基于云模型的配电网抢修质量和效率评价方法
2020-03-03吴郅君王晓峰陈中孟军施萱轩
吴郅君,王晓峰,陈中,孟军,施萱轩
(1.东南大学 电气工程学院,江苏 南京210096;2. 国网南京供电公司,江苏 南京 210019)
近年来,配电网结构日趋复杂,网络规模迅速扩大,使得配电网故障发生的概率大大提高。为保证电力用户正常的生产、生活用电,满足用户对供电质量和电力服务的高要求,高效率、高质量地完成配电网故障抢修工作尤为重要。抢修队作为配电网故障抢修的主要力量,是实现故障高效恢复的关键,客观全面地评价抢修队的故障抢修能力,可以为管理抢修队、调整抢修调配方案提供参考依据,对提高配电网故障抢修水平具有重要意义。
目前,针对配电网故障抢修开展的研究主要集中于故障定位[1-3]、故障恢复[4-5]、抢修驻点优化[6-7]、抢修路径优化[8-9]等方面,且在研究过程中大多将每个抢修队的抢修水平设置为同等理想状态,造成结果与实际情况有所不符。文献[10]建立了一种基于二维空间地理位置坐标的配电网故障抢修驻点选址与抢修任务分配模型,但是在进行任务分配研究时,并未考虑到抢修队自身的抢修水平差异,使得结果缺乏实际效果。文献[11]建立了配电网突发多处故障情况下的多目标优化模型,将开关操作变量作为虚拟故障点处理,建立了一种多队协同的抢修优化模型;但该文献将抢修队人力和资源设置为理想状态,与实际抢修过程中各抢修队的实际情况可能不符。目前对于配电网故障抢修水平方面的研究极少,文献[12]构造了配电网故障抢修质量与效率评价体系,采用层次分析法和熵权法进行评价;该文献虽然实现了对配电网故障抢修质量与效率的评价,但是没有考虑到评价系统的随机性和模糊性,且在评价过程中没有考虑到专家的差异,使得结果缺乏一定的客观性。
本文针对配电网实际抢修调配中需要考虑的抢修队水平差异,建立抢修队故障抢修质量和效率评价体系,采用被广泛应用于决策分析与数据挖掘领域的云模型[13-14],充分利用其能将随机性和模糊性有机结合起来的特性,提出一种基于云模型与专家置信度的综合评价方法。该方法考虑了专家自身的认知差异,以及在评价过程中所受到的内外在因素影响,对指标评分和权重进行修正,从而得到更加真实可靠的评价结果;以南京市某区域抢修队为例,将得到的最终评价结果生成云图,通过与云标尺对比,形象直观地反映出抢修队抢修质量和效率的评价情况;最后与常用的评价方法进行比较,验证所提方法的可行性与优越性,为抢修队的管理以及配电网故障抢修实际调配提供参考。
1 抢修队故障抢修质量和效率评价体系
为了客观全面地反映抢修队对配电网故障实施抢修的质量和效率,并考虑数据收集的难易程度,在遵循指标选取科学性、完备性、简明性、客观性以及系统性原则[15]的基础上,从故障抢修实施的抢修质量层面和抢修效率层面出发,分别选取用户满意度、重复报修工单比例、用户等候时长、抢修工作准备情况、故障处理时长作为抢修队故障抢修质量和效率的评估指标,指标体系如图1所示。
设用户等候时长、用户满意度、抢修工作准备情况、重复报修工单比例、故障处理时长的评价得分分别为x1、x2、x3、x4、x5,具体评分方法如下:
a)用户等候时长。采集处理时间与实际到达现场时间,二者相减得到用户等候时长原始数据;再根据实际情况和专家经验设置“非常及时、及时、较及时、一般、误时”5个评价等级,分别赋分“5分、4分、3分、2分、1分”。

图1 抢修队故障抢修质量和效率评价体系Fig.1 Quality and efficiency evaluation system of emergency repair team
b)用户满意度。根据用户满意度的实际情况和专家经验设置“非常满意、满意、较满意、一般、不满意”5个评价等级,分别赋分“5分、4分、3分、2分、1分”。
c)抢修工作准备情况。根据抢修工作准备实际情况和专家经验设置“非常充分、充分、较充分、一般、不充分”5个评价等级,分别赋分“5分、4分、3分、2分、1分”。
d)重复报修工单比例。采集1个月内相同地点相同故障重复报修超过3次的工单数量,除以1个月内工单总量,得到重复报修工单比例原始数据;再根据实际情况和专家经验设置“不高、一般、较高、高、非常高”5个评价等级,分别赋分“5分、4分、3分、2分、1分”。
e)故障处理时长。采集实际到达现场时间与抢修实际完成时间,二者相减得到故障处理时长原始数据;考虑到相关设备的使用年限和类型的实际情况,设置修正系数σ,σ的值由专家确定,用修正系数乘以故障处理时长原始数据,得到故障处理时长最终的原始数据;再根据实际情况和专家经验设置“不长、一般、较长、长、非常长”5个评价等级,分别赋分“5分、4分、3分、2分、1分”。
2 抢修队故障抢修质量和效率评价方法
本文从解决信息随机性和模糊性出发,综合考虑专家的权威性与个体差异,提出一种基于云模型与专家置信度的评价方法。设专家组一共有m位专家。
2.1 云模型
2.1.1 云模型定义
云模型是由李德毅院士提出的一种定性、定量相互转换的模型,在传统概率论和模糊数学的基础上,通过数字特征将随机性和模糊性有机结合起来,实现定性概念和定量数值之间的自然转换[16-17]。
设U为1个定量论域,C为论域U上的定性概念,任意元素x∈U是定性概念C上的1次随机实现;x对C所表示的定性概念的隶属度μc(x)∈[0,1]是具有稳定倾向的随机数,隶属度在论域U上的分布称为隶属云,简称为云;每一个元素x代表1个云滴,即
μc(x):U→[0,1],∀x∈U,x→μc(x) .
(1)
2.1.2 云模型数字特征
云模型的数字特征可以用期望值Ex、熵En、超熵He来表征,即(Ex,En,He)。图2所示为云模型数字特征示意图。其中,Ex是论域空间的中心值,最能代表定性概念;En反映了定性概念的不确定性和随机性,熵越大,表示这个定性概念越模糊;He是熵的熵,反映云滴的离散程度,超熵越大,云越厚,云滴的离散程度越大。
2.1.3 云发生器
云发生器按照功能可分为正向云发生器和逆向云发生器。
a)正向云发生器。正向云发生器(如图3所示)是在已知云数字特征的条件下生成云滴,可以将定性概念转化为定量数值。图3中CG表示正向云发生器,Drop(x,y)表示云滴。

图3 正向云发生器Fig.3 Forward cloud generator
b)逆向云发生器。逆向云发生器(如图4所示)是将已知的云滴作为样本,求出云数字特征,可以将定量数值转化为定性概念。图4中,CG-1表示逆向云发生器。

图4 逆向云发生器Fig.4 Backward cloud generator
c)云数字特征计算。利用逆向云发生器计算数字特征的算法[18]为:输入为n个云滴xi(1≤i≤n),输出为云滴对应的3个特征数值(Ex,En,He),具体运算步骤如下。
步骤1,根据云滴xi计算样本均值

(2)
步骤2,计算样本方差
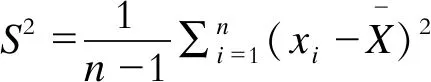
(3)
步骤3,计算云滴的期望值Ex、熵En和超熵He如下:
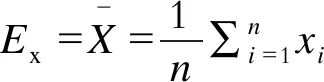
(4)

(5)

(6)
2.2 基于权威性和协调性的专家置信度确定方法
由于专家在进行指标评价时的可靠度不同,为了使得最终的评价结果更加真实可靠,在对评价结果进行处理时,需要考虑专家评价的置信度。本文从专家权威性和评价协调性出发,提出基于权威性和协调性的专家置信度确定方法。
2.2.1 专家权威性
为保证评价结果的可靠性,往往需要考虑专家对评价对象的权威程度。本文从专家的专业水平、对评价对象的熟悉程度[19]这2个方面出发分析专家权威性。
2.2.1.1 专业水平系数
一般情况下,对同一个评价对象,一个专家的专业水平越高,做出的判断就越有参考价值。本文从工作领域、实践经验、抢修参与度等方面对专家的专业水平进行评价,并以百分制的形式给出定量描述,具体描述见表1。

表1 专家专业水平评价标准Tab.1 Evaluation criteria for expert professional level
设m位专家中第j位专家的工作领域评分为aj,实践经验评分为bj,抢修参与度评分为cj,则专家j的专业水平评价值
Zj=ajbjcj,j=1,2,…,m.
(7)
专家j的专业水平系数
λj=Zj/maxZj,j=1,2,…,m.
(8)
2.2.1.2 熟悉程度系数
对评价对象的熟悉程度关系到专家做出判断的正确性与可靠性,本文从对评价指标的熟悉度、评价自信度等方面请专家进行自我判断,并以百分制的形式给出定量描述,具体描述见表2。

表2 专家熟悉程度判断标准Tab.2 Judgment criteria for expert familiarity
设第j位专家对指标熟悉度的自我评分为uj,对评价自信度的自我评分为vj,则专家j的熟悉程度评价值
Fj=ujvj,j=1,2,…,m.
(9)
专家j的熟悉程度系数
γj=Fj/maxFj,j=1,2,…,m.
(10)
2.2.1.3 专家权威性系数
基于专业水平和熟悉程度,计算专家权威性系数qj,计算公式如式(11)所示:
qj=(λj+γj)/2,j=1,2,…,m.
(11)
2.2.2 评价协调性
不同专家对同一指标的评价各不相同,设置评价协调性系数来反映某位专家对各项指标的评价结果在所有专家中的认可程度,从侧面反映出该专家的可靠度。
设第j位专家对第z个指标的评价值为xjz,第k位专家对第z个指标的评价值为xkz,故障抢修评价指标个数为N,则专家j与所有专家评价差值的总和
(12)
专家j的评价协调性系数

(13)
2.2.3 专家置信度
综合专家权威性和评价协调性,计算专家置信度Dj,计算公式如式(14)所示:
Dj=qjpj,j=1,2,…,m.
(14)
2.3 基于云模型与专家置信度的评价方法
2.3.1 评语集和云标尺建立
本文采用黄金分割法生成评语概念,建立云标尺,其核心思想[20]是:将给定的论域看作语言变量,并用云模型来表达每个语言变量,云的熵和超熵与论域中心的远近有关,离论域中心越近,熵和超熵越小;其中,相邻云的熵和超熵以0.618倍依次减小,通常取3个或5个奇数个数的云。
为反映抢修队的故障抢修质量和效率,将抢修队的总体评价分为5个等级,分别为“高”“较高”“一般”“较低”和“低”,构建5层正态云[20]为评价标准,生成云标尺见表3,获得的云标尺图如图5所示。

表3 云模型标尺Tab.3 Cloud model scales

图5 云标尺Fig.5 Cloud scales
2.3.2 云权重确定
2.3.2.1 云权重云滴计算

2.3.2.2 基于专家置信度的云权重计算
由于专家权威性与认知性存在个体差异,为使得权重分配更加可靠,为每个权重云滴乘上相应专家的专家置信度,最终得到第z项指标的m个权重云滴

(15)
采用第2.1.3节介绍的逆向云发生器计算得到各项指标权重的云特征值,即云权重[23-24],将权重矩阵记为β,则

(16)
式中:βN为第N个指标的云权重;ExN、EnN、HeN分别为第N个指标云权重的期望值、熵值和超熵值。
2.3.3 云评价值确定
2.3.3.1 云评价值云滴计算
按照图1的评价体系,收集待评价抢修队的各项指标数据信息,并根据上文所述指标评分方法,邀请专家组进行评价赋分,得到各项指标的原始评价分值为:{x11,x12,…,x1N},{x21,x22,…,x2N},{xk1,xk2,…,xkN},…,{xm1,xm2,…,xmN},其中{xk1,xk2,…,xkN}表示第k位专家对N项指标的评价分值,由此组成各项指标的m个评价值云滴。
2.3.3.2 基于专家置信度的云评价值计算
由于专家权威性与认知性存在个体差异,为使得指标评价分值更加客观可靠,为每个评价值云滴乘上相应专家的专家置信度,最终得到第z项指标的m个评价值云滴为
{D1x1z,D2x2z,…,Dmxmz},z=1,2,…,N.
(17)
利用第2.1.3节介绍的逆向云发生器计算得到各项指标评价分值的云特征值,即云评价值,将评价值矩阵记为y,则

(18)
式中:yN为第N个指标的云评价值;ExyN、EnyN、HeyN分别为第N个指标云评价值的期望值、熵值和超熵值。
2.3.4 基于云模型的综合评价
综合评价云特征值的具体计算公式[23]如式(19)、式(20)所示:
Y=(Ex,En,He).
(19)
(20)
将综合评价云特征值利用MATLAB生成云图,与第2.3.1节建立的云标尺进行对比,可得到所评价抢修队的故障抢修质量和效率评价结果。
3 实例分析
以抢修队的故障抢修质量和效率评价为背景,以江苏南京市某区域抢修队为例,对本文所提评价方法进行实例分析,证明其可行性和实用性。邀请5位从事相关工作的专家成立专家组进行评分,结合专家经验,将故障处理时长修正系数σ取值为0.91。
3.1 专家置信度计算
邀请专家组对自身专业水平、评价对象熟悉程度进行打分,并收集指标相关数据信息,请专家对各项指标进行评分,结果见表4、表5、表6。

表4 专家专业水平评价Tab.4 Evaluation of expert professional level

表5 专家熟悉程度判断Tab.5 Expert familiarity judgment
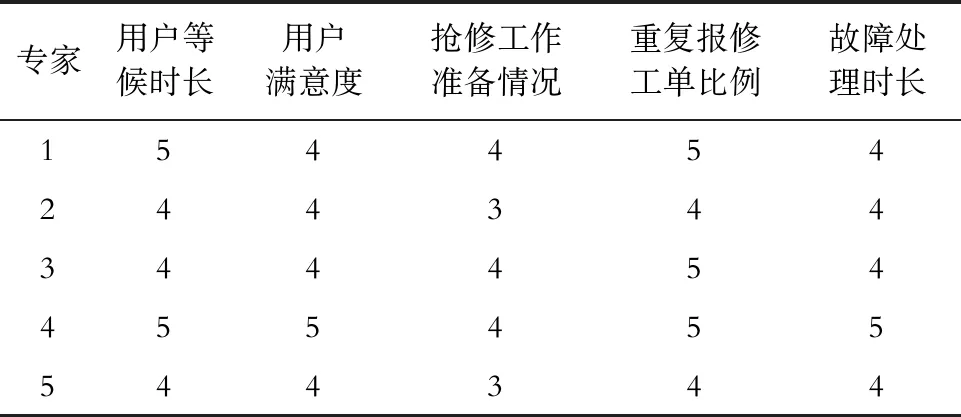
表6 指标原始评价分值Tab.6 Original evaluation scores of indicators
结合表4、表5、表6,利用式(7)—式(14)可以求得专家权威性系数、评价协调性系数和专家置信度,结果见表7。

表7 专家置信度及相关系数Tab.7 Expert confidence levels and correlation coefficients
3.2 计算指标云权重
3.2.1 采用层次分析法计算指标原始权重。
邀请专家组根据图1的评价体系,对指标的相对重要性进行两两判断,以专家1的判断为例,构造判断矩阵A1如下:

(21)

表8 指标原始权重Tab.8 Indicator original weights
3.2.2 计算基于专家置信度的云权重
利用式(15)和表7、表8,计算基于专家置信度的权重云滴,计算结果见表9。

表9 基于专家置信度的权重云滴Tab.9 Weighted cloud droplets based on expert confidence level
利用第2.1.3节介绍的逆向云发生器计算得到各项指标权重的云特征值,即云权重,见表10。

表10 评价指标云权重Tab.10 Cloud weights of evaluation indicator
得到权重矩阵

(22)
3.3 计算指标云评价值
3.3.1 计算原始评价分值
将表6中的指标评分统一到[0,1]区间内,结果见表11。
3.3.2 计算基于专家置信度的云评价值
利用式(17)和表7、表11,计算基于专家置信度的评价值云滴,计算结果见表12。

表11 原始指标评分[0,1]转化结果Tab.11 Transformation results of original indicator scores in [0,1]
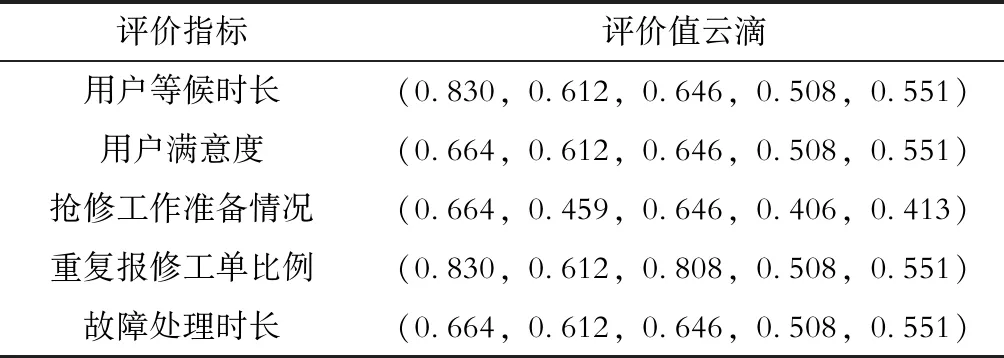
表12 基于专家置信度的评价值云滴Tab.12 Cloud droplets based on expert confidence level
利用第2.1.3节介绍的逆向云发生器计算得到各项指标评价分值的云特征值,即云评价值,结果见表13。

表13 评价指标云评价值Tab.13 Cloud evaluation values of evaluation indicator
得到评价值矩阵

(23)
3.4 综合评价云的计算与分析
利用式(19)和式(20),结合式(22)、式(23)计算综合评价云特征值,得
Y=(Ex,En,He)=(0.664,0.111,0.003).
(24)
将综合评价云特征值利用MATLAB生成云图,与第2.3.1节建立的云标尺进行对比,结果如图6所示,图中灰线表示云标尺,黑线表示抢修队最终评价云。

图6 抢修队最终评价云与云标尺对比Fig.6 Comparison of final evaluation cloud of the emergency repair team and cloud scales
由图6可以看出,评价结果处于“一般”与“较高”之间,距离“较高”较近,偏“较高”。由此可以判定抢修队故障抢修质量和效率的最终评价结果均为“较高”。
为了进一步说明本文所提基于云模型与专家置信度的评价方法的有效性,采用目前较常用的模糊层次分析法[25]对上述算例进行评价。利用模糊层次分析法计算指标权重,结合各项指标的原始评价分值,分别计算出5位专家的个人评价结果,再利用加权平均算子对各评价结果进行综合,得到最终评价结果见表14。

表14 基于模糊层次分析法的指标评价结果Tab.14 Indicator evaluation results based on fuzzy analytic hierarchy process
由表14可知,应用模糊层次分析法得到的最终评价结果为0.703,与本文所提基于云模型与专家置信度的评价方法所得出的最终评价云模型(0.664,0.111,0.003)的期望值0.664相近,在一定程度上证明了本文所提评价方法的有效性。在与文献[11]的对比中也可以看出,本文所提方法得出的结果能够生成形象直观的对比图,并且充分考虑评价系统中的随机性和模糊性,具有一定优越性。
4 结束语
为反映抢修队的故障抢修质量和效率,提升配电网故障抢修管理水平,本文提出一种基于云模型与专家置信度的评价方法。利用云模型,充分考虑评价的随机性和模糊性,实现定性与定量的相互转化;同时从专家权威性和评价协调性出发,对各云滴进行专家置信度修正,从而得到更加真实可靠的评价结果。实例验证表明,所提方法在具有较好的可行性和实用性的同时,具有一定的优越性,可以形象直观地反映出抢修队故障抢修质量和效率的高低,为抢修队的可视化管理提供一种新的分析手段。
