面部运动单元检测研究综述
2020-03-06严经纬王春茂王保青
严经纬,李 强,王春茂,谢 迪,王保青,戴 骏
(杭州海康威视数字技术股份有限公司 研究院,杭州 310051)
0 引言
为了更精细地研究人类面部表情,美国著名情绪心理学家Ekman等[1]于1978年首次提出了面部运动编码系统(Facial Action Coding System, FACS),又于2002年作了重要改进[2]。基于FACS,各类表情可分解为一系列基础的面部肌肉运动的组合,从而进行后续的编码。Ekman等根据面部肌肉的解剖学情况,定义了32种面部肌肉运动单元(Action Unit, AU),图1所示分别为上半脸和下半脸中的几种常见AU及AU组合的示意图(http://www.cs.cmu.edu/~face/facs.htm)。从图1中可见,每个AU描述了面部某块特定肌肉或肌肉组的运动情况,如AU1表示通过额肌控制的内眉角上抬,AU5表示由眼轮匝肌控制的抬升眼睑等。本文所述的面部运动单元检测的目标即是让计算机在给定人脸图像或视频中自动判断目标AU是否存在,由于每种AU都经过严格的定义,该问题也可称为面部运动单元识别。此外值得注意的是,FACS中对每种AU定义了从A到E五个级别的强度(A最弱,E最强),本文仅关注定性的AU检测问题,对定量的AU强度回归技术不作涉及。
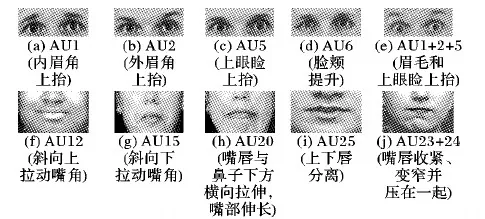
图1 上下半脸中若干常见AU的定义及示意图Fig. 1 Definiton and schematic diagram of some common AUs in upper and lower face
AU和面部表情的联系十分紧密,既可将表情分解为不同AU的组合,同样也可基于AU组合定义6种基本表情(愤怒、厌恶、恐惧、高兴、悲伤和惊讶)或更为复杂的复合表情(惊喜、苦笑等)。与面部纹理等媒介相比,从AU的角度出发分析面部表情更为直观且具有更强的可解释性,因此在人机交互领域,特别是在表情相关的任务上有着广泛的应用需求[3-4],例如在安防感知场景中通过AU识别群体的情绪,对突发事件进行警报;在公安刑侦或审讯过程中基于AU识别对方无意识显露的微表情,辅助相关人员判断其是否撒谎;在网络教育中通过摄像头捕捉学员呈现的面部AU,了解其对所授知识是否存疑。近年来随着大规模带有专家标注的面部运动单元数据库的建立和深度学习技术在AU检测领域的蓬勃发展,未来的应用场景和需求将会越来越多。
1 AU数据库
带有准确标注的AU数据库是开展AU检测研究工作的基础,本章介绍6个常用的AU数据库,分别为DISFA[5]、BP4D[6]、EmotioNet[7]、CFEE[8]、UNBC-McMaster肩痛表情[9]和CK+[10],各个AU数据库的概况总结如表1,按照常用程度的顺序依次介绍如下。
1)DISFA数据库。
丹佛大学自发面部运动单元数据库(Denver Intensity of Spontaneous Facial Action database, DISFA)[5]建立于2013年,采集了15位男性和12位女性,共27位被试的AU视频样本。被试坐着观看由YouTube上的9个片段拼接而成242 s的视频,每个片段激发一种情绪。在此过程中摄像机从正面采集被试的面部表情,被试所处环境如光照、背景等条件一致。视频样本分辨率为1 024×768,帧率为20 fps(frame/second),每位被试均采集4 845帧。2名FACS专家在数据库中每帧图像上标注了12种AU的起始和终止,同时按照0~5共6个级别标注了AU强度。
2)BP4D-Spontaneous数据库。
BP4D-Spontaneous[6]简称BP4D,由宾汉姆顿大学和匹兹堡大学合作建立,采集了18位男性和23位女性,共41位被试的视频样本。不同于直接观看视频激发情绪,BP4D采集过程中通过指导被试作8个任务激发相应的情绪,整个过程由专业演员主持,任务之间通过被试自评确定是否产生期望的情绪。数据集中包含每个任务对应的2D和3D视频,只保留表情显著的片段,每段平均时长1 min。对于每个视频中一段20 s表情最为丰富的片段,由2位FACS专家标注27种AU的起始和结束,同时对于AU12和AU14,按照0~5的级别标注强度。该数据库与DISFA是目前学术界使用最为广泛的两个AU检测基准数据库。
文献[11]又通过类似的方式(8个任务增加到10个任务,其余不变)采集了一批140人的数据库,大幅度扩展了样本规模,该数据库被称为BP4D+。除了视频数据外,BP4D+中还包括如血压、呼吸、心率、皮肤电等的生理信号,为多模态分析提供了便利。5位FACS专家标注了第1,6,7,8号任务中34个AU是否出现,且对其中5种AU标注了强度。
3)EmotioNet数据库。
俄亥俄州立大学Benitez-Quiroz等[7]于2016年建立的百万规模人脸表情数据库EmotioNet,图像均来自于互联网,相对于实验室场景中采集的数据,EmotioNet中的数据来自于自然场景,因此更加真实且接近实际应用场景。数据库分为训练集和测试集,其中测试集包含26 116张图像,通过FACS专家标注了12种AU是否出现,训练集有约95万张样本,由算法自动检测AU并标注,其检测准确率约为80%。由于训练集的AU标签中含有一定程度的噪声,EmotioNet被较多应用于弱监督学习中。
4)CFEE数据库。
该数据库是文献[8]在研究复合表情(Compound Facial Expressions of Emotion, CFEE)时建立,CFEE数据库由230位被试的正面面部图像构成,包括平静状态(中性)在内,共包括22种复杂的复合表情,如高兴的惊讶、怨恨、敬畏、惊骇等。FACS专家对每种表情标注了特定的AU。经统计,数据库中被标注的AU有19种。
5)UNBC-McMaster肩痛表情数据库。
UNBC-McMaster肩痛表情数据库[9]由25名患有肩痛的被试的视频数据构成,共200个视频序列,视频为正面拍摄,被试表情为肩痛过程中的自然流露。FACS专家对视频中的每一帧进行了10种AU强度标注。该数据库的最大特点是含有其他数据库中少见的与疼痛相关的AU43。
6)CK+数据库。
CK+数据库由CK(Cohn-Kanade)数据库扩展而来[10],大部分数据为黑白视频,少数为彩色视频。数据库中包含123位被试的593段表情视频,所有视频序列中的表情都是从平静到峰值程度。FACS专家对593段视频的峰值帧,即最后一帧进行标注,共标注了30种AU是否出现,其中大部分AU标注了强度。
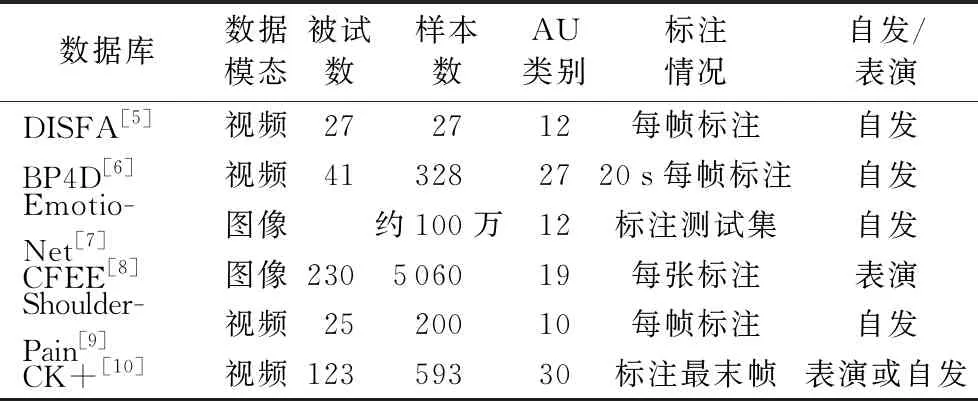
表1 AU数据库概况 Tab. 1 Profile of AU databases
2 传统AU检测方法
现有AU检测方法可简单分为传统方法和深度学习方法两大类,如图2所示,本章重点介绍传统的AU检测方法。
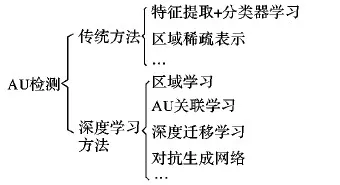
图2 AU检测方法Fig. 2 AU detection methods
传统AU检测方法一般可分为预处理、特征提取和分类器学习3个步骤,其中:1)预处理,主要包括人脸检测、关键点定位、人脸对齐、尺寸归一化等操作;2)特征提取或学习,即从人脸图像中提取或学习具有较强AU判别性的特征;3)分类器训练,即通过已获得的特征训练分类器检测AU是否出现。
在预处理阶段,目前可用的人脸检测和关键点定位模型有很多,例如人脸检测工具有Adaboost[12]、多任务级联卷积神经网络(Multi-Task Cascaded Convolutional Neural Network)[13]、DSFD(Dual Shot Face Detector)[14]等,关键点定位工具有主动外观模型(Active Appearance Model, AAM)[15]、循环形状回归(Recurrent Shape Regression, RSR)[16]等,这里不再赘述。
提取或学习与AU相关的具有强判别性的特征是AU检测的关键。传统AU检测方法的特征提取一般利用面部纹理特征[17]、几何特征[18]或两类特征的结合[19],即在面部关键点位置处提取纹理特征。与纹理特征相比,几何特征不会受到光照、肤色和人与人之间面部差异的影响,但受限于预处理中关键点定位的精度,且对于如AU14、AU15这种相对基准点几何位移较小的AU效果不佳,而面部纹理特征则不会受到这种限制。由于目前没有专门为AU检测设计的特征算子,所以通常借助于计算机视觉领域中人工定义的经典特征描述子,如图像中常用的局部特征算子尺度不变特征变换(Scale-Invariant Feature Transform, SIFT)、Haar、Gabor等,视频中常用的空时特征LBP-TOP(Local Binary Patterns on Three Orthogonal Planes)或光流特征[20]等。文献[21]在20个面部关键点处提取Gabor小波特征,并用Adaboost和支持向量机(Support Vector Machine, SVM)进行分类;文献[22]将45个面部关键点转换为Gabor小波系数,并使用稀疏表达模型(Sparse Representation, SR)分类;文献[23]将几何特征与局部Gabor小波特征融合,并基于核子类判别分析(Kernel Subclass Discriminant Analysis, KSDA)分类;文献[24]直接提取Haar特征作为AU的特征表达。
除直接提取特征外,为了获得更具判别性的AU相关特征,文献[25-26]中提出将人脸图像用均匀网格划分,基于每个区域对于AU的贡献进行选择或者加权,但这种简单的划分方式对于人脸姿态的变化并不鲁棒。文献[27]使用两层组稀疏在事先定义好的面部区域上进行AU编码;文献[28]通过面部关键点确定区域中心并提取SIFT特征,再使用组稀疏学习自动选择图像上与目标AU相关的区域所对应的特征。通过稀疏表达方法习得的特征判别性有一定程度的增强,然而选择出来的关键区域仍较为粗糙,无法习得像素级别的AU重要区域。
在分类阶段,传统AU检测方法中一般使用如支持向量机、K近邻(K-Nearest Neighbors,KNN)或稀疏表达模型等作为分类器。
上述方法大都使用人工设计特征描述子与传统模式识别领域中的分类器,近年来随着深度学习的兴起,基于深度学习的AU检测技术被广泛研究。一方面由于深度卷积网络能够习得与AU检测任务更相关的具有强判别性的特征;另一方面通过网络全连接层的输出可方便地解决多标签问题。当然传统方法与深度学习方法存在着密切的关联,很多在传统方法中使用的解决问题思路也常被应用在深度模型中。
3 基于深度学习的AU检测方法
近年来由于深度学习方法在计算机视觉、模式识别等诸多方向上取得的巨大成功,在AU检测领域,基于深度模型研究AU检测已成为主流,如文献[29]使用一个三层卷积一层全连接的浅层网络学习AU检测和AU强度判断;文献[30]中提出优化的卷积核尺度CNN(Optimized Filter Size CNN, OFS-CNN)模型建模AU识别问题,OFS-CNN中卷积核的尺寸和权重在训练过程中同步更新以适应不同的图像分辨率。本章内容主要以深度学习方法为主,同时在介绍一些通用问题时也将概述传统方法中的解决方案。
由AU的定义可知AU与面部肌肉是密切相关的,相比于其他物体检测任务,AU检测具有其特殊的性质。自从文献[31]于1996年首次展开AU检测研究以来,该领域发展至今一直存在两个研究重点被广泛关注,大量研究工作围绕这两个问题展开:1)如何更好地确定AU所在的关键面部区域并加以重点学习;2)如何更好地建模AU之间的相关性,通过习得的AU关联信息辅助提升整体检测性能。这两个问题逐渐抽象为两条研究路线:区域学习与AU关联学习,本章前两节将详细介绍这两个方向上的研究进展;同时,由于AU标注数据的稀缺性,近年来弱监督学习被引入解决这一问题,3.3节将介绍这一方向的相关工作。
3.1 区域学习
每个AU所在人脸区域的位置可由AU定义确定,对任意一个AU考虑其检测问题,显然并非所有面部区域对它是否出现都有贡献,若不考虑AU之间的关联,一般来说仅有其对应面部肌肉所在的几块稀疏的区域对它的检测是有贡献的,其他区域则不需要过多关注,因此找到那些需要关注的区域并加以重点学习才能更好地进行AU检测,专注于这一问题的解决方案一般被称为区域学习(Region Learning, RL)。
类似于传统方法中在AU中心处提取特征的做法,文献[32]基于面部关键点和AU领域的先验知识对每一个AU提前选择一个相关区域,并构造二值的掩膜,然后基于此区域和掩膜使用卷积神经网络和长短时记忆(Long Short-Term Memory, LSTM)网络进行学习,然而这种做法需要人工构造掩膜且检测性能依赖于掩膜的准确程度。
2016年Zhao等[33]首先提出深度区域和多标签学习(Deep Region and Multi-label Learning, DRML)框架,通过提出的区域层(Region Layer)自动学习与AU相关的重要面部区域,如图3所示,使得在各个区域习得的权重能够捕获面部的结构信息。该模型将区域层置于第一层卷积输出之后,首先用均匀网格将卷积特征映射图分块,在每块小区域上使用一组独立的卷积核学习该区域上与AU相关的特征,最后将各区域的特征映射图拼回原来的位置并与原始特征映射图相加,类似于深度残差网络中的残差结构。除区域层外,其他部分的网络结构类似于AlexNet,最后一个全连接层的节点数与目标AU个数相同,从而隐式地进行多标签学习,且可直接输出多个AU的检测结果。得益于像素级别的关键区域精度和多标签学习方式,DRML取得了超越传统方法及普通CNN模型的检测性能。
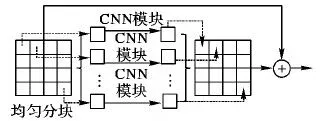
图3 区域层结构Fig. 3 Structure of region layer
沿袭这一思路继续改进的有文献[34]中提出的EAC-Net (Enhancing And Cropping Net),通过构造增强层(E-Net)和裁切层(C-Net)学习与AU更相关的面部区域。EAC-Net的基础网络架构为VGG- 19,在第2组和第3组卷积之后加上增强层,在第4组卷积之后加上裁切层。为了显式地限制网络需要重点学习的面部区域,增强层中人工构造了一种AU注意力映射图,该图由BP4D数据集中的12个AU定制而来,首先以数据库中给定的面部关键点坐标为基础,基于各AU所在面部肌肉位置选择与其最为邻近的关键点并进行一定的偏移修正,由此得到每个AU对应的中心点坐标,然后再基于各个中心点,将其分别扩展成大小为11×11的AU相关区域,并且在该区域内,点离中心的距离越远则其所在位置对应的权重越小,由此在深度模型中人为地引入AU所在位置的先验信息。
在裁切层中,类似于DRML中的区域学习,将上述定义的20个感兴趣的区域裁切出来后使用互相独立的卷积核学习AU相关特征,再通过全连接层进行特征融合并输出AU检测结果。相比于DRML,EAC-Net对关键区域进行了进一步的强化,通过关键点的先验知识引入AU所在面部区域,从而使网络更容易在关键区域学习AU相关的特征。
除了EAC-Net,类似地文献[35]在视频的AU检测任务中提出了感兴趣区域(Region Of Interest, ROI)裁切网络,同样使用面部关键点定位了20个与AU相关的ROI区域,然后对于每块感兴趣的区域使用独立的CNN进行学习,并使用LSTM推导出AU的标签。
进一步地,文献[36]于2018年提出联合的AU检测和人脸对齐框架JAA-Net(Joint AU detection and face alignment)。由于面部关键点与AU位置的密切关联,JAA-Net将面部关键点定位作为附加任务引入网络,与AU检测同步优化,以此促进AU检测性能的提升,JAA-Net的多任务网络结构如图4所示。JAA-Net中的初始注意力映射图通过网络输出的面部关键点位置构造,构造方法与EAC-Net相同,不同的是,EAC-Net中的注意力图是固定不变的,而JAA-Net中考虑了padding对AU检测结果的影响,在注意力图上通过上采样等操作进行优化。此外,不同于DRML和EAC-Net中只有一个尺度的区域学习,JAA-Net中使用了分层的多尺度区域学习,将卷积输出的特征映射图均匀分成8×8、4×4和2×2三种尺度,在三个尺度上对每块区域使用一组独立的卷积核进行学习,最后将每块的特征映射图拼回原来的位置,并将所有尺度的输出级联起来与原始特征映射图相加。目前JAA-Net是AU区域学习方向上表现最佳的网络,在BP4D和DISFA上均超越了EAC-Net和DRML的性能。
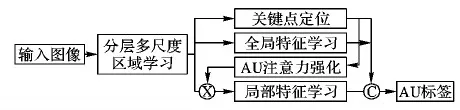
图4 JAA-Net框架Fig. 4 JAA-Net framework
3.2 AU关联学习
AU是在面部肌肉解剖学的基础上定义的,描述了一块或几块肌肉的运动,某些肌肉在运动过程中会牵动几个AU同时出现,因此AU之间存在一定程度的相关性。某些AU常常一同出现,而一些AU则无法同时出现[36]。显然,这些AU关联性信息会有助于模型检测性能的提升,因此如何挖掘AU之间的关联并基于相关性提升AU模型检测性能是另一个需要重点关注的问题[37]。
在传统方法中研究人员一般建立一个独立的关系模型描述AU之间的相关性,然后基于已预测的AU标签进行相关性推理,相当于对预测标签进行进一步的后处理,其优点在于:1)增大了一些难以直接从图像上检测到AU的被检概率;2)修正了一些基于图像或视频预测错误的AU,提升了检测模型的鲁棒性;但是由于关联模型的独立性和对预测标签后处理的方式,使这种建模方式无法影响前端的特征学习和检测过程。这类工作的典型代表有:文献[38]使用隐马尔可夫模型建模AU关联,并与SVM相结合。文献[39-41]中提出使用贝叶斯网络建模AU之间的关联,贝叶斯网络是用来表达一组变量之间的联合概率分布的一种有向无环图,首先通过分析AU数据库中两两AU出现概率分布以此构造初始贝叶斯网络,然后通过优化网络结构分数更新贝叶斯网络,从而得到更加准确的AU关联。文献[42]基于定性的先验知识和定量的数据通过Credal网络学习AU之间的关系。文献[43]使用三层受限玻尔兹曼机(Restricted Boltzmann Machine, RBM)挖掘AU之间的高阶相关性关系,与其他仅能学习两两AU之间关系的方法相比,RBM能习得全局的AU之间的相关性。类似的,文献[44]使用四层RBM学习全局的AU关联和AU检测与面部关键点定位之间的关联。
为了克服这种后处理模式带来的弊端,有研究人员将AU关联性学习与前端基于视觉特征的检测过程结合起来,作为一个整体同时进行优化,以此提升模型的整体性能。文献[45]在多任务中通过多核学习(Multiple Kernel Learning, MKL)方法同时学习更具判别性的面部特征表达和AU之间的关联。文献[46]基于多个条件隐变量模型同时融合面部特征和检测AU,在连续隐变量空间中,不需要AU之间的先验关系也能有效地在大量AU输出之间建模关联信息。文献[28]从数据库中统计同时存在和互斥的成对AU,即正相关和负相关的AU关系,然后构造关系正则项并加入目标表达式中一同优化,以此学习AU之间的关联。文献[36]基于一般性的领域知识将AU关联用有向图表达,在没有训练数据的前提下也能实现AU检测。上述方法大都直接使用传统计算机视觉中人工定义的底层特征描述子提取面部特征,导致AU关联学习与前端特征学习互相独立,在一定程度上仍然限制了模型的性能。
由于深度学习模型自身具有的端对端特性,直接在深度网络后端加入关联模型即可将特征学习、关联性学习和AU检测融为一个整体同时进行优化,进一步消除了上述方法的弊端。文献[47]将copula函数作为条件随机场(Conditional Random Field, CRF)的团学习AU之间的相关性,并将其与CNN联合迭代优化;类似的,文献[48]使用CRF-RNN建模AU之间的关系,而在3.1节所述的DRML、EAC-Net、ROI-Net和JAA-Net中,最后一层全连接均直接输出AU的多标签检测结果,即通过一层全连接网络学习各个AU之间的关联性,达到多标签学习的目的;然而仅通过一层全连接学习AU之间的关联性并不充分,近年来已有一些研究人员试图通过其他方法进行显式地建模。
文献[49]中提出深度结构推理网络(Deep Structure Inference Network, DSIN),使用类似于图模型推理的思路学习AU之间的关联,这里的结构信息即指AU之间的关联信息,其网络结构如图5所示。首先在输入图像的几个AU相关的关键区域切割出若干小图像块,经互相独立的CNN提取特征后输出AU的多标签概率,经全连接层融合之后,进入结构推理模块,该模块由一组互相连接的循环结构推理单元(Structure Interference Unit, SIU)构成,SIU如图6所示。
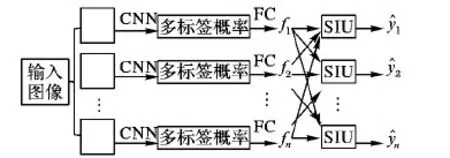
图5 深度结构推理网络Fig. 5 Deep structure inference network
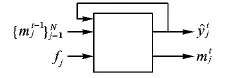
图6 结构推理单元Fig. 6 Structure interference unit
每个目标AU对应一个专门的SIU,以类似于RNN的方式循环更新AU标签。类似于LSTM中的元胞状态,SIU通过信息单元m存储其他所有AU的标签状态,由此接收其他AU的标签信息,通过迭代地更新m学习目标AU与其他AU之间的关联,同时每个AU的预测值也在不断迭代优化。假设目标AU个数为N,SIU实现了如下功能:
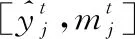
(1)
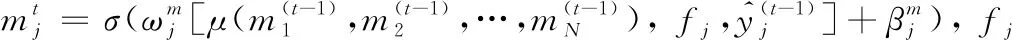
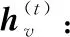
(2)
(3)
(4)
(5)
(6)
(7)
其中:Av是节点v的邻接矩阵;⊙为元素间点乘;W和U为需要学习的权重矩阵。由于每个节点在每一时刻均接收到其他节点的信息,因此在迭代过程中能够学习到AU之间的全局关联。在经过T轮迭代后,每个节点的输出为:
(8)
其中:xv为节点v的标注;g为全连接网络,由此可以得到各个目标AU的检测结果。经实验,SRERL超越DSIN,在BP4D和DISFA数据库上达到了目前最好的性能,具体性能对比见文献[50]。
3.3 结合弱监督学习
与其他计算机视觉领域中的任务一样,在AU检测任务中,无论是区域学习还是AU关联学习均依赖准确标注的AU数据,且基于深度学习的方法一般需要大量数据才能取得较好的检测性能。相比于在图像中框出人脸或者标注其中物体的标签,在一张人脸图像上辨别几十种AU是否出现乃至标注其强度对于普通的数据标定人员,甚至AU检测领域的专业研究人员而言,都是非常困难的,所以在建立AU数据库时一般需要邀请至少两名经过专业训练的FACS专家进行数据标注,从而保证数据标注的准确度,而即便如此也并非意味着所有AU标签完全正确,这些问题导致获得大规模有准确标注的AU数据的门槛很高且代价高昂,严重限制了AU检测技术的发展。另一方面,现实世界中存在海量的未标注过AU或者仅有不准确标注的人脸图像。为了充分利用这些易于获得的大规模数据提升AU检测性能,弱监督学习技术被引入AU检测任务中,希望借此改善AU准确标注数据严重不足的问题。近年来在各个顶级学术会议中出现了一批结合弱监督学习的AU检测研究,目前已逐渐成为AU检测领域内的主流研究方向。
文献[51]通过数据库中正确的AU标签学习AU分布,然后基于大量未标注数据最大化关于AU标签分布的log似然映射函数训练SVM分类器,由于该方法基于原始数据库中的AU分布,故对于分布不同的未标注数据性能有限;文献[52]为了让AU检测模型对数据库中的噪声标签鲁棒,提出一种全局-局部(Global-Local, GL)损失函数,在保证AU检测准确率的同时,模型能够快速收敛;文献[53]基于不准确AU标注的互联网人脸数据,提出一种弱监督谱聚类方法学习一个嵌入空间来耦合图像特征及其AU语义;文献[54]仅利用视频序列中标注的峰值帧,提出一种基于领域知识的半监督深度CNN模型回归AU强度;不同于文献[48],文献[55]将与数据库无关的AU先验概率分布与AU分类器损失函数相结合,实现了在无AU标注样本下的AU检测,取得了较高的性能。
此外由于生成对抗网络(Generative Adversarial Network, GAN)能够在一定程度上消除两组异质数据之间的差异[56],目前有部分研究人员关注于将其应用到AU检测任务中。文献[57]将对抗训练思路与弱监督学习结合起来,依靠AU先验知识和带有表情标签的数据训练AU检测模型,由此充分利用表情数据量大的优势解决AU检测问题。
4 存在的不足及潜在的发展
借助深度学习方法,面部运动单元检测技术在区域学习和AU关联学习等方面取得了长足的进步,模型的检测性能已大幅度超越传统方法,在公安刑侦、在线教育和社会感知等人机交互领域应用前景广泛。然而,现有的AU检测研究仍存在一些不足,这些不足也是未来的潜在发展方向。
1)大部分检测模型只能处理正面人脸的情况,对于非正面人脸性能下降严重,导致图像或视频在输入网络前需经过繁琐的预处理步骤,除了必要的人脸检测外,还需进行面部关键点定位和人脸对齐,在实际应用场景中影响整体检测速度。该问题的主因是目前非正面的人脸AU数据十分匮乏,此外非正面人脸上的AU特性与正面情况不同。未来需要从数据和算法两方面入手:一方面建立大规模的AU数据库,数据库内需要包含各种姿态、光照、遮挡、背景噪声等条件的AU数据;另一方面需要研究非正面AU的特点并建立非正面AU检测模型。
2)目前的AU检测研究局限于强度显著的AU,按照FACS的定义,AU强度由弱到强分为A、B、C、D、E五个级别,在文献的实验中往往使用强度大于B或C的样本作为正样本,其他强度视为负样本,对于弱强度AU检测研究还不多。由于弱强度AU与微表情紧密关联,可用于测谎等领域,所以是未来AU检测领域的一个发展趋势。
3)很多研究中通过引入注意力映射图强化AU的区域学习,而目前大部分注意力映射图需要人工根据目标AU所在位置进行事先定义,当数据库中AU种类有限时这一做法尚可行,但AU种类增多到一定程度则十分不便,需要研究自适应地学习AU注意力映射的方法。
5 结语
自1978年面部运动单元的概念被提出后,面部运动单元检测技术逐渐被越来越多的研究人员关注,并且在最近二十年来得到了蓬勃的发展。本文综述了面部运动单元检测中包括预处理、特征学习、分类器学习等各个环节的技术发展情况,着重总结了在AU区域学习、关联学习以及结合弱监督学习等AU检测方向利用深度学习技术取得的研究进展。未来面部运动单元检测技术将在大规模数据库的建立、区域学习和运动单元关联学习上继续发展,同时基于弱监督学习等方法的面部运动单元检测也将成为主流的研究方向之一。
