一种基于部件CNN的网络安全命名实体识别方法*
2020-03-04秦永彬陈艳平
魏 笑 秦永彬,2 陈艳平,2
(1.贵州大学计算机科学与技术学院 贵阳 550025)(2.贵州大学贵州省公共大数据重点实验室 贵阳 550025)
1 引言
在网络安全方面,研究者们常采用流量控制、内容解析监控的网络监测系统及时阻止内部计算机的敏感信息泄露。而网络攻击的形式具有复杂多变性,现有网络监测系统无法保证及时监测和预警这些动态变化的攻击类型。部分研究者提出采用知识图谱技术构建网络安全知识图谱。网络安全命名实体识别是网络安全知识图谱构建的基础。
国外英文网络安全领域命名实体识别技术的研究已经发展多年,研究者们提供了许多性能优良的工具和系统。Mulwad等[1]利用标准命名实体识别工具OpenCalais抽取网络安全相关网页文本中的组织机构、软件,并采用支持向量机(Support Vector Machine,SVM)抽取计算机漏洞相关概念;Joshi等[2]使用CRF识别英文网络安全公告和相关博客中的软件、硬件、文件等网络安全实体;Lal等[3]采用基于Stanford NER的条件随机场模型识别来自各种数据源的安全相关术语来解决处理非结构化文本,识别英文网络安全实体;Bridges等[4]利用国家漏洞数据库(NVD),对英文非结构化的安全信息文本进行自动化的网络安全实体标注,并采用最大熵模型识别网络安全实体中的软件、漏洞编号和相关术语;Mittal等[5]对推特(Twitter)中的网络安全漏洞、受影响的软件、硬件和组织机构等网络安全实体进行识别。在网络安全实体识别问题中,国外技术逐渐成熟,推动了网络安全领域实体抽取的发展。
目前,通用领域的命名实体识别方法已经非常成熟。在通用领域中,常用的机器学习方法有条件随机场[6~7]、隐马尔可夫[8]、最大熵[9]等。除此之外,很多研究者采用整体性能优于传统机器学习的深度神经网络来进行命名实体识别,缓解了构建特征过程中的人为因素。神经网络模型通过大规模无标注文本数据自主学习特征,可以抽取高阶抽象的特征支撑命名实体识别。Liu等[10]提出一种多任务处理的增强序列标注模型。在CoNLL03 NER、CoNLL00 chunking、WSJ多个数据集上实验,实现字符级别的语言模型(Language Model,LM)。通过与预训练的字向量结合,并使用Bi-LSTM和CRF网络进行序列标注任务,该模型取得了较好的效果。Peters等[11]提出一种带有双向语言模型的半监督序列标注模型。在字级别的Bi-RNN网络中加入预训练的词级别的Bi-LM,二者直接拼接成新的词向量。然后经过Bi-RNN和CRF网络进行识别,该模型也取得了不错的效果。Dong等[12]提出一种基于部件和字向量的LSTM-CRF模型。通过将汉字拆分成部件,然后使用Bi-LSTM得到部件级别的字向量。最后经过LSTM和CRF网络进行识别。通过调整网络参数,得到性能较高的中文命名实体识别结果。Chiu等[13]选用CNN抽取字符特征,然后与词向量结合作为LSTM-CRF的输入进行英文命名实体识别,取得了很好的模型识别效果。
虽然通用领域和英文网络安全领域的命名实体识别方法已取得了较好的识别性能,但中文网络安全文本相较于普通的自由文本和英文网络安全文本有较强的特殊性、专业性和差异性,中文网络安全命名实体识别仍然有待研究。
因此,针对网络安全实体中英文混合、部分实体为缩略词的问题,考虑到基于字级别的命名实体识别方法中的字向量无法表征网络安全实体的复杂语义特征。中文汉字部件具有“表音”和“表意”双层含义,英文字母具有“语素”和“词缀”双层语义,部件向量具有中英文词语隐含的语义信息。因此,中文部件和英文字母在一定程度能够增强网络安全实体的语义信息。本文提出一种基于部件CNN的网络安全命名实体识别方法,利用部件CNN抽取词语部件特征中的关键语义特征,丰富字词级别的语义信息,并引入LSTM-CRF确保抽取字向量和部件特征中的抽象信息,同时获取标签之间的关联信息,以便于更加精准地识别文本中的网络安全命名实体。
2 基于部件CNN的网络安全相关命名实体识别方法
本文提出一种基于部件CNN的网络安全命名实体识别方法(Network Security Named Entity Recognition Method on Component-Based CNN,CCNS-NER),该模型架构为 C-CNN-BiLSTM-CRF。在每个句子中,每一个字的标注为 y=(y1,…,yn)。模型的字符输入表示为 x=(x1,x2,…,xn)。其中 xi代表第i个字。其对应的部件的输入表示为c=(c1,1,c1,2,…,c2,1,ci,j,…,cn,l)。其中 ci,j表示第i个字xi的第j个部件。符号说明如表1所示。
在C-CNN-BiLSTM-CRF模型架构中,本文首先通过大量未标注网络安全数据集,使用word2vec的CBOW模型训练基于字级别的字向量表示。然后,根据中文汉字和英文词语的部件有“表音”、“表意”的特点,选用CNN模型抽取部件语义特征,实现部件的语义自动抽取。

图1 C-CNN-BiLSTM-CRF网络架构图

表1 符号说明表
该特征表示为部件向量。最后,通过预训练的字向量与部件向量拼接,形成联合字级别的特征向量,作为LSTM-CRF网络模型的输入。该层的输出为当前序列的识别结果。接下来,本文按照自底向上的顺序详细介绍C-CNN-BiLSTM-CRF神经网络架构。
2.1 字符级层
本文使用大量未标注的网络安全文本数据进行训练网络安全领域字向量,并应用预训练的字向量到网络安全命名实体识别任务。针对网络安全网页文本干扰信息较多的问题,去除文本中不需要的标记,去除噪音,提取正文文本。经处理,本文获得了11726条未标记的数据作为预训练的语料库。字符向量的预训练采用gensim[14]中word2vec的python版本实现。为了更快地获得字符向量,本文采用速度相较于Skip gram更快的CBOW模型进行预训练,并设置字向量的维度为100。预训练的字向量记为xi,字向量表示为x={xi|xi∈ℝm,i=1,2,…,n},m为字向量的维度。
2.2 C-CNN层
CC-NS-NER方法的框架C-CNN-BiLSTM-CRF中的C-CNN层用来抽取部件特征。卷积神经网络中的卷积层能够自动学习数据在各个层次的特征,池化层可以选择其中的显著特征。
网络安全文本中的网络安全命名实体存在中英文混合、单词缩写等问题,仅基于字的命名实体识别方法难以充分表征字或词的语义信息。因此,本文考虑中英文更细粒度的部件语义捕捉字或词的语义特征。中文汉字与英文有较大差异,英文最小单元为字符,而中文汉字的最小单元是部件。英文词语及字母历经语义演变,词语与字母、词语内字母与字母之间具有特定的语义特征信息。汉字是一种象形文字,其形旁和声旁部首是根据外物的特征和含义演化而来的。其中,形旁可以获得汉字的内部语义信息。因此,本文提出利用CNN抽取部件特征。其中由卷积层和池化层自动提取出部件中的语义信息。
部件级CNN层的网络结构如图2所示,主要组成部分为部件向量层、卷积层和池化层。
部件向量层将一个汉字拆分为一个或多个部件,将一个英文单词拆分为一个或多个字母,并根据随机初始化的部件向量表查找对应的部件向量,部件向量并随着模型训练而不断更新。针对汉字和英文词语部件长度不等的情况,采取补充占位符的方法。由汉字部件字典和英文词汇表可知部件长度,设定部件最大长度max_comp_len为20,并以此为准在部件右端填充占位符或截断。
卷积层使用不同数量的过滤器和不同大小的卷积窗口进行卷积运算,每个卷积窗口有一个权重W矩阵称为卷积核。卷积层使用的卷积核的大小为T=[kernel_size,input_dim],其中 kernel_size为卷积窗口大小,input_dim为部件向量随机初始化维度50。卷积核的权重矩阵值,初始值采用随机生成,通过训练进行变化。卷积层通过卷积操作,提取多个部件之间的局部特征,并采用ReLU为激活函数优化神经元的稀疏性。卷积层的部件局部特征可表示为
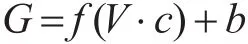
其中:V为权值矩阵,c是部件向量矩阵,初始值采用随机生成,后经卷积核计算得到训练的部件向量矩阵,b为偏置,f为ReLU非线性激活函数。卷积层每一个输出神经元通过卷积核计算得来,表示相邻多个部件的语义特征,形成部件特征映射矩阵。整层神经元通过卷积核可以提取到单个汉字部件序列多个相邻部件的特征,生成传递给下一层的特征映射矩阵G。
池化层通过Max Pooling操作抽取出卷积层多个相邻部件特征中最具有明显特征的部分表征一个汉字或英文词语的多个部件的特征信息c,后文称之为联合部件特征。池化后的联合部件特征矩阵行的维度和字符级别输入矩阵X相同,每一行对应一个联合部件特征向量,表示多个部件之间的特征信息。
这样,部件特征经过卷积核池化操作,得到一个包含部件位置信息和语义关系的联合部件特征向量c。

图2 部件级CNN层网络结构图
2.3 Bi-LSTM字符级联合层
在本文的模型架构中,采用Bi-LSTM网络获取单个字在字符级别上前向后向两个方向上的信息。正如图1所示,每个字的字向量xi和部件特征ci连接,组合Bi-LSTM网络的输入为vi=[xi⊕ci]。选用字符级LSTM[15]网络来处理字符级输入训练汉字特征,以获得当前汉字在整个语句中的隐含语义信息,预测下个位置处的汉字。双向字符特征向量序列为列向量拼接后的ht∈ℝ2*l;最后对隐藏层特征向量序列采用tanh激活函数做激活处理,从而得到隐藏层的输出结果:zt=tanh(Whht+bz)。其中隐藏层字符特征向量ht对应的权重为 Wh∈ℝl×2l,ht的偏置向量为bz∈ℝl,zt为双向LSTM的序列预测输出结果,l表示隐藏层维度。
2.4 CRF序列标注层
为了获取真实情况下标签序列的最大合理性即最大概率序列预测结果,提高网络安全命名实体识别结果的准确性,相关研究中采用CRF模型解码序列标签,获取标签之间的关联信息,确保获取最大概率的全局最优标注序列。
具体地,设输入序列表示为 X=(w1,w2,…,wn),其中 wi=(xi,ci)表示第i个字的输入向量,输出序列表示为 y^=(y^1,y^2,…,y^n)。单个字的训练实例可以表示为 (xi,ri,yi),经过字级别的LSTM后得到的输出结果表示为 zi=(zi,1,zi,2,…,zi,m) ,m 表示类别数。CRF模型可以根据wi或z学习出所有可能的输出序列标签。给定一个序列X,标签序列y^的可能性如下式:

在训练中,本文采用预测值和真实值的最小化负对数似然作为优化目标:

在解码和测试中,本文通过最大化似然获得概率最大的序列:

3 实验及结果分析
3.1 数据集
本文实验语料来源于网络安全技术网站Free-Buf网页结果,根据要提取的网络安全信息的需要进行类别标签设计,主要包括组织机构名、软件及应用程序名、操作系统名、域名、统一资源定位符、漏洞名称、漏洞编号、相关专业术语等。本文采用BIO格式,添加类别标签后缀。网络安全语料实体类别及数量统计信息如表3所示。
3.2 实验设置
1)子字符组件
为了拆分汉字部件以训练得到汉字部件级的特征向量,本文从汉程网HTTPCN中检索中文字符的部件和字根信息。共获得了20,879个字符,13,253个部件和218个字根。其中7,744个字符具有多个部件,214个字符与它们自身的字根相等。英文词语部件为字母,随机初始化字母向量构成英文部件向量表,共26个英文部件向量。

表3 网络安全语料实体类别及数量统计表
2)参数设置
在初始化时,设置字向量维度为100维,设置部件向量的维度为50维,并随机初始化其它参数。语句参数初始化时,语句长度为100。设置汉字中的部件长度为20,并采用pad_sequences的方法对语句和部件序列预处理,低于阈值的语句和部件补足长度,高于阈值的语句和部件作截断处理。
本文应用Adam作为模型的优化器,并设置学习率为0.001,batch size为64,epochs为100。为了防止过拟合,设置丢失率为0.5。
3.3 卷积核参数调整实验
经过调整模型中神经网络的维度,设置部件向量初始化维度为50。经过调整模型中神经网络的卷积核大小,设置部件CNN的卷积核数量为50,150,调整窗口大小为 3、4、5、7。字符级联合层LSTM隐藏层维度与其输入维度相同,模型网络参数如表4所示。本文以P、R、F1值为评价指标,对比结果如表5所示。

表4 模型网络参数表
通过实验结果表5可以看出,部件CNN的卷积核数量固定为50、150时,模型F1值随着窗口的增大,呈现增高趋势,在窗口大小为7时模型性能最优增高至最高。由表5可知,本文模型在网络安全数据集上,模型卷积核数量为150,窗口大小为7时性能最优,性能指标中准确率达到了72.00%,召回率达到了67.41%,F1值达到了69.63%。经过分析,我们发现产生这样结果的原因是网络安全实体中的有效实体的英文部件长度均保持在7左右的字节长度,且中文汉字的最大部件长度为9,而大多汉字的部件不足9个。因此,结合中英文的部件长度,模型在窗口为7时性能最优。

表5 卷积核参数对CCBC模型的F1的影响结果表
3.4 方法性能对比实验
为了验证模型的性能,本章节在网络安全数据集上,将本文的基于部件CNN的网络安全命名实体识别方法CC-NS-NER与现有的一些方法进行对比。本节中提到的所有实验数据均以自动标注的结果为基准,以提供对模型性能真实客观的评价依据。实验结果如表6、图3所示。

表6 CC-NS-NER模型与其他模型的指标对比表

图3 CC-NS-NER模型与其他模型8类的F1值对比图
通过表6、图3的实验结果可以看出,在网络安全数据集上,本文的CC-NS-NER算法相较于当前主流的深度学习方法在整体P、R、F1值上均有所提高。模型最优性能达到了69.63%,相比BiL-STM-CRF模型F1值提高了7.37%,相比GRU-BiLSTM-CRF模型F1值提高了2.54%。且各类别相较于其他两个对比模型,较难识别的组织结构ORG和软件名称SOF均有提升,并且漏洞名称VN和相关术语RT达到性能最优为63.45%和72.84%。由于网络安全文本中,网络安全相关专业术语实体是文本中出现较多的实体,其次是软件名称实体。网络安全相关术语实体识别的效果较高,而软件名称安全实体的识别效果则较低,分析其构成可知,软件名称安全实体中常包括软件应用和软件应用组件程序等实体,构成较为复杂,并且大多软件名称与其开发团队的组织结构名称表述一致,软件名称更新速度较快。因此,难以抽取实体间共有特征以识别软件名称安全实体。而文本中出现数量较少的实体则是域名DN、统一资源定位符URL实体和漏洞编号VI实体,虽然同样训练样本少,但其命名具有一定的规律性可言,因此,可以较为准确地识别,识别率最高。
4 结语
本文提出了一种基于部件CNN的网络安全命名实体识别方法。在该方法中,利用中文汉字部件具有“表音”和“表义”的双层含义,英文字母具有“语素”和“词缀”的双层含义(中文汉字部件与英文字母统称为部件)。在部件CNN的作用下抽取中英文部件的隐含语义信息,增强了网络安全实体的语义特征。相较于传统命名实体识别方法,对域名、统一资源定位符和漏洞编号三类规则性网络安全实体具有较好的实体识别效果。然而,网络安全命名实体识别任务中,存在部分实体具有修饰词语、由两个或多个实体组合的网络安全命名实体问题,更精准识别网络安全文本中的网络安全命名实体,是下一步的研究方向。
