3种修正的机器学习算法在逐3 h降水量预报中的比较应用
2020-02-24孙俊奎王占良
孙俊奎,王占良,张 颖
(云南省昆明市气象局,云南 昆明 650034)
降水预报是天气预报和防灾减灾工作的关键环节,特别是定量和定时的降水天气预报预警呈精准化趋势[1]。数值预报模式输出的降水量预报准确性较低[2]。天气预报业务常用的欧洲中心细网格预报场中降水场相对其他物理量场效果差,特别是强降水的预报效果更差。因此,对数值预报模式的其他物理量场解释应用再输出降水量场的研究十分必要。
数值预报释用技术从模式输出统计(MOS,model output statistics)和完全预报(PP,perfect prognosis)等线性统计回归方法,发展到非线性回归方法。目前常用的非线性机器学习算法有神经网络(BP,back propagation)方法[3]、支持向量机(SVM,support vector machine)方法[4-5]和Logistics判别方法[6-7]等。农吉夫等[8]基于主成分径向基函数(RBF,radial basis function)神经网络建立了降水预报模型;常军等[9]和陈超辉等[10]采用SVM回归方法开展了预测和预报研究;黄健敏等[11]和吴凡等[12]建立了Logistics回归的区域地质灾害和铁路水害预报模型。在此基础上,有人选用多家数值预报模式产品集成不同预报因子方案进行对比分析,优选效果较好的预报方案。但是很少有研究综合多种机器学习算法,优化算法参数,综合各种学习机器的优点,对比分析不同量级的降水在各种优化算法的特点及优劣。
研究基于3种机器学习算法建立3 h时间间隔的累计降水量预报模型,并分别采用遗传算法优化预报模型和修正的Logistics判别方法构建3种降水量预报模型,最后对比检验3种预报模型特点,综合各种方法的优点,在时间上实现了发布逐3 h分辨率的降水量的短期预报,在业务上具有一定的实用性。
1 资料与方法
1.1 资料
采用2016—2018年5—9月的欧洲中期天气预报中心(ECMWF,european centre for medium-range weather forecasts)细网格数值预报各种物理量场资料,通过插值方法把物理量值插值到石林站点上,构建预报因子。预报量为同期石林观测站未来3 d的3 h时间间隔的累计降水量。
首先根据降水过程的水汽条件和垂直运动条件等天气学条件,以及降水的物理机制,选取备选预报因子(见表1);然后,计算预报量与备选预报因子的相关系数,排列与预报量相关性较好的因子(见表2)。

表1 预报因子选取

表2 预报因子与降水相关系数
上述预报因子符合天气学原理,基本包括了预报站点的温度、湿度、稳定性参数和垂直速度等。而且各个优选预报因子之间的相关性较差,这样预报因子的共线性特征显著,预报因子代表性也良好。
根据中央气象台现行业务规定,3 h时间间隔累计降水量≤0 mm为无降水;0~0.1 mm为零星小雨;0.1~2.9 mm为小雨;3.0~9.9 mm为中雨;10.0~19.9 mm为大雨;20.0~49.9 mm为暴雨;50.0~69.9 mm为大暴雨;≥70.0 mm为特大暴雨。
1.2 机器学习算法
(1) PNN方法 概率神经网络(PNN,probabilistic neural network)结构简单,所需的训练样本较少,解决分类问题优势明显。PNN用线性的算法完成非线性学习算法,是一种具有强大的容错能力和结构自适应能力的非线性分类诊断网络系统。
PNN网络结构如图1所示。PNN网络由输入层、隐含层、求和层和输出层构成。向量x输入到隐含层中第i类模式的第j神经元的关系定义为[13]
Φij(x)=1/[(2π)1/2σd]·
exp[-(x-xij)(x-xij)T/σ2],
(1)
其中:i=1,2,…,M,j=1,2,…,L;M为训练样本总数;L为第i类神经元个数;d为样本空间数据的维数;σ为平滑因子,对网络性能至关重要。

图1 PNN网络结构Fig.1 PNN network structure
(2) SVM方法 支持向量机(SVM)是常见的一种机器学习判别方法,是一个有监督的学习模型,通常用来进行模式识别、分类以及回归分析。SVM方法是通过一个非线性映射提高样本空间维度,使得在低维度的样本空间中非线性问题映射后变为高维度空间中的线性问题。
根据SVM回归理论和降水量样本的复杂性,优选RBF核函数和Sigmoid 核函数,然后对惩罚系数C和核参数γ(γ为1/m,m为样本空间维数)进行优化,构建非线性回归预报模型,即[14]
(2)
K(x,xi)=exp(-γ‖x-xi‖2),
(3)
K(x,xi)=tanh(γxTxi+coef),
(4)
其中:f(x)为预报函数;M为支持向量的训练样本个数;ai、bi、b0为通过训练样本确定的最优超平面参数;K为核函数;xi为预报因子;coef为偏置系数。公式(3)即RBF核函数,公式(4)为Sigmoid核函数。
(3) Logistics判别方法 Logistics判别方法一般用于二分类问题[15],该函数方程为
P(x)=1/[1+exp(-xβ)],
(5)
其中:x为样本矩阵;β为待定参数;P为降水发生的概率值,位于0和1之间。
因为Logistic回归输出的只是预报概率,无法直接进行分类。一般以0.5为临界值,进行二类判别。但是在实际问题中,以分类准确率为标准,得到实际问题对应的预报概率的判断阈值pc。于是判断大于pc为一类,而小于pc的属于另一类。
2 降水预报模型
构建包含石林地区各种类型的降水天气过程的样本集合。采用2015—2017年5—9月期间的261 d 有效数据作为训练样本,训练样本数为2 088(每天8份3 h时间间隔累计降水量预报值)。
2.1 GA-PNN和GA-SVM算法的优化
PNN和SVM训练过程中容易出现局部最优问题。遗传算法(GA,genetic algorithm)能够进行全局搜索,通过选择、交叉和变异产生全局范围内的最优个体,从而弥补PNN和SVM模型不足。利用GA算法优化PNN网络平滑参数和SVM模型的惩罚系数以及核函数参数。
(1) GA-PNN设计和优化 选用11个降水预报因子,设计了PNN输入层对应有11个结点,输出层有8个结点,分别对应无降水、零星小雨、小雨、中雨、大雨、暴雨、大暴雨、特大暴雨。利用MATLAB函数newpnn创建的神经网络自动选择隐含层和求和层,使得误差尽可能小。
GA-PNN和GA-SVM算法1[16-17]:
第1步:参数设置:定义迭代次数D,种群规模B,交叉概率p1和变异概率p2。
第2步:fori=1∶D
① forj=1∶B
根据PNN(SVM)准确率定义适应度。
以适应度为标准进行重抽样,适应度越高,抽样概率越大。
② 以p1概率进行交叉。
③ 以p2概率进行变异。
第3步:输出最优个体,将最优个体带入PNN(SVM的惩罚系数和核参数)的平滑参数,得到改进后的模型。
PNN神经网络的径向基函数的平滑参数,一般默认是0.1,研究基于GA算法,通过大量训练样本的试验,以试验训练样本分类的准确率为结果目标,寻求最优平滑参数。结果发现,平滑参数取值0.126 0时,GA-PNN神经网络模型的分类正确率最高。建模试验的效果如表3所列。

表3 2种模型降水预报结果对比
(2) GA-SVM设计和优化 同样,选用11个降水预报因子,结果输出8个降水量级,算法见算法1。选用训练样本进行试验,定义最大迭代数为400次,最大种群是50,交叉验证准确率满足60%。
SVM主要是寻优惩罚系数和核参数,GA算法寻优SVM的迭代过程如图2所示,大约迭代200次以后,适应度值稳定少变。当惩罚系数为25.861 3,核参数为0.143 2时,GA-SVM模型的分类正确率最高。

图2 遗传算法优化SVM最佳参数的适应度曲线Fig.2 Fitness curve of the optimal parameters of SVM optimized by GA
2.2 Logistics回归判别模型
(1) Logistics回归 单个的Logistics回归只能得到一个降水量级概率,通过判断阈值可以解决二类问题的分类。首先,建立11个降水预报因子与3 h累计的某一降水量级的线性回归。线性回归方程为
y=β0+β1x1+β2x2+…+β11x11,
(6)
采用MATLAB回归函数nlinfit。其次,将回归的方程系数和预报结果值代入Logistics回归方程:
P=exp(y)/[1+exp (y)]。
(7)
最后,由修改后的Logistics回归方程得到某降水量级是否发生的概率。
(2) Logistics判别 Logistics判别的输出概率与某一阈值比较,得到分类结果。不同的阈值对应不同分类。受试者工作特征(ROC,receiver operating characteristic)曲线和曲线下方面积(AUC,area under the curve)是判别分类的评价标准。
不同降水级的ROC曲线如图3所示。由图3可知,3条ROC曲线,在假阳率等于0.3处取一条直线,ROC越往上,判别效果越好,晴雨的判别分类最好,大雨的判别分类最差。仅从ROC曲线不能完全体现判别分类的效果,于是通过AUC值辅助判断分类。AUC 值的计算公式为
(8)
其中:x、y为ROC空间坐标轴;M为样本数;AUC为ROC曲线下的面积,取值在0.5~1。由图3可见,晴雨、中雨和大雨的AUC分别是0.806 9、0.780 4和0.689 8,晴雨分类最优,中雨次之,大雨最差。降水量级越大分类效果越差。
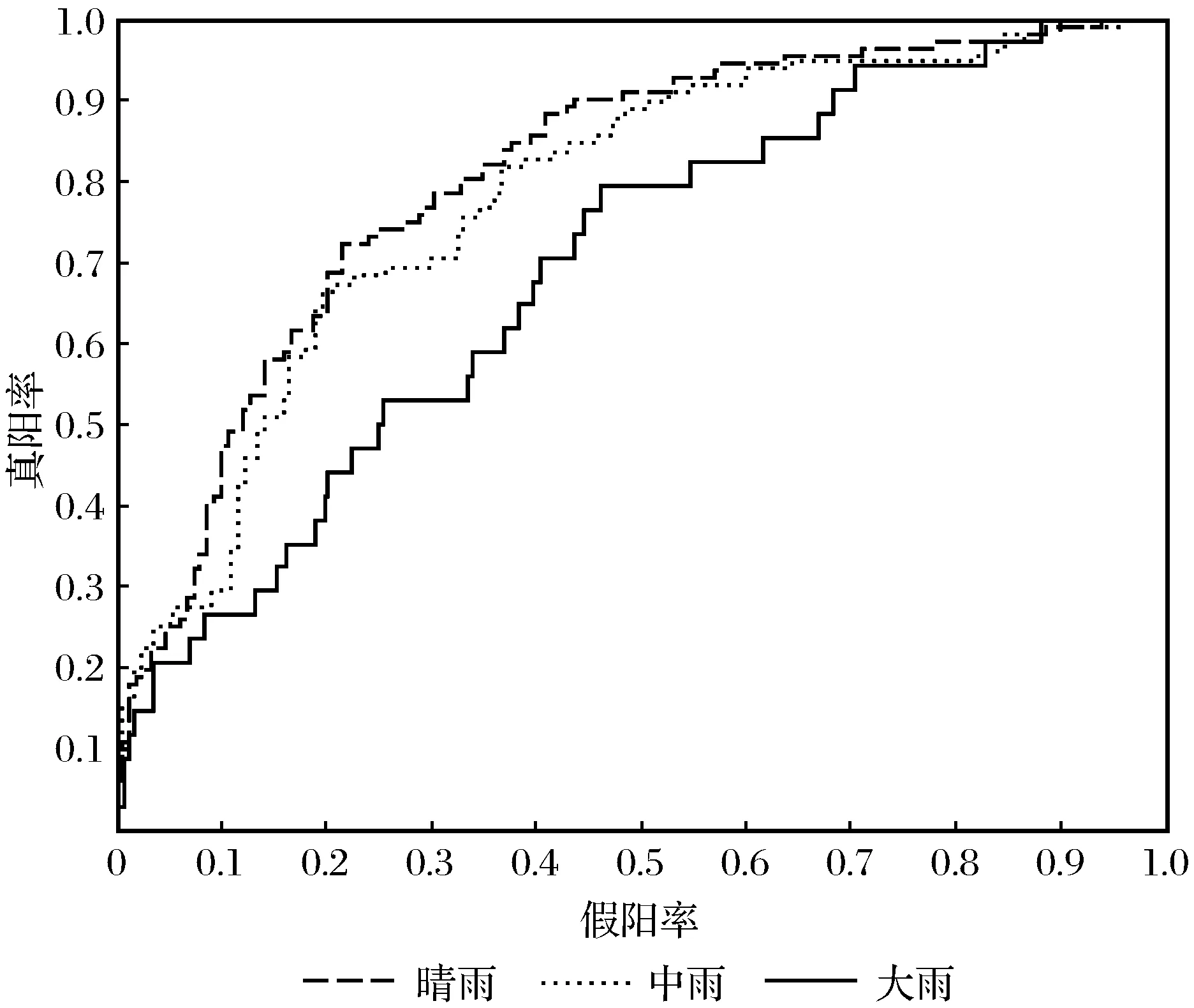
图3 不同降水级的ROC曲线Fig.3 ROC curves of different precipitation levels
如果这个分类器设定合适的阈值,则更能有预测价值。再次计算分类结果跟降水实况误差值,进而可计算符合气象预报业务准确性评价的TS(threat score)评分,从而得到最终的阈值pc。
以上为某一个降水量级的二分类方法,各级降水量的预报还需要进行多级判断。
Logistics判别算法2:
第1步:Logistics回归:计算各级降水量的概率p。
第2步:阈值计算:计算各级降水量AUC值,判断预报的可能性。在TS评分基础上计算最佳阈值pc。
第3步:定义样本数M,降水量级数N,y=1为正样本,y=0为负样本,某降水量级预报正样本正确票数rv,预报负样本正确票数为ro,漏报票数为lo,空报票数为ko。
fori=1∶M
① forj=1∶N
ifp>=pcandy=1
rv=rv+1
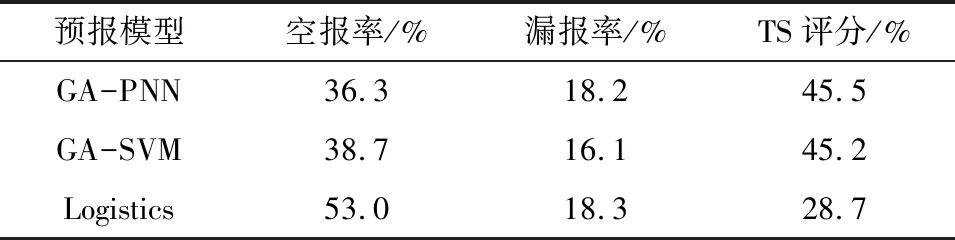
else ifp ro=ro+1 else ifp lo=lo+1 else ifp>=pcandy=0 ko=ko+1 end ② 求出每个降水量级的各类票数和,取最大票数为最终预报量级。 ③ 输出各个训练样本的预报结果以及TS评分、空报率和漏报率。 对训练样本进行计算得出,晴雨、中雨和大雨的概率阈值分别为0.581 7、0.543 0和0.518 2(其他降水量级略)。训练样本所得的准确率和TS评分如表4所列。 表4 Logistics模型降水预报结果 选用2018年5—8月汛期的100 d有效数据作为检验样本,检验样本数为800(每天8份3 h时间间隔累计降水量预报值)。GA-PNN、GA-SVM和Logistics 3种机器学习算法的检验效果见表5,GA-PNN、GA-SVM学习算法的降水量预报分级检验效果见表6。 表5 3种模型降水预报检验 表6 GA-PNN和GA-SVM模型降水预报分量级检验 由表5可知,GA-PNN和GA-SVM预报性能较稳定,Logistics算法较差。但是3种算法的漏报率较低。3种算法中GA-PNN和Logistics的泛化能力较好,GA-SVM算法在训练时最佳,但是检验时TS评分降低明显,可能存在过拟合现象。总体上看,3种算法可以参考使用,具有一定业务参考价值。 由表6的GA-PNN和GA-SVM算法的多级降水量预报检验结果可见,2种算法晴雨TS评分高于50%,较强降水(中雨)的TS评分超过30%,强降水(大雨)的TS评分近28%。而且2种算法的漏报率均在30%以下,GA-SVM的漏报率较大,而GA-PNN的空报率较高。2种算法可以对比使用,取长补短。 研究利用GA算法修正PNN和SVM机器学习模型,又扩展Logistics判别算法,实现多级分类功能,修正Logistics输出概率的阈值判别方法。建立3种机器学习算法模型,对比分析各类算法模型的优劣,得到如下结论: (1) 通过修正优化了PNN和SVM算法参数,使预报模型本地化,达到更好的预报效果。扩展Logistics判别算法和修正输出概率的阈值,实现Logistics判别算法多级降水量预报的可能性。 (2) GA-PNN和GA-SVM检验的TS评分在45%以上,Logistics判别算法的TS评分在28%以上,3种算法模型的检验漏报率均在20%以下。由此可见,GA-PNN和GA-SVM机器学习算法预报性能稳定,有较好的效果,Logistics判别算法效果较差,但也是一种很好的补充。 (3) 从扩展的Logistics判别算法的多级降水量预报检验结果可见,扩展的Logistics判别算法较强降水(中雨)的TS评分达36%,强降水(大雨)的TS评分近28%。虽然扩展的Logistics判别算法TS评分不高,但不失为一种补充使用的方法。 3种机器学习算法取得了较好的效果,但是Logistics判别算法的稳定性和强降水的TS评分不及30%,仍然需要进一步研究,如在预报因子组合和训练样本集合的优选方面还需不断完善。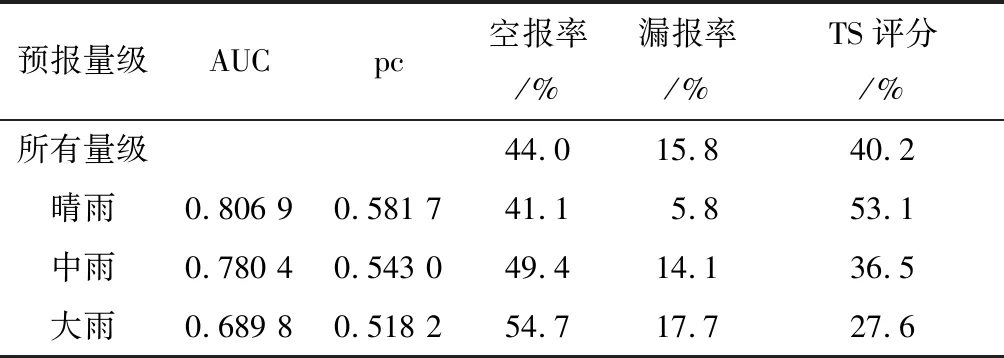
3 模型效果检验分析

4 结论
