融合社交网络与流行度特征的POI推荐模型
2020-03-08吴清寿余文森
郭 磊,吴清寿,余文森
(1.武夷学院 数学与计算机学院,福建 武夷山 354300;2.福建省认知计算与智能信息处理重点实验室,福建 武夷山 354300)
随着手机等智能终端设备的广泛使用,基于位置的社交网络(location-based social network,LSBN)得到了广泛的使用,如Foursquare、大众点评、Geolife、Gowalla等。目前,有大量学者对基于LSBN的POI推荐方法展开研究,但由于LBSN中签到矩阵非常稀疏,用户签到行为受地理、时间、社交因素等多种因素影响,使得如何综合这些因素提高用户推荐质量是一个研究重点。
目前基于社交网络的推荐方法研究较成熟,许多模型通过结合社交网络提高推荐准确率,如Ye等[1]使用幂律分布刻画POI距离,综合考虑POI位置关系与用户社交关系进行协同过滤。Cheng等[2]采用一个多中心的高斯模型反映地理位置信息的影响,并融合社交网络信息进行推荐;Lian等[3]提出GeoMF模型,将地理信息融合到加权矩阵分解中,通过给为零和非零签到数据赋予不同权重来提高推荐效果;Yang等[4]使用半监督学习方法建模地理信息与社交网络信息,使用协同过滤技术学习用户偏好,最后用神经网络嵌入将二者结合,提出了PACE模型;Li等[5]通过定义三类朋友关系,挖掘三类朋友关系的POI信息,采用矩阵分解方法对模型进行优化;彭宏伟等[6]提出了一种基于矩阵分解的上下文感知POI模型,同时考虑位置信息、社交网络信息等进行模型构建,有效缓解的数据稀疏性。除了地理信息与社交网络信息外,还有许多上下文信息被利用进行POI推荐研究。部分研究认为时间信息对POI推荐具有重要作用,建模了时间对POI推荐的影响[7-11];一些研究考虑文本信息对POI推荐的影响[12-13];许多研究把POI分类作为提高推荐效果的一个因素进行研究[14-15]。以上大部分研究均是结合个别关键信息进行POI推荐,或者对多种信息通过简单的协同过滤进行组合,无法较全面的反映用户的签到行为并进行个性化推荐。
为解决以上问题,本文提出了综合位置信息和社交网络的动态异质网络协同过滤推荐算法DHRA(collaborative filtering recommendation algorithm Based on dynamic heterogeneous network),该算法有效融合用户社交关系和用户位置关系,并在社交关系中考虑包含用户好友信息与区域活跃用户双重因素的用户社交网络,有效的缓解了签到数据稀疏性的问题,同时融合分类流行度特征,能够有效的刻画用户行为与自身偏好,提高了推荐准确性,并具有良好的延展性;模型在Foursqure(NYC)数据集和Gowalla数据集上进行充分实验表明,该算法在准确率与召回率上均优于其他算法,推荐效果更优。
1 个性化推荐算法
1.1 问题描述
在LBSN中,POI推荐是通过对用户历史数据和上下文相关信息的分析,给用户推介1个未访问过的兴趣点,为讨论方便,在表1中列出本文使用的基本符号。
1.2 地理位置信息对兴趣点推荐的影响
在实际生活中,用户行为与地理位置相关,有数据显示,用户签到行为经常发生在较小的范围,即空间聚类现象[14]。根据地理学第一定律:任何事物都有相关,越近的事物关联越紧密,用户也偏向访问距离较近的POI,研究表明,地理位置信息能够有效提高POI推荐的准确率。
本文使用Triangular核函数计算POI间的相似度,以此计算地理位置信息对用户签到行为的影响。目前的相似度计算方法很多,如Cosine,Jaccard和皮尔逊相似度等,但Triangular核函数具有无参估计,能够将相关度较低的POI过滤掉等优点。本文用sim(i,j)表示任意两个POI间的相似度。

其中:d(i,j)是根据经纬度信息计算POI间的距离。a是核函数的宽度参数,I是指示函数,当POI间距离大于a时,函数值为0,否则,距离越近,函数值越大。由此本文定义了用户对POI的偏好矩阵M:

其中,gu表示用户u访问过的POI的集合,rui是用户u访问POIj的次数。
1.3 社交网络信息对兴趣点推荐的影响
在现实生活中,用户的行为会受到好友的影响,一般认为,好友签到过的POI用户极有可能有兴趣,同时,用户还会参考区域活跃用户的意见,如果把区域活跃用户的意见推荐给用户,也会提高推荐准确度。
1.3.1 好友关系推荐方法
本文采用基于用户的协同过滤算法来反映好友关系对用户行为的影响,具体公式为:

其中,puj表示用户u到POIj点的偏好值,Fu是用户u的好友集,SIu,m表示用户间的相似度,本文使用Cosine相似度计算,具体公式为:

式中,tmj是签到纪录,如果用户m有到j点签到,则值为1,否则为0。
1.3.2 区域活跃用户推荐方法
区域活跃用户认为是一种专家用户,可以帮助普通用户更准确的推荐。本文计算特定区域内的活跃用户,然后计算用户与活跃用户间的相似度,根据活跃用户签到情况,对用户进行推荐。
根据用户当前位置为中心,以d为半径,统计区域内全部POI的集合,记为LR。计算圆内每个用户在区域内签到次数的总和,计算公式为:

选区域内top-N的用户,即活跃用户,定义活跃用户集uau。
在位置推荐的过程中,若POI用户签到数少或者无数据,将活跃用户签到最多的位置推荐给用户,若有签到数据,则选区活跃用户中与当前用户相似度最高的TOP-N用户的签到点进行推荐,用户相似度计算可用公式(3)完成,推荐方法的计算公式为:
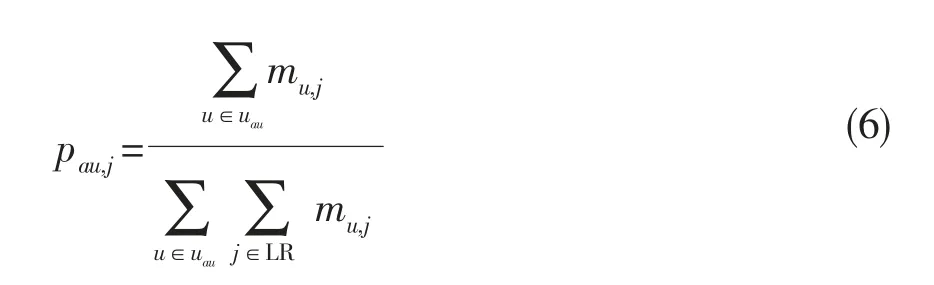
其中mu,j表示用户u在位置j的签到记录。
综合2种社交因素得到的推荐方法为:

其中:a∈[0,1]是权重因子。
1.4 分类流行度对兴趣点推荐的影响
LBSN将POI进行分类,如Foursquare中将所有POI分为8大类,对用户签到POI类别的分析有利于分析用户偏好,提高推荐准确度。
用户对POI类别的偏好程度可以通过不同类别的签到情况的到反应,首先统计每个类别每个用户的签到数量,记为Tu,c。本文采用式(8)计算用户每个用户对各个类别的偏好向量cot(u,c)。
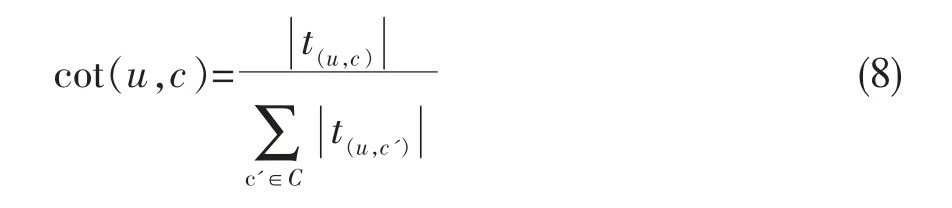
通过式(8)可以得到每个用户对各类别的偏好分量,记为cot(u)=〈cot(u,c1),cot(u,c2),L cot(u,cn)〉。
如果仅分析用户偏好类别,对每个类别内的POI视为同等重要,对用户而言明显是不合理的,为了对各POI进行比较,本文引入流行度的概念。流行度即POI受欢迎程度,一般认为,同类POI中,流行度高的应该优先推荐。通过用户对POI的总签到数t(lj)和总访客数ν(lj)可以对流行度进行直观体现。考虑到各POI间签到数与访客数差距较大,本文采用调和平均数进行流行度计算,具体公式如下:
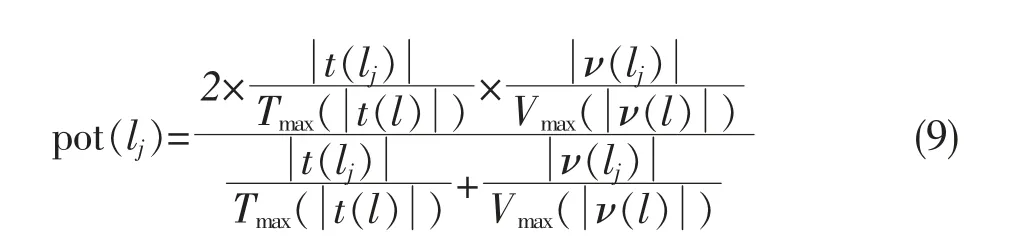
综合以上两种方法可得到同时考虑分类与流行度因素的推荐计算方法:

1.5 DHAR算法
由于时间,空间和社交关系的利用能够在一定程度上提升推荐性能与冷启动问题,目前大量流行的算法主要考虑以上三个因素,本文在此基础上,将分类流行度作为参考因素,并在社交关系中增加活跃用户的影响,提出了融合社交网络与流行度特征的POI推荐算法DHAR(POI recommendation algorithm combined with social networking and popularity features)。在融合前,使用Min-Max标准化方法对三个算法进行标准化处理:

最终推荐计算公式为:

2 实验结果与分析
2.1 数据集及对比算法
本文实验使用真实数据集Foursqure(NYC)数据集和Gowalla数据集来验证所提方法的效果,这两个数据集均为LBSN的经典数据集,包含用户访问位置、时间等各类信息。实验前对数据集进行过滤,移除一些异常数据。对Foursqure(NYC)数据集筛选出多于5条评论数的用户及其社交关系,签到多于2人的地理位置。在Gowalla数据集筛选出签到次数超过40的用户数及其社交关系,签到数超过40的地理位置。预处理完的数据集基本情况如表2所示。由表中可以看出两个数据集用户签到密度都极低,但用户社交平均数约为9.80和15.88,说明用户间社交关系较密切。实验比较算法如表3所示。
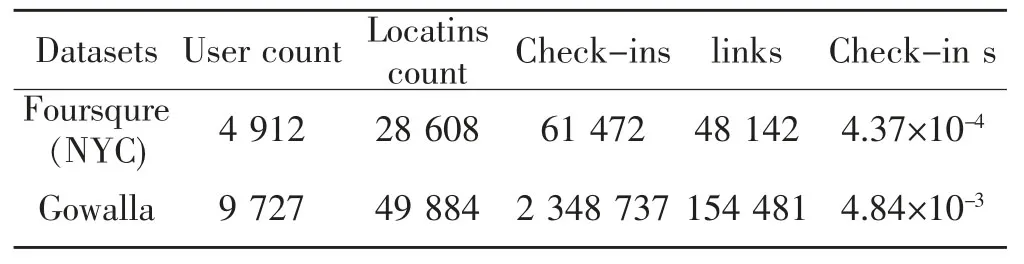
表2 预处理完的数据集基本情况Tab.2 Basic case of pre-processed datasets

表3 实验比较的算法Tab.3 Algorithms for experimental comparison
2.2 评价指标
实验采用5-折交叉验证法,将以上2种数据集随机分为20次,每次使用其中80%为训练集,剩下20%为测试集,将20次评价结果取平均值做为最终评价数据。
实验度量选取了在推荐算法中最为广泛的评价指标:准确率(precision@N)和召回率(recall@N),公式分别如式(13)和(14)所示,其中,准确率反映推荐的N个POI中用户实际访问的比例,召回率反映推荐的N个POI中,用户访问过的POI占用户所有访问POI的比例。

2.3 实验结果与分析
2.3.1 参数选取的影响
本文算法的推荐效果受到地理位置,社交网络信息和流行度等因素影响,在一定程度上调节社交关系和分类流行度对推荐结果的影响。实验验证了β和δ的值分别为[0.001,0.01,0.1,0.3,0.5,1,5,10]时的实验结果,图1和图2为Top-K为10时的β和δ的值的对算法性能的影响。
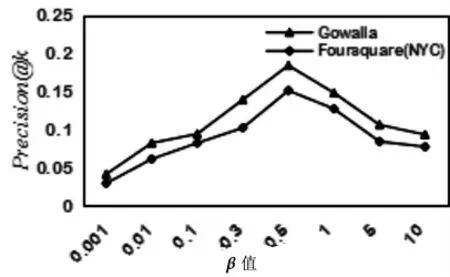
图1 不同β值对推荐精确率的影响Fig.1 Effect of differentβvalues on recommended accuracy

图2 不同δ的值对推荐精准率的影响Fig.2 Effect of differentδvalues on the recommended accuracy
从图中可以看出参数β和δ的值对Precision和Recall的影响都呈现相同的变化趋势,并且分别在0.5和0.3时获得最佳效果,说明了位置、社交网络和流行度均可直接影响到POI的推荐效果。
2.3.2 算法性能比较
本实验使用TOP-N策略,n的取值分别为5、10、20、30,本实验中取值为0.5,取值为0.3,实验结果如图1所示。


图3 各算法准确率对比Fig.3 Accuracy comparison of algorithms
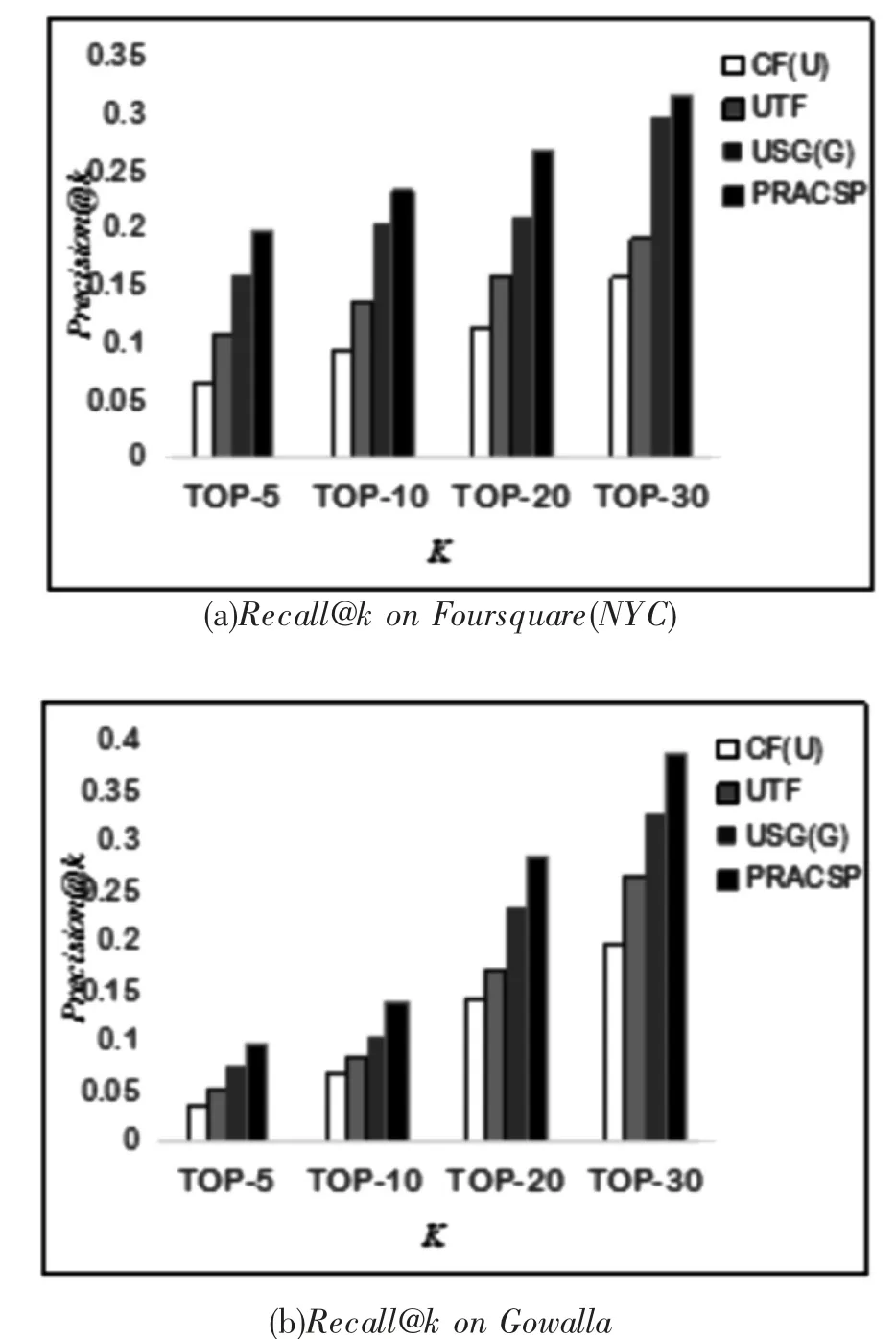
图4 各算法召回率对比Fig.4 Comparison of recall rates among algorithms
由图3,图4分析可知,CF(u)算法是基础的协同过滤算法,没有考虑其它维度,如时间、位置等信息,因此在精准率和召回率上都比较低,效果最差。算法UTF在推荐过程中融入时间信息,在准确率上提高了35%~50%,此结果表明,对维度信息融合能够较显著提高算法的准确率和召回率,但由于只考虑单一维度,效果提升有限;USG(G)将位置因素加入其中,综合参考两个维度因素,使得推荐效果得到显著提升,说明位置因素对POI推荐效果明显;本文提出的算法DHAR在融合位置信息网络和社交信息网络的同时,还融入分类流行度因素,在精确率和召回率上提高了22%~50%,提升效果显著。
3 结束语
本文提出了一种融合地理位置因素、社交因素与项目流行度的POI推荐模型DHAR,该模型根据用户位置计算用户对POI的偏好值,在社交关系中综合考虑了好友关系和区域活跃用户的影响,同时还参考了兴趣点的分类流行度因素,有效缓解了签到数据稀疏性的问题,提高推荐结果的质量。通过在Foursquare数据集上进行的实验对比,DHAR在精确率与召回率上均优于当前流行算法。后期笔者将进一步提升算法效率,同时将算法由本地推荐扩展到异地推荐。
