基于相似性的T/R组件剩余寿命预测方案研究
2020-03-05侯晓东杨江平常春贺孙知建
侯晓东,杨江平,常春贺,孙知建,郭 健
(1.中国人民解放军94969部队,上海 200137;2.空军预警学院, 武汉 430019)
T/R组件(发射/接收组件,T/R Module)是大型相控阵雷达天线阵面的重要组成部分,是大型相控阵雷达的核心部件。T/R组件由高功率放大器、移相器、限幅器、收发转换开关和低噪声放大器等器件组成,主要完成发射功率放大、收发隔离和接收低噪声放大等功能,具有集成度高、设备量大、可靠性高的特点[1-2]。T/R组件剩余寿命预测能够指导装备维修保障人员及时掌握装备的健康状态,对部队提高装备战备完好率和缩短维修保障时间具有重要的实际意义[3]。
装备的剩余寿命预测一直是故障预测与健康管理(Prognostics and System Health Management,PHM)的热点和难点问题。装备的剩余寿命是指装备失效前能够保证持续正常运行的能力,即距离失效发生的大概时间[4]。为了合理有效预测装备的剩余寿命,Wang[5]提出了相似性剩余寿命预测方法,该方法的思想是若两个样本在某段时间内的表现相似,则这两个样本在该段时间内的剩余寿命也相似。孟光[6]和张仕新[7]分别对设备寿命预测方法进行了全面论述,分析和总结了基于相似性的剩余寿命预测方法。尤明懿[8-10]提出了一种能同时利用失效历史数据和未失效数据的拓展的相似性剩余寿命预测方法,并对其鲁棒性和不确定性进行了研究,提高了相似性寿命预测的应用范围。文献[11-12]分别对相似性及其改进方法的应用进行了研究。
以上方法是针对简单机械设备(如轴承、齿轮和基础元部件)的剩余寿命预测,由于其失效机制已得到比较充分的认知,可以根据实际经验和对失效的理解采用,单退化变量下的相似性寿命预测方法,具有较好的预测效果。对于具有多种失效机制和故障模式的T/R组件而言,因结构复杂,性能退化或失效均为多种因素共同作用的结果,不同的状态监测指标包含了反映不同故障模式的信息,单个状态退化变量难以准确反映状态退化过程,造成了最终的剩余寿命预测结果与实际剩余寿命存在较大的误差。如T/R组件发射通道中输出功率下降,可能出现的一种情况是较低的输入功率也会使输出功率下降,然而并不是T/R组件本身出现故障,必须在输出功率下降基础上,结合发射增益的变化来判断输出功率的下降是输入功率低造成的结果还是组件发生故障造成的结果,这种情况下如果只选择发射通道的输出功率进行剩余寿命预测,将会得到错误的预测结果,依据错误的预测结果制定的维修保障方法,不仅错过了最佳的有效维修时间,而且对于装备的性能有着重要的影响,因此对于具有多故障模式的T/R组件而言,需要深入分析性能退化过程,提取如实反映该过程的所有性能参数,然后据此采用合适的剩余寿命预测方法进行预测。
为了及时准确掌握T/R组件的健康状态,本文提出了两种基于相似性的剩余寿命预测方案。首先,通过分析T/R组件的故障机理和故障特点,采用基于关联规则的提取方法提取了准确反映T/R组件性能状态退化过程的状态监测指标。然后,在提取到的状态退化指标的基础上,根据基于相似性的剩余寿命预测的对象的不同,提出了先融合后预测的方案A和先预测后融合的方案B,并对两种方案的具体预测过程进行了研究。最后,通过实例对两种方案进行了比较,结果表明了先预测后融合的方案B具有更高的预测精度。
1 T/R组件状态退化指标提取和权重计算
1.1 基于关联规则的提取方法
开展基于相似性的剩余寿命预测的研究,首先需要确定出能够反映装备性能退化过程的状态退化指标。在实际应用中,由于性能退化过程是随机的,获取到的某些性能退化特征信息存在测量误差和对性能退化过程敏感性不高,不能很好地反映装备性能退化过程,直接影响了剩余寿命预测的精度。为了有效地预测装备的剩余寿命,减少原始数据的冗余信息和相关误差,需要对初始状态监测指标进行提取,以获得反映装备性能退化过程的有效成分。当前针对此类问题的研究较少,没有提出统一的具有指导性的理论与方法。梁泽明[13]采用Spearman系数计算出每个参数的趋势,依据对装备退化过程敏感参数具有单调的退化趋势选择用于寿命预测的关键参数。谷梦瑶[14]利用累积贡献率对退化变量进行约简。
在大型相控阵雷达装备系统中,为了及时准确掌握装备的健康状态,系统内部安装了大量的机内测试设备(Build-In Test Equipment, BITE),实现了装备功能检查、故障诊断与隔离、性能指标测试等功能[15],经BITE得到的特征信息对装备的故障与剩余寿命预测等提供了重要的特征数据。通过对T/R组件的故障进行分析,T/R组件主要有三种故障模式:发射通道故障、接收通道故障和发射、接收通道同时发生故障。不同的故障模式下不同监测指标的变化趋势是不同的,因此以上文献采用的分析指标的单调退化趋势的思路只局限于单故障模式的情况。基于T/R组件的多故障模式问题,需要从故障模式入手,分析不同故障模式下的不同监测指标的特点,确定出能够反映不同故障模式下状态退化过程的状态退化指标。
关联规则是通过寻找同一个事件中出现的不同项之间的相关性,来确定此事件中频繁发生的项或属性的所有子集,以及它们之间的相互关联性[16]。记D为事务数据库,D={f1,f2,…,fn},其中,n为事务数据库中子集数据的个数。子集事务为fi={x1,x2,…,xn},x称为项。设D={x1,x2,…,xj}为D中所有项的集合,X的任何子集A称为项集,|A|=k称A为k项集。在事务数据库D中,包含某特定项集A的事务个数称为A的支持度计数,记为σ(A)。假设项集A⊂D,B⊂D,且A∩B=∅,则定义关联式A→B为关联规则。A和B分别成为关联规则A→B的前提和结论。以T/R组件为例,若A为初始状态监测指标,B为T/R组件发生的故障模式,则关联规则A→B表示初始状态监测指标与相应的故障模式之间的关联程度。
在关联规则中通过支持度和置信度这两个指标来衡量其有效性和可信性。支持度表示当T/R组件发生某种故障时,相关状态监测指标超出警示值的概率,即在事务D中出现A∪B的概率,如果在某种故障模式下某一状态监测指标的支持度接近于1,说明该指标与该故障的紧密程度越大,该监测指标的有效性就越大。支持度表示为:

(1)
置信度用来表示该关联规则的可信程度,即度量发生的故障模式与状态监测指标间的相关关系。在事务D中,出现A的同时出现B的概率,记为P(B|A),当某个监测指标超出警示值时,发生相应故障的概率和置信度越高,则监测指标对相应故障的依赖性、可靠度也越高。置信度表示为:
(2)
根据上面的定义,可以得到量化监测指标和故障模式之间的关系:
1) 事务数据库Di={第i个故障发生};
2) 子集Aij={第i个故障模式下第j个指标超出预警值};
3) 子集Bi={第i类故障发生}。
通过式(1)和(2)可得,规则Aij→Bi的支持度和置信度分别为:
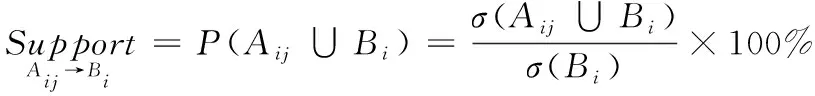
(3)

(4)
由于不同的状态监测指标反映了T/R组件不同的故障类型和程度,即某个状态监测指标对应某种故障类型,某些指标对应多种故障类型。而当支持度和置信度都达到一定阈值时,可认为T/R组件的故障状态和状态监测指标存在着一定的关系。结合上面的分析,通过计算故障状态和状态监测指标之间的支持度和置信度,筛选出反应T/R组件状态退化过程的状态退化指标,需要满足最小阈值,即:

(5)
1.2 基于熵权法的指标权重计算
熵最先由香农引入信息论,目前已在工程技术、社会经济等领域得到了非常广泛的应用。熵权法是一种客观赋权方法,在具体使用过程中,熵权法根据各指标的变异程度,利用信息熵计算出各指标的熵权,再通过熵权对各指标的权重进行修正,从而得出较为客观的指标权重[17]。一般来说,若某个指标的信息熵越小,表明指标值的变异程度越大,提供的信息量越多,在综合评价中所能起到的作用也越大,其权重也就越大。
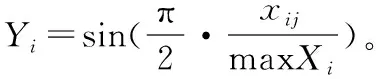
根据信息论中信息熵的定义,一组数据的信息熵为:
(6)
根据信息熵的定义公式(6),计算得到k个状态退化指标的信息熵为E=(E1,E2,…,Ek),通过信息熵计算得到各个状态退化指标的权重为:
(7)
2 T/R组件剩余寿命预测方案
开展多状态退化指标下基于相似性的T/R组件剩余寿命预测,有以下两套方案。
2.1 方案A:先融合后预测方案
先融合后预测方案借鉴了信息融合的思路,信息融合是对多个传感器或其他信息源的数据进行多级别、多方面、多层次的组合或者融合处理,以便得到更好的综合估计[18]。在T/R组件的剩余寿命预测问题中,将多个状态退化指标通过信息融合转化为一个表征T/R组件健康状态和退化程度的参数(HI)用于剩余寿命预测,该方案如图1所示。
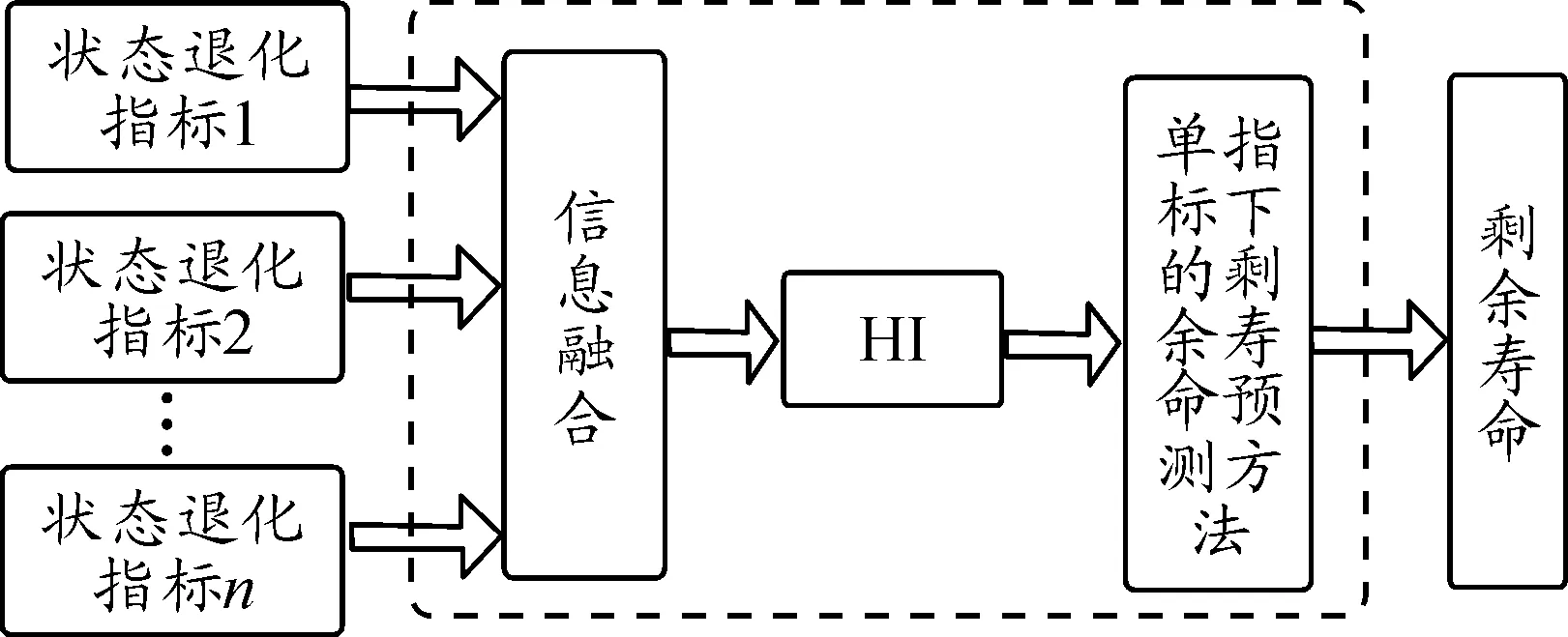
图1 方案A示意图
2.2 方案B:先预测后融合方案
先预测后融合方案的思路是分别对每个状态退化指标应用剩余寿命预测方法进行预测,将得到的每个指标对应的剩余寿命信息进行信息融合,从而得到装备最终剩余寿命。剩余寿命信息指从单个状态退化指标的角度,应用剩余寿命预测方法得到的装备的一部分剩余寿命,这是不完整的,不能代表装备实际剩余寿命。对于复杂的装备系统,其性能退化过程是非常复杂的,表现在多个状态退化指标的变化上,因此,装备的最终剩余寿命是综合多个状态退化指标对应的剩余寿命信息进行加权融合得到的。该方案如图2所示。

图2 方案B示意图
从图1和图2可以看出,两个方案是有明显区别的,虽然整个过程中都存在信息融合,但是信息融合的对象和层次都是不同的,最终反映在T/R组件剩余寿命预测结果与实际剩余寿命的误差大小。两种方案的详细比较如图3所示。
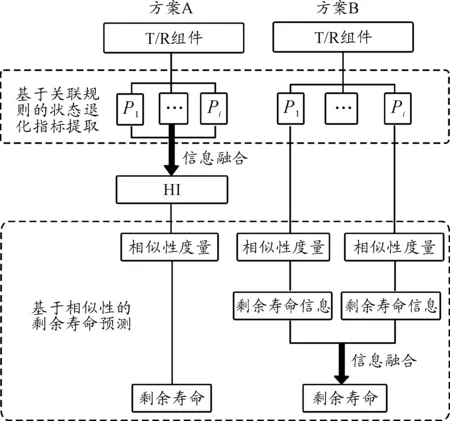
图3 两种方案的比较框图
由图3可知,方案A的重点在于如何构造和提取HI的过程,即将多状态退化指标融合为一维的HI,表1对常用的指标融合方法进行了梳理。

表1 指标融合方法
在此基础上,文献[25]提出了健康度的概念,系统健康度是衡量系统健康程度的一个量化指标,能够从整体上更全面地反映系统的健康状态,并提出了多退化变量下基于实时健康度的相似性剩余寿命预测方法,该方法首先从状态退化指标维度融合的角度,采用PCA法、马氏距离和负向转换函数等将多个状态退化指标转化为能够反映机电设备退化状态的定量指标—实时健康度,然后,采用单退化变量下的相似性剩余寿命预测方法来预测机电设备的剩余寿命,实例验证的结果表明了采用健康度的融合思路具有显著的优越性。实时健康度的计算过程如图4所示。
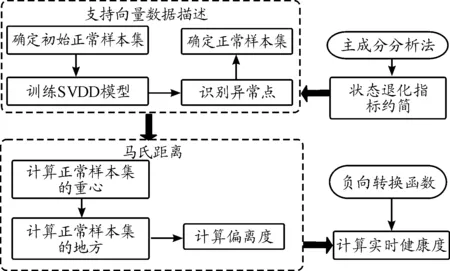
图4 实时健康度的计算过程框图
基于以上分析,确定出了方案A的预测路线,具体的预测路线如图5所示。
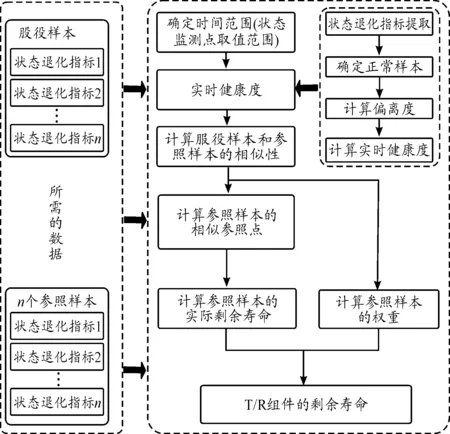
图5 方案A的预测路线框图
3 基于相似性的T/R组件剩余寿命预测模型
本节主要对方案B的详细预测过程进行设计。基于相似性的剩余寿命预测需要两类样本:服役样本和参照样本。
1) 服役样本指在正在运行的T/R组件(即预测对象)上采集到的,应用关联规则提取方法得到的状态监测指标的数据集合。
2) 参照样本为在相同或相近运行条件下,在已失效的T/R组件上采集的同类指标的数据集合,参照样本有多个,其整个寿命周期的信息都是已知的,包括整个退化过程中状态退化指标的连续监测记录和失效时间。
3.1 相似度的计算
记xoi(n·Δt)为服役样本o第i个指标从开始运行以来的第n个采样点,其中,n为自然数,Δt为状态监测采样区间。记r为参照样本的编号,第r个参照样本第i个指标的第m个采样点记为xri(m·Δt),其中,m为自然数。在相似性有效测度区间H=(h+1)·Δt中,服役样本的和参照样本分别可以表示为:
Xoi(k,h)=[xoi((k-h)·Δt),…,xoi(k·Δt)]
(8)
Xri(k′,h)=[xri((k′-h)·Δt),…,xri(k′·Δt)]
(9)
式中:h为非负整数;(k-h)和(k′-h)分别为服役样本和参照样本的起始状态监测点。服役样本和参照样本的第i个指标的采样区间如图6所示。

图6 状态监测指标采样区间示意图
考虑各点相同权重的基于ED的第i个指标的服役样本和参照样本相似度计算方法为:
(10)
实际情况中,在系统衰退过程的非稳态阶段,系统状态改变程度是非常快的,服役样本最新的指标状态监测值对比之前的监测值更能够真实反映装备系统的实际状态,在计算剩余有效寿命时应该赋予最新的指标状态监测值较高的权重[26]。在此引入权重因子α表达第i个状态退化指标在不同状态监测点对剩余寿命预测的贡献程度。考虑变权重的基于改进ED的服役样本和参照样本之间状态监测指标i的相似度为:
(11)
式(11)中:α为引入的权重因子,α∈[0,1);g为实数,且0≤g≤h。当α=0时,式(11)即为传统ED的形式,即式(10),当g的值在逐渐增加的过程中(采样点越靠近起始状态监测点),(1-α)g的值在逐渐减小,实现了越新的信息应该具有更高的权重。
基于公式(11),对同一个参照样本,在时刻t=k·Δt,第i个指标的相似性为:
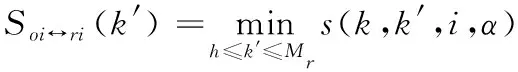
(12)
式(12)中:Mr为参照样本r失效或故障状态监测点。
3.2 剩余寿命预测
假设参照样本有R个,其中r∈R,定义相似样本为参照样本的第i个指标对应相似性Soi↔ri(k)满足下式的参照样本。
(13)
式(13)中:λ为引入的约束因子,λ∈[0,1],其大小决定了相似样本的数量,直接对预测结果的精度产生影响。在此取λ=0.5,符合式(13)的参照样本即为相似样本,同时得到了相似样本在参照样本R中的编号r和相似样本的数量n。

rulri(k′)=(Mr-Nri(k′))·Δt
(14)
式(14)中,h≤k′≤Mr;Mr·Δt是参照样本r的有效寿命。
由此可得服役样本的剩余寿命信息为:
(15)
式(15)中:r为式(13)计算得到的相似样本编号;n为相似样本的个数。
由此可得装备系统实际剩余寿命为:
(16)
式(16)中:i为得到的状态退化指标的个数;Wi为相似样本经式(7)得到的每个指标对应的权重。
3.3 合理性与有效性验证
在此定义预测精度指标:平均预测误差(Average Prediction Error,APE)来评估基于相似性的剩余寿命预测方法的合理性,即某个状态监测点预测值与实际值之间的平均绝对差值。
(17)
式(17)中:PRLi(k)为检验样本i在监测点k的剩余寿命预测值;ARLi(k)为检验样本i在监测点k的实际剩余寿命;r为检验样本的个数。通过式(17)可以看出,APE(k)的值越小,说明预测值与实际值越接近,对应的预测方法的精度就越高。
定义预测精度指标:总体预测误差(Overall Prediction Error,OPE)来评估预测方法的总体表现程度。即整个预测区间范围内的预测值与实际值的平均绝对差值。
(18)
式(18)中,Mi为检验样本i的失效时间点。
由式(18)可知,OPE的值越小,说明该预测方法的总体预测精度就越高。
3.4 预测精度分析
通过式(11)可以看出,权重因子α的取值对剩余寿命预测结果有着直接的影响。为了得到较高的预测精度,可以通过预测误差来优化权重因子α的值。采用交叉验证法(Cross Validation,CV)的思想进行验证。通过对α赋予不同的值,根据式(18)计算OPE,满足OPE最小时α的值即为最终确定出的权重因子(同理λ的值通过OPE来确定)。即:
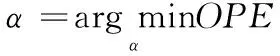
(19)
3.5 计算步骤
方案B的具体计算步骤如下:
步骤1 确定出时间范围H。即参与相似性计算的状态监测点H=[(k-h)·Δt,k·Δt]=(h+1)·Δt,一般根据实际情况进行确定。
步骤2 状态退化指标的提取。对T/R组件状态监测指标的多组数据序列通过式(3)~(5)进行状态退化指标提取,得到如实反映装备实际状态退化过程的指标序列,并进行数据标准化处理,利用式(7)计算得到每个指标对应的权重。
步骤3 相似度计算。对状态退化指标序列计算每一个指标对应的服役样本和参照样本的相似性程度s(k,k′,i,α),通过式(12)得第i个指标的相似性Soi↔ri(k)。
步骤4 剩余寿命信息融合预测。已知第i个指标对应的参照系统r的剩余寿命rulri(k),利用式(14)确定出相似样本的个数n和编号r,然后通过式(15)、式(16)得到最终的装备系统实际剩余寿命RULo(k)。
方案B的预测路线如图7所示。
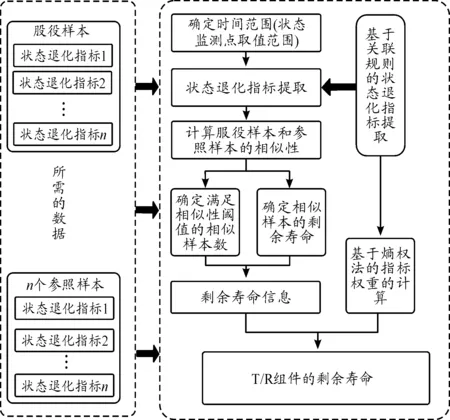
图7 方案B的预测路线框图
4 实例验证
T/R组件是大型相控阵雷达天线阵面的重要组成部分,设备量占整机的80%以上,由于数量庞大、故障率高,BITE覆盖率达到了100%。选择雷达装备BITE和现场测试设备能够直接获取的主要指标数据,来验证本文所提出的状态退化指标提取方法的有效性。
4.1 状态退化指标提取
根据部队实际情况,每天雷达装备在开机前,装备维修保障人员会对所有T/R组件进行测试,判断其健康状态,当故障单元达到一定数量时要及时维修或更换,使装备能够时刻保持良好的状态,以满足任务的需求。为衡量T/R组件的性能,需全面测试T/R组件的性能与状态监测指标多达几十种,在兼顾全面性和易得性基础上,从不同侧面反应T/R组件的状态退化信息,本文选择的状态监测指标如表2所示。
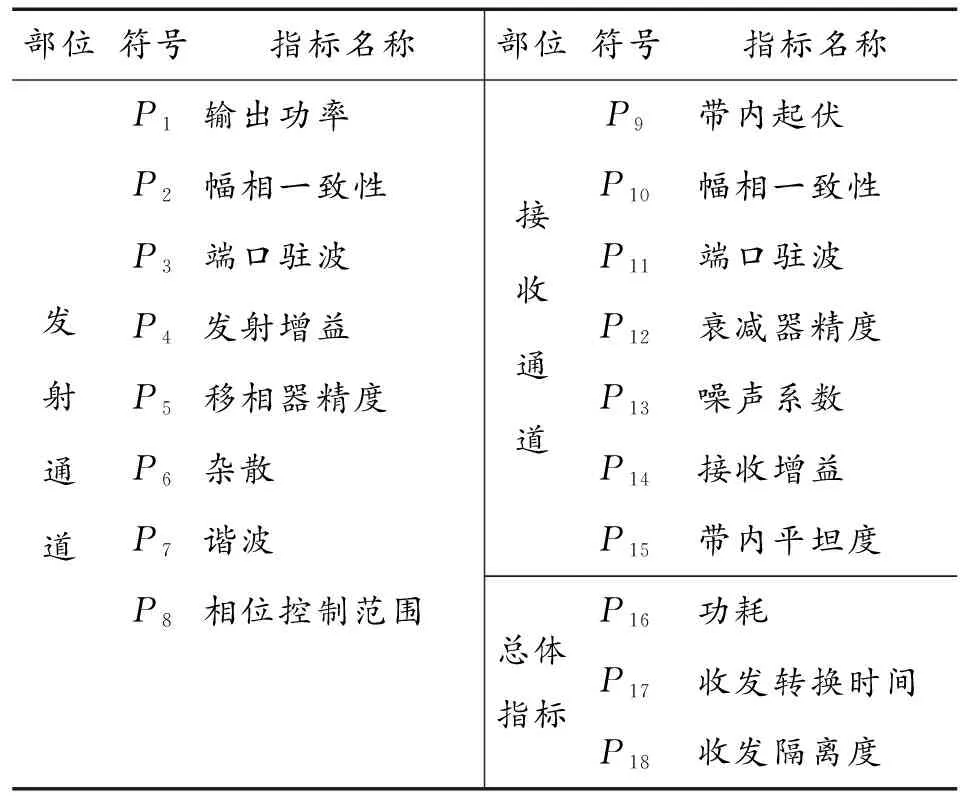
表2 T/R组件状态监测指标
已知大型相控阵雷达天线阵面T/R组件的主要故障机理为自激和晶体管失效或老化,经BITE统计得到的故障模式有3种,如表3所示。

表3 T/R组件的故障模式
根据2015年更换故障T/R组件的数据得知,2015年全年共更换故障T/R组件413个,三种故障模式的T/R组件分别有302、69和42个,结合表2对这些故障样本进行分析统计,得到T/R组件的故障状态统计数据如表4所示。
在表4基础上,根据式(3)、式(4),分别计算不同故障模式下每个状态监测指标的支持度和置信度,设置其最小阈值为:Support≥70%,Confidence≥50%,从而提取出T/R组件状态退化指标,如表5所示。
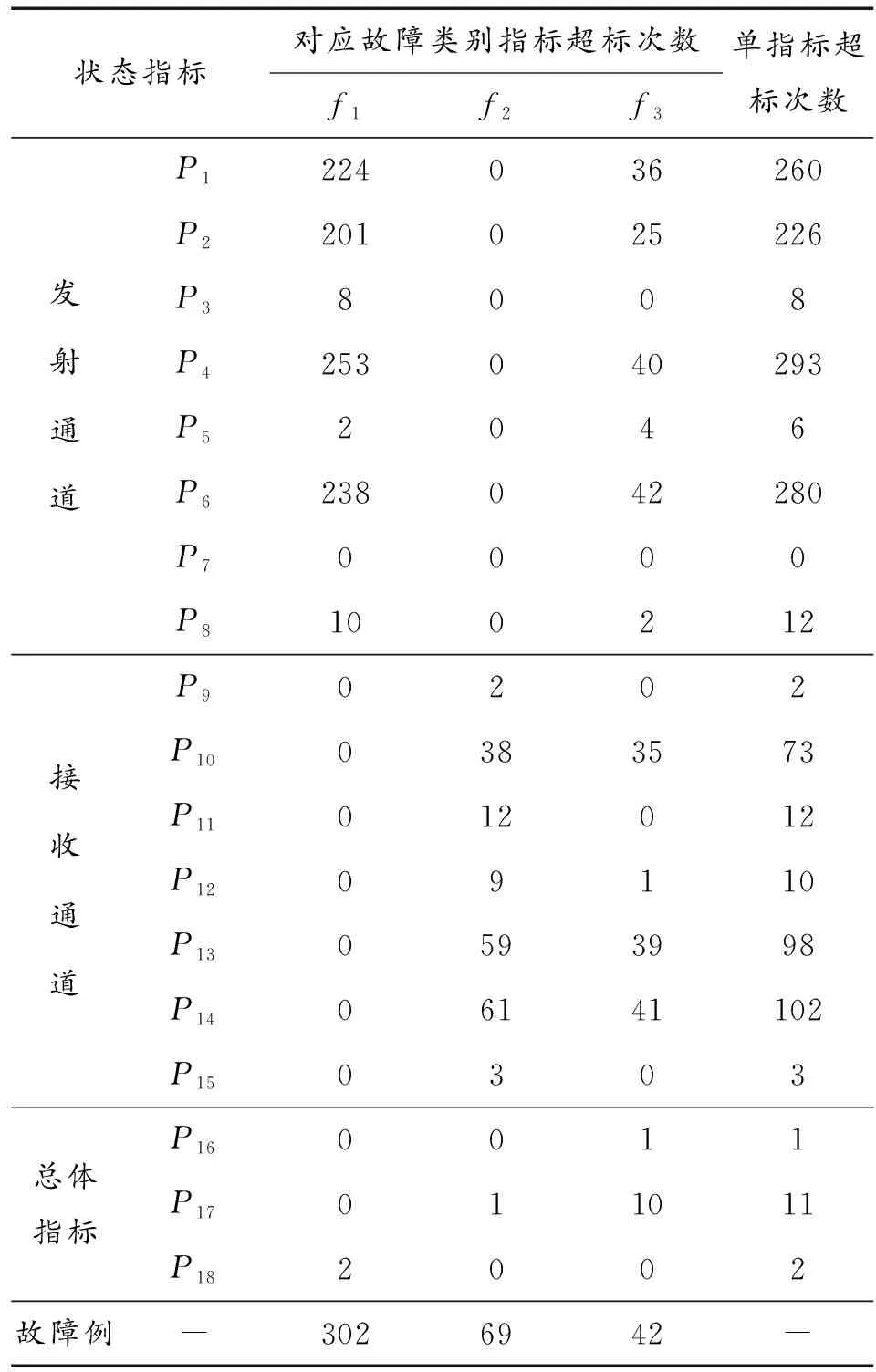
表4 T/R组件故障统计数据

表5 T/R组件状态退化指标
根据表5的结果可以看出:发射通道的状态退化指标主要有输出功率、发射增益和杂散,接收通道的状态退化指标主要有噪声系数和接收增益。结合前文的分析,选出来的这些指标与实际情况相符,涵盖了T/R组件的所有通道,并且能够全面刻画不同故障模式的状态退化过程,可以作为剩余寿命预测的状态退化指标进行预测。
4.2 两种方案的T/R组件剩余寿命预测比较
已知大型相控阵雷达平均每天运行时间为12 h,平均每天发生故障的T/R组件数为0.849个,故障T/R组件的半年累积数量平均为206个[30]。在相似性有效测度区间H=(h+1)·Δt中,选择h=5,Δt=5 min,即选择时间长度为H=30 min内的6组状态监测指标采样数据,在所有的故障样本中随机选择10个样本作为检验样本,分别使每一个检验样本作为服役样本,剩余9个样本作为参照样本对本文方法的有效性与实用性进行验证。
分别根据方案A和方案B对10组检验样本的剩余寿命进行预测,得到了剩余寿命预测结果(在此取α=0.3,后文有具体分析)。同时给出了实际剩余寿命作为参照和常规剩余寿命预测方法(参考文献[14]的方法)的结果进行对比,如图8所示。
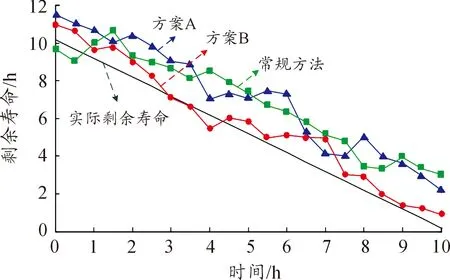
图8 预测结果曲线
通过图8的对比可以看出,方案A和方案B都可以实现对T/R组件的剩余寿命预测,而方案B与实际剩余寿命更加接近。为了使结果更具有说服力,同时给出了方案A和方案B与常规方法的平均预测误差(APE)如图9所示。表6表示了总体预测误差(OPE)。
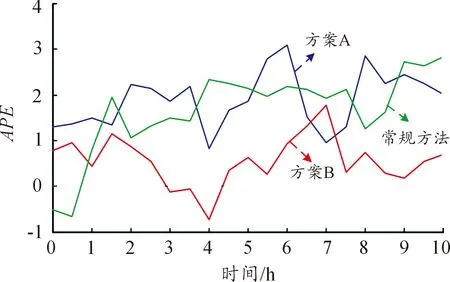
图9 APE曲线

表6 三种方案的OPE值
图9和表6显示了方案B确实具有更高的预测精度。从理论角度,方案B与实际剩余寿命能够更加接近,图9和表6从数据的角度证实了方案B具有更高的预测精度。
式(11)中引入的权重因子α表达了第i个状态退化指标不同监测点对预测结果的贡献程度,直接对预测结果的精度产生影响。通过对α赋予不同的值,得到总体预测误差(OPE)如图10所示。
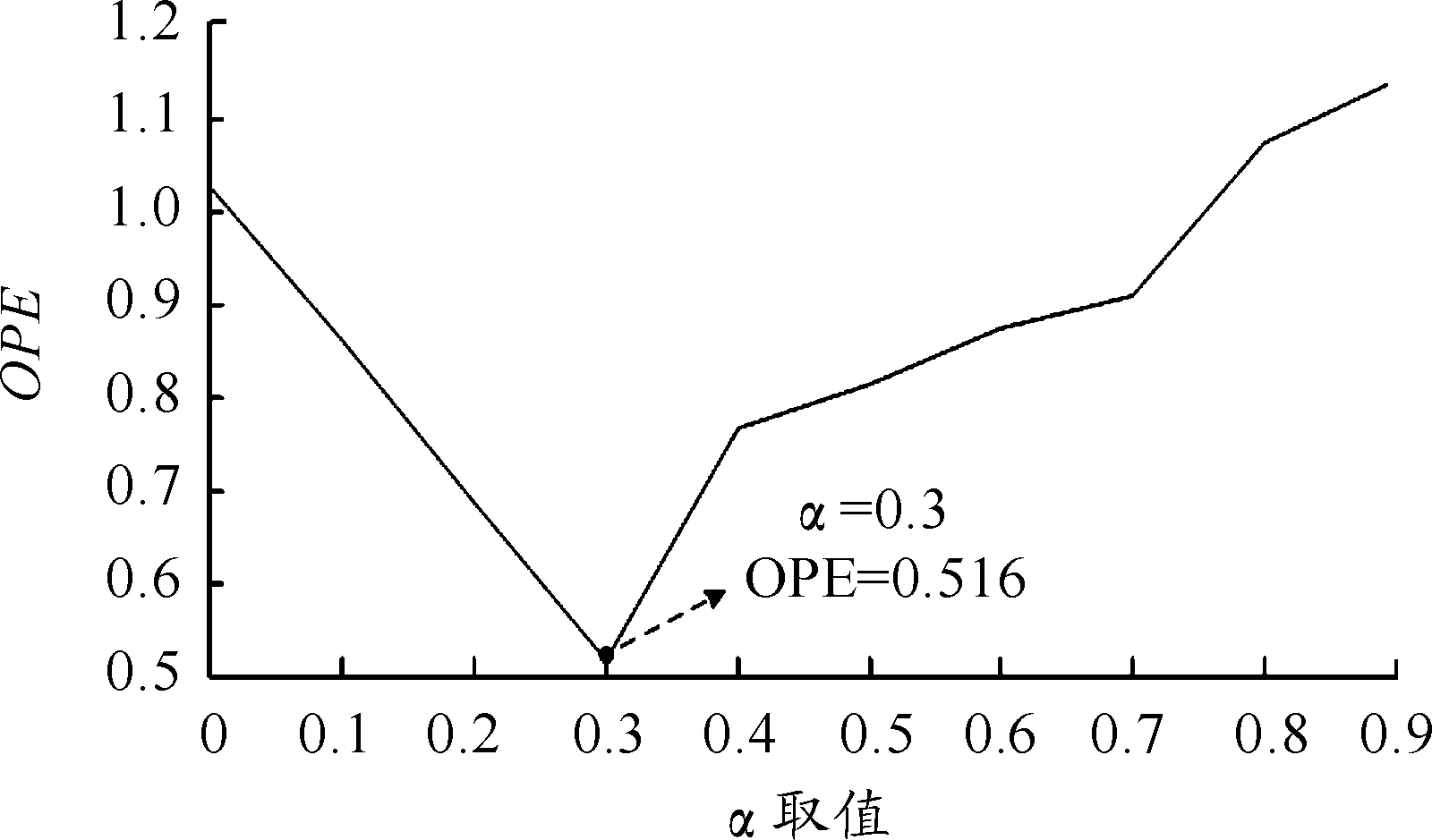
图10 α与OPE的关系曲线
由图10可知,当α=0.3时,总体预测误差(OPE)值最小为0.516,所以取α=0.3,可以得到更精确的剩余寿命预测结果。
综上所述,基于方案B的T/R组件剩余寿命预测方法在实现T/R组件剩余寿命预测的同时,改善了方案A中一维状态退化指标融合过程中的信息丢失问题,且通过实例验证了方案B具有更高的预测精度,对部队装备的维修保障具有重要的意义。方案A在具有单一故障模式的装备中具有较好的应用效果,计算过程简单、预测效率高。而对于具有多种故障模式的T/R组件而言,由于在不同故障模式下指标反映了装备性能退化过程的差异性,如采用方案A将会导致一些剩余寿命预测信息的丢失,最终的预测精度不如方案B,因此对于具有多种故障模式的装备而言,方案B具有更好的预测精度。
5 结论
1) 在分析T/R组件故障机理和模式的基础上,通过关联规则方法提取了反映T/R组件性能状态退化过程的状态退化指标,并通过熵权法计算了状态退化指标权重,为进行有效的剩余寿命预测提供了基础。
2) 方案A将多个状态退化指标融合为一维的健康参数(HI),采用单指标下的基于相似性的剩余寿命预测方法对T/R组件剩余寿命进行预测。方案B通过计算不同指标对应的相似性,结合相似样本的剩余寿命,得到剩余寿命信息,通过融合多个指标对应的剩余寿命信息得到T/R组件的剩余寿命。
3) 算例仿真与分析对两种方案进行了对比,结果表明了两种方案都能够解决T/R组件的剩余寿命预测问题,方案B具有较高的预测精度。
