一种利用迁移学习训练卷积神经网络的声呐图像识别方法
2020-03-06朱兆彤付学志胡友峰
朱兆彤, 付学志, 胡友峰
一种利用迁移学习训练卷积神经网络的声呐图像识别方法
朱兆彤1, 付学志2, 胡友峰1
(1. 中国船舶重工集团公司 第705研究所, 陕西 西安, 710077, 2. 中国人民解放军92228部队, 北京, 102249)
针对利用传统训练方法进行声呐图像识别时缺乏数据的问题, 文中提出一种利用迁移学习训练卷积神经网络(CNN)实现声呐图像识别的方法。基于迁移学习的原理, 通过对已有的预训练网络进行微调与重新训练, 以减小对训练数据量的需求。随后利用缩比模型水池试验验证了该方法的有效性。试验结果表明, 基于AlexNet预训练网络, 相比传统的学习方法, 迁移学习方法可以利用较少的训练数据, 在较短的时间内通过训练达到95.81%的识别率。试验还对比了基于6种预训练网络进行迁移学习后的网络性能, 结果表明基于VGG16的迁移网络识别率最高, 可达到99.48%。最后, 试验结果验证了CNN具有一定的噪声容忍能力, 在较强噪声背景下, 能保证较高的识别率。
声呐成像; 目标自动识别; 卷积神经网络; 迁移学习
0 引言
声呐成像技术包括实孔径侧扫成像、实孔径多波束成像、合成孔径成像和逆合成孔径成像等技术, 目前已经可以在几百米距离上获取水中或水底目标的高分辨率二维图像。随着声呐成像技术的逐步成熟, 如何快速高效地处理获取的大量声呐成像数据就成为目前亟待解决的问题。为了解决这一问题, 水下目标自动识别(underwater automatic target recognition, UATR)成为了水下目标识别领域研究的热点方向。
传统的声呐图像自动识别方法可分为2类: 一类是基于实测数据的识别方法, 另一类是基于物理模型仿真获得数据的识别方法。2类方法通过实验或仿真手段获取声呐图像中目标的先验知识, 提取响应特征, 然后设计分类器进行分类。对于传统的识别方法, 为了达到较高的识别成功率, 通常需要精心选择提取的特征组合形式和各项特征的权重, 并调整分类器的参数[1], 因此限制了这些方法的泛化能力, 即当应用场景变化时, 这些方法的性能通常有较大幅度的下降。
随着人工智能技术在大数据时代的发展, 深度学习在图像分类、目标检测和自然语言处理等模式识别领域得到广泛应用。目前常见的深度学习方法包括深度置信网络(deep belief network, DBN)、卷积神经网络(convolutional neural net- work, CNN)及循环神经网络(recurrent neural net- work, RNN)等, 其中CNN是在计算机视觉领域应用最广泛的一种算法, 与声呐图像识别类似, 传统的光学图像识别方法通常也可分为特征提取和特征识别两步。在传统方法中, 特征提取方法通常都是基于研究目标的物理或统计特性手动设计的。然而在最新的计算机视觉研究中, 这些传统的识别模式已被CNN等全新算法所替代。CNN可以自动学习图像中丰富的分层特征[2-3], 近年来在光学图像识别领域取得了巨大的成功。Kri- zhevsky等[2]采用深度CNN算法在ImageNet大规模视觉识别挑战(Imagenet large scale visual re- cognition challenge, ILSVRC)竞赛中取得了top5错误率15.3%的成绩, 远远超过了以前最好的成绩。Szegedy等[4]提出了包含22个卷积层的Goo- gleNet, 成功地将ILSVRC top5错误率降低至6.67%。在ILSVRC竞赛中, 基于CNN的各种改进算法性能一直在提升, 目前错误率最低的算法由Hu等[5]提出, 已将top5错误率降低至2.25%。
随着CNN在光学图像识别领域的广泛应用, 这类方法也被尝试引入声呐图像处理领域。例如Mckay等[6]利用CNN实现了在声呐图像中对水雷目标的检测。但由于CNN的训练需要大量标注的图像数据, 而在声呐图像识别领域并没有一个这样的数据库, 因此CNN在声呐图像识别领域通常面临缺乏训练数据的问题。
针对这一问题, 文中在CNN的训练过程中引入迁移学习的方法, 可将神经网络从源领域学习到的知识迁移至目标领域。迁移学习方法已经在图像识别相关领域(例如雷达图像识别[7]及医学影像识别[8]等领域)获得了应用, 并成功地解决了训练数据缺乏的问题。通常, 源领域的知识是从一个较大的通用数据集学习到的, 而目标领域的知识则基于一个相对较小并聚焦于具体识别任务的数据集。通过引入利用大量光学图片训练得到的预训练网络作为基础, 迁移后的网络继承了原网络的结构和大部分参数, 只需要对原网络的最后几层进行调整, 迁移后的网络就能获得对特定领域数据的识别能力。这样的方法也被称为微调(fine-tuning), 微调不但可减小网络训练阶段的计算复杂度, 也可减少训练网络所需的数据量。
针对CNN在声呐图像识别领域获得应用的潜力, 文中首先简述了CNN的基本算法与利用迁移学习训练特定神经网络的方法; 随后通过试验对5类缩比模型目标进行声呐成像, 利用试验获取的声呐成像数据, 对比了基于CNN和传统非深度神经网络之间, 传统训练方法和基于迁移学习的训练方法之间, 基于6种预训练网络进行迁移学习后得到的网络之间的性能差异, 以及不同峰值信噪比条件下CNN的性能变化; 最后给出初步结论。
1 深度CNN与迁移学习
1.1 深度CNN
深度CNN是一类具有特殊结构的神经网络, “深度”则表明其层数较多, 通常超过15层, 整个网络的开始几层由卷积层(convolution layer)与池化层(pooling layer)交替构成, 之后若干层是全连接层。其基本原理是: 先由卷积层学习不同的特征, 再由池化层将空域形状汇聚到高维特征空间, 多层交替的卷积加池化可以学习到层次化的特征表征。最后由全连接层在高维特征空间中学习得到1个分类器。
如图1所示, 深度CNN中卷积层和池化层的所有节点都排列成一系列2维数组, 称为“特征图”。在卷积层中, 每个隐层节点的输入仅包含前1层中1个局部邻域内的节点。前1层处于局部邻域内的节点乘以1个权值矩阵, 再通过1个非线性激活函数“正则化线性单元”ReLU[9], 运算结果作为卷积层的节点输出值。每个隐层节点都可以被看作是1个特征检测器, 因为当其输入中出现它所代表的某种特征时, 该节点便有1个较大的响应值。同一个特征图上的全部节点被限制为共享相同的连接权值, 所以每个特征图在图像的不同位置检测同一种特征。由于局部连接和权值共享, 深度CNN中需要从数据中学习的独立参数个数大为减少。在接下来的池化层中, 每个池化层特征图对应于1个卷积层特征图。池化层的每个节点以相邻的前1个卷积层中1个局部邻域内的节点为输入, 然后进行下采样。通常进行下采样的方法是只保留1个局部邻域内所有节点的最大值, 而忽略其余的节点值。1个深度CNN包含许多对卷积层与池化层的组合。通过交替的卷积层和池化层获得图像从全局到细节的各种特征后, 深度CNN通过全连接层实现最后的分类结果输出。
深度CNN在业界所取得的巨大成功得益于: 1) 算法的改进; 2) 海量数据的获得; 3) 图形处理单元等高性能计算资源的普及, 而其中算法的改进是深度CNN出现飞跃式发展的关键因素。
1.2 基于迁移学习的声呐图像识别方法
1个CNN通常包含超过百万级别的参数, 而在声呐图像识别领域, 由于试验难度较大, 通常可供训练的图片总量只有几百到几千幅。利用这样少量的训练样本去训练巨大数量的参数容易造成网络的过拟合。如图2所示, 首先将CNN看作通用的图像特征提取器, 在某个数据集(如Ima- geNet)上进行预训练, 然后在目标数据集(如声呐图像试验数据)上进行复用。采用大量数据训练完成的CNN具备强大的、可泛化的图像特征提取能力, 可用于声呐图像的特征提取。

图1 深度卷积神经网络典型结构
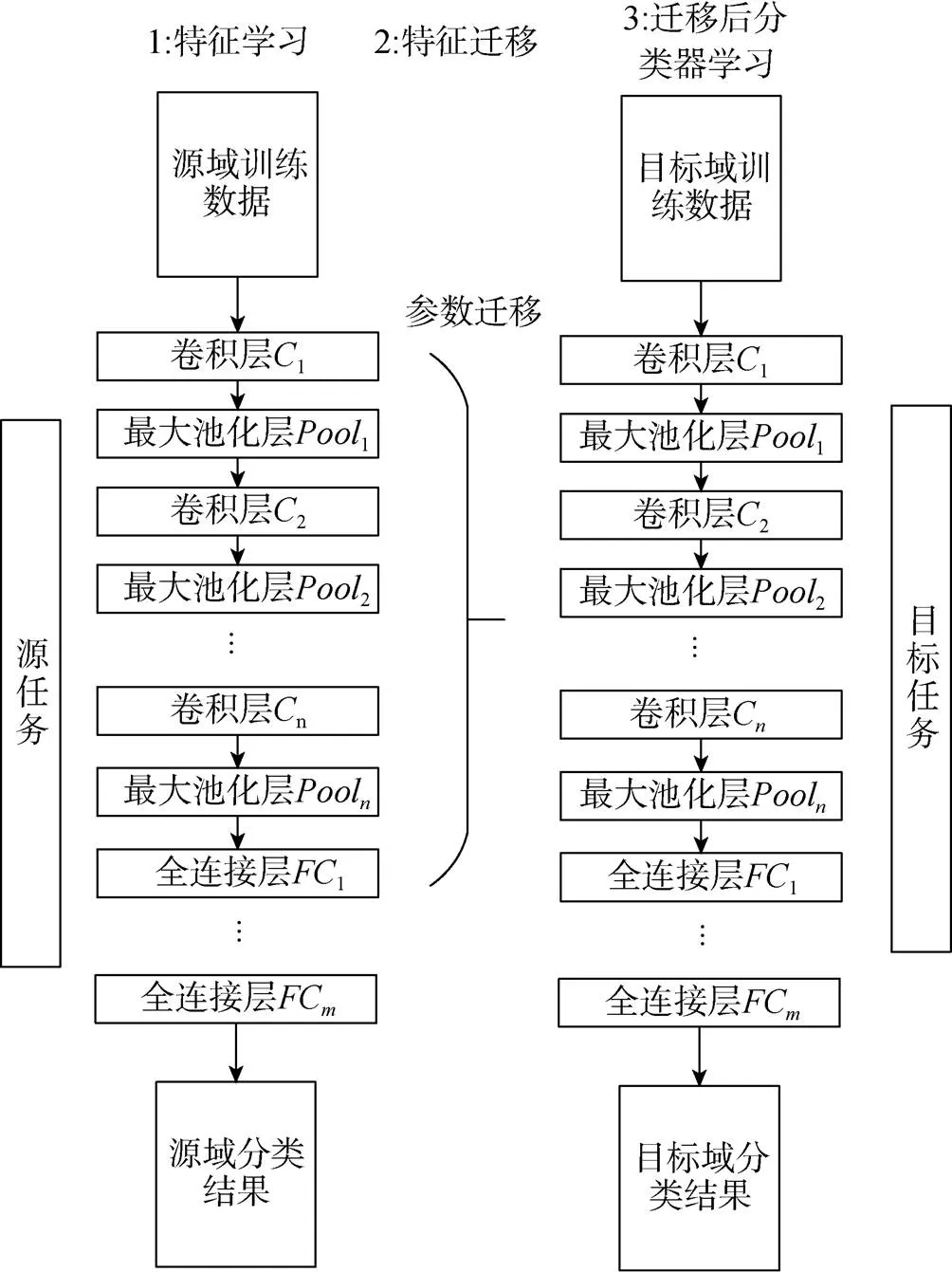
图2 迁移学习过程
利用迁移学习进行声呐图像识别的步骤包括: 1) 选择1个预训练网络, 通常该预训练网络是利用大量有标签的数据集训练得到的; 2) 将预训练网络中部分层的参数迁移至目标网络中; 3) 移除原网络中最后1个全连接层, 在迁移后的网络最后部分添加全连接层, 构成新的网络; 4) 利用目标域中有标签的数据训练新的网络, 完成整个网络的迁移。
2 声呐成像试验设计与成像结果
2.1 声呐成像试验设计
为验证文中提出的识别方法, 设计了水池试验进行验证。试验针对5类仿真潜艇模型利用水声转台成像方法分别进行成像。考虑到实际水下目标尺度较大, 故文中基于缩比模型的原理进行试验设计[10], 即将实际的水下目标最大长度缩小100倍至1 m左右。为了保持波长与目标尺寸之间的相对关系, 将换能器工作频率由成像声呐常用的20 kHz提升100倍至2 MHz, 带宽也相应提升至75 kHz, 此时, 试验声呐成像系统的分辨率可达到1 cm×1 cm(距离×方位, 下同), 相当于在实际系统中达到1 m×1 m的分辨率。为保证换能器波束完全覆盖模型, 成像距离依据模型实际尺度设置为9 m(模型尺度小于1 m)或12 m(模型尺度大于1 m), 此时, 设定转速为0.001 rad/s, 相当于潜艇以0.9 m/s(成像距离9 m)或1.2 m/s(成像距离12 m)的匀速低速巡航, 速度方向垂直于声呐视线向量, 脉冲重复频率为5 Hz。
搭建如图3所示的试验平台, 图中:,和分别为水池长度、宽度和深度;为换能器到转台的距离;为转轴到模型边缘的最大距离;为转台旋转角速度。模型通过金属杆连接至步进马达, 通过控制目标模型保持恒定转速。每种目标成像时转台均相对收发合置换能器由迎头方向转至追尾方向, 每种目标均保证连续转过180°。试验参数见表1, 试验详细描述参见文献[11]。
2.2 转台成像结果


图3 试验平台设计

表1 试验参数
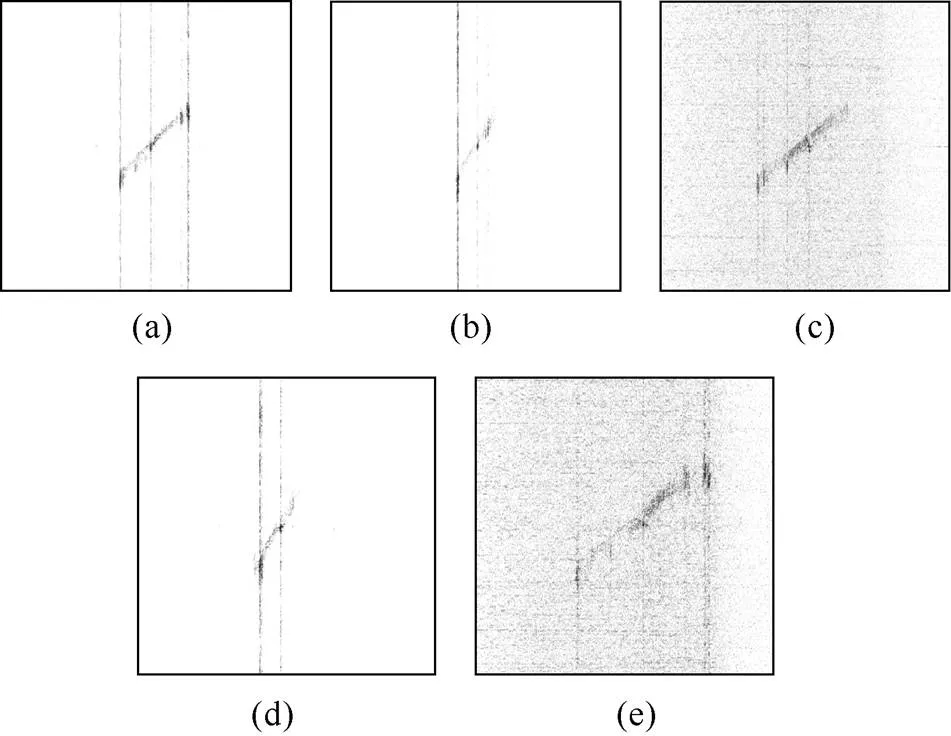
图4 5类试验模型典型成像结果
3 基于深度CNN的识别方法性能验证
3.1 深度CNN与非深度分类器性能对比
为了对比深度CNN与非深度网络之间性能差异, 文中引入支持向量机(support vector ma- chine, SVM)结合方向梯度直方图(histogram of oriented gradient, HOG)特征[12]的非深度分类方法。HOG是一种在计算机视觉和图像处理中用来进行物体检测的特征描述子, 它通过计算和统计图像局部区域的梯度方向直方图来构成特征。HOG特征结合SVM分类器已经被广泛应用于图像识别中。仿真试验分别对比了采用10%~100%的试验有效数据作为训练数据时2种分类器的性能, 试验结果如图5所示。

图5 不同训练样本条件下基于SVM+HOG与基于深度CNN的识别方法性能对比
相比于深度CNN, 基于SVM+HOG的方法可以在训练样本较少时有较好的识别性能, 然而当学习样本增加时, 基于SVM+HOG的方法由于可调参数较少, 当使用了50%左右的有效试验数据后, 分类器的性能就难以继续改善, 而深度神经网络的方法由于可调参数多, 因此采用的训练数据越多, 其性能越好。
3.2 迁移学习方法与非迁移学习方法性能对比
为了对比传统从初始状态开始训练网络的方法与基于迁移学习的训练识别方法之间训练速度与最终识别准确率的差异, 文中基于AlexNet预训练网络设计了对比试验。首先, 参照AlexNet网络结构设计了1个CNN, 其中仅将AlexNet最后1个全连接层的输出数目由1 000调整为5, 并用随机值初始化网络中所有参数的值; 随后用声呐图像数据训练该网络; 同时, 基于第2节中提出的迁移学习方法, 固定AlexNet预训练网络的权值, 仅对最后一个全连接层进行替换, 之后用声呐图像数据进行训练。试验结果如图6所示。

图6 传统方法与迁移学习方法训练过程对比
由图6可知, 由于声呐图像试验数据较少, 如果仅通过试验数据从头训练CNN, 将导致网络难以收敛, 经过4500个样本的训练后, 识别准确率仅能达到72.25%; 而如果采用迁移学习的方法, 在AlexNet的基础上进行迁移学习, 则可以达到95.81%的识别准确率, 同时分析迁移后神经网络收敛的过程, 可以发现在训练完2 000个样本后, 迁移后的网络识别准确率可以达到95%以上, 网络训练的时间可以大幅减少。
接受者操作特性(receiver operating character- ristic, ROC)曲线是一种反映分类器性能的指标, 可以反映分类器在对某一类目标进行区分时, 在给定的虚警率水平下能达到的正确识别率水平。通常, ROC曲线越靠近(0, 1)点, 说明分类器性能越好, 同时ROC曲线下面积(area under curve, AUC)则定量地说明了分类器对于每一类目标的识别性能。传统方法与基于迁移学习方法ROC曲线对比如图7所示。

图7 传统方法与迁移学习方法接受者操作特性对比曲线
3.3 不同预训练网络性能对比
为了对比不同预训练网络的识别性能, 选取AlexNet、GoogleNet、VGG16、VGG19、Resnet50和Resnet101等预训练网络进行对比。基于以上预训练网络进行迁移学习的结果如表2所示。
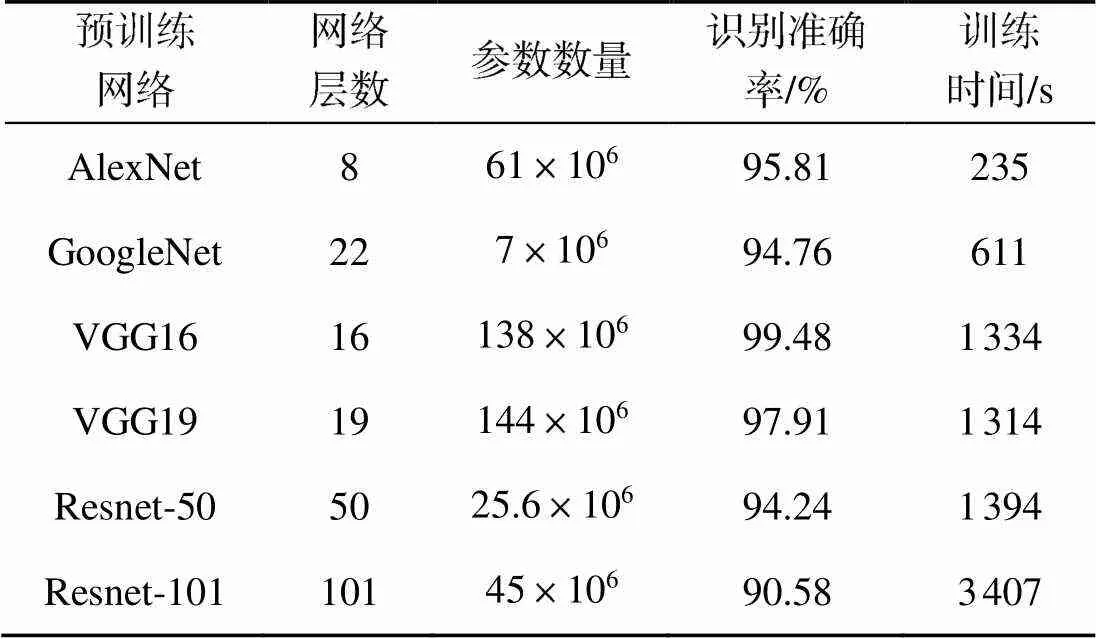
表2 不同预训练网络识别性能对比
由表2可知, 所有选用的预训练网络, 其识别准确率都达到了90%以上。其中, 利用VGG16完成训练的识别准确率最高, 达到99.48%, 完成训练时间为1334 s; AlexNet完成训练的时间最短, 为235 s, 同时也达到了95.81%的较高识别率。
3.4 不同信噪比条件下CNN性能对比
为了说明CNN对于噪声的容忍能力, 将训练图像和验证图像均叠加一定的加性高斯白噪声(additive white Gaussian noise, AWGN), 计算加噪后图像的峰值信噪比(peak signal-to-noise ratio, PSNR)并进行对比, 预训练网络采用AlexNet, 不同信噪比条件下分类器ROC曲线如图8所示, 识别率相对PSNR变化趋势如图9所示。
试验说明CNN具备较强的噪声容忍能力, 通常认为PSNR低于20 dB时, 图像质量已经很差, 然而在这样的条件下, 基于CNN的识别方法仍能保持90%以上的识别率, 说明基于CNN的识别方法具有较强的稳健性, 即使应用于实际系统中, 图像受到一定程度的干扰, CNN仍然具备较强的分类能力。
4 结束语
文中利用CNN和迁移学习技术, 提出了一种可用于声呐图像识别的新方法, 同时利用缩比模型转台成像的试验方法获得的声呐成像数据, 验证了所提方法的有效性。试验表明, 当可以获取一定量的试验数据时, CNN的分类性能将超过传统的SVM类方法。而利用迁移学习的方法, 相比传统将网络中所有权值进行随机初始化后开始训练的方法, 在训练数据量较小的情况下, 可以获得更高的识别率和更快的收敛速度, 在同样训练样本量的条件下, 最终识别的准确率提升了23.56%。然后对比了不同预训练网络进行迁移学习的训练时间与识别准确率的差别, 结果表明,利用VGG16作为预训练网络可获得99.48%的识别准确率, 完成训练时间为1334 s, 而AlexNet完成训练的时间最短为235 s, 识别率达到了95.81%。最后对比了在不同PSNR下, 基于CNN的分类方法性能变化情况, 结果表明, CNN具备较强的噪声容忍能力, 在PSNR低于20 dB的情况下, 识别率仍能保持90%以上。以上试验说明,基于迁移学习训练CNN的方法可以有效地对声呐图像进行分类识别, 并具备准确率高、训练数据需求较小、噪声容忍能力强的特点。


图9 识别率随PSNR变化曲线
[1] 朱兆彤, 彭石宝, 许稼, 等. 水下目标亮点拓扑特征提取及自动识别方法[J]. 声学学报, 2018, 43(2): 154-162.Zhu Zhao-tong, Peng Shi-bao, Xu Jia, et al. Multiple Highlights Topology Vector Feature Extraction and Au- tomatic Recognition Method for Underwater Target[J]. Acta Acustica, 2018, 43(2): 154-162.
[2] Krizhevsky A, Sutskever I, Hinton G E. ImageNet Classification with Deep Convolutional Neural Networks[J]Commu- nications of the ACM, 2017, 60(6): 84-90.
[3] He K, Zhang X, Ren S, et al. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification[C]//2015 IEEE International Conference on Computer Vision(ICCV). Santiago, Chile: IEEE, 2015: 1026-1034.
[4] Szegedy C, Liu W, Jia Y, et al. Going Deeper with Convolutions[C]//2015 IEEE Conference on Computer Vision and Pattern Recognition(CVPR). Boston, Massachusetts, USA: IEEE, 2015: 1-9.
[5] Hu J, Shen L, Sun G. Squeeze-and-Excitation Networks[EB/OL]. (2017-09-05)[2018-09-18]. http://adsabs. harvard.edu/abs/2017arXiv170901507H.
[6] McKay J, Gerg I, Monga V, et al. What's Mine is Yours: Pretrained CNNs for Limited Training Sonar ATR[C]// Oceans 2017-Anchorage. Alaska, USA: Oceans, 2017: 1-7.
[7] Gao F, Huang T, Wang J, et al. Dual-Branch Deep Con-volution Neural Network for Polarimetric SAR Image Classification[J]. Applied Sciences, 2017, 7(5): 447-465.
[8] Huang Z, Pan Z, Lei B. Transfer Learning with Deep Convolutional Neural Network for SAR Target Classification with Limited Labeled Data[J]. Remote Sensing, 2017(9): 907-927.
[9] Glorot X, Bordes A, Bengio Y. Deep Sparse Rectifier Neural Networks[C]//International Conference on Artificial Intelligence and Statistics. Ft. Lauderdale, UK, 2011: 315-323.
[10] 卢建斌, 张云雷, 席泽敏, 等. 基于统计特征的水下目标一维距离像识别方法研究[J]. 声学技术, 2015, 34(2): 121-126.Jianbin Lu, Yunlei Zhang, Zemin Xi et al., Research on underwater target recognition with statistical features of high resolution range profiles [J]. Technical Acoustics, 2015, 34(2): 121-126.
[11] 闫慧辰, 彭石宝, 许稼, 等. 水下旋转目标缩比声纳成像方法及系统: CN104297756A[P]. 2014-10-09.
A Sonar Image Recognition Method Based on Convolutional Neural Network Trained through Transfer Learning
ZHU Zhao-tong, FU Xue-zhi,HU You-feng
(1. The 705 Research Institute, China Shipbuilding Industry Corporation, Xi’an 710077, China, 2. 92228thUnit, the People’s Liberation Army of China, Beijing, 102249)
A sonar image recognition method using convolutional neural network trained by transfer learning is proposed aiming at the data shortage problem in making use of conventional training method for sonar image recognition. Based on the principle of transfer learning, the existing pre-trained network is fine-tuned and retrained to reduce the demand for training data. Pool experiment of the scale model verifies the effectiveness of this method. Experimental results show that, on the basis of AlexNet pre-trained network, the transfer learning method uses less training data compared with the conventional learning method, and achieves a recognition rate of 95.81% in a short time. The experiment also compares the performance of the network after the transfer learning based on six kinds of pre-trained networks, and the result shows that the recognition rate of the transfer network based on VGG16 is the highest, which can reach 99.48%. It is verified that the deeply convolutional neural network has certain noise tolerance ability, and can ensure a high recognition rate in the background of strong noise.
sonar imaging; automatic target recognition; convolutional neural network; transfer learning
相关文章导航
1. 赵国贵, 梁红, 陆禹, 等. 基于多参量联合特征的水下小目标分类识别[J]. 水下无人系统学报, 2019, 27(6).
2. 杜雪, 廖泓舟, 张勋. 基于深度卷积特征的水下目标智能识别方法[J]. 水下无人系统学报, 2019, 27(3).
3. 李磊, 杜度, 陈科. 基于改进生物启发模型的UUV在线避障方法[J]. 水下无人系统学报, 2019, 27(3).
4. 杜度. 基于RBF神经网络参数自整定的AUV深度控制[J]. 水下无人系统学报, 2019, 27(3).
5. 王明亮, 李德隆, 林扬, 等. 基于能量优化的AUV舵角解耦方法[J]. 水下无人系统学报, 2019, 27(3).
6. 杨管金子, 李建辰, 黄海, 国琳娜. 基于主惯导参数特性的传递对准调平方法[J]. 水下无人系统学报, 2018, 26(6).
7. 段杰, 李辉, 陈自立, 等. 基于RBF与OS-ELM神经网络的AUV传感器在线故障诊断[J]. 水下无人系 统学报,2018, 26(2).
8. 何心怡, 高贺, 卢军, 等. 逆合成孔径成像在鱼雷真假目标识别中的应用及展望[J]. 水下无人系统学报, 2017,25(4).
9. 温志文, 杨春武, 蔡卫军, 等. 复杂环境下UUV完全遍历路径规划方法[J]. 鱼雷技术, 2017, 25(1).
10. 吴亚军, 毛昭勇. 小波神经网络多传感器信息融合在AUV深度测量中的应用[J]. 鱼雷技术, 2016, 24(4).
11. 何心怡, 高贺, 陈菁, 等. 鱼雷真假目标识别技术现状与展望[J]. 鱼雷技术, 2016, 24(1).
12. 张远彪, 朱三文. 有缺陷的多接收阵合成孔径声呐成像技术[J]. 鱼雷技术, 2015, 23(4).
13. 范若楠, 曾进, 任庆生, 等. 基于神经网络响应面的鱼雷总体性能参数仿真优化方法[J]. 鱼雷技术, 2015, 23(5).
TB566; TN911.73
A
2096-3920(2020)01-0089-08
10.11993/j.issn.2096-3920.2020.01.013
朱兆彤, 付学志, 胡友峰. 一种利用迁移学习训练卷积神经网络的声呐图像识别方法[J]. 水下无人系统学报, 2020, 28(1): 89-96.
2019-01-16;
2019-05-26.
中国船舶重工集团公司第七〇五研究所博士后基金资助项目; 陕西省博士后科研项目资助(2017BSHQYXMZZ04).
朱兆彤(1988-), 男, 博士, 工程师, 主要研究方向为声呐成像与目标识别.
(责任编辑: 陈 曦)
