煤矿机电设备运行状态大数据管理平台设计
2020-02-24曹现刚张鑫媛吴少杰
曹现刚,张鑫媛,吴少杰
(西安科技大学 机械工程学院,陕西 西安 710054)
随着现代工业与科技的不断发展,我国制造业规模和生产能力不断提升,自动化程度不断提高,设备的性能和状态对企业的产量和成本的影响也日益增强[1-3]。另一方面,由于各种先进制造技术、装备的产生和应用,以及电子商务等商业模式的快速发展,制造企业正面临着减少消耗资源、提高生产效益等严峻挑战[4]。
在煤炭行业,煤矿企业设备的运行已经进入少人甚至无人的智能化时代,由人与机器产生的数据也急剧增多。我国的大中型煤矿企业,由人产生的数据规模一般在TB级别以下,但形成了高价值密度的核心业务数据;机器数据规模已经达到PB级[5-9],是大量数据的主要来源,但数据的相对价值密度较低,传统的数据管理方式已经无法满足大量数据的管理需求。其次,由于数据的来源多样,包含产品全生命周期管理(PLM)及企业资源计划系统(ERP)等系统的关系型数据、传感器日志数据及视频监控数据等非结构化或半结构化数据,涵盖了所有的时间和空间上的数据关系,具有不同的格式和标准[10-12]。企业内部机电设备管理系统相互独立,实际中经常存在孤立的信息岛,数据无法得到合理、高效的利用,形成了“垃圾进,垃圾出”的数据管理现象[13-15]。基于上述现状,提出一种基于Hadoop的煤矿机电设备状态大数据管理分析平台,本平台集数据采集、数据转换、分布式存储、大数据挖掘、大数据分析建模等为一体,对煤矿机电设备运行状态的大量数据进行合理存储、利用,挖掘多源数据之间的信息和规律,推动煤矿企业内“信息孤岛”聚合为“信息大陆”。
1 平台总体设计
1.1 平台总体架构
结合煤矿机电设备运行状态大数据复杂、异构等特性以及企业用户的实际需求,本文将煤矿机电设备运行状态大数据管理平台总体架构分为五层:资源层、数据存储层、平台层、应用层服务层,平台总体架构如图1所示。
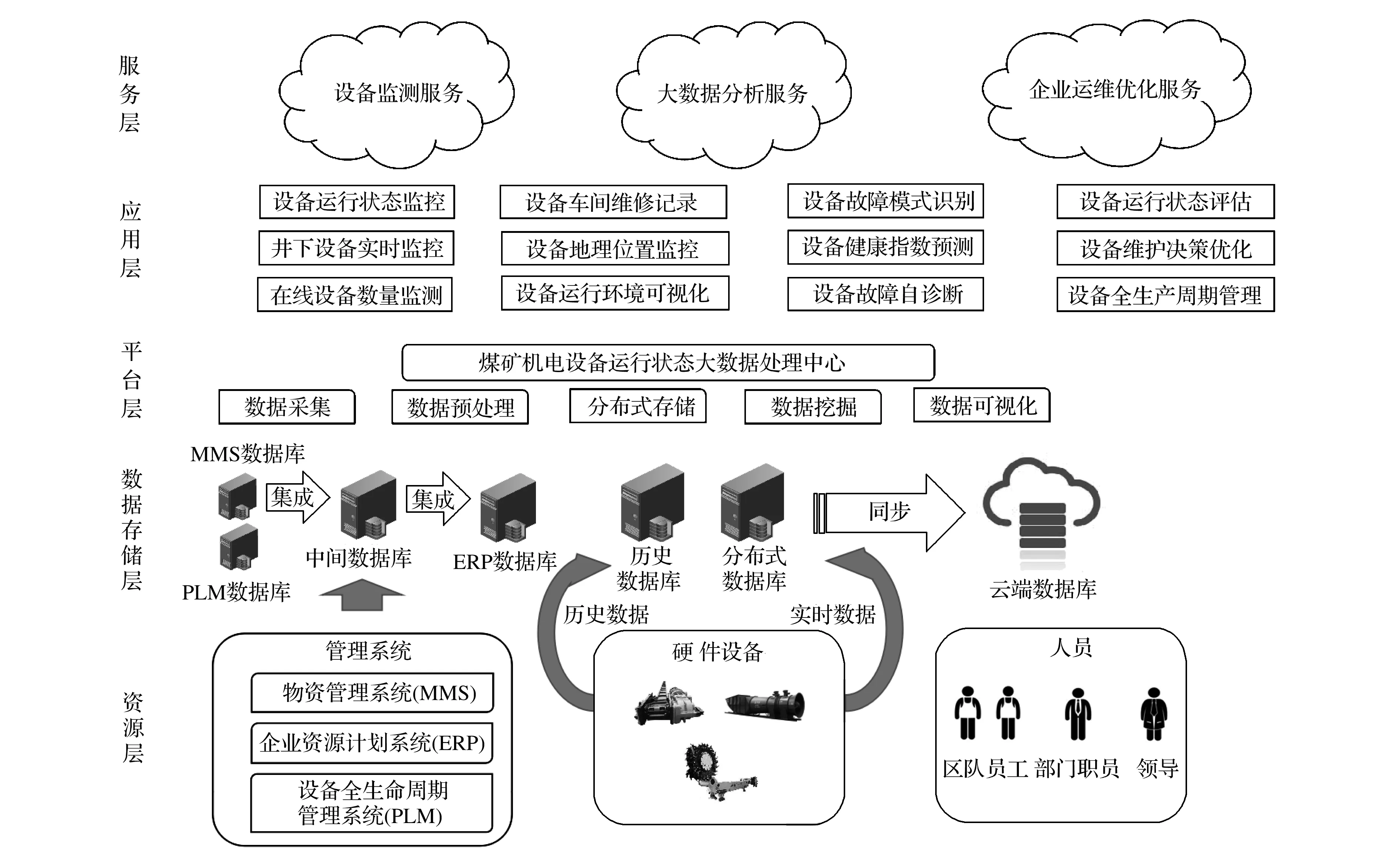
图1 平台总体架构
资源层为平台的数据源,由管理系统、硬件设备及人员构成,是整个平台的数据基础。管理系统包括物资管理系统、企业资源计划系统、产品全生命周期管理系统以及财务系统等;硬件设备由采煤机、矿井主通风机、刮板输送机、液压支架等硬件设备组成;人员由区队员工、企业各部门职员及领导组成。
数据存储层由各系统服务器、分布式服务器以及云端服务器组成,形成一个包含系统、设备和人员的多源异构数据资源池。煤矿企业系统软件对应各自的数据库服务器,通过中间服务器对数据进行集成,分布式数据库存储设备实时非结构化数据或半结构化数据,云端服务器则对需要进行数据挖掘、分析的海量数据进行同步存储。
平台层整合数据采集、处理、分析和显示为一体,建立“多元异构信息互联框架”。数据采集能够根据煤矿设备的多样性及大型部件高复杂性的特点,建立数据采集与分类规范;数据预处理针对物联网智慧终端采集来的数据进行降噪、清洗;数据分析在大量的历史数据、设备运行状态数据中,挖掘出高价值的内容;实时显示是设备运行状态的实时体现,可通过数据的统计分析处理,实现动态监测。
应用层面向企业业务需求,实现设备的互联、优化运行以及企业的高效运维。通过设备在线数量监测、井下设备实时监控等应用将零散的设备组成设备群,实现企业员工管理调度;设备故障自诊断、设备健康指数预测等应用能够降低设备的故障发生率,实现设备的“零故障”运行;设备维修效率优化、全生命周期管理等应用能够提升煤矿企业的运维效率。
服务层对各种应用进行整合,对平台各种功能进行服务化封装,不同的用户能够根据实际需求进行应用的定制,去除不必要的应用占用资源,实现系统服务的模块化、透明化、标准化。
1.2 功能模块
根据煤矿设备数据存储管理系统的功能目标,采用结构化设计方法对本系统的功能进行设计,主要分为数据采集模块、数据预处理模块、分布式存储模块、数据挖掘模块以及数据可视化模块,在以上五个主要功能模块下又被分为了若干个子功能模块,系统总体功能模型如图2所示。
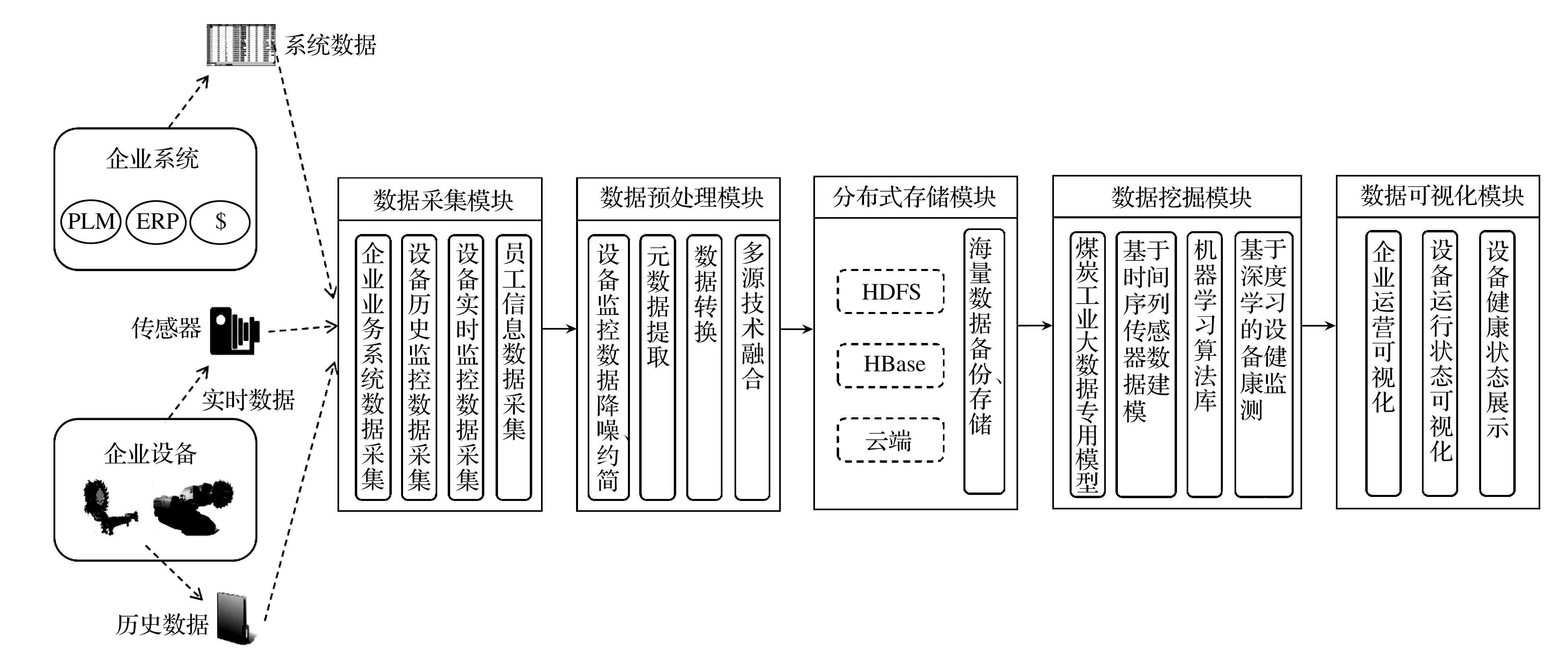
图2 系统功能模型
2 大数据管理平台关键技术
2.1 高通量数据管理技术
针对煤矿机电设备数据量大且关系复杂的特点,本平台提供基于Hadoop的分布式文件系统以及基于霍夫曼(Huffman)算法和LZW(Lenpel-Ziv & Welch)等的高效数据编码压缩方法对海量的结构化和非结构化数据进行写入。同时,为了实现设备运行状态大数据的高效共享和利用,在分析现有的各种资源描述技术的基础上,本平台提出了一种基于HBase分布式数据库的RDF(资源描述框架)数据存储模型。以RDF为基础的设备运行状态数据资源描述方法,建立了元数据模型,其中设备运行状态大数据资源本体如图3所示;设计的存储模型为设备运行状态大数据本体文件中定义的每个类创建HT-SPO(主语为行键)、HT-POS(谓语为行键)以及HT-OSP(宾语为行键)表,分别见表1、表2和表3,将RDF数据按照类的不同进行划分存储,在降低存储开销的同时提升查询效率,利用HBase的列存储、可扩展性等特性满足海量RDF数据的存储需求,满足RDF数据八种基本三元组模式的查询,为用户对海量数据的查询和索引提供服务,能够通过不同的方式进行高效查询。
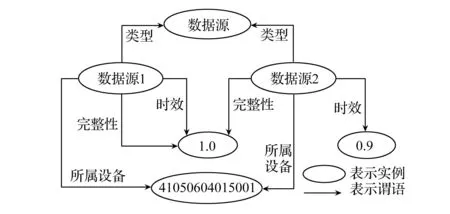
图3 设备运行状态大数据资源本体(片段)
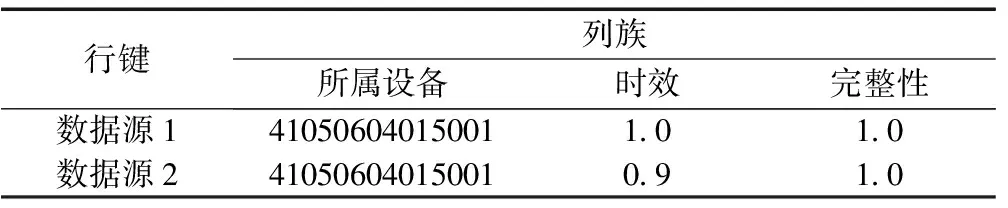
表1 HT-SPO表

表2 HT-OSP表

表3 HT-POS表
2.2 多源数据融合技术
针对煤矿机电设备的多种数据源形式,该平台提供多源数据融合技术。关系型数据以企业资源计划(ERP)为中心进行信息融合,融合过程借用中间数据库的对应接口表,并不直接将数据导入ERP系统,更是从层次化物料表(BOM)结构、运行环境等对工业大数据的语义进行一体化整合,将非结构化与半结构化的数据与BOM定义的企业核心语义结构的物理对象(设备或零部件)节点相结合,打破企业的“信息孤岛”。
为了对资源进行更加细致的描述,在对煤矿设备运行状态大数据资源的特性、功能以及类别进行详细分析的基础上,定义了一个具有通用性的设备运行状态大数据资源基本词集,核心内容包括:资源标识(ID)、资源名称(Name)、资源所属设备(Subordinate Equipment)、资源所属企业(Subordinate Enterprise)、资源位置(Position)、资源状态(Status)、资源创建时间(Creation Time)、资源约束信息(Restriction)以及基本描述(Description)等。本平台通过元数据定义通用对象实体的数据内容,通过数据接口标准对数据的交换进行规范,使得数据行业化,形成数据的资源池,完成数据的标准化体系和专业性数据化模型的建立。
2.3 并行化数据处理技术
针对煤矿机电设备数据质量差、可用性低的特点,本平台利用典型的机器学习算法,建立数据清洗和数据预警分析模型。提出了基于时间序列分析的设备运行状态大数据清洗模型,将设备运行状态大数据中存在的异常值进行分类,分析不同类型的异常值对建模的影响,通过迭代检验的方法将数据中的异常值检测并修复。为提高数据清洗的效率,将基于时间序列分析的数据清洗模型与MapReduce技术相结合,建立了双MapReduce的设备运行状态大数据清洗模型;针对非线性时间序列特征提取与处理的算法以及复杂BOM结构离散装备的分析建模,解析设备故障模式与特征之间的相互关系,实现设备运行状态健康监测、劣化趋势跟以及故障预警。除此之外,基于时间序列、时空数据以及序列模式的深度学习算法库也在逐步完善当中。
2.4 数据可视化技术
本平台利用数据可视化技术解析设备和人员信息的表达模式,研究设备故障模式与特征之间的相互关系,向用户多层次、多角度地展示设备运行状况,使数据更加具备客观性和说服力,提供的数据可视化技术包括:WEB前端技术、ECharts可视化技术工具、Ajax(异步JavaScript和XML)技术及多维数据可视化技术。本平台通过echarts.init方法初始化echarts实例,调用ECharts样本库文件,通过setOption方法进行图例设计,并利用Ajax技术异步发送JSON的格式数据请求,实现煤矿机电设备运行状态的动态加载。
3 系统测试与分析
为验证本文设计的煤矿机电设备运行状态大数据管理平台的数据存储性能、数据处理性能,在实验室搭建Hadoop集群进行性能测试,进行RDF数据存储模型实验以及并行化数据处理模型实验。
3.1 测试平台搭建
本文中Hadoop集群是在IBM-S822LC服务器上搭建而成,服务器配置NVIDIA Tesla K80 GPU、256G内存、960G固态硬盘以及10T的磁盘存储阵列,实现海量数据的高效处理与存储。通过在服务器上创建三台虚拟机组成Hadoop集群,其中一台虚拟机作为Hadoop的主节点即名称节点(NameNode),另外两台虚拟机作为从节点即数据节点(DataNode)。测试环境硬件配置见表4,软件配置见表5。
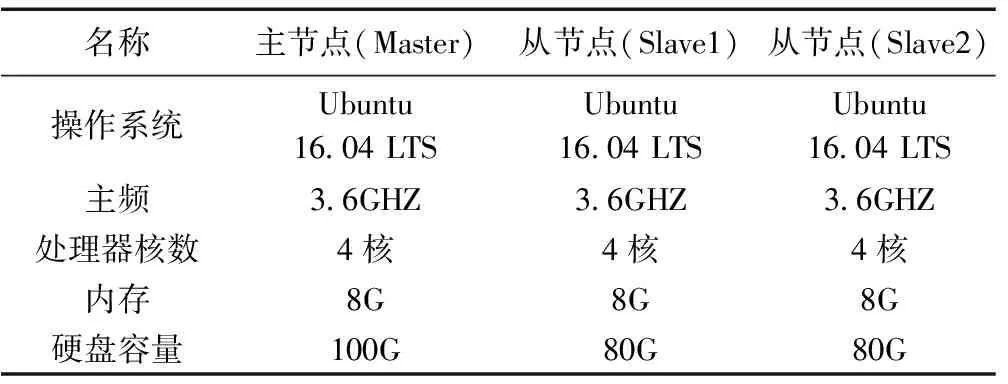
表4 Hadoop平台集群硬件配置
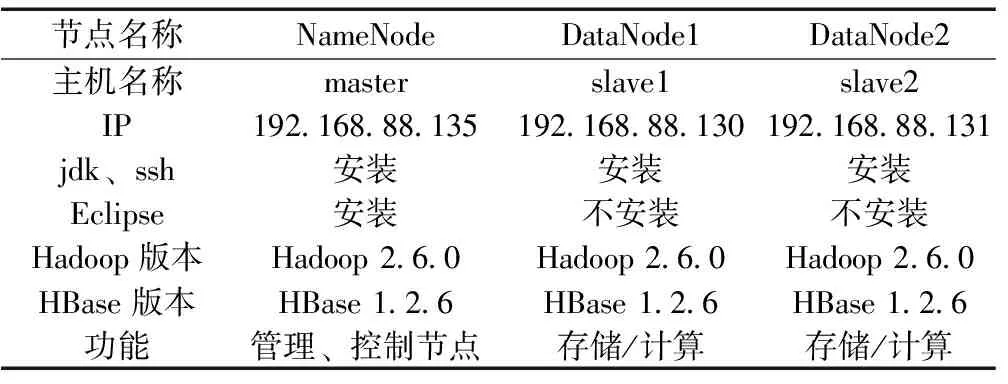
表5 虚拟机软件配置
3.2 RDF数据存储模型实验及分析
为验证RDF数据存储模型的可行性,对海量的RDF数据进行解析与加载,数据来源于设备运行状态大数据统一描述后生成的RDF的数据,本次实验分别对Oracle和Hadoop集群的数据存储性能进行测试,分别记载单机和集群对数据进行解析和加载的时间,结果如图4所示。
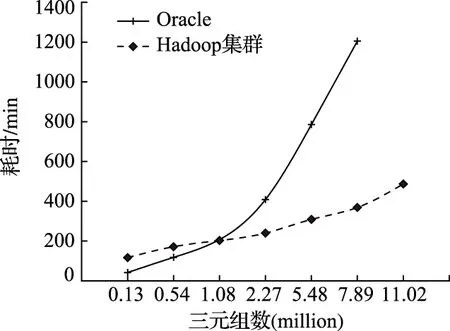
图4 RDF数据解析与加载时间对比
由图4可知,当三元组数目为1.08百万以下时,Oracle系统的数据解析和加载性能优于本平台,当三元组数目超过1.08百万时,Hadoop集群的优势越来越明显。原因如下:
1)集群对RDF数据进行加载时启动多个MapReduce任务需要耗费部分时间,因此,当数据量较小时,Oracle系统性能更优。
2)当数据量大时,Hadoop的优势体现于底层的HDFS进行分布式数据管理、 MapReduce进行并行数据处理,因此,所耗费的计算和网络资源更少,提高数据加载效率。
3.3 并行化数据处理模型实验及分析
本文在Hadoop平台上对设备运行状态大数据进行清洗处理,对存在的噪声点和缺失值进行修复,分别对基于时间序列清洗模型和本文提出的清洗模型进行分析,结果如图5所示。
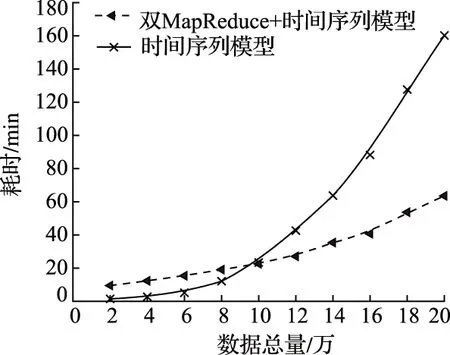
图5 数据清洗时间对比
从图5中能够得出,在数据总量较少时,由于系统初始化、中间文件的生成与传递耗时较多,因此,基于时间序列的数据清洗模型效果更优;随着数据量的不断增大,系统初始化、中间文件生成与传递所花费的时间与数据清洗的时间相比越来越少,本文建立的双MapReduce的设备运行状态大数据清洗模型就体现出了明显的优势。
4 结 语
本文简述了煤矿机电设备大数据的来源,指出煤矿企业在数据存储、处理方面所面临的难题,提出基于Hadoop的煤矿企业大数据管理分析平台。该平台集数据采集、多源数据数据融合、分布式存储、大数据挖掘分析等为一体,通过高通量数据管理技术和多源数据融合技术对数据进行融合转换,通过大数据挖掘分析算法对数据进行建模分析,进一步提升了数据管理能力,实现企业底层到上层的信息贯通。
