还需证明被识别出的核心用户(或创作内容)曾经得到博客平台其他用户的广泛认可。科学网博客热门博文是由读者推荐产生,受到了其他用户的广泛认可,热门博文可以在科学网博客首页获得。全部热门博文共4 502条,涉及585位用户。本文以识别出的核心用户是否有博文是热门博文为标准进一步验证结果的合理性。对比发现,上述识别的一区核心用户中有63.83%的核心用户拥有1篇以上的热门博文;二区核心用户中87.3%以上的核心用户拥热门博文,其中35人至少拥有10篇以上的热门博文;三区核心用户中93.3%的用户拥有共计894篇的热门博文,有8位用户拥有84篇以上的热门博文。对比结果表明,依靠BCSI识别出的核心用户,大部分曾经得到博客平台其他用户的广泛认可。
进一步分析三区核心用户发现,他们中的大部分人接受过硕士及以上的高等教育,目前在大学任教。以图情领域为例,武夷山、赵美娣等用户更是所在领域的知名学者。他们在科学网博客长期活跃,贡献了许多高质量的博文,借助平台与其他用户建立好友关系,有的还进一步建立了科研合作关系,发表了多篇高质量的学术论文。部分用户发表的博文更是被其他学者引用到正式的文献交流中,获得了广泛认可。笔者利用知网的引文检索功能,检索被引文献来源为“sciencenet”的文献,发现武夷山、黄安年和陈儒军等人有多篇博文被引。值得注明的是,部分学界知名学者(如施一公,排名267位,为一区核心用户)并未进入三区核心,出现这样的结果并不影响评估和识别的合理性与可靠性。学术博客核心用户是平台的活跃用户,是在一定时期内通过创作内容对其他用户具有高影响力且获得了广泛的认可的用户。通过观察施一公博客主页,该博客自2016年12月10日便停止更新内容,这一点已经“有悖”核心用户定义,但是其在使用博客期间贡献了29篇高影响力博文,至今仍吸引着大量用户的阅读、推荐和分享。所以即使停止更新博客两年,其博客仍然具有较高的影响力。综上所述,基于BCSI的核心用户识别的合理性、可靠性得到有效验证。
5 结论
研究表明,基于学术博客行为数据构建的指标体系能够准确地表征博客的主要特征,其加权值定义的博客综合指数具有较好的区分度,据此可以识别出学术博客平台上的核心用户。博客综合指数概念的理论基础是多指标序列的排序理论。本文运用熵权法计算得到的BCSI序列与理想评价法得到的结果对比,发现两者具有很好的重合度。实证研究表明,科学网博客BCSI值总体上偏小,反映了学术博客行为差异性较大,规范性不好。分组研究表明,不同学科用户行为具有不同的偏好特征。由于本文选取的学术博客行为数据构建的指标体系都是正向性指标,所以依据BCSI值的大小也可以间接地作为学术博客影响力的评价指标。
本文尚存在以下局限。第一,本文只考虑了学术博客中具有精选博文这一特征的少数用户的使用行为,还有大量用户没有精选博文,他们的使用行为未被考虑在内。第二,对权重的赋值只选取了客观赋值法,缺乏与主观赋值法的比较分析。第三,具有不同特征的用户行为可能存在较大的差异,本文仅探讨了不同研究领域的用户行为具有不同的偏好特征,还需从更多视角对用户进行分组研究来证实。以科学网博客为例,除了可以按学科领域对用户分组,还可以按照性别、工作类型、职称、学历、博文系统分类等条件对用户进行分类研究。
