供应链溯源场景的区块链存储模型研究
2020-03-05张登平许亮
张登平,许亮
(四川大学计算机学院,成都610065)
0 引言
2008 年Bitcoin:A Peer-to-Peer Electronic Cash System[4]的发表标志着区块链技术的诞生。2009 年1 月4日比特币的第一个区块诞生,时至今日,比特币已经走过了10 年,其底层的区块链技术更是获得了社会各界的广泛关注和研究。2019 年10 月24 日下午,中共中央政治局就区块链技术发展现状和趋势进行第十八次集体学习,并指出把区块链作为核心技术自主创新重要突破口。区块链技术俨然已经成为互联网的又一个风口,各种“区块链+”模式的创新型应用层出不穷。
随着公众对食品安全,假冒伪劣产品等问题的关注度升高,供应链管理问题逐渐进入了公众视野,并演变成了国家政策。当前供应链的管理主要为中心化的方式,物流数据人为上传,并存储在中心化的数据库中。传统中心化的供应链管理方式存在诸多问题,其中最为突出的是数据可篡改,溯源困难和数据不透明。区块链作为一种分布式账簿,多方共同参与维护,天然具备数据不可篡改、去中心化、可追溯等特点。区块链技术与供应链管理相结合是一种比较具有说服力的方案,也是当前区块链应用领域的研究热点。
然而,区块链技术本身存在可扩展性差,交易吞吐量低下,数据持续增长等问题,这些问题限制了其在非数字货币交易以外的应用。本文着眼于区块链数据持续增长的问题,对现有的区块链数据存储模型进行了研究,并根据供应链溯源场景下的需求,提出了一种适用于供应链溯源场景的区块链数据存储模型。
1 研究现状
2017 年3 月7 日,丹麦航运巨头马士基成功完成了“区块链+商品追溯”应用的测试,该应用能够实时跟踪集装箱在供应链中的位置,从而保证了供应链数据的透明度和安全性,降低了供应链管理成本。此后,国内外“区块链+供应链管理”的实例不断涌现。国外比较有代表性的应用有IBM 与哥伦比亚物流解决方案提供商AOS 合作完成的“区块链与沃森物联网(Blockchain & Watson IoT)”、IBM 与沃尔玛合作完成的沃尔玛商品物流、Everledger 自主研发的钻石防伪验证数字账本等;国内主要有京东防伪溯源平台、京蓝科技的区块链农产品溯源、蚂蚁区块链等。诸多供应链管理与区块链结合的成功案例说明区块链在供应链管理应用方面的巨大价值。
比特币底层的区块链数据存储模型为链式数据结构(如图1)的存储模型,所有矿工节点存储完整的区块链数据,该模型的数据量随着系统的运行逐渐增加,截至2019 年10 月,比特币底层的区块链数据量已超250G,使得新加入节点的同步时间变得很长,同时网络中矿工节点的存储压力不断上升。针对区块链数据量不断增长的问题,相关学者进行了深入研究[5-7]。

图1 比特币的区块链数据存储模型
迷你区块链模型[5]使用账户树,迷你区块链和证明链三个组件构建了一条可以丢弃旧区块的区块链,使用账户树代替比特币的UTXO 来保证资产所有权,使用证明链保证了数据的可信。该模型因为只保存近一段时间的所有区块,所以能有效减少节点存储区块链的数据量。但是由于该模型会剔除旧交易,在交易溯源和交易验证方面的性能不能满足溯源场景的需求。
区块链存储容量可扩展模型[6]使用分布式分片存储的方法,先将区块链数据按照安全性能算法进行分片,然后分布式存储在一定比例的节点中,同时使用P链和POR 链来定位区块存储位置及其证明。该模型中,所有节点都没有完整的区块链数据,因此在一定程度上优化了区块链数据存储模型,减小了节点的存储压力。但是该模型在验证交易的时候,节点需要请求本节点没有的区块,该过程增加了验证的时长和复杂性;此外,数据的存储依靠验证节点的数据来决定数据存储的位置,一定程度上会造成数据的中心化存储,减少区块链的去中心化程度。
联盟区块链的容量优化模型[7]采用基于位置的分组设计,组建了联盟链。在每个分组中根据一个节点评价算法选取一个可靠且高性能的节点来存储完整的区块链数据,组内其他节点根据分布式一致性算法共同存储完整的区块链数据;组内存储节点还存储完整区块链的区块头链数据,用于当全节点宕机的时候下载完整的区块链数据,替代全节点。该模型因为只有一个节点存储所有的区块数据,其他组内节点存储部分区块链数据,降低了组内节点的存储压力,但是关于节点的可靠性评价算法尚有不足;同时由于组内节点不存储完整的区块链数据,在交易验证的时候受限于网络带宽,同样不适用于供应链溯源场景的应用。
2 供应链溯源场景下的数据存储模型
供应链溯源场景下,物流数据随供应链环节的增加呈指数级增加,因此要求底层的区块链系统有较高的交易吞吐能力。同时因为数据体量大,减少节点的存储压力的需求更为迫切。
本模型为基于网络分区的区块链数据存储模型,同一分区内的节点有主节点和普通节点两种角色,主节点负责存储整个区块链数据并参与区块链的共识过程,普通节点相当于比特币和以太坊中的轻节点,只存储少量的区块头链数据,不参与区块链数据的存储和共识过程,仅仅只是发送包含供应链数据的交易至全网。这里的网络分区是指抽象意义上的网络分区,即根据普通节点选择跟从的主节点划分区域。从全网来看,整个网络仍是P2P 的组网形式。
主节点的选取可以由大型企业,监管部门等提供,这个过程可以保证主节点的可信和高性能;普通节点则经过监管部门的审核,然后随机连接到不同的主节点,该连接过程可以对普通节点不可见以保证主节点的安全。
本模型的组网形式可见图2,该模型在供应链溯源场景下的普通节点占绝大部分,而这些节点都是轻节点,不存储所有的区块链数据,因此大幅降低了整个系统的存储压力。而主节点之间沿用了比特币等数字货币应用的组网形式,其抗恶意攻击的性能已经得到了验证,故而整个系统的鲁棒性可以得到保证。
3 模型运行过程与性能分析
3.1 模型的数据存储过程
本模型的工作流程如下。其中第二步,主节点收到分区内普通节点的交易后并不立即转发,主要是考虑到主节点可靠性比较高,如果交易转发出去之后再进行验证,则可能转发无效的交易浪费网络带宽。
(1)普通节点将供应链数据以交易的形式向全网广播;
(2)其他普通节点转发收到的交易;主节点收到交易后先验证,再将通过验证的交易向其他主节点转发;
(3)主节点将一段时间内的合格交易打包成区块,并开始参与共识过程;
(4)主节点将共识生成的区块记录在本地,并向全网广播区块头数据;
(5)普通节点将收到的区块头数据保存在本地。
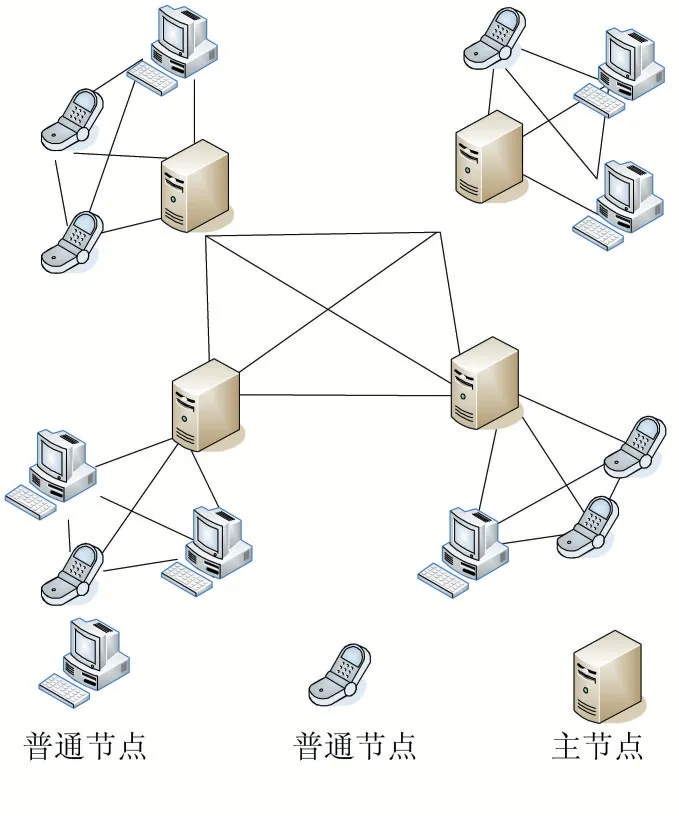
图2 基于网络分区的区块链存储模型的节点组网形式
3.2 性能分析
由于比特币等传统数字货币区块链采用公有链的形式,节点间不互信,节点只能存储整个区块链的数据才能保证整个系统的高可信度,故而系统存储压力大,单个节点的物理存储浪费严重,并不适用于数据体量更大的供应链溯源场景;迷你区块链模型保证了节点只存储最近一段时间的一部分区块,但是增加了证明链以及账户树的存储,虽然该模型降低了整个系统的存储压力,但随着时间增长,该模型的数据量仍是线性增长的,且因为对区块链数据的剪枝操作,使得交易的追溯变得不可行,也不适用于供应链溯源场景;区块链存储容量可扩展模型和联盟区块链的容量优化模型都大幅降低了系统的存储压力,在数字货币领域有一定的应用价值,但因为验证交易占用了网络带宽,提高了交易验证时长,对于交易吞吐量要求较高的溯源场景是不适用的。本模型跟联盟区块链的容量优化模型类似,都大幅降低了普通节点的存储压力,不同的是,本模型采用监管更为有力的联盟链形式,于是可以使普通节点不必参与到区块链的共识过程中来,解决了联盟区块链的容量优化模型的交易验证问题,更加适用于溯源场景的使用。各种模型间的性能对比情况见表1。

表1 各种模型间的性能对比情况
4 结语
本文在文献研究的基础上,通过对已有的区块链存储优化模型的对比分析,结合供应链溯源场景需求,提出了基于网络分区的区块链数据存储模型。通过分析,本模型能大幅降低系统和普通节点的存储压力,达到了区块链数据存储优化的目的,同时本模型因为去除普通节点的交易验证过程,节省了交易验证时间,提高了系统交易吞吐量,因此更加适用于溯源场景的应用。但是由于本模型参与共识过程的节点较少,一定程度上降低了系统的去中心化程度。未来的工作可以从两方面着手,一方面研究该模型下的共识算法的选择,以进一步提高系统的安全性和交易吞吐量;另一方面,可以考虑增加同一分区内主节点的个数及同一分区内主节点间的协调性,增强去中心化的程度,提高系统的可靠性。
