基于BLSTM 的诗词风格分类技术研究
2020-03-05张航何中市
张航,何中市
(重庆大学计算机学院,重庆400030)
0 引言
诗词,是指以古体诗、近体诗和格律词为代表的中国古代传统诗歌,是阐述心灵的文学艺术,而诗人、词人则需要掌握成熟的艺术技巧,并按照严格韵律要求,用凝练的语言、绵密的章法、充沛的情感以及丰富的意象来高度集中地表现社会生活和人类精神世界。作为中国文学的瑰宝,其风格的评判以及检索一直是历代学者关心的学术问题。而最主要和常用的诗词风格可以分为豪放风格和婉约风格两类。一般而言,具有数量少、形体小、色彩素、声音柔、味道淡、重量轻、速度慢等形式特征的事物更容易引起人的柔和意味,美学上往往称为“优美”,“指小巧、细腻、柔和的美”也称作婉约风格;具有数量多、形体大、色彩艳、声音粗、味道浓、重量沉、速度快等形式特征的事物更容易引起人的强烈意味,美学上往往称为“壮美”,“指巨大、粗犷、豪放的美”也称作豪放风格。以一句写雪的诗句为例:
“北国风光,千里冰封,万里雪飘”毛泽东,豪放风格
“小城风光,一里冰封,两里雪飘”李良炎[1],婉约风格
目前诗词分类研究中,诗词训练测试涉及到的数据量相对较少,而且应用的都是比较成熟的传统机器学习方法。随着互联网信息爆炸式的增长以及大数据时代的到来,基于深度学习神经网络(递归神经网络(RNN)、卷积神经网络(CNN)等)的自然语言处理技术和词嵌入技术受到了很多学者的热捧,并被广泛应用到了文本分类、情感分类等领域[2-3]。相比与传统的机器学习方法,深度学习自然语言处理技术能更好的对海量数据自动学习特征,同时能带来更佳的学习效果。但是,该方法在目前极少应用到古诗词风格判别上。本文通过整合诗词语料库,生成诗词字、词向量,运用深度递归神经网络成功构建适合古诗词风格分类的模型,并取得了目前更好的分类效果。
1 相关工作
诗词的处理问题实际从形式上也可以看作内容较特殊的文本处理问题。胡俊峰等人[4-5]开发了“唐宋诗计算机辅助研究系统”,以唐诗中的词汇为主要研究单位,实现语词检索、词频统计、意象索引。李良炎[1,6]提出了基于词联接的自然语言处理技术,并用于诗词语言的理解,成功的进行了诗词语料标注测试、诗词语言初级分析测试、诗词语言豪放与婉约风格的评价测试。易勇等人[7]通过将朴素贝叶斯与遗传算法相结合的方式,在以诗词每个字为最小单位的基础上,首次提出了古典诗词的豪放和婉约风格判别计算模型,并在精典诗词测试语料上取得了较好的效果。匡海波等人[8]从题材角度出发,将贝叶斯分类技术引入唐诗研究,取得较好的实验效果。钱鹏等人[9]提出了基于点互信息和LDA 的诗词主题分类方法,诗词主题与时代演变的关系上取得了较好的分类效果。胡韧奋等人[10]采用向量空间模型(VSM)将唐诗文本转换为向量,通过卡方检验进行词语特征选择,最后基于朴素贝叶斯和支持向量机算法构造文本分类器,平均分类准确率达到74.7%。
随着深度学习的兴起,Zhang 等人[11]首次将RNN神经网络运用到中国古诗词的生成中,并将整个诗词历史语料作为训练语料,在生成诗词字与行之间增加一定的约束条件,达到了比传统诗词生成系统更好的效果。Yi 等人[12]运用RNN 模型生成诗词绝句,并成功的加入了注意力机制,使诗词能同时学习到语义、结构、韵脚等信息。Wang 等人[13]在RNN 模型基础上,通过优化诗词字向量、引入注意力机制与混合训练,得到了可以根据关键词生产主题相关诗词的模型,取得了不错的效果。
2 诗词风格分类方法
诗词风格分类的流程如图1 所示,主要有3 个模块:①预处理:诗词文本自动分词,去除标点乱码等操作;②诗词数字化:诗词文本向量化表示;③训练RNN分类器:使用深度学习递归神经网络训练诗词文本风格分类器。

图1 诗词风格分类流程图
2.1 预处理
不同于英文单词之间以空格作为自然分界符,而中文只是字、句和段能通过明显的分界符来简单划界,这种没有空格作为词分界标志的问题造成了分词的歧义和困难。中文分词的准确与否,常常直接影响到文本分类结果的准确性。同理,在诗词风格分类中如何准确的分词也是提高分类效果的重要环节。易勇等人[7]认为诗词是特别凝练的语言,一般通过“字”就表达很复杂的事物和情感,并通过以字为单位的向量空间模型较好地表现了诗词的内容和情感。所以,以字为单位的全切分算法是一种可行的策略。但是,也有学者[10]认为诗词的词组如:“芳草”、“长堤”、“秋思”、“白云”、“秋风”等在当今时代已经被大量使用且在诗词中这些词组都有一定的隐喻意义,不宜切分。综合上述两种思想,本文以字和词两种方式同时进行诗词风格分类,验证各自的有效性。具体切分方式如下:
字切分:白日依山尽。
词切分:白日依山尽。
本文采用jieba 分词系统对古诗词进行分词系统来对诗词文本进行处理。
2.2 诗词文本向量表示
(1)向量空间模型
向量空间模型(Vector Space Model,VSM)由Salton等人[14]于20 世纪70 年代提出,并成功地应用于著名的SMART 文本检索系统。目前广泛的应用在文本分类、信息检索的各个领域。在VSM 模型中,一篇文章被抽象成一个由多个特征词构成的向量。假设有n 个特征词,每个特征词对应的权重为kn,那么文档d 就可以向量表示为d={ }k1,k2,…,kn。向量空间模型的关键是确定特征词以及特征权重,最常用的方法有基于统计的TF-IDF(Term Frequency-Inverse Document Frequency)算法。
(2)Word2Vec 模型
为了以更高效的算法获取词向量,Mikolov[15]提出了著名Word2Vec 模型。其目的不仅仅是建立语言模型,而是更偏向于获取高效的词向量。Word2Vec 可以在百万数量级的词表和上亿的数据集上进行高效地训练;而得到的训练结果——词向量,可以很好地度量词与词之间的语义相关性和相似性。Word2Vec 包含了两个网络模型:CBOW(Continuous Bag-of-Words)模型和Skip-Gram 模型,网络结构如图2 所示。Skip-Gram则可以看作是CBOW 的反向过程。CBOW 模型其实质是对前向反馈神经网络语言模型(Feed Forward NNLM),其变化如图2 所示。
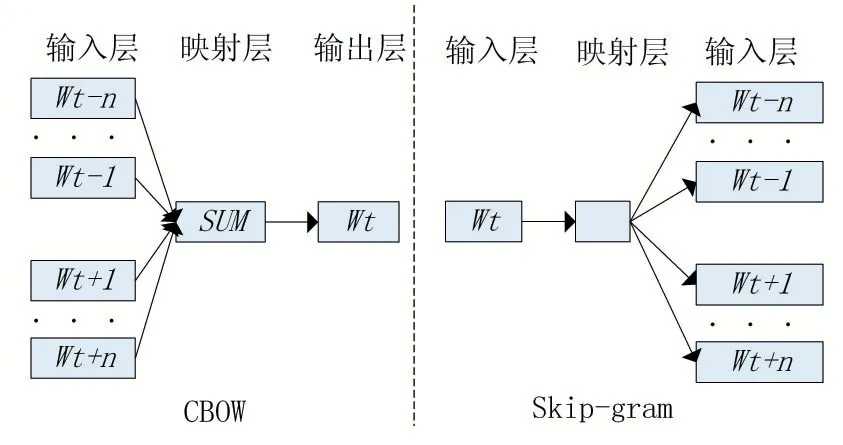
图2 CBOW和Skip-gram模型结构图
2.3 RNN分类模型
相比于神经网络语言模型,Word2Vec 做出了一下几点改变:①去掉了前馈神经网络语言模型中的非线性的隐藏层,使神经网络的映射层直接与输出的Softmax 层相连,保证效果的前提下减少了计算量。②映射层不再是将输入单词的词向量按顺序拼接,而是将词向量相加求和。③每个词不再单纯与其前面n 个词有关,也与其后面的n 个词相关,正真做到了利用上下文而不是上文。
本文在一定量的诗词语料的基础上,利用Word2Vec 构建一个更适合诗词文本的字、词向量。一首包含n 个词或字的诗词,wi表示第i 个字或词的向量,那么一首诗P 可以表示为
RNN 是专门针对序列化问题所设计的神经网络,其基本的网络结构如图3 所示。

图3 RNN的基本网络结构图
之所以称为循环神经网路,即一个序列当前的输出与前面的输出也有关。具体的表现形式为网络会对前面的信息进行记忆并应用于当前输出的计算中,即隐藏层之间的节点不再无连接而是有连接的,并且隐藏层的输入不仅包括输入层的输出还包括上一时刻隐藏层的输出。RNN 模型包含输入序列xT={x1…,xt-1,xt,xt+1,…,xT},输出序列yT={y1,…,yt-1,yt,yt+1,…,yT},隐藏层序列hT={h1,…,ht-1,ht,ht+1,…,hT}则根据网络可以得到xT到yT的映射关系如下:

其中,σ 是隐藏层的非线性激活函数,通常是sigmoid 分类函数。Whx是输入层与隐藏层的权重矩阵,Whh是前一轮迭代的输出作为条件计算得到的权重矩阵。Why是隐藏层与输出层的权重矩阵。bh和by分别代表隐藏层和输出层的偏差。
(1)LSTM 模型
当输入序列信息过长时,基础的RNN 模型会带来梯度爆炸和弥散的问题[16],长短期记忆神经网络(LSTM)将传统的神经元替换为有记忆系统的神经元(被称为记忆神经元),很好地解决了RNN 模型无法处理长序列信息的问题。图4 展示了记忆神经元计算隐藏层状态ht和神经元输出Ct的过程。

图4 LSTM神经元内部结构图
其中,遗忘门通过ht-1和xt对神经单元的上一状态信息进行操作。对于来自Ct-1的信息,当遗忘门ft的值为1 时,则将Ct-1的信息保留到Ct的计算中;若遗忘门ft的值为0,则将Ct-1的信息丢弃。具体的计算方法如公式(3)所示:

接下来,同样通过ht-1和xt计算出输入门it和候选状态的值,计算公式如下:

然后,在神经元上一状态Ct-1和候选状态~Ct的基础上,综合输入门it和遗忘门ft的值,可以获得神经元的当前状态值Ct,计算方法如公式(5)所示:

最后,由输出门和神经单元的当前状态值可确定神经单元的输出状态ht,计算公式如下:

(2)BiLSTM 模型
双向长短时记忆神经网络(BiLSTM)本质上是两个独立的LSTM 网络,一个网络从头到尾学习数据,另一个网络从尾到头学习数据。其网络结构如图5 所示。

图5 BiLSTM的网络结构图
图5 中,BiLSTM 网络中两个并行的隐藏层同时从正序和逆序两个方向处理序列信息。它的两个并行神经元分别从前向和后向两个方向计算隐藏层状态并合并到输出层。
前向传播隐藏层的计算公式如式(7)所示:

后向传播隐藏层的计算公式如式(8)所示:

然后,将两者合并到输出层可以得到yt可以表示为式(9):

3 实验与分析
本节主要评价了深度学习神经网络在古诗词分类中的可行性与效果,同时探究了诗词字向量、词向量以及生成词向量的语料对于诗词分类效果的影响。
3.1 实验设置
数据集:数据集包含了训练诗词字和词向量的语料库,诗词风格分类的训练集和测试集。
(1)诗词语料库(PoemCorpus):在文献的唐代诗词的语料基础上加入了宋、元、明和清代的诗词一共107MB 诗词数据,用于生成基于诗词语料的字向量和词向量。
(2)诗词训练语料(PoemTrainData):由专家①重庆大学文学院老师及古诗文网分类https://www.gushiwen.org/shiju/整理形成的带有风格标签的诗词数据集,其中豪放诗词1100 首,婉约诗词1140 首。
(3)诗词测试语料(PoemTestData):由两部分组成:①TestYi:文献[7]中提供的精典诗词语料豪放风格188首,婉约风格210 首,此测试集包含与诗词训练语料。②TestP:由专家(Professional:P)整理的诗词语料,豪放和婉约各300 首,与训练语料独立。
词向量:本文基于Google 的Word2Vec 工具,针对诗词的文言文结构生成了3 类字或词向量:
(1)基于诗词语料库的字向量(PoemCharacterVec:PCVec):在107MB 的诗词语料库上以单字为切分单位通过Word2Vec 工具训练的字向量,每个向量包含100个维度。
(2)基于诗词语料库的词向量(PoemWordVec:PWVec):用现代jieba 分词工具处理古诗词语料后,生成的古诗词词向量。向量维度同字向量。
(3)基于维基中文语料库的词向量(WikiWordVec:WWVec):基于维基百科中文文本语料(1.2GB),训练得到的中文词向量。
分类器:主要使用了2.2 小节中的LSTM、BLSTM分类器、文献[7]的基于遗传算法改进的朴素贝叶斯分类器。
LSTM 和BLSTM 参数:本文的神经网络分类模型基于Keras 工具包。经过多次实验验证得到网络模型的最佳参数:隐藏层神经元为256;Dropout 层参数设置为0.5;采用ADAM 优化器[17],该优化器可以根据网络训练参数自动调节学利率,能有效防止过拟合与局部最优解,初始学习率设置为0.001。
3.2 结果分析
本文方法及对比方法在诗词数据集上的准确率如表1 所示。
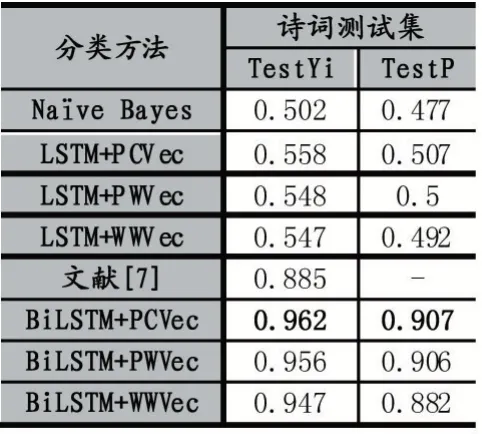
表1 不同分类器与不同词向量在两个诗词数据集上的准确率(%)
从表1 中可以看出在的精典诗词语料上,相比于朴素贝叶斯50.2%和文献88.5%的准确率,BLSTM 网络模型在基于3 种字或词向量的古诗词分类风格分类中都取得了更高的准确率,对应诗词字向量,词向量和维基百科中文词向量的准确率分别提高了7.7%、7.1%和6.2%,达到了96.2%、95.6%和94.7%。同时,相比于文献只在封闭数据集上做了测试,BLSTM 在开放的测试语料上也取得很好的准确率,最好达到了90.7%。充分证明了本文方法的在古诗词风格分类工作中的有效性。但是,LSTM 在相同环境下的古诗词风格分类中的表现显得差强人意,准确率只有50%,这样大的差距在现代文的处理中是几乎没有出现过的。由此推断出中文古诗词的上下文联系比现代文更加紧密,特征相关性也更强,而单向网络模型只能关联上文或者下文的信息,不能将两者结合,从而导致LSTM 的分类效果不佳。

表2 精典诗词语料上各分类器的ROC 面积
另一个重要的二分类问题的统计分析工具就是受试者工作特征曲线(Receiver Operating Characteristic Curve,简称ROC 曲线)。ROC 曲线下包含的面积代表了二分类选择正确的概率,面积越大说明分类方法越好。表2 给出了基于精典诗词数据集下的各个分类器的ROC 曲线面积大小,BLSTM 同样在3 个词向量下都获得了很高的ROC 面积率分别是99.48%、99.03%和97.90%。进一步验证了递归神经网络以及词嵌入技术在古诗词风格分类中的有效性、高效性。
更进一步,本文还研究了文本语料及词向量对诗词分类的影响关系。图6(a)、6(b)分别是BLSTM 模型下3 种字或词向量对应的精典诗词语料和专家语料的ROC 曲线。
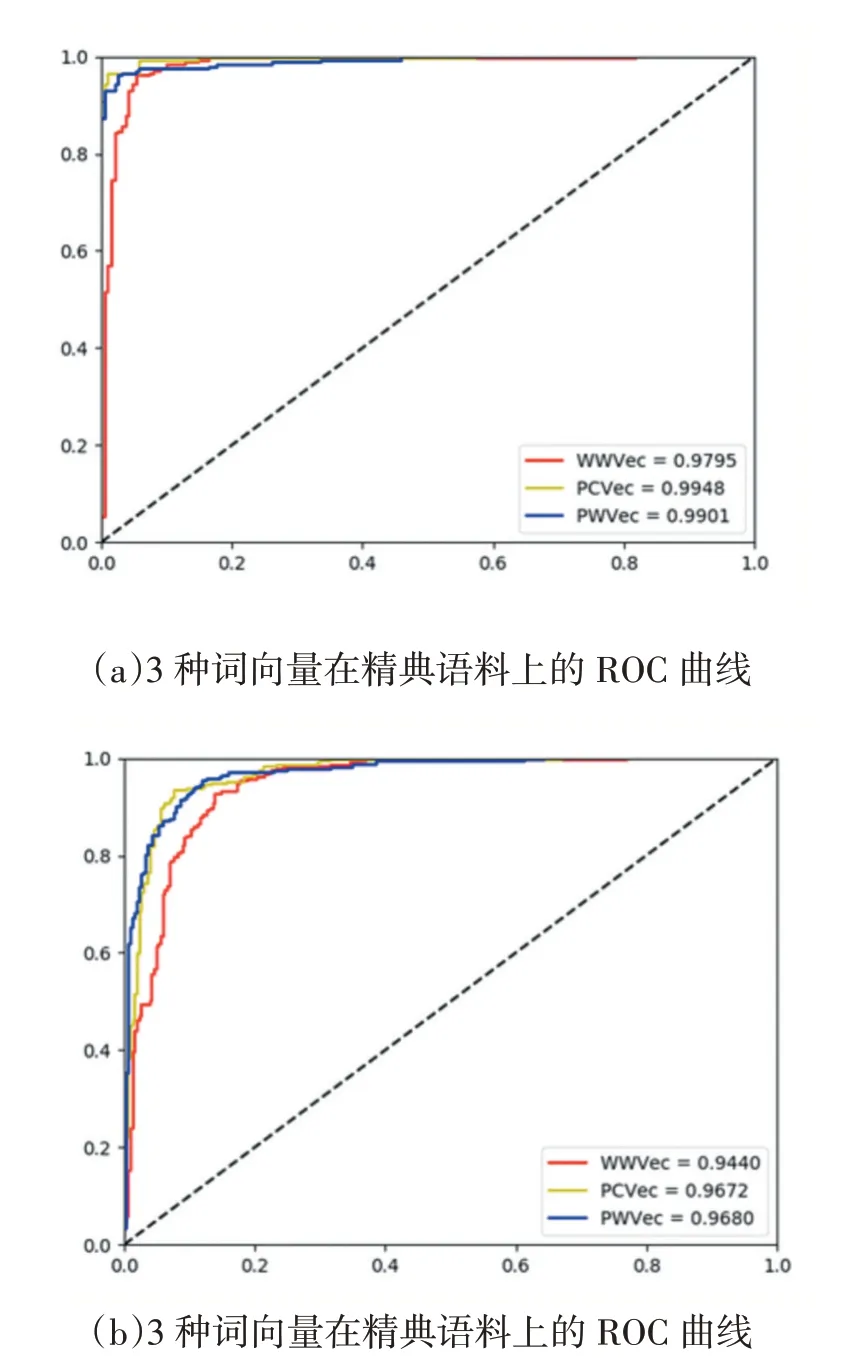
图6 3种词向量在两种语料下的ROC曲线图
从图中可以得出:在两个测试语料上,基于诗词语料的字向量和词向量的ROC 面积基本上差异很小,分别是99.48%与99.01%和96.72%与96.80%。而基于维基百科的中文词向量ROC 面积则要稍微低一点,分别是97.95%和94.40%。综合表1 中的分类准确率可以得出,基于诗词语料库的诗词字或词向量相比现代汉语语料效果更好。构建古诗词语料库并由该语料库生成词向量能提高古诗词风格分类的准确率,分类器的效果也会更好。同时,对于同样的诗词语料下的诗词的词向量和字向量获得的分类效果差别不大。其次,现代汉语文本语料生成的词向量在处理诗词文本同样可以获得较好的准确率,也大幅提高了之前传统的机器学习算法所获得的准确率。这一点也从侧面证实文献提出的诗词词组在现代文本中已经变得很常用,现代分词工具也能正常应用到古诗词分词中。
4 结语
本文在诗词语料库的基础上将深度递归神经网络成功运用到了中文古诗词“豪放”和“婉约”风格分类中。与传统的机器学习分类算法相比,在分类精确度上有大幅提高,最高达到了96.2%。同时,通过实验得到了以下几点结论:
(1)深度学习递归神经网络(RNN)能够对中文古诗词进行风格分类,效果比传统机器学习算法更好。
(2)现代文语料库在处理诗词风格分类中也能取得较传统机器学习方法更好的效果,但是,建立更大、更全面的古诗词语料库对古文诗词的分类更加有效。
(3)对于古诗词语料库的诗词,字切分和词切分对诗词风格的分类效果影响很小,都能取得很好的分类效果。
后期工作可以组建更大更丰富的现代中文语料,在中文文本语料库足够丰富可以预测,现代文的词向量可能会与古文语料词向量效果匹敌。对于诗词,进一步研究其更细腻的风格的判断,例如:诗词意向、诗词各个风格程度大小等。
