一种基于文本检测的书脊定位方法*
2020-03-04任明武
崔 晨 任明武
(南京理工大学计算机科学与工程学院 南京 210094)
1 引言
书脊(spine)图像,作为连接书刊封面、封底的部分,既包含书名、期号等关键书籍信息,又具有宽度小、便于批量处理的优点,在图书馆书架管理、自助借还书柜管理等应用场景下具有重要作用。为了减轻整理书柜的人力劳动、提高图书的整理和检索效率,实现自动书脊定位具有重要意义。
传统的书脊定位方法主要包括基于射频技术和基于图像处理技术两类。基于射频识别的方法需要对书脊进行芯片附着预处理,通过芯片与解读器信号产生的感应电流识别书脊信息,操作不够简便且成本高。因此,基于图像的书脊定位具有更实际的应用价值,并且受到了更多学者的关注。文献[1~5]直接通过检测较长直线对书脊进行定位,存在书脊图案干扰造成的多检问题;文献[6~7]基于所有图书倾斜方向相同的假设,通过霍夫变换得到倾斜角,根据倾斜角度方向对边缘图像进行滤波,从而去除书脊图案轮廓,然后通过直线检测对书脊进行定位;文献[8]通过检测平行线段对延伸线段检测书脊角点进行定位;文献[9]通过小波分析去除书脊图案轮廓,然后进行直线检测定位;文献[10]通过建立状态机模型,判断图像中的每个像素属于书脊边缘、书脊文字、文字背景还是书脊间隙。上述方法基本都依赖于梯度图进行检测,缺点在于对光照敏感,当相邻书脊颜色对比度过小、光照不足或相机过曝时容易发生漏检。文献[11]通过字符检测对书脊进行定位,较好地解决了多检、漏检问题,但是该方法假设所有书脊倾斜角度相同,仅沿一个方向合并检测到的字符,不适用于实际书脊多方向倾斜的书架场景。
基于上述分析,为了减小光照影响、能够定位不同倾斜角度的书脊,本文提出一种基于字符检测的书脊区域粗选方法,然后结合支持向量机(SVM)算法[12],以方向梯度直方图(HOG)[13]为特征,精选正确的书脊区域,分割出书脊图像。
2 基于文本检测的候选书脊区域定位方法
本文首先使用基于序贯分割(sequential algorithm)的方法检测单排书脊图像上的字符区域,然后在检出的字符中找到最可能同属于一本书的字符集合,下文将称同属于一本书的字符为相似字符,然后根据相似字符集合计算书脊的候选区域。
2.1 基于序贯分割的文本检测方法
目前的文本检测算法主要分为基于连通区域的文本检测和基于深度学习的文本检测两类。基于连通区域的方法主要包括笔划宽度变换算法(SWT)[14]和最大稳定极值区域算法(MSER)[15],使用这两种方法检测汉字中的非独体字时,需要进一步进行字内合并,在书架场景中,相邻书脊的字符由于距离过短可能对字内合并造成干扰,合并方法的稳定性将难以保证。基于深度学习的方法使网络模型自动学习书脊图像特征,具有更好的检测效果,但是需要提供具有代表性的、足够数量的训练样本,而书脊常常具有各式各样富有设计感的字体,使用基于深度学习的方法也将难以保证检测的稳定性。
基于上述分析,本文采用基于序贯分割的文本检测方法,该方法能够能够保证字符不漏检,同时较好地实现字内合并,算法描述如下:
算法1基于序贯分割的文本检测
输入:灰度图像及图像大小
输出:字符外接矩形数组
1:function SeqGetChar(Image,width,height)
2:thres[n]←{t1,t2,…,tn} △二值化阈值序列
3:foreach t in thres do
4: binImage← Binarize(Image,width,height,t)
5: mark[width*height]←{0}
6:foreach pixel in binImage do
7: if mark[pixel]==0 then
8: push RegionGrowing(binImage,width,height,mark,pixel)into Rects
9: end if
10:end
11:end
12:RemoveNonCharRects(Rects)
13:return Rects
14:end function
15:
16:function RegionGrowing(binImage,width,height,mark,pixel)
17:color← binImage[pixel]
18:UpdateRect(pixel)
19:push pixel into S
20:while S is not empty do
21:pop a pixel p from S
22: mark[np]=1
23:UpdateRect(pixel)
24: foreach pixel np in Neighborhood(p)
25: if color==binImage[np]then
26: push np into S
27: end if
28:end
29:end
30:return S
31:end function
其中,本文将输入图像统一按比例缩放使其高度为500,从而在保证检测率的同时提高算法速度;本文选择的thres序列是以20为公差的、以20和240为首项和末项的等差数列;Binarize函数实现灰度图二值化,灰度值小于阈值的像素置为0,反之置为255;mark数组用于记录图中的每个像素是否已被归为某一连通域;RegionGrowing函数通过区域增长算法合并二值图中灰度相同的连通域,同时返回连通域的外接矩形的四边坐标(四边坐标指上下边的y坐标和左右边的x坐标,在每个像素新加入连通域时通过调用UpdateRect函数得到),区域增长算法中的Neighborhood取像素的八邻域;RemoveNonCharRects根据外接矩形的边长、长边与短边的比值、是否被其他矩形包围来去除不是字符的连通域。
序贯分割的方法和MSER相似,区别在于MS-ER更精确,只保留最稳定的字符边缘,而本文对字符检测的精确性要求较低,允许多检、误检(后期通过SVM分类器筛选去除),只要保证没有漏检的区域即可,因此本文保存了每一个阈值下的所有候选字符轮廓,如果存在嵌套则留下最外层的轮廓。改善字内合并的原理在于字符内部由于光照会产生一定的倒影,所以在阈值改变的过程中,左右结构或上下结构的字会逐渐连接为一体,如图1所示。如果应用场景的光照影响没有这么明显,则可以通过闭运算对临近的字内结构进行合并,然后再进行检测。图2为本文检测结果与SWT和MSER算法的对比图,可以看出字内合并取得了较好效果。

图1 阈值为180和240时的二值图像

图2 从左到右依次为本文算法、SWT、MSER算法检测结果

2.2 基于相似字符配对的候选书脊定位方法
根据先验知识,本文将符合以下条件的两个字符判断为相似字符:
1)相似字符的外接矩形宽度之比在1/2~2倍之间;
2)基于图书竖直摆放或偏离竖直方向的倾斜角不超过45°的假设,相似字符的外接矩形在宽度方向存在重叠、在高度方向不存在重叠;
3)相似字符中心点连线距离不超过字符宽度的3倍。
在符合上述条件的前提下,根据字符宽度相似度和字符外接矩形宽度方向的重叠程度对相似字符对的相似程度进行定量评估,具体计算方法如下:

由于字符宽度的相似程度在相似字符评估中具有重要作用,所以本文优先对宽度相近的字符判断相似度,即在进行相似字符配对之前,首先把所有字符外接矩形按照宽度从大到小排序,然后对排序后的每个字符计算其相应的配对信息,具体算法如下:
算法2相似字符配对算法
输入:字符外接矩形数组
输出:相似字符对数组
1:function MakePair(Rects)
2:set all SimilarRectPairs.smallerId-1
3:set all SimilarRectPairs.biggerId-1
4:set all SimilarRectPairs.score 0
5:sort Rects by width from big to small
6:for i← 0 to n-1 do
7: for j← i+1 to n-1 do
8:if IsSimilar(Rects[i],Rects[j])==true then
9:SimilarRectPairs[i].smallerId=j
10: SimilarRectPairs[j].biggerId=i
11: SimilarRectPairs[i].score=ComputeScore(Rects[i],Rects[j])
12: break
13: end if
14:end
15:end
16:return SimilarRectPairs
17:end function
算法记录了每个字符的3项配对信息:比自身宽度更大的相似字符、比自身宽度更小的相似字符、与比自身宽度更小的相似字符的相似度得分,若没有找到与自身相似的字符则得分为0。IsSimilar函数基于上文三条判据实现,ComputeScore根据式(3)实现。上述信息用于通过相似字符对获得相似字符集合,然后根据集合中每个字符的中心点进行最小二乘直线拟合,结合集合内的字符最大宽度得到候选书脊区域,具体算法如下:
算法3基于相似字符配对的候选书脊区域定位
输入:相似字符对数组,字符外接矩形数组
输出:书脊候选区域数组
1:function MakeCandidateSpines (SimilarRectPairs,Rects)
2:while SimilarRectPairs is not empty do
3:set SimilarRectSet empty
4: maxScoreId ← FindMaxScoreId(SimilarRectPairs)
5: push Rects[maxScoreId]into SimilarRectSet
6: FindSimilarRects(SimilarRectSet,SimilarRectPairs,maxScoreId,Rects)
7: oneSpine← ComputeOneSpine(SimilarRectSet)
8: DeleteCharRectsOnThisSpine (SimilarRectPairs,SimilarRectSet)
9:push oneSpine into CandidateSpines
10:end
11:return CandidateSpines
12:end function
13:
14:function FindSimilarRects(SimilarRectSet,Similar-RectPairs,maxScoreId,Rects)
15:smallerID←SimilarRectPairs[maxScoreId].smallerId
16:biggerID ← SimilarRectPairs[maxScoreId].biggerId
17:if smallerID!=-1 then
18: push Rects[smallerID]into SimilarRectSet
19: FindSimilarRects(SimilarRectSet, SimilarRect-Pairs,smallerID,Rects)
20:end if
21:if biggerID!=-1 then
22: push Rects[biggerID]into SimilarRectSet
23: FindSimilarRects(SimilarRectSet, SimilarRect-Pairs,biggerID,Rects)
24:end if
25:end function
其中,FindMaxScoreId函数返回相似字符对数组中分数最高元素索引;FindSimilarRects函数通过递归,把所有直接或者间接相似的字符加入相似字符集合,即A与B互为相似字符、B与C互为相似字符,则ABC都加入相似字符集合;ComputeOneSpine函数通过相似字符集合中每个字符的中心点坐标进行最小二乘直线拟合,把拟合直线分别向左、向右平移,使得平移后的直线与拟合直线的距离为集合中的最大字符宽度,得到两个直线方程作为书脊区域的左边界和右边界,由于本文假设输入为单排书脊图像,所以书脊区域的上下边界即为输入图像的上下边界;DeleteCharRectsOnThisSpine函数将所有中心坐标位于书脊区域内的字符从相似字符对数组中删除,从而保证找到的书脊区域不重复;返回的CandidateSpines是一系列书脊区域的左右边界的直线方程,左右边界直线平行,直线方向与竖直方向的夹角即为书脊的倾斜角,本文首先切出书脊区域的外接矩形,然后根据倾斜角旋转,得到最终的候选书脊图像,算法效果如图3所示。
3 基于HOG和SVM的书脊筛选方法
由于本文对字符检测部分的准确性要求较低,候选书脊中可能出现书脊倒影区域、书柜干扰区域、封面干扰区域等非书脊图像,如图4所示。所以本节采用SVM模型基于图像的HOG特征筛选真正的书脊区域。

图3 基于相似字符集合拟合得到的书脊区域直线表示,以及矫正分割得到的候选书脊图像

图4 非书脊图像示例
支持向量机是一种二分类模型,定义为在特征空间上使两类样本间隔最大的线性分类器,具有泛化能力强、适合小样本训练集的优点。HOG特征是一种在图像处理中用于进行物体检测的特征描述子,具有旋转不变性、光照不变性的优点。本文使用候选书脊图像的HOG特征作为支持向量机的输入特征,以90幅书脊图像为训练集正样本、60幅非书脊图像为负样本训练SVM分类器,对书脊图像和非书脊图像进行分类。图5为具体训练过程。
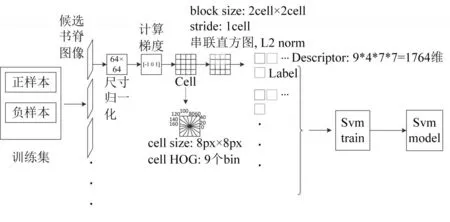
图5 HOG+SVM训练书脊图像分类器流程图
4 实验结果
本文实验环境为64位Windows 10操作系统,i7CPU(2.40GHz),8G内存,使用IDE为VS2013,算法使用C++结合libsvm库实现。采集实验图像50幅,每幅图像包含1~8本书不等,共包含201个书脊图像,考虑了不同光照、不同摆放角度、低颜色对比度的相邻书脊、部分遮挡、拍摄不全等多种情况,如图6~9所示。实验平均处理一幅图像的时间为2.2s,以分割出的书脊图像内容能够被百度OCR接口识别、不漏检多检、不重复为标准,书脊定位成功率为98%,在书脊花纹复杂且前后遮挡的场景下出现了分割失败的情况,我们计划结合图像局部二值化和直线检测对此进行改进。

图6 多种倾斜角度摆放测试结果

图7 与图3相同摆放姿态、不同光照拍摄测试结果

图8 反光干扰、封底干扰、拍摄不全干扰测试结果

图9 书间遮挡情况测试结果
5 结语
本文提出了一种基于文本检测的书脊定位方法,避免了传统的基于直线检测的方法易受光照影响的问题,提出了合并相似字符的算法,能够定位不同倾斜角度的书脊,在实际项目采集的数据集上表现良好。本文数据集小,相机与书架相对位姿固定,书架背景简单,所以虽然取得了较好的定位效果,但是在通用性方面仍需提高,首先,本文假设书脊偏离竖直方向的角度不超过45°,如果超过45°可将图像旋转90°再检测,但是这种方法的准确性尚未得到验证,此外,算法中的一些参数是根据书脊区域占整幅图像的比例确定的,所以在相机距离书架远近改变时,参数将不再适用,影响定位成功率,后期我们将尝试自适应参数算法,或者对输入图像进行缩放、分割等处理,使其与既有参数相适应。
