近红外光谱法对松原不同品种大米的确证探究
2020-02-29王朝辉高地赖瀚清王艳辉沈海鸥陈雷程娇娇王靖会
王朝辉,高地,赖瀚清,王艳辉,沈海鸥,陈雷,程娇娇,王靖会,*
(1.吉林农业大学食品科学与工程学院,吉林长春130118;2.吉林省长春市净月开发区福祉街道办事处,吉林长春130122;3.吉林农业大学资源与环境学院,吉林长春130118;4.吉林省长春市交警支队南关区大队,吉林长春130000;5.吉林农业大学信息技术学院,吉林长春130118)
大米是世界上主要粮食作物之一,我国有三分之二的人口以大米为主食,大米可以提供人们每日所需能量的75%,所以大米是不可或缺的。由于大米的产地不同,其价格也有很大的跨度。吉林省松原大米,因其得天独厚的地理条件,土壤肥沃且偏弱碱性,并用江水灌溉,这种环境种植出的大米口感松软,飘香四溢,有很高的商业价值。由于品种鉴别方法的缺失及产地确证技术的不成熟问题较严重,导致每年因为品种混卖对市场产生了不良的影响及不菲的经济损失;建立产地确证体系迫在眉睫。农产品的品种鉴别、产地确证及不同的处理手段结合化学计量学方法的应用受到国内外专家的广泛关注。
国内外文献表明,产地确证主要用在食用油[1-2]、苹果[3]、药类[4-7]、谷物[8-10]、蜂蜜[11]、咖啡[12]、鱼类[13-14]等;进行产地确证的方法有矿物元素方法、近红外光谱法、电子鼻指纹图谱、DNA 指纹图谱技术等;其中近红外光谱法因其具有采集信息量大、精度高、无污染、速度快等优点,被应用于不同领域[15-17]。Osborne 等用近红外光谱技术结合判别分析对来自巴斯马蒂及非巴斯马蒂地区的116 个大米样品进行判别归类,结果显示所有样品均能正确归类[18];陈全胜等利用近红外光谱技术结合模式识别方法,对4 种不同类型茶叶建立的识别模型,模型识别率均大于80%[19];Sinelli 等通过传统感官评价方法并结合傅里叶变换近红外光谱技术对112 组初榨橄榄油进行了产地溯源研究,研究采用线性判别(linear discriminant analysis,LDA)分析及模式识别分类方法,其产地判别正确率为71.6%、100%[20];苏学素等利用近红外光谱法结合簇类软模式法及偏最小二乘判别法成功对来自江西、重庆和湖南的不同地区脐橙进行溯源,其模型对训练集和验证集样品的识别率达到100%[21]。现有文献表明近红外光谱结合多元统计分析方法在品种分类及产地确证方面是可行的。本研究利用近红外光谱方法结合多元统计分析技术对来自松原的5 个品种的大米进行判别。同时,对松原和非松原大米进行产地分类,为松原大米品种和产地提供一种便捷、高准确度的鉴别方法。
1 材料与方法
1.1 试验材料
为提高研究的科学性与可靠性,确保所采样品具有代表性,采样方法选择网格布点,网格布点的优点在于其布点方式可包含所采地区大部分采样点,使得样品来源科学、合理。所采样本全部为来自松原的稻花香、小高粱、通系 926、吉粳 515 及农大 521 共 5 个品种。取样后,根据地理位置及样品情况,确定5 个品种数量分别为 80、75、68、67 个和 78 个。
采集完成后,先将样品在实验室条件下风干、脱穗、去空粒、砻谷。挑出未成熟的发黄发绿的籽粒后进行碾米。最后用锤式旋风磨研磨至粉末状,过100 目筛,标号,待测。
1.2 试验仪器设备
所用仪器设备如表1 所示。

表1 仪器设备信息Table 1 Instrument Information
1.3 光谱数据的获取
将处理好的松原大米样品用傅里叶近红外光谱仪进行扫描。在扫描样本之前先扫描背景,每扫4 次样品扫1 次背景,扫描背景是为了降低环境因素的影响。用烧杯量取待测样品约75 mL 放入样品杯,样品装填均匀并要求底部没有裂缝;将样品杯放入样品室,开始扫描;扫描结束后,取出样品杯,清扫样品;重新装样,进行第二个样品的扫描;依次进行,直至扫描完所有样品,每个样品均扫描3 次,求平均值作为最终结果[22]。
1.4 分析方法
1)主成分分析:是采取一种数学降维的方法,所要做的就是设法将原来众多具有一定相关性的变量,重新组合为一组新的相互无关的综合变量来代替原来的变量[23]。
2)偏最小二乘判别分析(partial least squares discrimination analysis,PLS-DA):是一种基于偏最小二乘法(partial least squares,PLS)的判别方法;是一种的有监督的模式识别方法,也是目前应用较广泛的光谱分析方法,可以实现全谱或部分谱数据的分析[24]。
3)试验过程:首先利用OPUS7.5 光谱采集软件进行光谱数据的采集;用OMNIC 软件和MATLAB R2016a 软件对数据进行预处理、主成分分析及PLSDA 模型的建立;用验证集验证模型对品种判别的效果;最后用来自柳河和梅河的同年际稻花香大米近红外光谱数据带入到松原稻花香大米品种模型中,进行松原大米的产地确证。
2 PLS-DA判别模型的建立与验证
2.1 光谱数据预处理
5 个品种大米样本的原始近红外光谱图如图1 所示,由于所有大米图谱混杂在一起,难以用肉眼来分辨5 个品种,所以需要对图谱进行预处理。

图1 不同大米品种样品的近红外光谱图Fig.1 Near Infrared Spectrum of different rice varieties
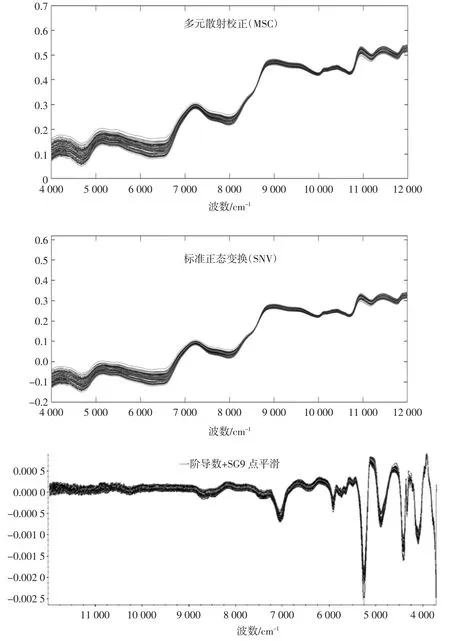
光谱样品预处理方法有多种,包括多元散射校正(multiple scatter correction,MSC)、标准正态变换(standard normal variate,SNV)、基线校正、平滑、一阶导数、二阶导数、导数结合卷积平滑等。不同的预处理方法对模型的建立所产生的影响不同[25]。MSC 法以及SNV法可以矫正样品因颗粒散射引起的光谱误差,SNV 可以有效减小粉末粒度不同因其的类内距离;一阶导数和二阶导数分别用于消除光谱中基线的平移和漂移,可有效消除其他背景的干扰,分辨重叠峰,提高分辨率和灵敏度。光谱用移动平均窗口平滑(窗口宽度=9、11、13 个数据点)的处理可以减少噪声;平滑处理可以有效平滑高频噪音,提高信噪比;窗口宽度小,噪声去除效果不好;窗口宽度大,噪声去除效果好但也可能导致信号失真,所以合理恰当的预处理方法是必要的[26]。本试验运用原始光谱、SNV、MSC、一阶导数结合SG9 点平滑、一阶导数结合SG11 点平滑、二阶导数结合SG9 点平滑、二阶导数结合SG11 点平滑几种处理方式对光谱数据进行处理,并建立模型比较模型的校正均方根误差(root mean standard error of calibration,RMSEC)值及R2(相关系数),经过分析,选择最适合建立模型的预处理方法。
2.2 试验样品的选取
将所有样本数据用Kennard-Stone(KS)法划分样本集,得到所要用到校正集样本248 组(稻花香54 组、小高粱 50 组、通系 926 共 46 组、吉粳 515 共 45 组、农大521 共53 组),验证集样本共120 组,用于接下来的建模分析,详细信息见表2。

表2 校正集与验证集Table 2 Correction set and verification set
2.3 近红外光谱预处理的选择对建模效果的影响
在PLS-DA 模型建立之前,要根据5 个水稻品种的校正集及验证集样本分类变量特征进行赋值。稻花香、小高粱、通系926、吉粳515 和农大521 大米的值分别为[10000]、[01000]、[00100]、[00010]、[00001],用校正集样本的近红外光谱与样本对应的分类变量建立回归关系PLS-DA 模型,用验证集样本对模型的准确度进行验证,用RMSEC 和R2作为验证指标,选择RMSEC 值越小、R2值越大所对应的预处理方式作为试验光谱预处理方法,建立的模型校正均方根误差及相关系数如表3 所示。
由表3 可知,经过预处理的光谱所建的模型效果比原始光谱所建立模型的准确度要高,对比发现,一阶导数结合SG9 点平滑对数据处理后所建立的PLSDA 模型对校正样本集的效果最好,R2和RMSEC 值分别为0.976 和0.145。原始光谱经过不同预处理后如图2 所示。

表3 不同预处理方式对模型准确度的影响Table 3 Influence of different preprocessing methods on model accuracy
3 结果与分析
3.1 不同品种大米的主成分分析
主成分分析后的248 个校正集样本的前3 个主成分得分如图3 所示。
由图3 可知,通过对数据中的原始变量进行线性组合后,小高粱、通系926、吉粳515,3 个品种基本可以较好的分开,还可以看出小高粱与稻花香、通系926、吉粳515、农大521 大米的距离都很远,这可能和小高粱的基因型有关,小高粱也叫松粳3 号,由辽粳5号作为母本,合江20 号为父本杂交育成,经在当地调查了解到,小高粱因其在松原种植产量较高,抗碱性比很多大米品种要好,因此在松原,很大一部分农户都选择小高粱种植;而稻花香和农大521 可能由于数据不稳定或试验误差等因素致使个别点交叉重叠。难以很好的区分。
3.2 模型的建立与验证
5 个品种校正集样本(稻花香、小高粱、通系926、吉粳515、农大521)分类变量的PLS 预测值与真实值的回归图见图4。
由图4 可以看出,此模型能够将单个品种与其他4 个品种进行区分,分散在参考值Yr=1 的大米样本点和参考值Yr=0 线上的其他4 个品种的大米样本能明显区分开。这也说明模型建立良好,有较高的可靠性。

图3 近红外光谱主成分123 得分图Fig.3 Near-infrared spectroscopy main component 1,2,3 score map
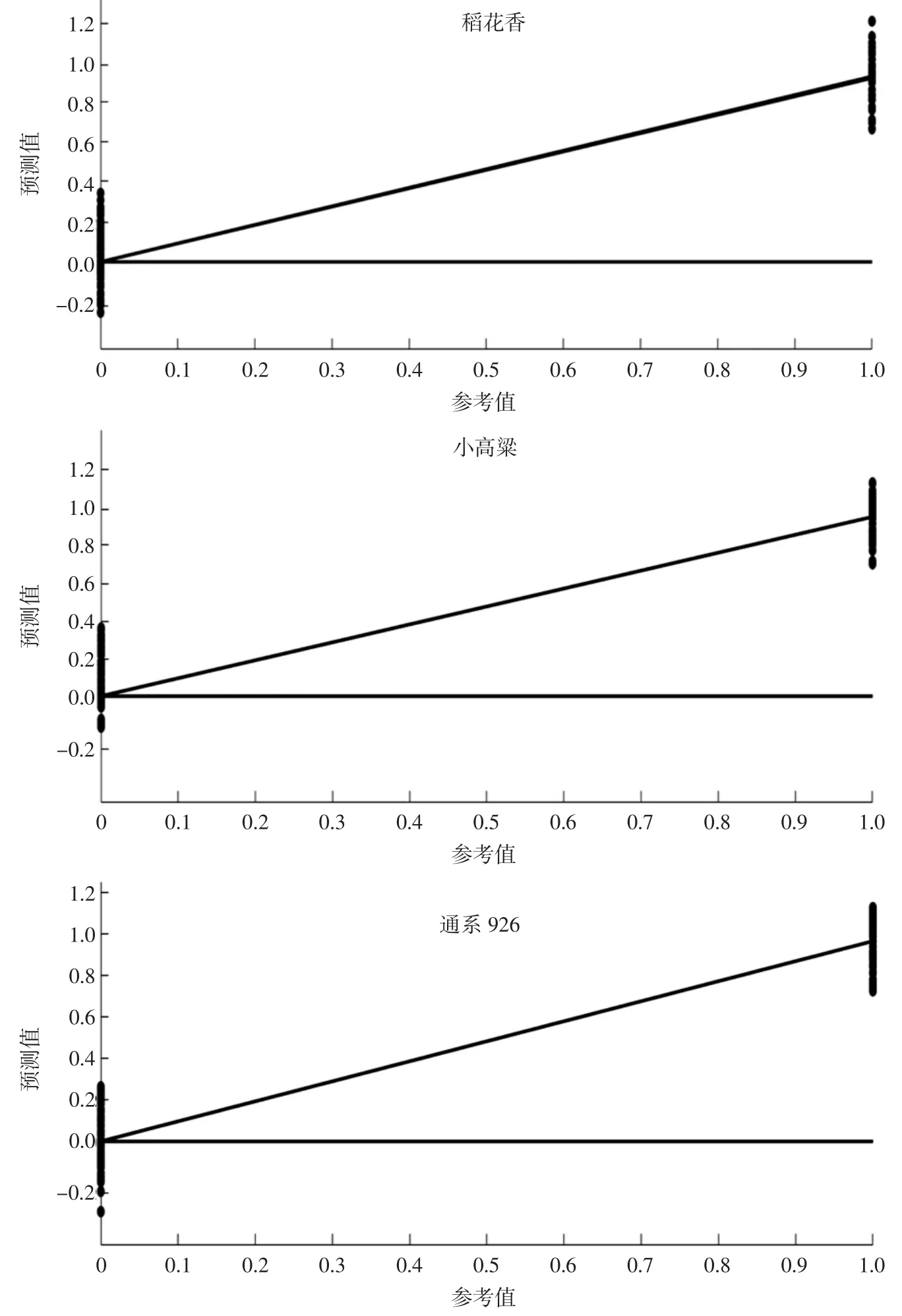
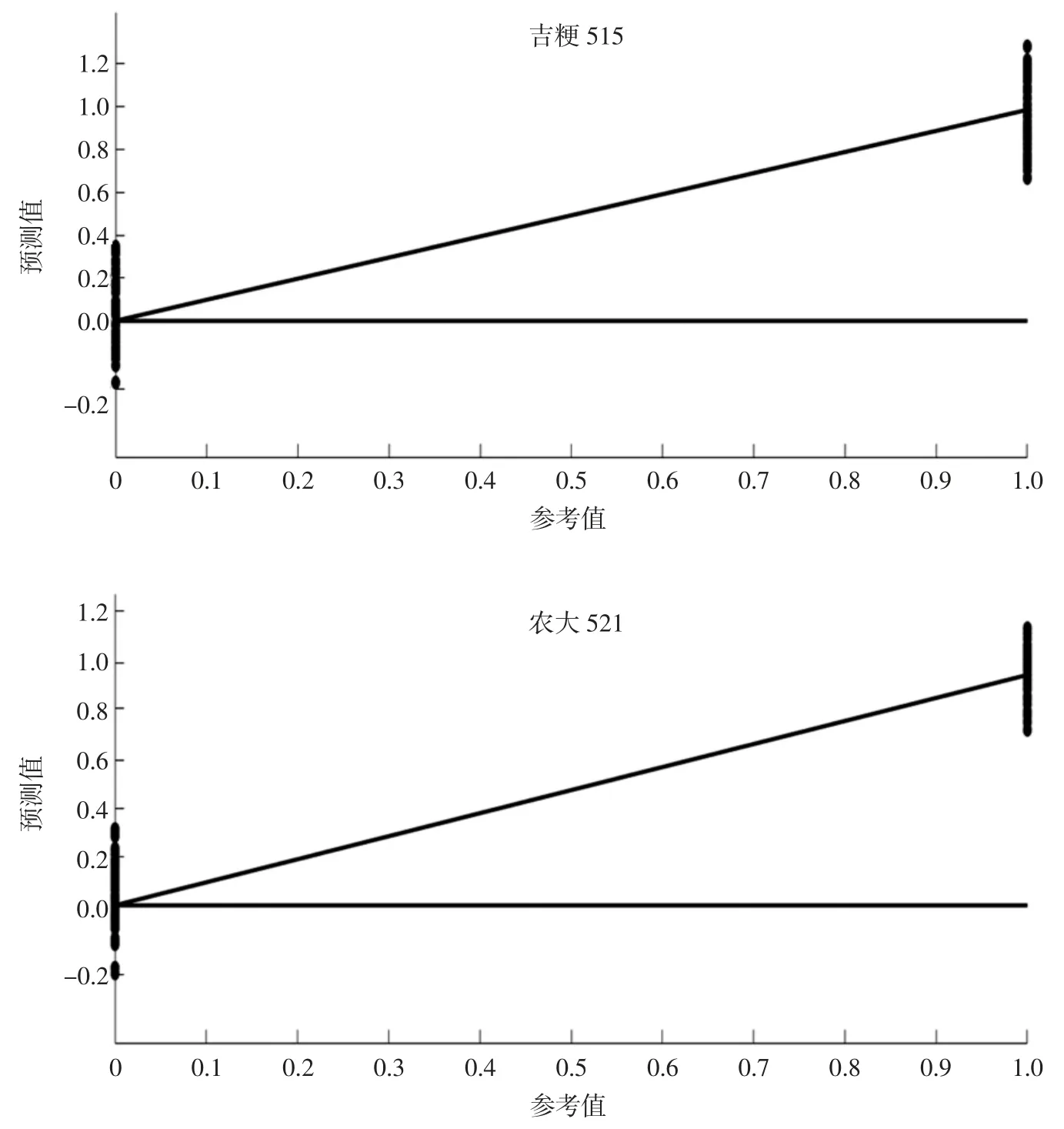
图4 PLS-DA 校正模型样本分类变量的PLS 预测值与真实值回归图Fig.4 PLS predictive value and real value regression graph of PLS-DA correction model sample categorical variables
模型建立好后,用验证集对模型进行验证,如图5 所示。
图5 是模型对5 个大米样本共120 个(稻花香26个、小高粱 25 个、通系 926 为 22 个、吉粳 515 为 22个、农大521 为25 个)进行判别分析的结果,如图5(1)中可以看出,稻花香样本的验证集分类变量的预测值都接近于1,而其他四类大米样本的分类变量预测值都在0 左右,验证集中属于稻花香的样本均被正确判别为稻花香,说明PLS-DA 判别模型对稻花香样本的判别准确率为100%,其他4 种大米不具备稻花香样本的特征;同理对其他4 种大米,每个品种的大米样本特征明显,由此可以看出,PLS-DA 判别模型对不同品种样本的判别准确率为100%。此模型效果要优于主成分分析结果。
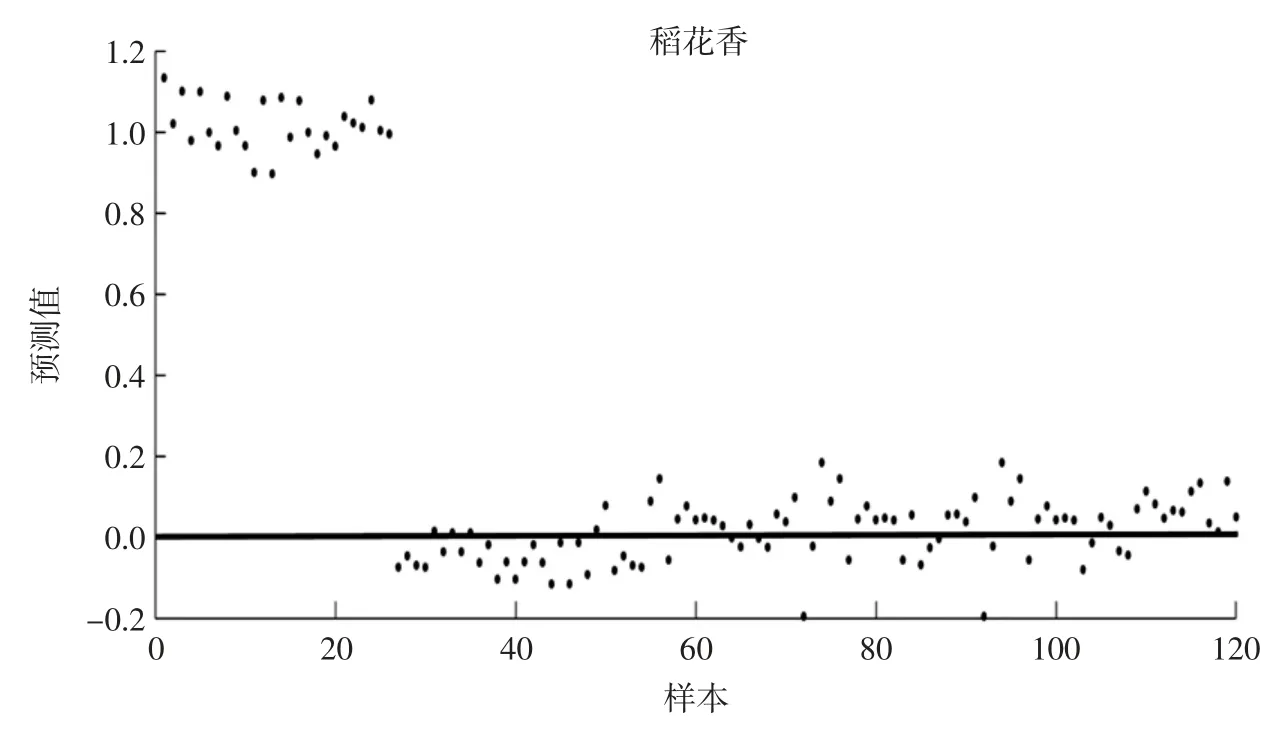
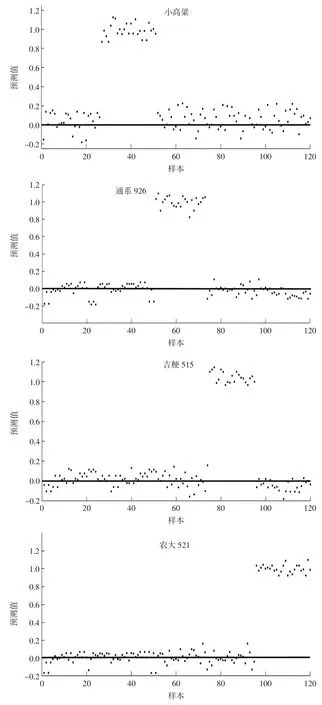
图5 验证集中大米样本的PLS-DA 模型判别结果Fig.5 Discriminant results for rice samples in validation set by PLS-DA model
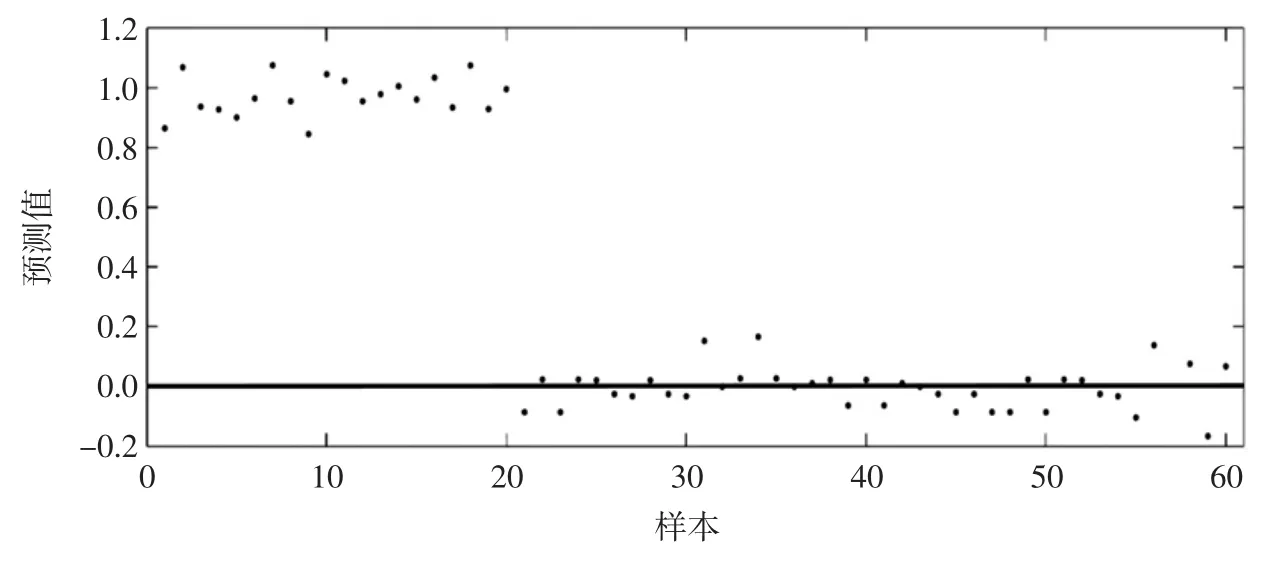
图6 不同地区稻花香大米样本的PLS-DA 模型判别结果Fig.6 Discriminant results for Dao Huaxiang rice samples from different areas by PLS-DA model
3.3 松原大米的产地确证
为了进行松原大米的产地确证,我们选取同年际所采来自柳河(20 个)和梅河(20 个)的大米进行验证,品种为稻花香,大米的保存及前处理方法完全相同,预处理方法同样选择一阶导数结合9 点卷积平滑的方式,将样品带入稻花香PLS-DA 判别模型中,判别结果见图6。
由图可知,松原的稻花香样本分类变量的预测值均在1 左右,而来自柳河和梅河的样本预测值在0 附近,判别正确率为100%。此模型可以用来进行松原稻花香的品种识别及产地确证。
4 结论
本试验共采集来自松原地区的稻花香、小高粱、通系926、吉粳515 及农大521,5 个品种共368 个样品,其中248 个样品作为校正集样本,剩余120 个样本作为验证集样本,对所有样品进行处理,呈粉末状,并进行样本近红外光谱数据的获取,确定原始光谱图的预处理方法为一阶导数+SG9 点平滑,通过PLS-DA 法建立判别模型,并用验证集对建立的模型进行验证,5个品种大米样本分类变量模型的识别率为100%。模型效果优于主成分分析结果。最后用来自柳河和梅河的稻花香大米样本带入模型中来进行产地确证,模型判别效果良好,初步认定采用近红外光谱分析结合PLS-DA 法可以用于松原不同品种大米的判别及松原大米的产地确证。
从以上研究结果来看,近红外光谱技术结合化学计量学分析可以用于松原大米品种的判别及产地确证,但是近红外光谱技术主要反映样品内部有机成分组成、含量、基团等,样品在采样回来后,贮藏、加工过程也可能会使得光谱特征发生变化;这是近红外光谱方法用于食品产地确证的局限性所在,因现在对于特定农产品光谱分析波段以及预处理方法没有统一定论,且本研究建立的判别模型是基于当年样本数据建立的,在接下来的研究中,在预处理方法及特征波段的选取方面可以进行进一步的研究,并丰富品种及年份,使得模型更加稳定。近红外光谱技术结合PLS-DA法可以为松原大米品种及产地确证的进一步研究提供借鉴。
