基于图卷积的骨架行为识别
2020-03-05董安左劼孙频捷
董安,左劼,孙频捷
(1.四川大学计算机学院,成都610065;2.上海政法学院,上海200000)
0 引言
随着视频大规模增长,视频人体行为分析成一个研究的热点。通常,人体行为可以通过外观特征、深度信息、光流、骨架序列来进行识别。骨架序列特征可以作为其他模态数据的重要补充。骨架模态的信息,对于不依赖场景和物体信息的类别,只包含行为动作本身的类别具有较好的区分度。人体的骨架关节点的坐标随着动作的变化而变化,例如起身和摔倒两个动作涉及到的骨架关节点坐标变化是完全不同的。
如图1 所示人体骨架关节点序列,节点与节点通过边相连接,可以构成一个图的表示。本文研究了基于图卷积神经网络的骨架序列行为方法,并在自采集的室内监护视频数据集上进行了实验及分析。
1 动作行为识别现状
动作行为识别具有广泛的应用场景,包括安防场景的异常行为识别,自动驾驶场景下行人的行为识别等。识别视频中人的行为类别是动作行为识别的主要任务。传统方法通过使用全局和局部特征识别任务行为已经取得了显著的进展,但是这些手工特征需要大量的人力和专业知识来开发有效的特征提取方法,无法在大型的数据集上很好的概括。
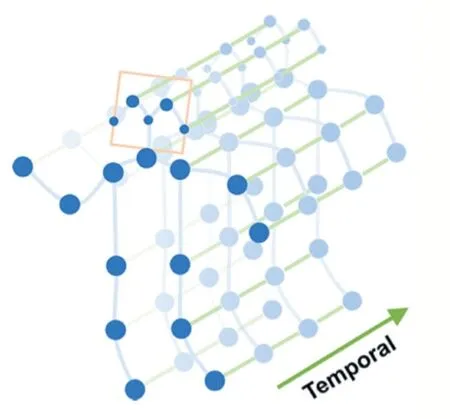
图1 人体骨架关键点序列
iDT[1]算法是深度学习兴起之前,在动作行为识别领域效果,稳定性最好,可靠性最高,最好的方法,不过算法速度很慢。近年来,使用深度学习技术进行特征学习,由于其强大的功能的能力而受到越来越多的关注。深度网络在动作识别中的成功也可以归因于将网络扩展到数以千万计的参数和大量标记的数据集。最近的深度网络在各种动作数据集上均取得了令人惊讶的高识别性能。
通过深度学习技术学习到的动作特征已得到广泛研究,近年来,开发用于动作识别的深度网络的两个主要变量是卷积运算和针对时序的建模,这产生了几种网络。
基于Two-Stream 的方法,从时间维度上,是对对视频序列中每两帧计算密集光流,得到密集光流的时序序列。从空间维度上,是利用RGB 视频关键帧的信息。使用两路CNN 分别对RGB 和光流进行训练,两路网络分别对动作类别进行识别,最后对两路网络的分类分数进行融合(直接平均或者使用SVM),得到最终的分类结果。
C3D 是由Facebook 提出的基于三维卷积的工作,使用三维卷积和三维池化构建网络。通过三维卷积,C3D 可以同时学习视频的时空特征,对运动信息和外观信息进行建模。由于省去了耗时的光流计算,C3D的速度也有效提升。
而基于骨架特征的行为识别因为其对光照和场景变换具有很好的鲁棒性,得到了越来越多的关注。通过姿态估计算法或高精度的深度摄像头也可以较为容易得获取到骨架特征。基于此,本文从骨架特征的角度来研究行为识别。
2 基于图卷积的行为识别方法
2.1 骨架序列的表示
OpenPose[2]是一个可以从视频中实时提取人体关键点的算法框架,本文只关注OpenPose 的输出,在一个视频中,可以有很多帧,每帧可以有多个人,每个人有多个关节点,每一个关节点有不同的特征(位置信息和置信度)。通过OpenPose 处理一个Batch 视频,可以得到一个5 维矩阵的特征表示(N,C,T,V,M),其中N表示视频的数量,C 表示关节点的特征(关节的坐标以及置信度),T 表示视频关键帧的数量,V 表示一个人的关节点的数量,M 表示一帧中人的数量。
2.2 图卷积神经网络分类模型
现实世界中,许多数据都是以图或者网络的方式存在的,例如社交网络、知识图谱、世界贸易网络、图卷积神经网络的提出,使得对这些非规则数据进行表示学习成为可能。本文采取了类似Kipf 等人[3]和Sijie Yan 等人[4]提出的图卷积方法,设计了如图2 所示的图卷积神经网络。模型主要分为三部分,输入模块、图卷积模块和输出模块。其中,输入模块是对2.1 小节中OpenPose 提取的骨架序列进行归一化,也就是将关节在不同帧下的位置特征进行归一化,做归一化的原因在于关节在不同帧下位置变化很大,如果不进行归一化不利于算法的收敛。第二个模块是交替使用GCN和TCN,对时间和空间维度进行变换。第三个模块是使用平均池化和全连接层对特征进行分类。其中GCN部分使用的公式是(1),D 表示关节点的度矩阵,A 表示关节点的邻接矩阵,X 是输入的骨架序列。公式的实际含义是以边为权值对节点的特征进行求加权平均。GCN 可以学习到空间中相邻关节的局部特征,而TCN 帮助学习到时间维度上关节变化的局部特征。


图2 图卷积神经网络
2.3 迁移学习方法
迁移学习是通过利用已经训练好的模型,使用其参数去初始化一个新的模型,从而提升新模型的性能。现实场景中,许多数据或任务是存在相关性的,通过迁移学习,可以将已经学到的模型通过初始化新模型的方式来分享给新模型,从而优化并加快模型的学习效率,不需要让新网络从头开始学习。DeepMind 在2018 年发布了大规模的视频动作数据集Kinetics[5],由于本文自采集的数据集较小,从零开始训练,数据量不够,所以本文先用Kinetics 训练好图卷积模型,将模型参数初始化新的图卷积模型(由于分类的类别不同,全连接层的参数不复用),在此基础上,再用自采集的数据集来训练新的图卷积模型。
3 实验部分
3.1 实验数据以及数据预处理
本次实验采用的数据集是模拟监护场景中,老人的起身、摔倒以及正常行走的视频,根据标注动作的起始和结束时间,利用FFmpeg 进行视频分割,得到的数据集总共包含1549 个5s 左右的视频,其中训练集1037 个,验证集512 个,训练集和验证集中三个类别各占1/3。然后利用OpenPose[2]提取视频中每一帧的骨架信息。
3.2 图卷积神经网络模型和训练细节
实验中采用图卷积神经网络输出维度的细节如表1 所示。空间维度是关节的特征,开始是3,时间的维度是关键帧数,开始是150,在经过所有时空卷积之后,关节的特征维度增加到256 维,关键帧的维度降低到38,最后使用平均池化和全连接层对特征进行分类,FC层神经元的个数取决于要分类的类别数。
在全连接层使用了dropout 技术避免过拟合,以0.5 的概率随机失活神经元。优化算法采用了随机梯度下降,学习率是0.01,每10 个epoch 衰减0.1。

表1 实验使用的图卷积神经网络架构
3.3 实验结果与分析
本文进行了三组实验,第一个实验室是利用大规模的视频动作行为识别数据集Kinetics 提取到的骨架信息进行训练图卷积神经网络,第二个实验是利用自采集的室内监护视频提取到的骨架特征对图卷积神经网络进行训练,第三个实验是在第一个实验得到的模型的基础上,进行迁移学习。识别的准确率定义如下:

实验一的结果如表2 所示,我们使用了Kinetics 数据集中的训练集提供的240000 个短视频,然后利用OpenPose 提取到骨架序列,进行训练图卷积神经网络,然后在20000 个验证集的骨架序列上进行了评估。观察实验结果,发现准确度并不高,远远低于常见的基于RGB 或者光流模态的方法,例如i3D[5]。分析原因,本文认为这是由于Kinetics 包含大量的类别都需要去识别与人体交互的物体和场景,例如打篮球这个动作,需要有篮球这个物体,例如踢足球,需要有足球场这个场景。而基于骨架的行为识别,能够对场景和物体本身不敏感,对动作本身有较好的区分度。

表2 Kinetics 视频数据集从头训练
实验二的结果如表3 所示,我们使用了自采集的室内监护视频数据集中的训练集提供的1037 个短视频,同样利用OpenPose 提取骨架序列,从头开始训练图卷积神经网络,然后在512 个验证集进行评估,得到0.78 的准确率。这符合实验一的分析,基于骨架的行为识别,对于不依赖场景和物体本身的动作类别具有较好的区分度。但这个精度还有提升的空间,分析其原因是数据量不够,基于此,我们进行了实验三。

表3 室内监护视频数据集从头训练
实验三的结果如表4 所示,我们利用实验一训练好的模型的参数初始化一个新的图卷积神经网络,然后再用训练集中1037 个短视频提取的骨架,训练新的图卷积神经网络,得到了0.9 的准确率。由于实验一的模型是基于大规模的数据集进行训练得到的,有更加丰富的知识,通过迁移学习,可以让基于小数据的任务性能提升。

表4 室内监护视频数据集迁移学习
4 结语
本文使用骨架模态的数据,基于图卷神经网络,进行人体动作行为识别。通过实验证明了基于骨架模态的动作识别,对于不依赖场景和物体的类别具有较好的区分度。使用大规模动作视频数据集提取得到的骨架信息来训练图卷积神经网络,再通过迁移学习的方式,对于小数据的任务性能提升具有很大的帮助。但是由于基于视频RGB 数据来提取骨架特征的这个过程,比较耗时,还不能做到实时,在未来的工作中,可以考虑把姿态估计网络和行为识别网络进行有效融合,减少整个过程的耗时。
