基于红外和可见光图像逐级自适应融合的场景深度估计
2020-03-05李宇琦赵海涛
李宇琦,赵海涛
(华东理工大学 信息科学与工程学院,上海 200237)
引言
深度估计是计算机视觉研究领域中一个至关重要的问题[1-4]。它主要研究如何从二维图像中恢复场景的深度信息,这种深度信息有助于理解物体与周围环境之间的几何关系,在提升无人车驾驶安全性[2]和机器人[3]等方面有重要的应用。
目前对深度估计的研究大多数是以可见光图像作为输入。这些研究中,传统方法通常需要提取手工特征[5-6]。随着卷积神经网络(convolutional neural network, CNN)的发展,越来越多基于CNN的深度估计方法[2,7-8]被提出。Eigen 等学者[7]提出了第一个基于CNN 的深度估计方法,该方法先对输入图像进行深度图的粗预测,然后对粗预测进一步精细化得到最终的深度图。Li 等学者[8]提出了一个深度CNN 来获得可见光图像的深度图,然后使用条件随机场精细化深度图。然而可见光图像对光照的变化十分敏感,在光强很低的情况下很难提取出有效的特征。
针对可见光图像对场景中光照条件的限制,很多学者提出使用红外图像来进行场景的深度估计[1,9-10]。Sun 等学者[9]提出了基于核主成分分析(kernel principal component analysis, KPCA)和全连接神经网络的方法,该方法首先使用KPCA 提取出适用于红外图像的非线性特征,然后利用该特征和真实深度标签训练神经网络。Xi 等学者[10]提出了基于多尺度和空间上下文的特征提取方法,然后通过独立成分分析来选择适合于深度估计任务的红外特征,最后使用支持向量回归来估计深度。由于红外图像缺乏纹理信息,对比度低,因此单独使用红外图像作为输入得到的深度图边缘不清晰,准确率不高。
通过以上分析可知,基于单一类型传感器进行深度估计很难在任何光照下都得到理想的结果,因此很多图像融合的方法被提出[11-12]。Prabhakar等学者[11]提出了利用CNN 融合两种图像的亮度通道,利用加权平均融合策略融合色度通道,最后将各个通道融合结果相加。现有的图像融合方法中大多是将两种图像特征等权重相加,没有考虑不同类型图像对不同场景深度估计的不同贡献。与此同时,普遍认为较深层的特征可提取全局上下文信息,而较浅层的特征可提取更多的空间细节信息,现有的图像融合方法只在最后一层卷积后进行融合,忽视了浅层卷积特征对深度估计的作用。
针对以上问题,本文提出了基于红外和可见光图像逐级自适应融合的深度估计方法(progressively fusion convolution neural network of infrared and visible light images, PF-CNN),自适应地融合不同卷积层下两种图像的特征,并逐级学习各层融合特征的结合以获得具有更多细节信息的深度图。该方法包含3 个部分,双流滤波器部分耦合卷积神经网络(two-stream filter coupled network, TFCNet),自适应多模态特征融合网络(adaptive multi-model feature fusion network, AMFNet)和自适应逐级特征融合网络(adaptive progressively feature fusion network,APFNet)。受文献[13]启发,滤波器在TFCNet 中部分耦合以学习红外和可见光图像之间的非线性转换,使两者特征进一步增强。AMFNet 中利用残差密集块提取两种图像的残差特征[14],同时设计自适应加权融合的方法将不同卷积层中两种图像的特征进行融合,充分考虑了两种图像对场景深度估计时的不同贡献。APFNet 利用自适应加权融合方法学习多级融合特征,充分考虑到不同卷积层的特征对深度估计的不同作用。
1 网络结构
下面介绍基于红外和可见光图像逐级融合的深度估计方法,该方法的网络示意图如图1 所示。
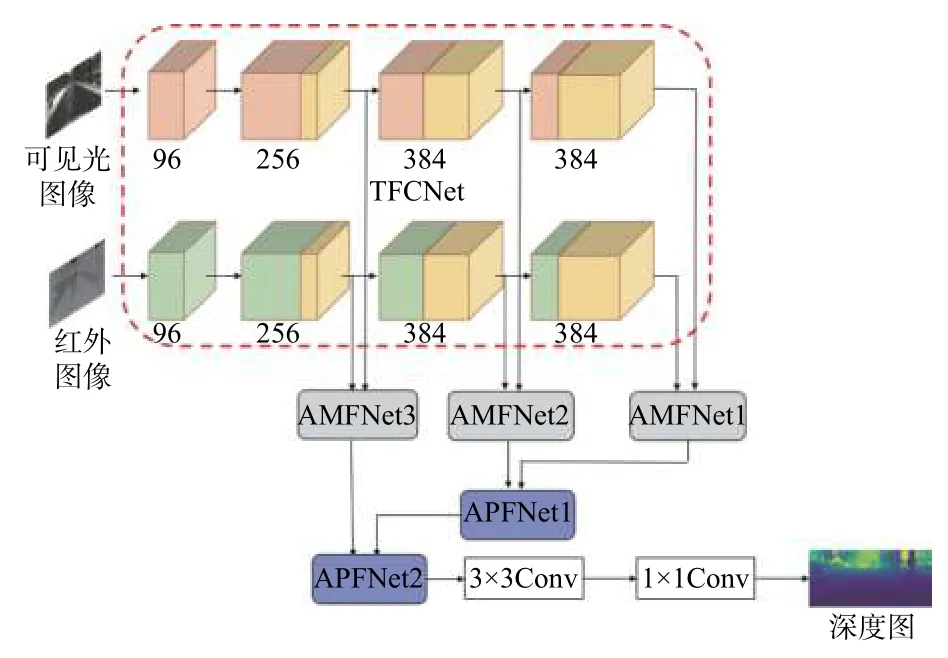
图1 网络结构图(PF-CNN)Fig.1 Structure diagram of network (PF-CNN)
1.1 双流滤波器部分耦合卷积神经网络
如前所述,单一类型的图像包含的信息不充分,导致估计的深度图不精确,因此本文提出的PF-CNN 采用将红外和可见光图像同时作为输入的双流卷积神经网络。由于每一对红外和可见光图像表示同一场景的不同类型图像,所以两者之间存在相关性。Wang 等学者[13]认为有一定相关性的两种特征可以通过滤波器耦合来相互表示和转换。然而,即使经过十分复杂的操作,也不是所有的红外和可见光图像的特征都可以相互转换。
基于以上分析,本文设计了双流滤波器部分耦合卷积神经网络(TFCNet),如图1 红色虚线框中所示,每一束卷积流都采用AlexNet 作为基础网络框架。在TFCNet 中,红外图像和其对应的可见光图像分别作为输入,不同于传统的双流CNN,TFCNet在每一层卷积中都将两种图像的滤波器部分耦合。如图1 所示,滤波器分为3 个部分:绿色部分为提取红外特征的滤波器,红色部分为提取可见光特征的滤波器,黄色部分为两者部分耦合的滤波器。耦合的滤波器既要提取红外图像的特征,也要提取可见光图像的特征。通过滤波器部分耦合的方式可以将红外和可见光图像视为彼此的“辅助变量”。红外图像可以帮助可见光图像捕捉到在光线较暗情况下难以提取到的有辨别力的特征,可见光图像可以帮助红外图像中提取到更多细节信息。非耦合滤波器学习两种图像各自的特征。各层中耦合滤波器的数量与滤波器总数的比值被称为耦合率:
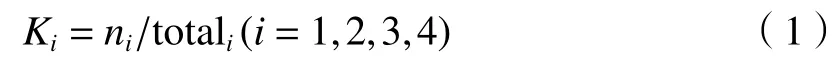
式中:Ki为第i层的耦合率;ni是第i层耦合滤波器的数量;totali为第i层滤波器的总数。耦合率都采用网格搜索法来设定,从最后一层卷积开始设置耦合率逐渐以0.25 的步长增大,以均方根误差作为评价指标,若均方根误差下降,则耦合率继续增大,若均方根误差上升,则返回至原来的状态并增大前一层的耦合率,以此方式依次进行。基于本文的网络结构和数据集耦合率依次为0,0.25,0.5,0.75。可以看出耦合率逐渐增大,这是因为在较浅层的纹理等细节特征上红外和可见光图像有较大的差异,较深的结构和轮廓等特征上红外和可见光图像有较大的相似性,容易学习两者的可转换特征。
在TFCNet 中,采用反向传播算法更新滤波器的参数。非耦合的滤波器参数在每次训练过程中迭代1 次,耦合的滤波器参数迭代2 次。因此,假设在参数更新过程中,先更新红外卷积流的参数,再更新可见光卷积流的参数。参数α更新如下:
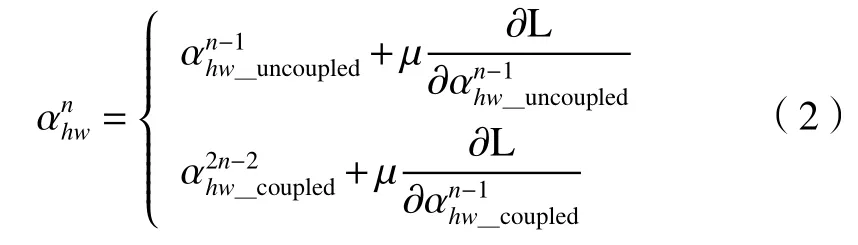
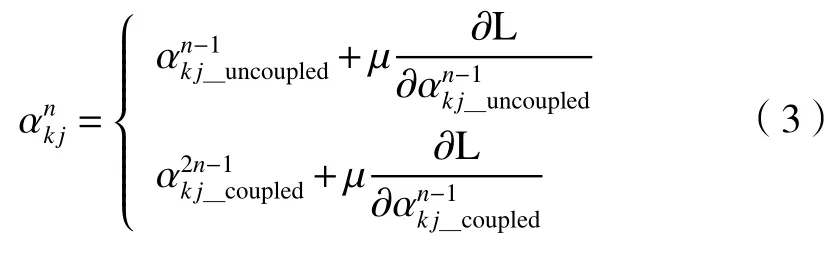
式中:n是迭代次数;μ为学习率;L为损失函数。耦合滤波器的权重更新过程如下:
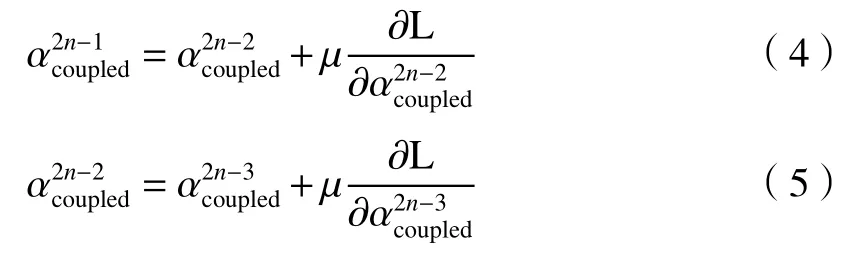
滤波器耦合的设计利用两者优势,弥补了可见光图像对光线敏感以及红外图像纹理缺失的不足。
1.2 融合网络
为了充分利用两种图像特征的互补信息,本文设计了一种自适应融合策略来融合多种特征。同时,大多数网络各个卷积层提取的特征一般用来参与后一层卷积的特征生成,并没有直接参与最终的深度估计,导致预测结果细节缺失。针对以上分析,本文的融合网络包含2 个部分,分别为自适应多模态特征融合网络(adaptive multi-model feature fusion network, AMFNet)和自适应逐级特征融合网络(adaptive progressively feature fusion network,APFNet)。
1.2.1 自适应多模态特征融合网络
考虑到红外和可见光图像的特征在不同场景对不同目标进行深度估计时所起的作用不同,本文设计了自适应多模态特征融合网络(AMFNet)。
AMFNet 网络的具体形式如图2 所示,主要由残差密集块(residual dense blocks, RDB)和自适应加权融合组成。通过TFCNet 得到红外和可见光图像的特征,将两种特征均进行一个1×1 的卷积,对每一个特征降低维度,避免出现参数爆炸问题。然后将每个特征通过m个RDB,如图2 中红色虚线框所示。RDB 允许将每一层的输出与当前块中后续所有层直接相连,也允许将前一个RDB的输出与当前块中的每一层连接,则第s个RDB中第i层的输入如下:
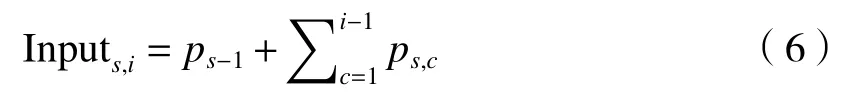
式中:s表示第s个RDB;i表示当前RDB 中第i层。如果每个RDB 最终输出N0个特征,且每一层输出N个特征,则第i-1 层的输出可以得到N0+(i-1)N个特征,本文令m=2,N=N0=32。相较于传统的CNN,RDB 可以充分利用原始特征的所有分层特征,使得各层之间的信息最大化,使边缘等细节信息增强。随后进行一个3×3 卷积,该操作对特征进行适当的缩放起到关键的作用。

图2 自适应多模态特征融合网络(AMFNet)Fig.2 Adaptive multi-model feature fusion network (AMFNet)
令fhw∈Rb×w×h×c和fkj∈Rb×w×h×c分别表示从两种模态最终提取出来的红外和可见光特征。由于红外和可见光图像的特征不同,本文设计了自适应加权融合策略,如图2 中绿色虚线框所示。首先,将两种特征在第三维度上连接,此时通道数为2c。其次,为了获得与两种特征相同维度的系数,矩阵引入了1×1 卷积,该操作学习两种特征之间的相关性并得到了系数矩阵M。最后,通过Sigmoid层使M中的每个元素转换为0~1 之间的概率形式,即为最终的系数矩阵G,令红外图像特征的系数矩阵Ghw=G,则可见光图像特征的系数矩阵Gkj=1-G,两者分别表示了红外和可见光特征对深度估计任务的贡献程度。即:

式中⊙表示点积。自适应加权融合策略决定了可以依赖红外或可见光图像的特征来进行深度估计的程度。
由于较浅层的卷积中提取到更多的细节信息,较深层的卷积提取到更多的轮廓等特征,若只利用最后一层的融合特征,则会忽略浅层信息,导致估计出的深度图细节缺失。因此本文希望各层双流卷积特征均通过AMFNet 进行融合,充分利用各层的特征。考虑到第一层卷积太浅,特征无法进行可靠的预测,所以本文所设计的网络不会对第一层卷积特征进行融合。
1.2.2 自适应逐级特征融合网络
为了学习各层的融合特征,充分利用深层特征和浅层特征,让各层级的特征直接参与最终的深度估计,本文设计了APFNet,自适应地学习不同层融合特征的结合,如图3 所示。
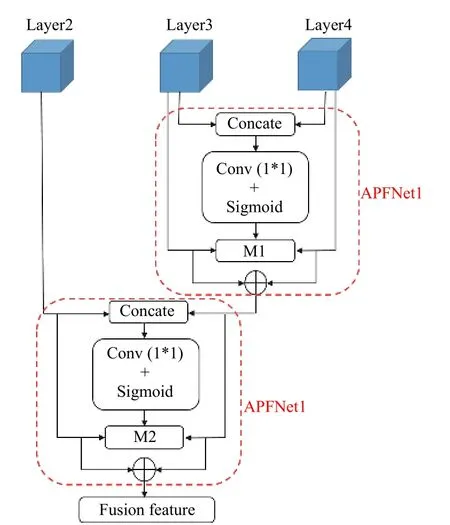
图3 自适应逐级特征融合网络(APFNet)Fig.3 Adaptive progressive feature fusion network(APFNet)
APFNet 中采用与AMFNet 中相同的自适应加权融合策略来融合不同卷积层的融合特征。首先对最后2 层的融合特征进行自适应加权融合,得到分辨率与第2 层卷积相同的融合特征,然后将该融合特征同第2 层融合特征进行自适应加权融合,得到最终的红外与可见光融合特征。但是该策略在这两个部分所起的作用截然不同。在APFNet 中,自适应加权策略是通过网络自适应地学习细节特征和轮廓特征对深度估计任务的不同贡献,在AMFNet 中自适应加权融合策略,衡量可以依赖红外和可见光图像进行深度估计的程度。随后3×3 卷积自适应地学习全部特征,我们设计了上采样层,输出分辨率为256×512 像素的深度图。
1.3 网络训练
本文使用Tensorflow 深度学习框架,参数采用截断正态分布进行初始化。学习率初始化为1e-4,每迭代20 000 次以0.9 的因子进行衰减,共迭代80 000 次。将交叉熵作为损失函数,利用Adam 优化器最小化损失函数:

式中:L为损失函数;ypredictedi为真实预测值;yi为期望预测值。
实验数据集NUST-SR 由无人车在白天和夜间采集的真实道路场景组成,采集设备如图4 所示。原始图像由分辨率为768×576 像素的红外和可见光图像及其深度值所组成,并利用NYUDepth 开发工具中Levin 等人[7]的方案对没有深度值的点进行补点。此外,本文使用分类方法进行深度估计,将真实深度图在对数空间划分为32 个类,该分类方法可以使近处的场景准确度较高,远处的场景准确度较低。最后将红外图像、可见光图像以及深度图剪裁为分辨率256×512 像素的图像,最终训练集3 000 张,测试集1 000 张。

图4 采集图像设备Fig.4 Device of image acquisition
2 实验及结果
介绍了评估实验结果所用的评价指标,然后对PF-CNN 进行全面分析,证明该方法中滤波器部分耦合、自适应加权融合方法以及逐级融合的有效性,通过对比不同深度估计方法[1,7,15-21]得到的深度图以及不同方法的参数内存,发现PF-CNN 在本文数据集上得到了最好的表现。
2.1 评价指标
为了在测试集上定量地证明基于红外和可见光图像逐级自适应融合的深度估计方法的性能,本文引入在深度估计领域中通用的评价指标,如下所示:
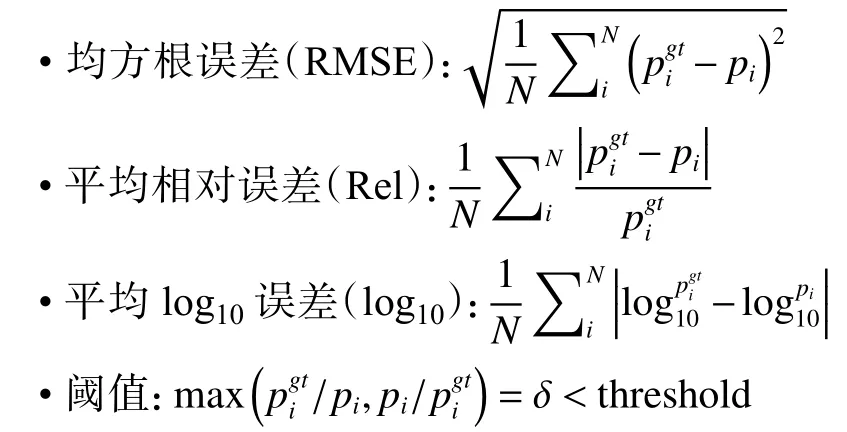
式中:pgti表示真实深度;pi表示预测深度;t表示像素总数。RMSE、Rel 和log10误差用来度量预测深度和真实深度之间的差异,值越小越好。阈值准确度用来度量预测深度和对应真实深度之间的相似度,值越大越好。
2.2 滤波器部分耦合效果
在双流卷积网络[11-12]中,红外和可见光图像的卷积核相互独立,红外和可见光图像的特征相互没有影响。但是在本文TFCNet 中采用了滤波器部分耦合的方式,使提取到的特征进一步增强。
将两者滤波器部分耦合和不耦合得到的深度图进行对比,结果如图5 所示。从图5 可以看出,将滤波器部分耦合后得到的深度图更接近真实深度,物体轮廓更加清晰,说明两种图像提取的特征通过滤波器部分耦合得到了增强。从上述4 个测试图像中随机选取100 个像素的分类结果如图6所示,将其与该像素点的真实类别比较,可以看到使用滤波器部分耦合方法后的预测分类结果更接近真实深度分类。

图5 红外和可见光图像的滤波器是否耦合得到的深度图对比Fig.5 Comparison of depth diagram whether filters coupled of IR/visual light

图6 4 个场景中滤波器是否耦合的分类结果比较Fig.6 Comparison of classification whether filters coupled in 4 scenes
2.3 红外和可见光图像融合的效果
为了证明基于红外和可见光图像逐级融合的方法相较于单独使用红外或可见光图像进行深度估计的优势,将PF-CNN 与单独使用红外和可见光图像估计深度以及只在最后一层卷积处融合两种图像特征估计深度进行对比,4 个指标的比较结果见表1 所示。可以看出,基于红外和可见光图像的特征逐级融合的方法在RMSE、Rel 和log10误差指标上数值最小,在阈值指标上,结果恰好相反。

表1 PF-CNN 与单独使用红外或可见光以及只在最后一层融合的4 个指标对比Table 1 Comparison of four indicators when using PF-CNN , using infrared or visible light only and fusing at last layer only
L1 范数融合、相加融合、加权融合和连接融合是两种图像进行融合经常用到的方法。本文将这些方法同自适应加权融合方法相比较,如图7 所示。通过比较可以看出,基于自适应加权融合方法预测的深度图在不同对象的边缘和细节方面具有相当大的优势。
2.4 相关深度估计方法的比较

图7 不同融合方法比较Fig.7 Comparison of different fusion methods

图8 不同深度估计方法的深度图对比Fig.8 Comparison of depth diagrams by different depth estimation methods
本文PF-CNN 得到的深度图同其他经典方法得到的深度图进行对比,如图8 所示。从图8 可以看出,不论是图像中的树还是行人,本文方法都有更清晰的轮廓。通过融合红外和可见光图像的信息,PF-CNN 可以增加红外图像的细节信息,减少可见光图像的冗余信息,同时,AMFNet 中的残差密集块可以增强融合特征并恢复细节信息。
为了说明PF-CNN 的性能优势,将上述4 种评价指标进行比较,如表2 所示。可以看出PF-CNN在各项指标上都得到了最好的表现,特别是阈值指标提高了5%。表3 为各种方法的参数内存比较,可以看出PF-CNN 比Eigen 等学者[11]的多尺度方法少了6.1 M,这是因为红外和可见光图像的滤波器耦合大大减少了参数的数量,说明本文方法在参数较少的情况下达到了最好的效果。
3 结论
为了解决单一类型图像在深度估计中受场景不同光照的限制问题,同时使红外和可见光图像在不同场景下对深度估计起不同的贡献,本文提出了基于红外和可见光图像逐级融合的PF-CNN网络,它将红外和可见光图像的滤波器部分耦合,进一步增强两者的特征,并将除第一层外的红外和可见光特征进行自适应加权融合,解决了在不同光照条件下不能准确估计深度的问题。同时PF-CNN 将各层的融合特征进一步逐级自适应融合,使不同卷积层的特征对深度估计做出不同的贡献。
未来将在不同的数据集上验证PF-CNN 的效果,并在此基础上进一步改进深度估计网络架构。将尝试采用递归神经网络来处理图像序列的不同帧之间的相关信息。

表2 不同深度估计方法的指标对比Table 2 Comparison of indicators by different depth estimation methods

表3 各种方法参数内存比较Table 3 Comparison of parameters memory by different methods
