基于改进DeepLabv3+的无人车夜间红外图像语义分割
2020-03-05刘致驿孙韶媛任正云刘训华卜德飞
刘致驿,孙韶媛,任正云,刘训华,卜德飞
(1.东华大学 信息科学与技术学院,上海 201620;2.东华大学 数字化纺织服装技术教育部工程研究中心,上海 201620)
引言
图像语义分割将图像中每一个像素分类到其所属的语义类别,其在无人车应用领域对场景理解具有重要意义。目前的语义分割算法多针对于白天的可见光图像,针对夜间场景的语义分割研究较少。夜视红外图像由红外热像仪获取,具有无色彩、纹理简单、对比度和信噪比低的特点,因此分割难度较大[1]。
随着完全卷积网络(fully convolutional networks,FCN)[2]的提出,形成了大量语义分割的网络模型。空洞卷积(dilated convolutions)[3]允许网络在扩大感受野的同时不对原特征图降采样,保留空间信息。编码器-解码器架构(Encode-Decode)旨在将Encode 模块的信息加入Decode 模块中,引入上下文信息(如SegNet[4]、U-Net[5]、RefineNet[6]等)。空间金字塔模块实现了拥有不同感受野的特征图的提取和融合,引入多尺度信息(如PSPNet[7]、DeepLabv2[8]、DeepLabv3[7]等)。条件随机场(conditional random field, CRF)预测更为精确的目标边界信息(如DeepLabv1[7]、DeepLabv2 等)。近期的DeepLabv3+[9]使用基于深度分离卷积(Depthwise convolutions)的Xception[10]作为基网络,并引入空洞卷积空间金字塔模块(atrous spatial pyramid Pooling, ASPP),同时加入简单高效的Decode 模块,达到了目前最先进的分割效果。
本文以DeepLabv3+网络为基础,提出了一种基于改进DeepLabv3+网络的无人车夜间红外图像语义分割算法。考虑到自动驾驶场景中的对象往往显示出非常大的尺度变化,通过重构DeepLabv3+中ASPP 模块,以密集连接的方式编码多尺度特征信息,获得更大和更密集的特征尺度范围,并控制其参数量,使得改进后的网络在速度上与DeepLabv3+基本保持一致。此外,本文在Decode 模块中加入了更多的上下文信息来改善分割的结果。
1 网络结构
1.1 DeepLabv3+网络结构
DeepLabv3+将DeepLabv3 作为网络的Encode模块,其包括基网络的特征提取、级联和并联的具有不同空洞速率的空洞卷积层。在级联模式下,上层的空洞卷积接受下层的空洞卷积的结果,因此能产生更大的感受野。并联模式也称为ASPP模块,它接受基网络提取的高级特征图作为输入,经过具有不同空洞速率的空洞卷积,最后将结果融合,达到覆盖多尺度感受野的目的。假设表示卷积核大小为k、空洞速率为r的卷积操作,则DeepLabv3+中的ASPP 模块可表示为

同时DeepLabv3+实现了对基网络的更新,将Xception 用于语义分割,提升了网络性能;另一方面,DeepLabv3+引入了简单高效的译码器模块,将其中一层的Encode 模块的特征图拼接到对应大小的上采样结果中,进一步改善了分割效果。
DeepLabv3+网络结构如图1 所示。基网络和ASPP 模块共同构成网络的Encode 模块,输入任意大小的图像,可得到对应的高级特征图,再通过双线性插值上采样与Encode 模块其中一层的低级特征图进行融合构成网络的Decode 模块,最后上采样回原图大小,经过Softmax 分类层得到对应的分割图。值得一提的是,DeepLabv3+将改进后的Xception 作为基网络,并在基网络中实现了串行的ASPP 模块,同时通过空洞卷积控制降采样系数,提升了网络的性能。整个网络采用逐像素的交叉熵损失作为损失函数,对于每个像素x,Softmax 分类器的输出为
其中:x为二维平面上的像素位置;K为总类别数;αk(x)表示Softmax 输出的像素x对应的第k个通道的值;pk(x)表示像素x属于第k类的概率。于是整个网络的损失可表示为

其中:wl为类别l的损失权重;pl(x)为像素x属于真实类别l的概率。

图1 DeepLabv3+网络结构Fig.1 Structure diagram of DeepLabv3+ network
1.2 改进DeepLabv3+网络
本文以DeepLabv3+网络结构为基础,通过密集连接的方式重构了网络ASPP 模块,同时借鉴UNet 等经典Encode-Decode 结构,将Encode 模块的多层结果特征图拼接到Decode 模块中。整体网络结构图如图2 所示。

图2 改进DeepLabv3+网络结构图Fig.2 Structure diagram of improved DeepLabv3+ network
1.2.1 密集连接的ASPP
受DenseNet 的启发,本文重构了DeepLabv3+的ASPP 模块,以密集连接的方式获取更密集的特征金字塔和更大的感受野,更密集的特征金字塔主要体现在更密集的感受野范围和更密集的像素提取两个方面。
空洞卷积首次在DeepLabv2 引入,用来在不改变特征图分辨率的同时扩大感受野。在一维情况下,对于输出信号y和输入信号x,空洞卷积的操作可描述如下:

式中:r表示空洞速率;w(k)是滤波器第k个位置的参数;K表示滤波器的尺寸。空洞卷积相当于在卷积核的两个值之间插入(r-1)个零,因此它扩大了感受野,且r值越大,感受野越大。对于一个卷积核大小为k、空洞速率为r的空洞卷积,它所能提供的感受野大小为

而两层级联的空洞卷积层可提供的感受野大小为

式中:R1、R2分别为相邻两层空洞卷积所提供的感受野,因此密集连接的ASPP 所提供的感受野范围如图3 所示。

图3 密集连接ASPP 感受野范围Fig.3 Receptive field range of densely connected ASPP
另一方面,与DeepLabv3+中ASPP 模块相比,密集连接的ASPP 在计算时可以得到更多的像素。由于空洞的存在,空洞卷积比起标准卷积像素采样更为稀疏。图4(a)显示了一维空洞卷积层,其空洞速率为6,感受野为13。然而,在这个大的卷积核中,只有3 个像素被采样来进行计算,这种现象在二维情况下会变得更糟,虽然获得了很大的感受野,但在计算过程中却丢失了大量的信息。
在密集连接ASPP 中,空洞速率逐层增加,上层卷积利用下层的特征使像素采样更密集。图4(b)说明了这个过程:空洞速率为3 的卷积层被置于空洞速率为6 的卷积层之下,这样对于空洞速率为6 的卷积层,有7 个像素参与计算,其密度比原来的3 个像素高。在二维情况下,49 个像素参与计算,而在单层的空洞卷积中,只有9 个像素参与计算,如图4(c)所示。因此,通过密集连接的方式,具有较大空洞速率的卷积层可以从较小空洞速率的卷积层中获得帮助,并以更密集的方式对像素进行采样。

图4 空洞卷积采样Fig.4 Sampling of cavity convolutions
密集连接的ASPP 的另一个优势是能提供更大的感受野。以空洞速率(6, 12, 18)为例,遵循(6)式,假设表示卷积核大小为k、空洞速率为r的卷积所能提供的感受野,那么普通ASPP 的最大感受野可表示为

而密集连接的ASPP 的最大感受野为

尽管密集连接的ASPP 能获得更密集的特征金字塔和更大的感受野,但是它必然会伴随着网络参数量的增加,这对实时性非常不利。因此,本文在密集连接的ASPP 中的每个空洞卷积之前使用1×1 的卷积将特征维度降为输入特征图的一半来降低网络参数量,同时1×1 卷积也能为网络增加更多的非线性因素。
假设每个空洞卷积的输出特征维度为n,密集连接的ASPP 模块的输入特征维度为c0,cl表示第l个空洞卷积之前1×1 卷积的输入特征图的特征维度,则有

本文使用Xception-65 作为基网络,其输出的高级特征图的特征维度c0为2 048,ASPP 模块输出特征图的特征维度n为256,因此,本文ASPP 模块的参数量可计算如下:式中:K为空洞卷积的卷积核的大小;L为空洞卷积的总个数。在DeepLabv3+中,ASPP 模块的参数量为

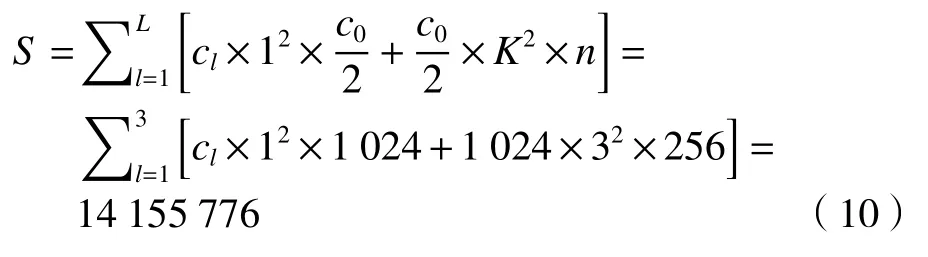
由此可见,本文重构的ASPP 模块在获得更密集的特征金字塔和更大的感受野的同时,合理地控制网络参数与DeepLabv3+中的ASPP 模块保持一致。
1.2.2 Decode
对于Decode 模块,本文在DeepLabv3+基础上引入了更多层的来自Encode 模块的低级特征图,如图2 所示。具体来说,本文使用基网络中降采样系数分别为1/4、1/8 和1/16 的低级特征图,先通过两层额外的3×3 卷积提取特征和一层1×1 卷积将特征维度降为21,再引入Decode 模块,降维的目的是因为我们希望在分割时网络的高级特征图能够对分割的结果起到更大的作用。
2 实验过程及结果分析
2.1 实验配置和数据
本文算法基于Tensorflow 框架,实验硬件配置为处理器Intel i5-6600,内存8 GB,显卡NVIDIA GTX1070,操作系统Ubuntu16.04。实验数据来自车载红外热像仪采集的视频,通过对视频抽帧筛选出900 张图像作为网络的训练集和300 张图像作为测试集,图片尺寸为480×360 像素。使用LabelMe工具标注图像,得到对应的标签图。本文数据集标有天空、道路、草地、树木、建筑、标志物、车辆和行人共8 类。
2.2 实验流程和评价指标
将训练集及对应的标签图生成为适合Tensorflow输入的Tfrecord 文件,输入改进DeepLabv3+网络进行迭代训练,模型收敛后输入测试集得到语义分割的结果,实验流程图如图5 所示。
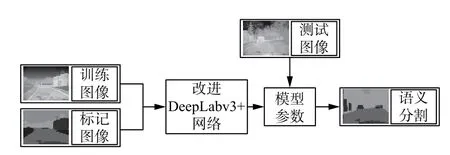
图5 实验流程图Fig.5 Flow chart of experiment
语义分割评价指标通常有3 种。假设nc为总类别数,nij表示实际类别为i、被预测类别为j的像素数量,为类i的像素总数,为总像素数量,则有
2)类平均像素精度(mean pixel accuracy, MPA)为;
3)平均交并比(mean intersection over union,MIoU)为
其中MIoU 为真实值与预测值的交集比并集,通常为语义分割最终的评价标准。
2.3 实验结果与分析
2.3.1 ASPP 模块实验
为了验证密集连接ASPP 模块的效果,本文通过在原DeepLabv3+的基础上构建具有不同空洞速率的密集连接ASPP 模块对红外数据集进行分割,结果见表1。可以看出,尽管当使用密集连接ASPP(6, 12, 18, 24)时分割精度最佳,但其在分割一幅图像的时间上比原网络多出了近1/3 的时间,因此本文选用密集连接ASPP(6, 12, 18)。

表1 ASPP 模块实验结果Table 1 Results of ASPP
2.3.2 Decode 模块实验
表2 显示了以密集连接ASPP(6,12,18)为基础,Decode 模块中不同低级特征图加入时对分割结果的影响。当选用降采样系数为1/4、1/8、1/16的特征图均以48 维加入到Decode 模块中时,分割精度反而大幅下降,这是因为大量的低级特征图的加入大大减少了ASPP 模块输出的高级特征图的占比,因此本文选用降采样系数为1/4、1/8、1/16 的特征图并控制其降维通道数为21 维。

表2 Decode 模块实验结果Table 2 Results of decode
2.3.3 红外数据集实验结果与分析
部分实验结果如图6 所示,尽管由于人工标记的粗糙,真实标签里存在少量漏标或错标的像素,但是本文算法仍能对图像实现较为准确的分割,具有良好的鲁棒性。图7 显示了本文算法与DeepLabv3+算法和同类型网络PSPNet 结果的比较,可以看出本文算法在各个类别都有不同程度的提升。将测试数据输入训练好的模型,并计算得到PA(像素精度)、MPA(均像素精度)、MIoU(均交并比)和单幅图像预测时间这4 个评价指标,结果见表3。可以看出,本文的算法较DeepLabv3+在速度上基本持平,但预测效果更好。表4 显示了每个类别的像素精度比较,尽管本文算法拥有更好的结果,但它们的共同问题是对于数据集内本身占比较少的类别,预测的精度不高。据统计,行人仅占1.65%,标志物仅占1.63%,因此后续工作除了进一步改善标记质量之外,还需增加这两类的数据进行训练。

图6 本文算法结果Fig.6 Results of proposed algorithm

图7 算法结果比较Fig.7 Comparisons of algorithmic results

表3 评价指标结果Table 3 Results of evaluation indicators

表4 各类像素精度比较Table 4 Comparison of different kinds of pixel accuracy
2.3.4 可见光数据集实验结果与分析
选用来自PASCAL VOC 2012 的可见光数据集验证本文算法在白天场景下的分割效果。数据集共2 913 张图像,其中训练集1 464 张,测试集1 449张,共20 类。同时加入PSPNet 和DeepLabv3+的结果进行比较,表5 显示了这3 种算法的指标对比,部分实验结果对比如图8 所示。由此可见,本文算法在白天场景也能实现较好的分割效果。

表5 评价指标结果Table 5 Results of evaluation indicators

图8 算法结果比较Fig.8 Comparisons of Algorithmic Results
3 结论
本文基于无人车夜视场景,提出了改进的DeepLabv3+网络,实现了对该场景下获取的红外图像的语义分割。根据无人车夜视场景下目标尺度范围较大的特点,引入密集连接的ASPP 模块实现更密集和更大的多尺度信息的编码并控制其参数量,同时引入多层低级特征图与Encode 模块输出的高级特征图进行融合。该方法在不牺牲速度的情况下,能达到比DeepLabv3+更好的分割效果,具有良好的实时性和准确性。
