基于四叉树和R+树复合索引时空数据查询研究∗
2020-03-06赵燚钱育蓉杨兴耀汪丽娟
赵燚,钱育蓉 ,杨兴耀,汪丽娟
(1.新疆大学信息科学与工程学院,新疆乌鲁木齐830046;2.新疆大学软件学院,新疆乌鲁木齐830008)
0 引言
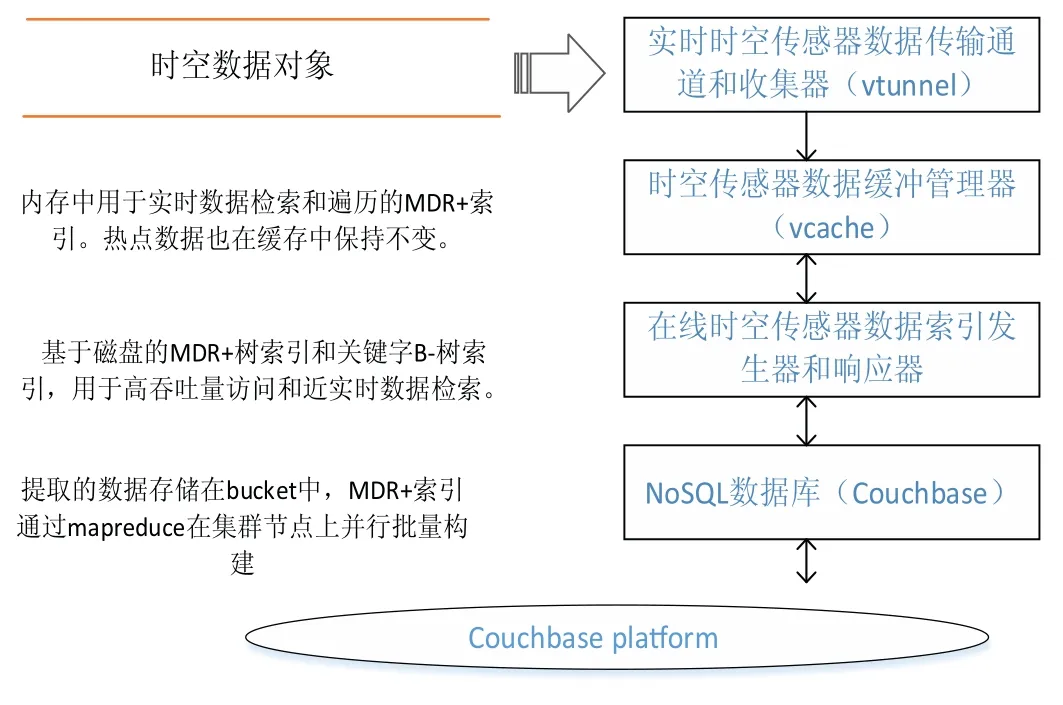
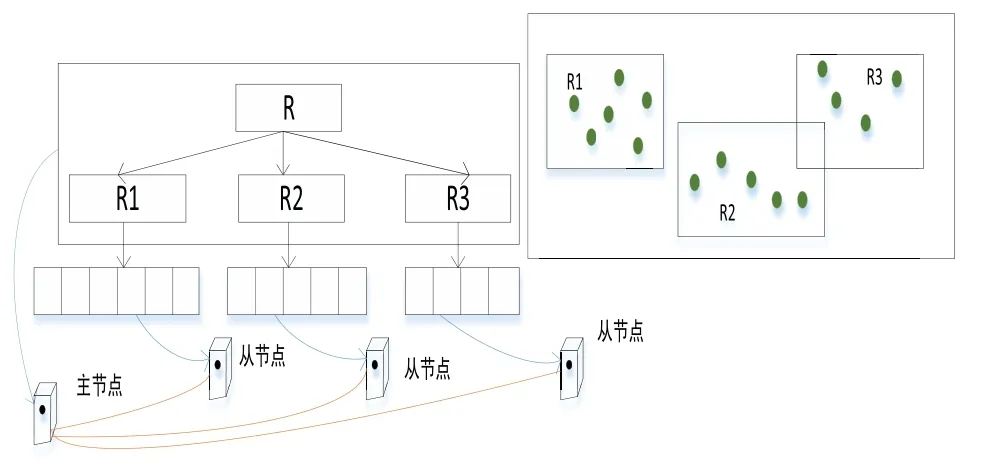
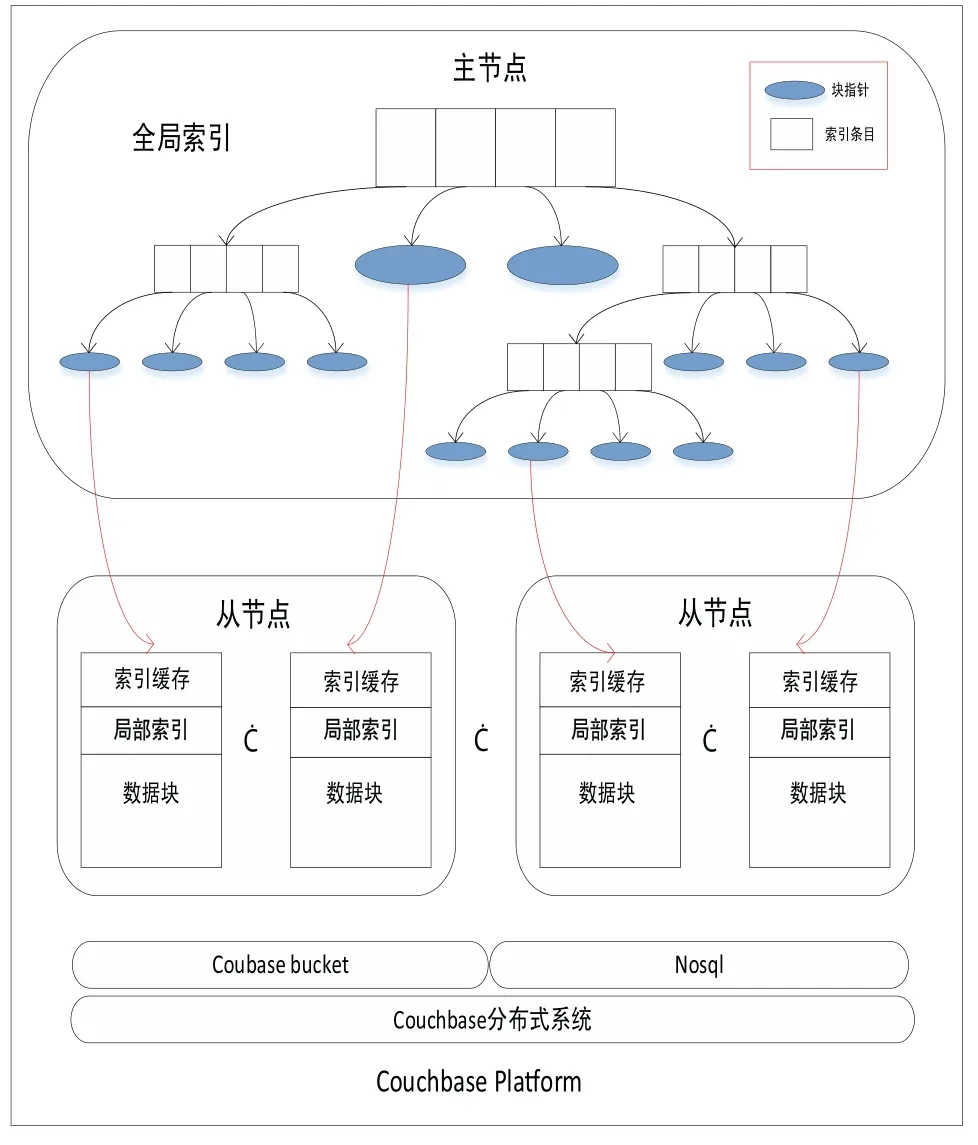
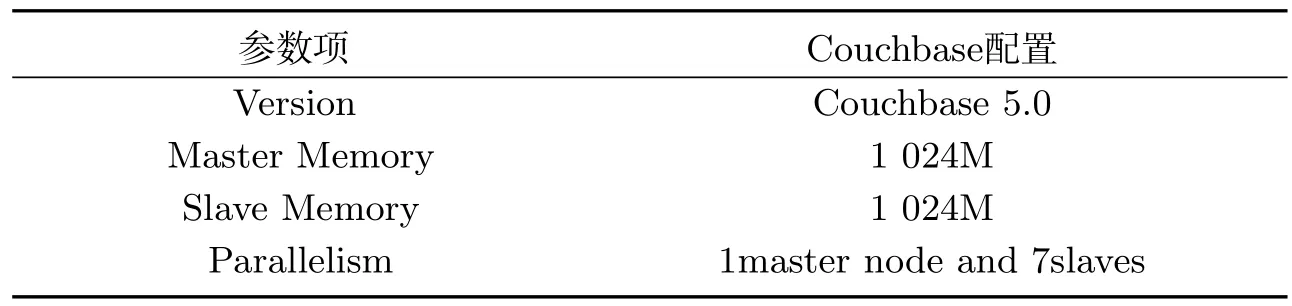
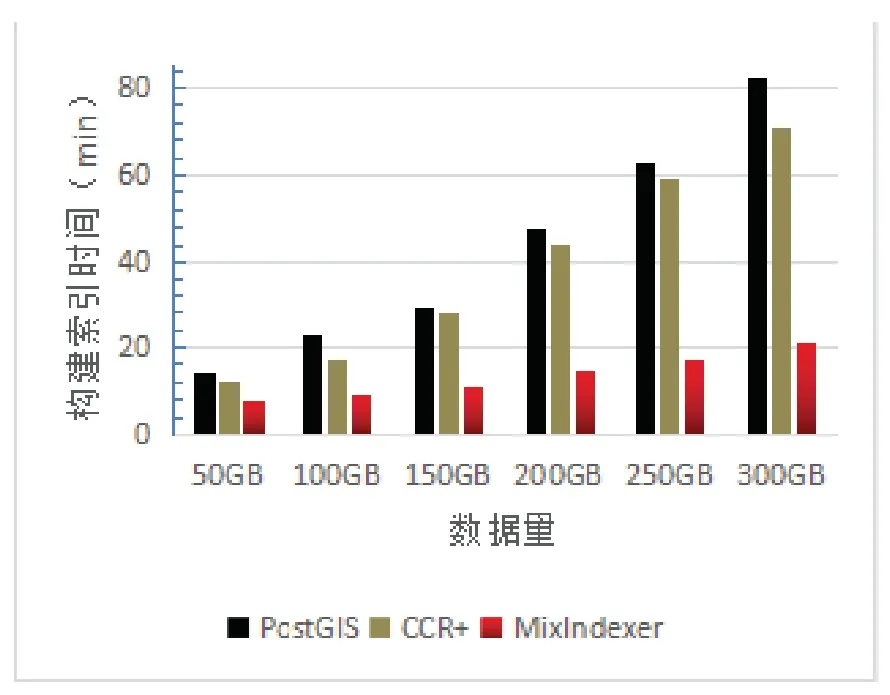
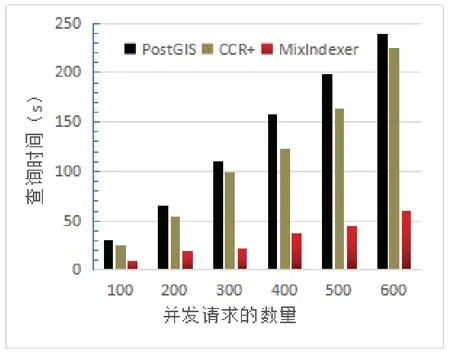
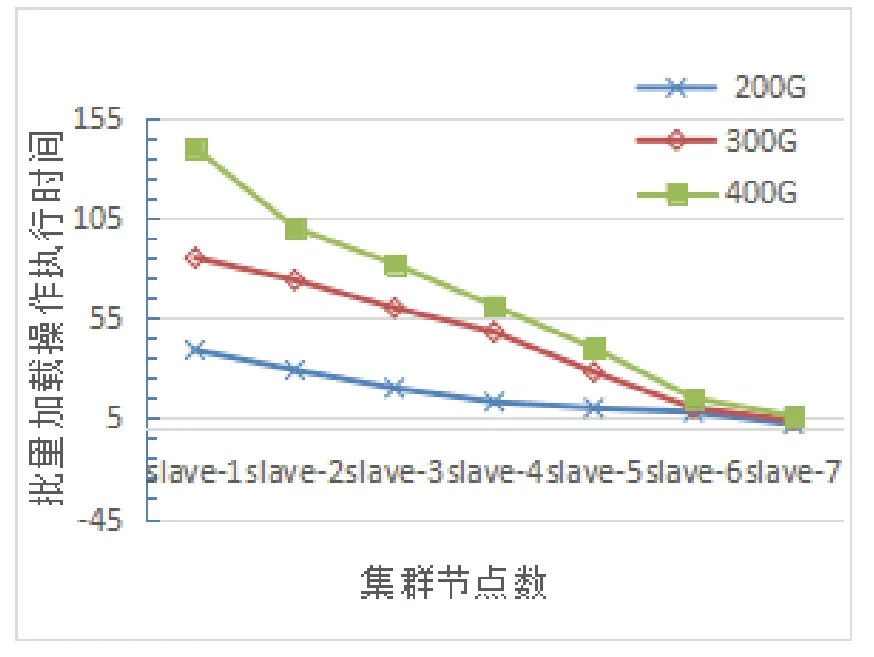
近年来,随着遥感、全球定位等技术的进步和WebGIS、物联网等数据密集型地理空间应用的普及[1],产生了大量的时空传感器数据[2].获取的时空数据对于在各种应用场景中进行智能分析和决策支持具有重要意义,例如手机通话、手机连接WIFI热点、公交卡、银行卡等智能卡刷卡、用户签到等事件.典型的时空传感数据是高维的,包含空间范围、时间序列和多个其他属性[3].更具体地说,具有时空特征的传感数据可以表示为具有时空信息和属性的记录结构,即 时空数据的索引方法是加速数据检索和提高查询效率的重要问题之一[4].目前常见的索引方法有基于单节点空间数据库管理系统(SDBMS)的[5],它们在处理小数据集时表现良好.然而,在面对大量时空传感器数据的查询时提出了巨大的挑战.首先,底层SDBMS的可扩展性差、事务语义严格,效率低下;其次,大部分都是为集中计算环境而不是分布式集群而设计的[6],检索和查询操作是串行执行的;最后,它们有限的存储和计算能力无法支持来自许多并发用户的密集访问和查询请求,在索引时空数据时也缺少对时间维的详细描述. 基于上述不足,本文提出了一种分布式复合时空索引方案MixIndexer,可以有效地处理传感器时空数据的查询.为提高检索和查询效率提供了解决方案,该方案利用了新兴的空间云计算范式[7].MixIndexer的设计主要思想如下:首先,提出了一种基于云平台的时空数据分布式索引体系结构,该体系结构由全局索引和局部索引组成.全局索引用于确定数据块位置,而局部索引用于在块中查找要素对象;其次,本文应用了分布式增强R+(MDR+)树算法以提高时空数据检索和查询效率.MDR+树索引可以提高随机访问效率,支持多种查询类型,包括空间选择、时间查询和属性查询,在实际的地理空间应用中,MDR+树索引驻留在分布式内存缓存中,避免了磁盘I/O延迟,保证了对并发数据的实时响应.最后,设计了一种基于MapReduce的大时空传感器数据批量构造指标并行处理方法.此外,本文在NoSQL数据库Couchbase上实现MixIndexer 混合索引.经实验,第一方面MixIndexer复合索引方案在构建索引效率方面优于SDBMS(即PostGIS和CCR+树)大约4倍;第二方面在并发数请求加大的情况下MixIndexer复合索引的查询时间明显缩短;第三方面在集群节点数由4个增加到8个时,MixIndexer在平均加速方面效率提高68.5%∼116.3%. MixIndexer是一个集群化的、基于文档的数据库系统,其使用一个缓存层来提供非常快的数据访问,将大部分数据都存储在RAM 中,可以弥合地理空间应用程序和云平台之间的差距.该结构使用多个节点和一个自动分散在整个集群上的缓存层.实现了一种弹性,可扩大和紧缩集群,以便利用更多RAM 或磁盘I/O 来帮助提升性能. MixIndexer可以弥合地理空间应用程序和云平台之间的距离.如上所述,由于Couchbase是主从架构,本文索引方案包括全局索引和局部索引.全局索引用于查找数据块,传感器数据对象通过遍历局部索引树来确定. 为了满足地理空间应用的密集访问和检索需求,本文设计了多层次的MixIndexer结构.图1显示了MixIndexer体系结构.底层是Couchbase平台,其部署在由服务器组成的横向扩展集群上.Couchbase由两个关键组件组成:Couchbase 分布式文件系统[8]和MapReduce[9],两者都是主从体系结构, 即一个主节点控制多个从节点.Couchbase 依赖于本地文件系统(如Json),Couchbase 块文件存储在本地磁盘上.MapReduce 部署进程在与Couchbase相同的物理集群上,主节点被分配为协调器(jobtracker),其他节点被分配为工作节点(tasktracker).NoSQL数据库在很大程度上依赖于底层Couchbase平台的存储和计算能力. 图1 Mix indexer层次结构Fig 1 Mix indexer hierarchy 本文选择Couchbase作为具有代表性的NoSQL数据库,因为它安装便捷并具有良好的可扩展性和高可用性.Couchbase的基本形式是一个基本文档和基于键/值的存储[10].只有在知道文档ID 时,才能检索集群提供的信息.在Couchbase 中,将文档存储为JSON 格式,然后使用视图系统在存储的JSON 文档上创建一个视图.视图是在存储在数据库中的文档上执行的一个MapReduce 组合.来自视图的输出是一个索引,它通过MapReduce函数来匹配定义的结构.索引的存在提供了查询底层的文档数据的能力.Couchbase是一个面向列的键值存储,每个逻辑表由多个列族组成.数据对象在物理上组织在桶(bucket)中,每个bucket通常包含多个列.MixIndexer可以方便地将新的列添加到现有的Couchbase表中.原始传感器数据文件存储在Couchbase分布式文件系统中,而从空间和时间字段提取的数据表示为 第四层和第三层是MixIndexer的核心,第三层是在线时空传感器数据索引生成器和响应器.生成器用于定期创建、更新和重新组织索引,而响应器接收客户端的索引数据访问请求,设计了基于磁盘的MDR+树索引和基于Couchbase的关键字btree索引,实现了高吞吐量访问和实时数据检索.在生成器和响应器中嵌入了创建、插入、更新和删除等索引操作算法.该生成器封装了基于MapReduce的批量加载操作符,用于批量构造时空索引.在将传感器数据加载到Couchbase表后,使用Mapreduce的集群节点并行构造索引.每一个响应器对应一个守护进程. 第二层用于接收客户端的数据检索请求,当客户端请求数据时,响应器首先解析请求参数,并分析空间范围和时间间隔.然后Responsor确定与MBR和时间间隔相交的有效MDR+树,并向维护候选MDR+树的工作节点发送指令消息.这些工作节点并行执行指令并计算各自的中间结果.最后,主节点从并将最终结果返回给客户端. 第一层根据实际应用的访问模式,经常检索索引树,对不合格的数据对象进行修剪,得到候选对象,因此索引检索效率支持并发实时访问.另外,一旦查询特定区域和时间间隔内的数据,会访问地理上相邻的数据.因此,一个称为Vcache是为MDR+索引和热点传感器数据设计的,以保证实时访问.每个节点都分配一个可配置的内存池,vcache通过使用一致的哈希协议收集小池来组成一个更大的分布式缓存池.例如,有8个节点,每个节点分配1 GB,vcache容量为8 GB,vcache可以根据数据量配置可变内存大小.在实际应用中,所有的索引数据都是在vcache中存储的,但只有部分时空数据是根据访问频率预先提取到vcache中的.顶层结构是vtunnel,用作传感器数据传输通道和收集器.vtunnel维护多个实时先进先出(fifo)队列,每个队列从传感器网络的接收节点接收传感器数据流.假设队列容量为qv,队列数为nv,则在累积数据达到阈值大小(即qvnv)时,数据流将定期刷新到MixIndexer中. MixIndexer层次结构可以弥合地理空间应用程序和云平台之间的距离.由于Couchbase buckets是主从架构,因此本文索引方案包括两部分,分别是全局索引和局部索引.全局索引为四叉树索引,用于查找数据块. 四叉树是将已知的地理空间分成四个相等的子空间,递归下去直到树的结构达到一定的深度或满足某特定要求后停止分割[11].很多空间划分时都会采用四叉树结构,因为四叉树结构比较简单,当空间数据划分较为均匀时,具有比较高的空间查询效率;但若空间数据不平衡,四叉树在插入数据时会变成一颗不平衡的四叉树,导致查询效率低下[12]. 本文分析的时空数据量大结构复杂,在空间方面分布不均,针对这个问题,本研究在全局索引方面使用了改进四叉树结构.在Couchbase中以Bucket为单位采用四叉树划分GPS空间数据,并将其分割成若干个逻辑子区域,划分条件由Bucket的最小包围矩阵(Minimum bounding rectangle,MBR)和数据块阈值共同决定,改进后的四叉树划分算法的步骤如下: 第一,计算Couchbase中bucket区域内所有时空对象大小的和,若和不超过阈值,则停止划分这个区域,并将区域内的对象组织成一个数据块;否则继续将该区域递归地均匀划分为四个更小的子区域. 第二,分别计算每个子区域内所包含的时空对象长度之和,并调用上述步骤对新的子区域进行判断,直至所有子区域内的对象长度之和符合阈值条件. 采用以上步骤将bucket划分成若干个子区域,并把每个子区域内的时空对象组织成一个独立的数据块,最后将所有数据块均匀分布至Couchbase数据主节点上.通常设定数据阈值与Couchbase块大小一致,目的是为了保证划分后的子区域内的时空对象储存在同一个数据节点上. 全局索引对应改进四叉树结构,并将多版本分布式增强R+树(MDR+)设计为局部索引,时空GPS数据对象通过遍历局部索引树来确定.MDR+树为R树的变形模式,对R树进行改进. MDR+树设计为双层分布式结构,灵感来自修订的R*树(RR*)[13]和一致的哈希策略.时空数据对象按固定时间间隔分割,并且存在时间RR*各个时间间隔的树.MDR+索引树的中间节点包含其子节点的空间位置和时间间隔的最小边界矩形(MBR).真实数据对象存储在数据块中,MDR +的叶节点指向对象.时空数据对象根据其加权因子π均匀地分布在簇数据节点上,其中π由空间范围(例如,MBR区域)和一致的哈希值计对象ID,即π=combine(MBR,HashobjID). 图2 MDR +树索引Fig 2 MDR + tree index 如图2所示,根据对象的MBR,对象按给定的时间间隔[ts,te]分为3组,根节点和非叶节点由主节点维护,存储在vcache中,叶节点存储在3个从节点上.随着GPS数据的不断增长,指标数据量也必将增加.从数据记录中分别提取出 本文已经在Couchbase平台上实现了MixIndexer索引部分.如图3所示,全局索引树由Couchbase集群的主节点维护,而本地索引在从节点上保持不变.这个全局树的中间节点代表地理层的子区域,用空间尺度划分.每个中间子区域应细分为四个象限,即非叶节点有四个子节点.全局索引树的叶节点指向本地MDR+索引树的根节点.本地索引项在MixIndexer守护进程启动的情况下加载到从属节点的内存缓存池中.另外,将全局索引树保存为元数据图像,并将索引数据保存在主节点的内存中,以提高索引遍历和修剪效率. 图3 全局架构Fig 3 Global architecture 在存储方面全局四叉树有效避免了重叠死空间,局部索引使用MDR+树能保证其为一个高度平衡树,在MDR+树中,叶子节点保存数据的形式为(I,tuple-int),tuple-int表示存放Couchbase中的一条记录,包括时间、空间以及其他属性. 本实验硬件环境配置如表1所示.操作系统为CentOS release 6.5(Final),CPU为Intel(R) Core(TM) i7-4790 CPU @ 3.60GHz(3601 MHz),8 G内存,500 G硬盘.实验集群配置如表2,在8台普通服务器(1台主服务器和7台从服务器)组成的集群上进行,每个节点有2个四核Intel CPU 2.13GHz、4GB DDR3 RAM、15 000r/min SAS 300 GB硬盘.PostGIS-2.实验数据集采用来自微软T-Drive项目[15],该数据集包含2008年2月2日至2月8日期间北京地区10 357辆出租车的GPS轨迹,总数约为1 500万,轨迹总距离达到900万km的数据并导入Couchbase中,进行时空范围查询测试,并对本文算法进行验证.测试数据分为35个时间间隔,每个从节点保持5个时间间隔. 表1 硬件环境配置Tab 1 Hardware environment configuration 表2 实验集群配置Tab 2 Experimental cluster configuration 2.2.1 索引效率测试 图4所示为在不同数据量大小下所构建索引时间的大小进行比较,数据量的变化为50GB-300GB,在不同数据量下PostGIS、CCR+、Mixindexer构建索引所需时间的大小比较.可以看出随着数据量的增加,PostGIS以及CCR+树构建索引时间上涨幅度较大,MixIndexer构建索引时间上涨幅度较为缓慢,MixIndexer的索引构建时间比PostGIS平均缩短约78%,比CCR+树平均缩短约62%,说明前者构建索引效率更优,进一步验证了在随着数据量增大的情况下MixIndexer复合索引构建时间比较短.这是因为本文全局索引使用了四叉树索引,较大程度上降低了开始节点间的重叠,对分布不均匀的空间要素得以正确处理,从而提高索引操作的性能. 图4 不同数据量下构建索引比较Fig 4 Comparisons of index construction under different data volumes 图5 不同并发请求下的查询时间Fig 5 Query time under different concurrent requests 2.2.2 时空选择查询结果与比较不同数量的并发查询 图5所示为选择不同并发请求下PostGIS、CCR+、Mixindexer的查询耗时比较. 1)使用Mixindexer复合索引的查询耗时与并发请求数量呈线性正相关; 2)使用Mixindexer混合索引相比CCR+树和PostGIS平均耗时缩短了25%和42%; 3)随着并发请求量的增加,Mixindexer混合索引的查询响应时间优势比较PostGIS、CCR+更为明显. 经分析发现,PostGIS是一种对象-关系型数据库,而MixIndexer为分布式,把各个查询均匀的分配到了8 个节点;在对时间方面的查询时,由于CCR+树并未考虑时空数据的时空属性,并将其归入空间属性的另一维,致使整个多维空间数据不能协调分布,节点频繁访问,导致查询开销增加. 然而使用了四叉树和R树复合的MixIndexer先整体使用四叉树将数据划分,再局部使用R+,降低了R树节点间的重叠,使得查询所访问的节点数更少,提高了查询效率.同时本文将时间属性与空间属性分开,对于查询性能的提高也起了重要作用. 2.2.3 集群节点数的批量加载效率 图6所示为不同大小数据集下MiIndexer集群节点数从1-7的批量加载效率的影响,分析结论得到: 1)三个不同数据量下,随着集群节点的增加,批量加载操作时间逐渐变小. 2)在只有一个集群节点数时,三个数据量下的批量加载操作时间差距很大,随着节点数增加,三个数据量下的批量加载操作时间逐渐变小,并且在节点数为7的时候相差不大. 这是因为本文在构建MixIndexer的过程中,全局索引使得树结构更加紧凑,自底向上逐层构建树结构,建立局部索引,确保数据精准划分,避免访问多余节点,将时间和空间分开划分,有利于需要同时考虑空间和时间的时空传感数据的查询. 图6 集群节点数的批量加载效率Fig 6 Batch loading efficiency of number of cluster nodes 鉴于时空数据查询中缺乏在时间和空间方面合理组织的考虑,本文从时空数据的空间分布出发,利用Couchbase丰富的数据结构组织时空数据,在时间方面分为7个时间间隔,每个间隔为5 min,在空间索引方面使用复合索引,整体使用四叉树结构,在数据库的主节点划分四个子区域;局部索引使用MDR+树分布空间数据,最后在Couchbase节点上均匀分布数据. 为了满足大时空传感器数据的要求,本文提出了一种分布式复合索引方案MixIndexer.MixIndexer 将Web-GIS和物联网应用程序访问模式结合在一起,并将传感器数据特征纳入考虑.和面向时空优化后的方案相比,Mix-Indexer得到了逐步的改进.因此,MixIndexer为针对考虑时间维度以及空间维度数据密集型地理空间应用提供了一种高效、可行的方案.1 复合索引结构—MixIndexer
1.1 MixIndexer层次结构
1.2 基于MixIndexer的改进四叉树结构
1.3 MDR+算法
1.4 存储架构
2 实验
2.1 实验环境

2.2 实验结果
3 结论
