基于sparse group Lasso方法的脑功能超网络构建与特征融合分析
2020-03-06赵云芃李欣芸刘志芬陈俊杰
李 瑶,赵云芃,李欣芸,刘志芬,陈俊杰,郭 浩
(1.太原理工大学 信息与计算机学院,山西 晋中030600; 2.太原理工大学 艺术学院,山西 晋中 030600;3.山西医科大学第一医院 精神卫生科,太原 030000)
0 引言
近年来,神经影像学技术用于探索脑区间的交互作用已经得到了越来越多的关注。低频血氧水平依赖(Blood Oxygenation Level Dependent,BOLD)信号存在显著的低频相关,可作为神经生理学指标用于静息状态功能磁共振成像(Resting-State functional Magnetic Resonance Imaging, RS-fMRI)来检测静息状态下的脑自发活动[1]。该自发活动可通过BOLD信号的时间相关性来量化,进而将其表征为脑网络。复杂的脑网络研究有助于阐明神经精神疾病的机制,并有可能提供相关的成像标记,为临床脑疾病的诊断和评估提供新的视角[2],因此,脑功能网络已成功地用于研究脑疾病的研究,包括癫痫、抑郁症、阿尔茨海默症、精神分裂症等。
传统的网络模型大多都是捕捉两个脑区间的信息。然而,已有研究表明在人脑交互活动中,不仅两个脑区间存在联系,多个脑区间也同样存在直接交互信息[3]。为了弥补传统网络的不足,超网络被提出[4]。超网络基于超图理论,区别于传统网络,其节点表示脑区,超边表示多个脑区间的直接交互,是对传统的延伸。近年来,超图已成功地应用于各种各样的医疗影像领域包括图像分割以及分类[5-6]。Liu等[5]使用视图对齐超图学习方法对阿尔兹海默症中得到的不完整的多模态数据进行分类诊断。彭瑶等[6]提出一种基于超图的多模态特征选择算法来改善原有方法对脑疾病的诊断。一些最近的研究给出了神经科学和超图之间的联系[4,7-9]。Jie等[4]通过超图技术创建脑功能超网络,来进行脑疾病诊断。靳研艺等[7]考虑到脑区间的组效应,进一步对Jie等[4]创建的超网络进行改进。张帆等[8]考虑到全局的拓扑信息,提出了基于脑功能超网络的多特征融合分类方法。Gu等[9]提出了基于BOLD磁共振影像数据的超图表示方法,且将超边分成具体的三类:桥、星型以及聚类,来分别代表二分:焦点和空间分布式架构。进一步地,一个新的基于学习的超网络最近也被提出来表示多个脑区间的复杂连接模式[10]。Zu等[10]采用基于超图学习的方法来识别自闭症谱系障碍和注意力缺陷多动障碍疾病中子网络中的生物标记物。除此之外,其余感兴趣的超图应用也被发现在蛋白质功能预测和模式识别中[11],Gallagher等[11]将聚类系数扩展到超网络中,并从蛋白质相互作用的角度来看待这些指标的物理意义。
在最近的研究中,Jie等[4]利用Lasso(Least absolute shrinkage and selection operator)的方法求解稀疏回归模型进行超网络的构建,但Lasso方法由于本身的局限性,导致构建的超网络缺乏解释分组效应的能力[12]。然而,多个研究表明脑区间经常存在组结构,脑区结构倾向于共同参与以实现某种功能[13],因此,考虑到组结构的问题,之前的研究中,提出使用基于group Lasso(gLasso)方法来改善超网络的创建[14],但group Lasso方法是在组级别上进行变量选择,这样构建的超网络过于宽松,可能包含一些错误的连接。
为了解决上述问题,考虑到脑区间存在着潜能的组结构,本文对Guo等文章[14]进行了延伸,进一步提出sparse group Lasso(sgLasso)[15-17]方法来求解稀疏回归模型进行超网络的创建从而解决组结构问题。sparse group Lasso方法是混合了Lasso与group Lasso方法,既选择组间变量也选择组内的变量,是一个双级选择方法。该方法能够有效地去除不重要的组以及重要组内的不重要的单个变量[15-16]。
除此之外,多个研究证明真实网络邻域之间存在显著的重叠,不仅单个顶点间的邻居节点更容易重叠,而且单一的边也有更大的邻居凝聚力[11,18-19],因此为了更加准确阐明神经精神疾病的机制以及全面地评估疾病的性能,本研究又引入超网络中广泛使用的几个成对节点间的相互聚类系数作为另一种特征提取方法。
本文主要工作包括:1)使用sparse group Lasso方法来创建脑功能超网络;2)通过使用两组超网络聚类系数计算方式提取特征使其更全面地表达脑功能网络拓扑且使用非参数检验来选择具有差异的特征;3)使用多核支持向量机(Support Vector Machine,SVM)对选择的特征进行分类。
1 被试与方法
1.1 方法框架
对于基于sparse group Lasso方法来创建超网络来进行脑网络分析的流程框架主要包括数据收集及预处理,基于sparse group Lasso方法的功能超网络创建,特征提取,特征选择及分类。具体来说,这个框架由下列几个步骤组成。
1)数据收集及预处理。
2)超网络的创建:对于每个被试,使用稀疏线性回归模型来创建超网络,即通过sparse group Lasso方法优化目标函数,将选定区域由其他区域的时间序列的线性组合来表示。
3)特征提取与选择。
a)使用超网络中独有的局部聚类系数的定义,计算成对节点间的聚类系数。也就是一对节点共享了多少条边。
b)使用聚类系数在传统图中的定义,即一个顶点的邻居也互相是邻居的比例。将其概念应用至超网络中来定义聚类系数,进而求得每个节点的局部聚类系数。
4)使用非参数检验来分别对两种不同类型的局部聚类系数选取脑区特征。
5)分类模型构建:
a)将两种不同类型的局部聚类系数选取出的具有显著差异的特征作为分类特征融合至一起来构建对应的分类器。
b)使用交叉验证方法来测试创建的分类器以及获得最后分类结果。
1.2 数据采集和预处理
按照山西医学伦理委员会(reference number: 2012013)的建议征得所有参与者的同意,并参照Helsinki宣言与所有被试达成书面协议。本次实验中,一共招募66名被试,分别包括38名首发,无用药抑郁症(Major Depressive Disorder, MDD)患者(15名男性;平均年龄:28.4±9.68岁,区间:17~49岁)和28名健康被试(13名男性;平均年龄:26.6±9.4岁,区间:17~51岁),所有被试者均为右利手。他们的影像数据通过3T磁共振扫描仪(Siemens Trio 3-Tesla scanner, Siemens, Erlangen, Germany)进行收集来获得。详细被试信息参考表1。本文所用数据集已存至网盘,其链接为https://pan.baidu.com/s/11Ae-Qm9WX4MqwwobYjPP7g,提取码为964a。
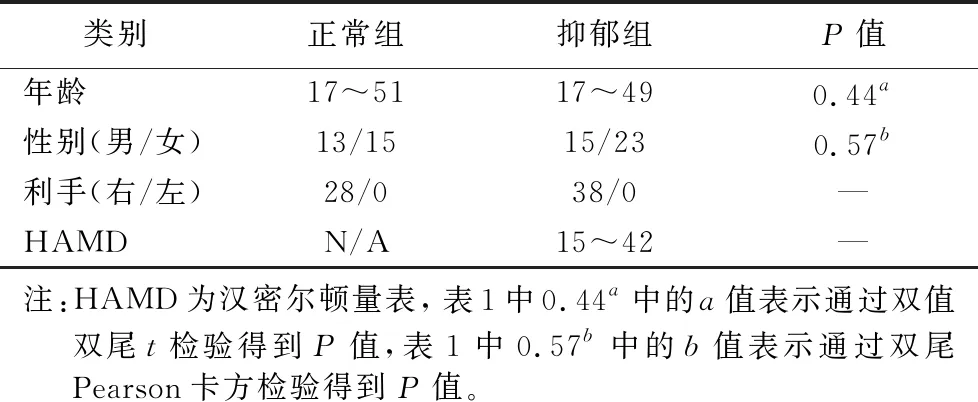
表1 被试基本特征 Tab. 1 Basic characteristics of subjects
参与者的影像数据由山西医科大学第一附属医院中熟悉磁共振的放射科医师来完成采集以及扫描工作。扫描过程中,所有参与者要求闭眼保持静止,不去想其他事情。每次扫描得到248个连续的EPI功能图像(volumes),且设置具体的扫描参数如下:33 axial slices, repetition time (TR)=2 000 ms,echo time (TE)=30 ms,thickness/skip=4/0 mm,field of view (FOV)=192 mm×192 mm,matrix=64 mm×64 mm,flip angle=90°。由于初始数据信号的不稳定性,将功能图像的前十个时间序列丢弃。
应用SPM8(http://www.fil.ion.ucl.ac.uk/spm)进行磁共振图像数据预处理,主要通过时间层校正、头动校正、MNI空间标准化、带通滤波器(0.01~0.10 Hz)和去线性漂移。首先对图像进行时间层校正和头动校正。将头动大于3 mm或转动超过3°的被试丢弃,使其不包括在最后的66例被试中;图像校正后,接着进行12维度放射变换,将校正后的图像标准化到蒙特利尔神经学研究所(Montreal Neurological Institute,MNI)标准空间中;最后进行去线性漂移和带通滤波来避免低频漂移及高频生物噪声所造成的影响。
1.3 超网络创建
1.3.1 超图论
图论已经被广泛用于计算和脑研究成像,因为它可用于量化大脑连接,通过图来表示感兴趣对象之间的关系,且图中的节点表示的是对象,边即节点之间的连接来可以描绘对象之间的关系[20]。之前的许多研究都采用简单图来创建网络模型,节点作为脑区,两个节点间的连接作为一条边,但这个只能仅仅表达成对脑区间的成对关系,但在脑区间的功能互动中,越来越多的研究证明脑区间互动存在高阶关系,因此为了克服这个局限性,引入超网络。

1.3.2 稀疏线性回归模型
预处理完成后,按照自动解剖标记 (Anatomical Automatic Labeling, AAL)[22]模板将大脑划分为90个感兴趣区域(Region Of Interest,ROI),包括左右半脑各45个ROI,每个ROI作为功能脑网络中的一个节点。需要注意的是90个ROI指的是大脑区域,小脑除外。每个脑区的平均时间序列通过执行回归来排除大脑中平均脑脊液(Cerebro-Spinal Fluid,CSF)、白质信号以及头动校正的影响。这里需要注意的是,全脑平均信号是否回归在该领域内意见还不一致,因此为了避免争议,本研究在数据预处理的过程中并未作全脑信号。利用rs-fMRI时间序列基于线性回归方法构建功能连接超网络[4],具体来说,就是通过该方法将选定的脑区通过其他脑区的线性组合来表示,以此获得该脑区与其他脑区的交互作用,同时迫使与无意义脑区的交互作用为零。
稀疏线性回归模型具体表示如下:
xm=Amαm+τm
(1)
其中:xm表示第m个ROI的平均时间序列;Am=[x1,x2,…,xm+1,xm+2,…,xM]表示第m个ROI的数据矩阵(除了第m个脑区的所有平均时间序列,且对应第m个ROI的平均时间序列设置为0);αm表示系数向量,其量化了从其他ROI到第i个ROI的影响程度;τm表示噪声项。αm中非零元素表示的是与特定ROI有着交互作用的ROIs,零元素表示与特定ROI的交互作用是无意义的ROIs。
1.3.3 基于sparse group Lasso的超网络创建
在之前的研究中,通过Lasso方法来求解稀疏回归模型来创建脑网络[4],但Lasso方法缺少解释分组效应的能力[12]。也就是说,如果一个特定的变量与一组变量的成对相关性都很高时,那么Lasso方法通常只选择一组变量中的一个,且不关乎哪一个,因此选取的方法过于严格,会丢失一些有用的连接。为了解决这一问题,考虑到脑区之间的组结构,已有的研究通过引入group Lasso(后面用gLasso表示)方法来进行超网络的创建,主要是在事先定义的组级上进行有效的变量选择[23]。也就是说,gLasso将整个组视为一个整体,并确定它是否对问题重要。虽然组套索给出了一组稀疏组,但如果在该模型中包含一个组,那么该组中的所有系数都将是非零的。有时希望同时包括组稀疏性和组内稀疏性,例如,如果预测因子是脑区,希望在多个脑区相互作用中识别特别“重要”的脑区;然而,这种方法不能在一个组内产生稀疏度。也就是在功能脑网络中具有组结构的多个脑区中有几个脑区与选定脑区具有高度相关作用,gLasso则认为该组中的所有脑区非零,也就是所有脑区均与选定脑区均具有高度相关作用。这样构建的网络过于宽松,或者存在许多虚假的连接,或者丢失一些有用的连接。
因此引入sparse group Lasso(后面用sgLasso表示)[15]方法来改善超网络的创建,这个方法仍然是基于线性回归模型,但是既可以在组级上进行变量选择,又可以在单个变量级上进行变量选择,也就是说,可以在自由地选择组间或组中的单个变量。在功能脑网络中,如果存在组效应的多个脑区中有一个或几个脑区均与选定脑区相关,则该方法不会只选择该组,而是选择该组中与它相关的一个或多个脑区,当然如果该组均高度相关,则会选择整组,这样便能过滤掉一些虚假且保留一些有用的连接。因为sgLasso方法是选择出重要的组,在重要的组里再选择重要的变量,因此在利用sgLasso方法进行超网络创建之前,需要通过聚类算法先依据90个脑区的平均时间序列进行聚类得到分组,再基于该方法进行超网络构建。本研究中采用k中心点聚类法[24]来进行聚类从而对脑区进行分组,通过设置不同的k值,则会获得不同的超网络拓扑及分类性能。在本研究中,当聚类数目k设置为30时,该方法实现最高的分类准确率(详细分析在3.1节涉及)。接着使用sgLasso方法来创建超网络,式(2)是优化目标函数:
min(‖xm-Amαm‖2+λ1‖αm‖1+
(2)
其中:αm通过聚类被分成了k个非重叠的树组(αmG1,αmG2,…,αmGk),而G1有树结构的节点;λ1,λ2均是回归参数,λ1被用来调整模型组内稀疏性,即控制非零组中非零系数的数量,λ2被用来调整组级稀疏性[25-26],即控制具有至少一个非零系数的组的数量。该模型是Lasso与gLasso的结合:λ1=0得到gLasso估计,λ2=0即得到Lasso估计。需要注意的是,该模型看起来与elastic net模型有点相似,但却是不同的,因为l2范式在0处不可微分,因此一些组完全归零;然而,在每个非零组中,它给出了弹性网络拟合[27]。基于该方法来构建每个被试的超网络,ROI作为节点,第m个ROI以及在αm中非零元素对应的ROIs作为超边。对于每一个ROI,固定λ2值,通过变化λ1值从0.1~0.9,增量为0.1,则会产生一组超边。在该实验中,将λ2设置为0.4,得到了该模型中最高的准确率,为87.88%。本实验中,通过SLEP包[28]来优化求解(详细的分析描述见3.2节)。
1.4 特征提取与选择
功能连接超网络创建之后,需要选取具有代表性、能够识别目标的特征集合,这就需要特征定义。在脑功能超网络分析中,有多项指标可以反映节点及整个网络的特性,但在医学影像领域中,大多数研究都是将聚类系数作为网络局部特性指标来改善疾病诊断性能。在之前的研究中,只涉及到单个节点的聚类系数作为特征提取方法;然而依据多个研究证明真实网络邻域之间存在显著的重叠,不仅单个顶点间的邻居节点更容易重叠,而且单一的边也有更大的邻居凝聚力(neighborhood cohesiveness around individual edges)[11,18-19],因此为了尽可能更加准确且全面地评估疾病的性能,本研究又引入超网络中广泛使用的几个成对节点间的相互聚类系数作为另一种特征提取方法。
1.4.1 单一节点的聚类系数的特征提取
超网络构建完成后,需对其执行特征提取计算。本研究中,从不同角度引入了超图中三种不同定义的单一节点的聚类系数(HCC1、HCC2、HCC3)来描述超网络的局部聚合[11]。单一节点的聚类系数与传统图中聚类系数定义相同,即一个节点其邻居的紧密程度。从连接超网络中依据这三个基于单一节点的聚类系数提取特征。表2表示了定义及这些属性的计算。

表2 基于单个节点的聚类系数的定义与公式 Tab. 2 Definitions and calculation formulas of clustering coefficients based on single node
表2中:u,t,v指的是某一节点;N(v)={u∈V:∃e∈E,u,v∈e}指的是节点集,E指的是超边集,e指的是某条超边,N(v)表示包含节点的所在超边含有的其他节点的集合;若∃ei∈E,且u,t∈e,但v∉ei,则I(u,t,v)=1,否则I(u,t,v)=0;S(v)={ei∈E:v∈ei},v表示节点,ei表示超边,S(v)表示包含节点的超边的集合。
1.4.2 成对节点间的相互聚类系数的特征提取
多个研究证明真实网络可以被小世界网络表示,其邻域之间存在显著的重叠,不仅单个顶点间的邻居节点更容易重叠,而且单一的边也有更大的邻居凝聚力(neighborhood cohesiveness around individual edges)[11,18-19],因此对传统的聚类系数进行扩展,产生节点对间的聚类系数,而且该计算聚类系数的方式已被广泛用于超网络中[11]。在这种定义形式下,聚类系数则指的是一对节点共享了多少条边。在整个超图研究中,已经有多种方法计算了节点对的聚类系数[11,18-19]。在本文研究中,则引入了5种广泛使用的节点对的聚类系数从不同的角度反映通过单一的边的邻居凝聚力,从而更全面地表达超网络中的拓扑属性。从连接超网络中依据单一的边的聚类系数定义分别提取特征。表3表示了定义及这些属性的公式。

表3 基于一对节点的聚类系数的定义与公式 Tab. 3 Definitions and calculation formulas of clustering coefficients based on a pair of nodes
表3中:u,v指的是脑区节点,S(v)={ei∈E:v∈ei},v表示节点,ei表示超边,S(v)表示包含节点v的超边的集合,Total指的是超边的总数量。
通过计算成对节点的聚类系数之后,单一节点的聚类系数则是通过平均该节点与其所有邻居节点的聚类系数来得到[19]:
(3)
COMHCC(u,v)指的是通过任何方法计算求得的超图中成对节点间的聚类系数。N(v)={u∈V:∃e∈E,u,v∈e},V指的是节点集,E指的是超边集,e表示某一条超边,N(v)表示包含节点v的所在超边含有的其他节点的集合。
这5组指标是从不同的角度反映通过单一的边的邻居凝聚力,来进一步地计算每个节点的聚类系数,从而更全面得表达超网络的局部聚类属性。从连接超网络中依据单一的边的聚类系数定义分别提取特征。
1.4.3 特征选择
特征提取完后的特征有着一些冗余或无关的特征,需要对其进行特征选择,去掉无关或冗余的数据,这样便于建立更准确的预测模型,因此对于MDD患者和正常人,分别对使用两种不同方式提取的聚类系数产生的270个以及450个节点属性进行组间ks非参数检验[29],已通过错误发现率(False-Discovery Rate,FDR)(q=0.05)校正[30]。将选取出的具有显著组间差异的两组特征作为分类特征通过多核学习融合至一起进行预测模型构建。
1.5 分类
通过本文选取的超网络中两组具有显著差异的脑区特征作为输入特征来构建分类模型。通过两种不同类型的聚类系数彼此提供互补信息来进行MDD分类,采用多核学习来分别通过两种不同类型的聚类系数估计的内核的最佳线性组合来有效地融合特征。核的整合是通过多个核的线性结合[31]:
(4)
其中:ki(x,y)是第i组的聚类系数中被试x和y间的内核矩阵;M是需融合的核矩阵的数量;αi是权重参数。接着,利用基于LIBSVM分类包(http://www.csie.ntu.edu.tw/~cjlin/libsvm/)的高斯内核的SVM分类器对复杂核进行分类。
留一交叉验证(Leave One Out Cross Validation, LOOCV)被用来评估分类性能,即若样本数量为N时,则每次实验取1个样本当作测试集,其余样本作为训练集。此外,为了得到更好的分类模型,本实验加入参数寻优过程,主要是对训练集进行k折交叉验证,将训练验证分类准确率最高的(c,g)作为最优参数,参与模型的构建,从而得到最好的分类模型。本次过程重复N次,得到N个分类模型进行分类测试,最后选取N次实验的分类准确率的平均值作为最后分类结果。本研究中,(c,g)参数取值的变化范围设置为[2-5,25],步进大小为1。另外,需要对分类特征进行标准化再进行分类模型构建。需要注意的是,在基于sgLasso方法中由于聚类时初始种子点随机选取会影响最终的分类结果,在实验中,通过执行50次实验来计算其分类结果平均值作为最后分类结果。
2 实验结果与分析
2.1 差异脑区
利用sgLasso方法进行超网络构建并提取特征。对提取的每一个特征,均进行非参数置换检验且对所有被试评估MDD和CON之间的差异,特征已通过FDR校正。
表4和表5列出了通过两种不同类型的聚类系数得到的显著差异的大脑区域。通过两组聚类系数得到的重叠区域较少,主要集中于右侧中央沟盖、部分边缘系统区域(右侧后扣带回)以及双侧丘脑。如图1所示,因此可说明能从两组聚类系数中得到全面评估疾病诊断性能以及识别与疾病病理学相关的生物标记物。
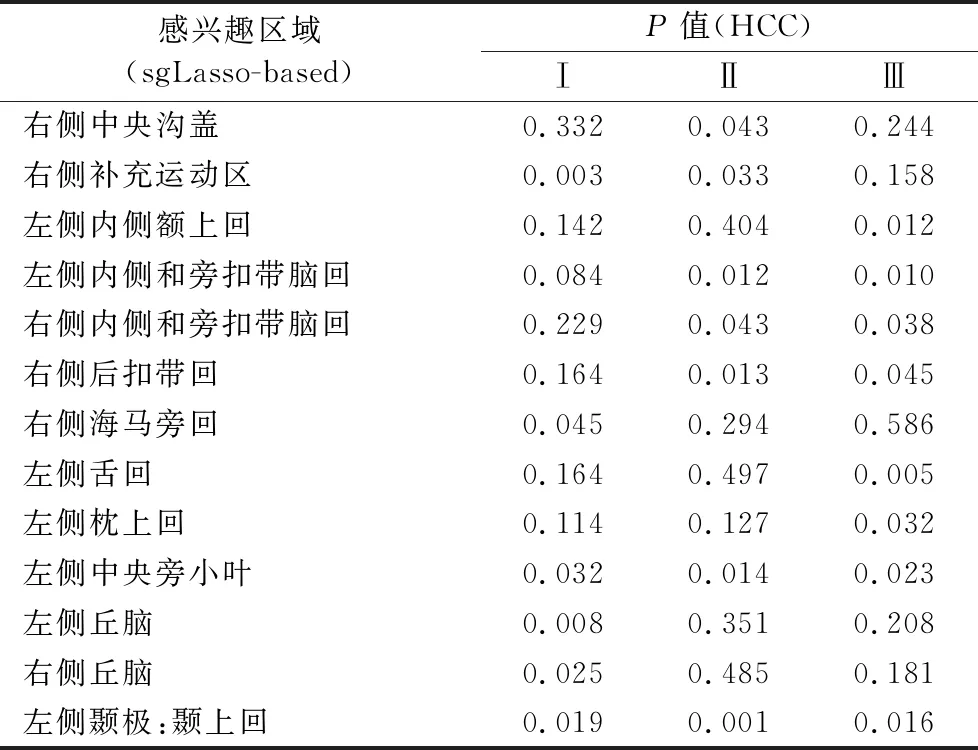
表4 基于单一节点的聚类系数得到的显著差异脑区 Tab. 4 Significantly different brain regions obtained by clustering coefficients based on single node
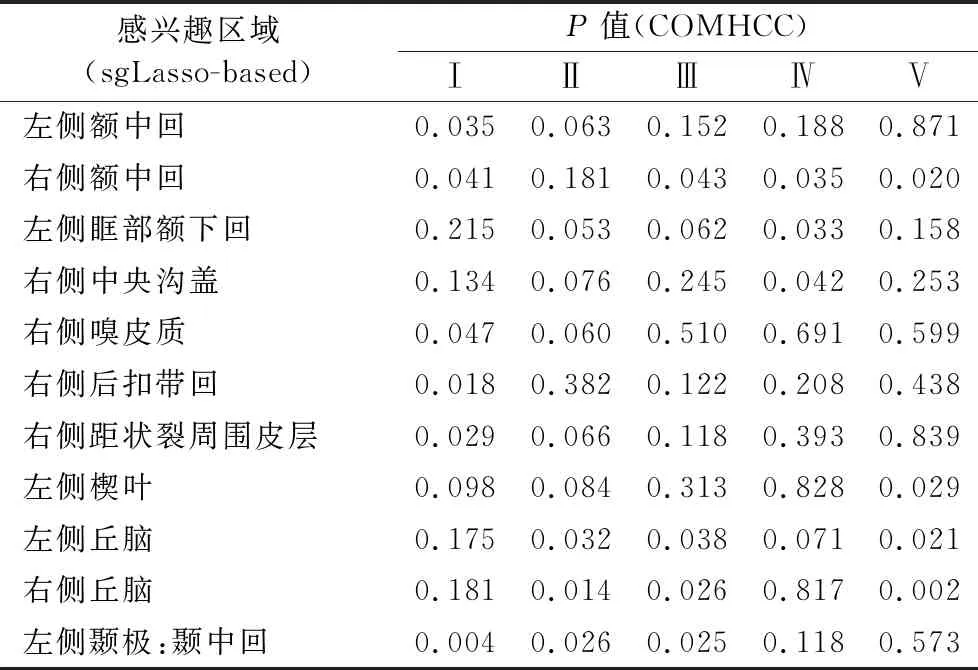
表5 基于一对节点的聚类系数得到的显著差异脑区 Tab. 5 Significantly different brain regions obtained by clustering coefficients based on pairs of nodes
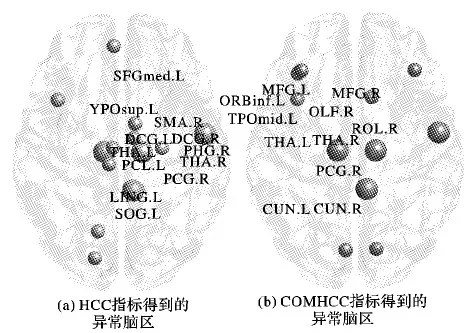
图1 使用BrainNet软件将所有异常脑区域映射到皮质表面Fig. 1 All abnormal brain regions mapped onto cortical surfaces using BrainNet software
基于sgLasso方法构建超网络,对两组不同类型的聚类系数利用统计分析计算方法分别得到13个异常脑区以及11个异常脑区(包括重叠区域),包括右侧额盖区、右侧补充运动区、双侧丘脑、额叶区域(左侧内侧额上回、双侧额中回、左侧眶部额下回)、边缘系统(左侧内侧和旁扣带脑回、右侧内侧和旁扣带脑回、右侧海马旁回、右侧后扣带回、右侧嗅皮质、右侧距状裂周围皮层)、枕叶区域(左侧楔叶、左侧舌回、左侧枕上回、左侧中央旁小叶)、颞叶区域(左侧颞极:颞上回、左侧颞极:颞中回)。这些脑区已经在之前的文献中被证明与抑郁症的病理研究存在着显著的关联,并将该方法取得的差异脑区与其他文献所得到的结果一致。Zhu等[32]证明右侧额盖区的模块度与抑郁严重程度呈负相关。Liu等[33]证明在右侧补充运动区,抑郁症患者与正常人存在差异。Jin等[34]使用图论来评估抑郁症青少年脑功能网络的拓扑特征时,发现抑郁症青少年中的左侧内侧额上回等脑区受到严重破坏。Guo等[35]使用机器学习对抑郁症分类,其中异常脑区包括内侧和旁扣带脑回,右侧后扣带回和双侧额中回等。Qiu等[36]使用结构磁共振成像证明抑郁症异常脑区包括右侧海马旁回以及左侧颞级:颞中回等。Lord等[37]研究单极性抑郁症静息态功能连接社区结构的变化时,发现左侧舌回等脑区发生变化。Liu等[38]通过使用回波平面成像序列获得静息态fMRI,从而计算低频振幅以研究静息状态下的低频(0.01~0.08 Hz)振荡的振幅时,发现与正常人相比,抑郁症患者在左侧枕上回等脑区的低频振幅明显降低。Rolls等[39]发现左侧中央旁小叶等脑区在研究抑郁症的有效连接时与正常被试存在差异。Lui等[40]发现顽固性抑郁组患者主要在双侧丘脑区等的功能连接受损。Guo等[41]基于最小生成树的多特征融合方法进行分类时,表明右侧嗅皮质在两组被试间存在差异。Zhang等[42]发现在右侧距壮裂周围皮层抑郁症的节点中心性指标明显下降。使用不同成像方法识别的大脑区域之间的覆盖脑区有限,最一致的区域包括左侧颞级:颞上回等[43]。
2.2 分类表现
评估了基于sgLasso方法创建的超网络模型的分类性能,并且与传统的超网络创建方法(Lasso方法与gLasso方法)进行比较。分别使用两种不同类型的聚类系数作为特征提取,非参数置换检验用来特征选择,SVM用来分类,LOOCV用来评估分类性能,得到其准确率、敏感性(可准确识别病人的比例)、特异度(可准确识别正常被试的比例)和平衡准确率(Balanced ACcuracy,BAC)(敏感性和特异度的均值,为了保证数据之间的平衡)。这里需要注意的是,这三种方法提取出来的用于分类的特征所对应的脑区是不同的脑区,假若使用相同的脑区,则会导致存在非差异性特征参与分类模型的构建,从而并不能创建最优的分类模型,以致不能得到最好的分类准确率;同时,利用这三种方法创建超网络所使涉及的参数也是不一致的,均是根据分类结果,从而选出每种方法中最优的参数。分类结果在表6中表示。结果表明,sgLasso得到了最高的准确率,为87.88%,优于基于Lasso创建的超网络及基于gLasso创建的超网络。基于Lasso创建的超网络低于sgLasso方法,其潜在的原因主要是Lasso只能选择存在组结构中的一个脑区,且无论哪一个,这将导致Lasso构建的网络过于严格或者失去一些重要的连接。这一结果暗示着不考虑组结构的存在则不能创建更合适的超网络。基于gLasso的超网络构建方法进行分类最后得到的分类结果不如sgLasso方法所得的结果,其潜在的原因主要是它不具有组内变量选择的灵活性,仅选择相关组,以使每组内的估计系数全部为零或全部为非零,这将导致gLasso构建的网络过于宽松或者加入一些错误的连接。这结果暗示着若为了改善超网络的创建,需要考虑到组信息,但不能逼迫使用整组信息,可以适当地对组结构进行扩展。

表6 不同方法的分类性能 单位:%Tab. 6 Classification performance of different methods unit:%
除此之外,本研究也与关于抑郁症研究的其他文献在分类结果上进行比较,从分类结果上看,本研究结果令人满意。使用皮尔逊相关或者稀疏逆协方差[44-45]来创建脑网络,这样仅能捕捉到两个脑区间的交互作用,忽略了脑区间的高阶交互。靳研艺等[7]利用Lasso方法和elastic net方法分别创建脑功能超网络,但是Lasso方法缺乏解释组效应的能力,从而导致丢失一些有用的连接,致使不能构建更加精确的超网络;因此提出elastic net方法来改善超网络的创建,虽然该方法能解决组效应问题。但需要注意的是该方法并不能使高度相关的变量均属于组中的活跃集中,而且本研究仅将单一节点的聚类系数作为脑区特征,仅考虑到单个顶点的邻居节点的重叠性,并未考虑脑区间邻域之间显著的重叠。本文的新方法使用sgLasso方法结合多特征融合来进行脑疾病的分类,既考虑到了多脑区间的交互,又考虑到超网络的组结构问题,同时将两组聚类系数结合,较好地弥补以上研究的不足之处。
为了判断两种方法中所选特征对分类的贡献程度,本文采用Relief算法计算每种方法中对应特征值的分类权重,Relief作为一种特征权重算法,可以判断特征对于分类的重要性,若权重越大,则表明分类能力越强,反之亦然。在本次实验中,将sgLasso方法中的单节点聚类系数特征、双节点聚类系数特征、多特征分别计算的差异特征利用Relief算法计算对应特征值的分类权重并进行比较,结果显示在图2中,结果表明,多特征得到的分类权重均高于单个特征的分类权重。通过Relief算法来评估特征的重要性。潜在的原因是基于多特征的方法有效地融合了两个不同的信息,单个节点的聚类系数特征以及双节点聚类系数特征,可以更加全面地表达脑区域间的交互信息。这一结果暗示着,表明多特征方法更适合评估特征的重要性,更适合分类抑郁症患者与正常人。
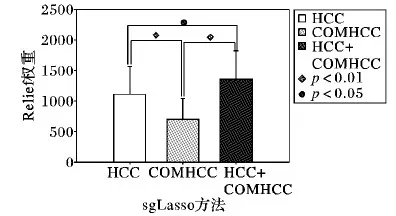
图2 脑区特征对应的分类权重Fig. 2 Classification weight corresponding to brain region feature
3 方法论及参数影响
功能超网络的不同构建,会对分类性能产生影响。在现有研究中使用Lasso进行超网络创建[4],该方法中,通过使用l1范数来控制网络的稀疏度,仅仅是对单个变量的选择,未考虑到脑区间的组效应,导致一些相关的脑区无法选择出来,使得超网络过于严格,从而缺失重要的连接。考虑到组结构问题,Guo等[14]引入group Lasso方法进行超网络的创建,但group Lasso仅仅是在组级上进行变量选择,将整组作为整体,使得超网络又过于宽松,从而导致包含一些错误的连接。本文提出sgLasso方法来进行超网络创建,基于sgLasso方法是引入l1、l2范数惩罚项,即该方法范式是混入Lasso与gLasso惩罚项,可以进行组间选择以及组内变量选择,即双级选择,区别于简单组选择,变量可以在组级上以及单个变量间进行选择,不仅可以选出重要的组,而且可以选出这些重要组中重要的变量。
除此之外,本文所提出的方法中的一些参数同样也会影响分类性能,例如聚类数k,超网络构建模型正则化参数λ1和λ2,优化权重参数αi。为了探讨这个问题,本文对基于sgLasso方法的多特征融合方法进行了实验。
3.1 聚类数k的影响
k指的是sgLasso方法中的聚类数目,设置不同的k值会获得不同的超网络拓扑和分类性能,本研究中,为了分析不同k值对于超网络拓扑及分类结果的影响,设置k值取值范围为[6,90],其中步长为6。对每一个k值基于sgLasso方法进行超网络构建,特征提取,特征选择,分类及评估验证。由于第一个初始种子点的随机选择的影响,对于每个k值则分别进行50次实验,最后取50次实验的平均值作为最后的结果。图3展示了sgLasso方法的实验结果,结果表明当k=30时,sgLasso方法表现出最高准确率87.88%。
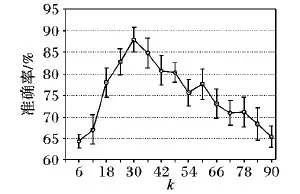
图3 基于sgLasso方法中不同k值的分类准确率Fig. 3 Classification accuracy based on sgLasso method under different k values
3.2 正则化参数λ1和λ2的影响
以前的研究已经表明参数λ影响超网络的拓扑。正则化参数λ决定了网络的稀疏以及规模。本研究中,参数λ1是l1范数项的正则化参数,偏向于控制模型组间稀疏,步长设置为0.1。参数λ2是l2范数项的正则化参数,偏向于控制模型组级稀疏,同λ1,步长设置为0.1。不同的λ1和λ2的设置会得到不同的网络拓扑,会使模型选择不同的组变量,从而导致产生不同的组结构,同时也会影响分类性能。在基于sgLasso方法的超网络的创建中,本文固定λ2值,通过变化特定范围内的λ1值产生一组超边;同时,为了探讨λ1,λ2对分类性能的影响,λ2分别设置为0.1,0.2,…,0.9,λ1使用了一系列升序组合,{0.1},{0.1,0.2},{0.1,0.2,0.3},…,{0.1,0.2,…,0.9},以此来进行不同的超网络创建。进而提取特征来进行分类,判断分类性能。分类结果展示在图4中。结果显示在sgLasso方法中,当λ2=0.4,λ1使用{0.1,0.2,…,0.9}时,表现出最高正确率达到87.88%。当λ1使用{0.1}时,准确率低于60%,主要是因为一个脑区节点可能只包含在一条超边中,导致HCC3计算无意义。
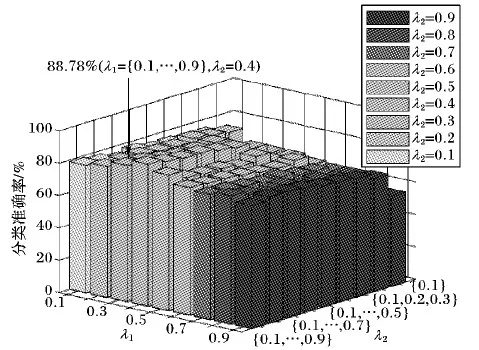
图4 基于sgLasso方法中参数(λ1,λ2)的分类准确率Fig. 4 Classification accuracy based on sgLasso method under different parameters (λ1,λ2)
3.3 有效权重αi的影响
在多核学习中,重要的一步是选择权重参数αi,这直接影响数据融合的方式,对分类性能有很大影响。在获取权重参数αi之后,多个内核集成混合内核,然后可以通过传统的SVM分类器来解决该模型。本文采用了shogun工具箱(http://www.shogun-toolbox.org),来获得优化权重。当α1=0.121 9和α2=0.878 1时,sgLasso方法的精度达到最大值87.88%。
4 结语
本文研究考虑到现有研究中存在的组结构的问题,引入sparse group Lasso方法来进行超网络创建;同时,考虑到真实网络不仅单个顶点的邻居节点更容易重叠,邻域之间也存在显著地重叠,引入一组双节点的聚类系数也作为特征提取。最后特征经过多核学习融合成一个混合核进行分类诊断。通过分类结果分析,显示基于sgLasso方法的多特征分类表现(87.88%)优于现有的关于超网络创建方法。由此暗示着不存在组结构或仅存在组结构,均不能得到令人满意的效果,若对组结构进行适当的扩展,则可获得更为有效的分类特征;同时,通过两组聚类系数选取的差异特征评估,多特征的分类权重均优于单组特征的分类权重。这表明基于多特征的方法有效地融合了两个不同的信息,可以更有效地分类抑郁症患者和正常对照组。
在目前的研究中,有两个主要的问题。首先,基于sgLasso方法中由于k中心点聚类法本身的影响,即初始种子点的随机选取以及k值的不同设置从而导致网络拓扑及分类结果不唯一,因此在未来的研究中可以采取不同的聚类方法来进行分组,以此建立更加稳定的超边来进一步改善超网络。其次,可以采用不同分配脑区的模板,探究不同模板创建的超网络对于分类性能的影响。
