基于Kubernetes的动态负载均衡机制研究与设计*
2020-03-04陈莉君
平 凡 陈莉君
(西安邮电大学计算机学院 西安 710121)
1 引言
随着云计算技术的飞速发展,以Docker为代表的容器技术因其轻量级、可迁移、可快速部署等特性而得到了业界的广泛应用[1]。Kubernetes则因其优秀的容器管理能力和轻量开源的特点成为了业界容器编排系统的首选[2]。然而Kubernetes只实现了对于Pod的静态调度,缺少集群节点的动态负载均衡。在集群长时间运行的场景下,会出现集群中节点的负载不均衡的情况从而引发诸多问题[3]。
由于Kubernetes容器云平台备受关注,其负载均衡领域已经有诸多学者做了大量研究[3~9]。杨鹏飞[4]设计了应用对资源有不同敏感度的负载均衡模块,解决了应用对资源有不同实际需求情况下的调度问题,以减少碎片化的资源。彭丽苹、吕晓丹、蒋朝惠等[5]对Ceph集群数据副本存储策略进行改进,建立了一个资源调度优化模型,在此基础上提出了基于Docker云平台的应用容器部署算法和应用在线迁移算法。杨欣[6]实现了一种自动化的智能弹性负载均衡机制,通过分析预测机制和资源池模块来解决弹性伸缩过程中的滞后性问题。但上述文献都没有考虑到云平台的动态负载均衡,致使集群长时间运行情况下会出现负载极不均衡的情况。唐瑞[7]提出了抢占式调度策略以及简单的动态负载均衡策略,但是针对具体待重新调度Pod的选择方案还有待改进。
本文提出了针对Kubernetes的动态负载均衡机制,解决集群长时间运行情况下负载可能出现的不均衡问题。首先提出将高于集群平均负载的节点集合为高负载队列。然后在高负载队列中挑选出合适的可被重新调度的Pod删除。在选择被重新调度的Pod时,依据先过滤,后排序的原则。使Pod在Kubernetes的调度器下做新的调度。以此保持Kubernetes动态的负载均衡。
2 Kubernetes调度器概述
Kubernetes动态负载均衡的核心在于让Pod做重新调度。重调度的一个相关组件是Kubernetes调度器。调度器的作用是将待调度队列中的Pod依据特定的调度策略绑定给集群中某一个节点,然后将绑定的结果信息写入到Etcd中。随后,该节点中的Kubelet通过APIServer监听到此绑定事件,Kubelet就会在该节点中依据Pod的详细信息从镜像仓库拉取对应镜像并启动容器。Kubernetes调度器框架如图1所示。

图1 Kubernetes调度器框架图
Kubernetes的调度流程分为以下两步:
1)预选调度:检查所有可用节点,筛选出符合Pod要求的节点。这些节点成为下一流程的候选节点。预选策略如:NoDiskConflict、PodFitsResources等。
2)优选调度:在流程1)筛选出来的节点中进一步进行筛选。采用优选策略计算出每一个候选节点的得分,得分最高者为最适合被调度的节点。优选策略如:LeastRequestedPriority、BalancedResourceAllocation等。
3 动态负载均衡机制的研究与设计
3.1 动态负载均衡机制的研究
3.1.1 集群中节点主要性能指标的数学表示
在Kubernetes集群中,CPU和Memory是节点性能的主要衡量指标。集群中的n个节点可表示各节点的资源配额表示为集群中标号为i的节点资源配额表,其中c,m分别表示第i个节点的iiCPU配额与Memory配额。集群中通过规格系数λi衡量各节点的性能。性能越好,规格系数λi越高。假设集群各节点的规格系数向量为,其中标号为i的节点的规格系数分别表示标号为i的节点的CPU和Memory的规格系数。因此,标号为i的节点的资源配额可表示为q是一个对角矩阵,C、M是常量系数。
例如对于一台双核2G内存的节点和一台八核16G内存的节点,可将两者的则两者的规格系数分别为集群中各节点的资源配额可以表示为
通过设置规格系数,可以将不同规格的节点进行区别对待。
以上描述涉及的各参数如表1所示。

表1 集群主要性能指标参数表示
3.1.2 集群负载均值
集群负载均值指集群CPU负载均值和Memory负载均值。用来衡量集群整体的负载情况。
集群CPU负载均值avCpuUsed由节点的CPU规格系数加权平均表示为

其中cpuUsedi表示标号为i的节点的CPU使用率,αi是标号为i的节点的CPU规格系数,
集群Memory负载均值avMemoryUsed由节点的Memory规格系数加权平均表示为
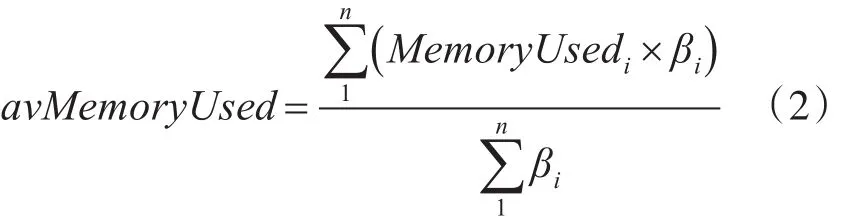
其中memoryUsedi表示标号为i的节点的Memory使用率,βi是标号为i的节点的Memory规格系数,i∈{1,2,…,i,…,n}。
各参数的描述见表2。
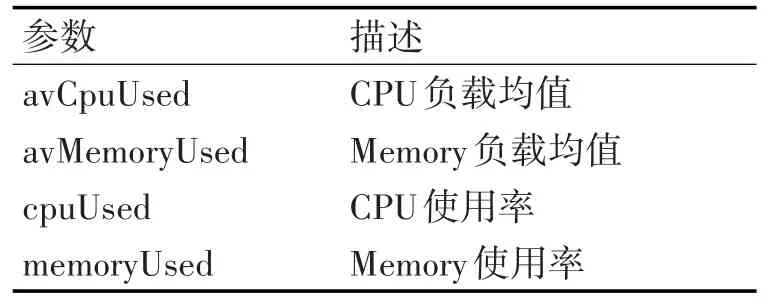
表2 集群负载均值相关参数表示
3.1.3 动态负载均衡的触发方式
本文提出的动态负载均衡机制有三种触发方式:
1)集群节点扩容触发:当集群增加节点的数量时,触发Kubernetes的动态负载均衡。
2)节点域值触发:当集群中节点的某资源使用率达到预设的阈值时(如CPU使用率超过90%),触发Kubernetes的动态负载均衡。
3)定时机制:定时触发Kubernetes的动态负载均衡。
3.2 动态负载均衡机制的设计
3.2.1 节点CPU和Memory得分
为了准确衡量集群中各节点的相对负载状况,对集群中各节点的资源(CPU和Memory)做分值计算。
标号为i的节点CPU负载得分计算公式为

Memory负载得分计算公式为

节点的负载总得分计算公式为

各参数描述见表3。
CPU和Memory负载得分区间为[ ]0,+∞ ,用CPU来举例说明资源得分的具体含义,Memory得分含义类似。cpuScorei分值大于0表示该节点的CPU负载情况优于集群CPU平均负载情况,小于0反之。得分越高,资源情况越好,通过得分可以判断节点相对于集群整体的相对负载情况。负载总得分scorei用来进行节点的排序。

表3 节点得分相关参数表示
3.2.2 建立高负载队列
若是定时或节点扩容触发的动态负载均衡,则依据各节点CPU和Memory的得分,将CPU和Memory得分为负数的节点筛选出来。并建立高负载队列。即高负载队列中的节点满足公式:

高负载队列示例如图2所示。

图2 高负载队列示例
若是阈值触发的动态负载均衡,除了要重复以上步骤计算得分并建立高负载队列以外,还要将该触发阈值的节点加入到队首。
节点高负载队列的数据结构表示如下:
type queue_node struct{
nodeId int //节点的唯一标识符
nodeName string //节点名称
score float32 //节点的负载总得分
server *next //服务器指针
}
高负载队列使用优先队列实现,在优先队列中有插入、删除、查找三种基本操作。
每次触发动态负载均衡,都查找得分最低的节点,待删除其上的某些Pod之后,若节点达到了要求,则将此节点从队列中删除。此时再查找得分最低的节点,删除其上的某些Pod之后,再将此节点从队列中删除,以此类推,直到处理完其中的所有节点。
对于处理触发阈值的节点,要将该节点中的Pod删除直至该节点不会再阈值触发动态负载均衡为止。
3.2.3 选择重调度的Pod
高负载队列建立之后,需要从得分最低(触发阈值)的节点中选择需要被重新调度的Pod删除。选择重调度的Pod需以下步骤:
1)筛选掉不可被重新调度的Pod
有状态且状态信息存储于本地节点中的应用是不能被重新调度的,因为该Pod在被重新调度到其它节点上运行时状态信息将会丢失,当业务对数据敏感时,此Pod的重新调度是不被允许的。
重启策略为Never的Pod不可以被重新调度,因为重启策略为Never的Pod在被节点删除之后是不会自动再被重新在新的节点上部署的。
2)剩余Pod做优先级的划分
描述Pod重要性的参考有两个:Pod的重启策略与服务资源质量。
Pod 的重启策略:Always、Onfailed、Never。其中Never的Pod不能被重新调度。
以重启策略作为Pod优先级的划分,是因为重启策略为Always的Pod无论何种情况,只要被删除就会立即被重新调度,而重启策略为Onfailed的Pod只有当它异常退出时调度器才会重新调度。因此一般情况下,在集群中以重启策略为Always部署的Pod重要性高于以Onfailed部署的Pod。当要选择被重新调度的Pod时首先应选择重启策略为Onfailed的Pod。
Pod的资源服务质量:Gurantee、Burst。当Pod的资源requests=limit时,资源服务质量为Gurantee。当Pod的资源requests<limit时,资源服务质量为 Burst[10]。
资源服务质量为Guranteee说明该Pod对资源服务质量的要求高于为Burst的Pod。所以资源服务质量为Gurantee的Pod重要性高于资源服务质量为Burst的Pod。因此当要选择被重新调度的Pod时首先选择资源服务质量为Burst的Pod。
综上,Pod重新调度的优先级划分如表4所示。

表4 待重调度Pod的优先级
以此顺序来选择被删除的Pod。
3.2.4 总体设计
如图3所示,本文针对Kubernetes的动态负载均衡机制共有三种触发方式:定时器、集群节点扩容、节点触发阈值。触发集群的动态负载均衡之后,首先集群会收集并分析负载信息,并依据上述得分建立节点的高负载队列。若是节点资源超出阈值触发的动态负载均衡,则将触发阈值的节点插入到高负载队列队首。最后从高负载队列中选择适合被重新调度的Pod做重调度。

图3 动态负载均衡机制设计图
4 实验结果与分析
4.1 实验环境表格
本次实验使用三台规格系数不同的服务器搭建的版本为v1.4.9的Kubernetes作为实验平台。用Guestbook作为实验用的应用,该Guestbook经过修改,将Web前端容器、Redis-Master、Redis-Slave放在同一个Pod中。Web前端容器向Redis-Master中写入数据,然后Redis-Master将数据同步到Redis-Slave中,Web前端容器再从Redis-Slave中读出数据。压力测试工具使用Webbench。实验会通过客户端向集群APIServer发出创建应用命令以及压力测试。
集群主要软件的描述如表5所示。
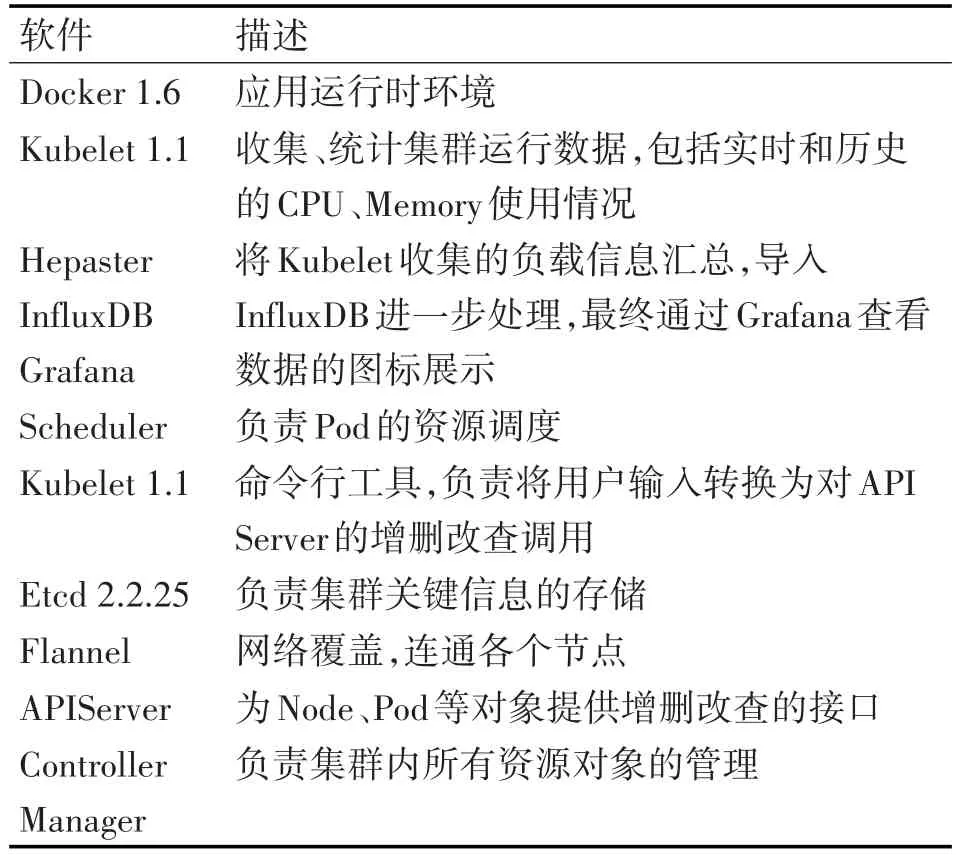
表5 集群主要软件描述
4.2 实验步骤
1)通过客户端向集群的APIServer创建12个GuestBook应用,之后每10min创建12个(三种重启策略与两种服务资源质量各两个且各应用requests值不同),直至创建60个GuestBook。
2)在客户端用Webbench向各工作节点并行发出Web请求,请求数由随机函数随机生成。
3)在Master节点上监测并记录各节点的资源使用情况,记录方式为刚创建GuestBook时记录一次,创建9min后一次。这样可以具体了解刚创建完应用时的节点负载情况与服务一段时间之后的节点负载情况。
4)定时动态负载均衡,在创建应用之后的5min进行动态负载均衡。
5)使用Kubernetes的默认调度算法重复步骤1)~3)。
4.3 实验结果与分析
含有动态负载均衡机制的调度算法如图4所示,本文共做了10次检测,由于前两次检测时Pod的数量较少,容易出现访问集中于某节点的情况,所以可见前两次检测节点的得分较为分散。而由于在集群运行中进行动态的负载均衡,所以集群中节点的得分在后面的检测中逐渐趋于0。也即负载趋于均衡。

图4 含动态负载均衡机制的调度算法各节点综合得分变化曲线图
Kubernetes的默认调度算法的检测结果如图5所示,同样由于前两次检测时Pod的数量较少,出现了访问集中于某节点的情况,所以前两次访问也较分散。从第3次检测开始,我们可以看到奇数次检测负载较为均衡而偶数次检测负载比较分散。这是因为奇数次检测时,集群刚被默认调度算法调度了新的Pod,而偶数次检测时集群已经运行了一段时间了。

图5 默认调度算法各节点综合得分变化曲线图
综合以上实验结果,我们可以看出Kubernetes的默认调度算法在静态调度时可以很好地维持集群的负载均衡度,但是在集群长时间运行的情况下集群的负载会出现较大的波动。本文提出的动态负载均衡机制结合静态调度与动态调度,可以较好地维持集群系统的均衡性,保持集群系统的稳定。
5 结语
由于当前Kubernetes的调度器仅提供了基于资源申请值requests的静态调度策略,而缺少依据节点实际负载值进行集群节点动态负载均衡的机制。本文提出了一种基于节点实际负载值的集群动态负载均衡机制,通过定时、集群扩容及节点阈值的方式触发集群的动态负载均衡。通过对集群各节点分值的计算建立节点的高负载队列,并从高负载队列中选择合适的Pod进行重调度,以此达到动态负载均衡的目的。但是由于集群在运行当中需要做Pod的重新调度,所以会增加一定的计算负担,考虑到增加的计算负担与节点的数量是简单的线性关系,因此这个计算负担是完全可以接受的。本文的实验结果表明,相比于Kubernetes默认的调度算法,含有动态负载均衡机制的调度算法能够更有效地保持集群负载的均衡。
