2维约束覆盖数组最小规模下限的提升
2020-02-24盛云龙魏长安姜守达赵伟志
盛云龙,魏长安,姜守达,付 尧,赵伟志
(1.哈尔滨工业大学 电子与信息工程学院 自动化测试与控制研究所,哈尔滨 150080;2.北京工业大学,北京 100000)
组合测试是一种重要的黑盒测试技术[1-4],利用更少的测试数据量,可以发现更多的由参数之间的相互作用引起的系统故障.通过对任意t个参数全部取值组合的覆盖,可以发现几乎100%的系统故障,因此又被称为“伪穷举测试”[5].
在实际测试中,参数之间往往存在约束条件,限制了参数之间的取值关系[6-8].这种情况下,组合测试的测试数据集被称为t维约束覆盖数组,其可覆盖任意t个参数之间满足约束的取值组合.t=2的约束覆盖数组被称为2维约束覆盖数组,因为其规模小,所以最为常用.为了提高实际测试的效率,2维约束覆盖数组的规模应尽可能的小,最好找到理论上最小规模的2维约束覆盖数组.然而找到规模最小的2维约束覆盖数组已被证明是NP完全(Non-deterministic Polynomial Complete,NPC)问题[9-10],因此为减少生成时间,很多测试数据搜索算法被应用到寻找规模最小或近似最小的2维约束覆盖数组.经典算法有HSS[11]、SA_SAT[12]、mAETG_SAT[13]、PICT、TestCover、IPOG[14]、IPOG-F[15]、CTWT[16]等.前两个算法属于启发式算法,其余算法属于贪心算法.
为了评价这些算法的性能,需要将这些算法生成的2维约束覆盖数组的规模与理论上的最小值进行比较.目前可以得出的理论最小值是任意两个参数之间满足约束的取值组合数的最大值,然而这个值只表示了约束下需要覆盖的取值组合数,并没有考虑约束的影响.由于约束的影响,2维约束覆盖数组不仅要考虑需要覆盖的取值组合数,还要考虑约束情况,约束的存在使得原本可以在一条测试数据中覆盖的取值组合,要被拆开放到多条测试数据中,这样就增加了测试数据的数目,导致2维约束覆盖数组的规模增加,因此2维约束覆盖数组最小规模要考虑约束的影响.
本文提出一种禁忌边分解方法,可以将描述被测系统输入配置的图分解成两个子图,通过计算覆盖两个子图中全部顶点的子覆盖数组的规模和剩余需要覆盖的取值组合数,与单纯计算需要覆盖的取值组合数相比,提升了2维约束覆盖数组的最小规模.提升的最小规模可以用于评价现有算法生成的2维约束覆盖数组,比较生成的2维约束覆盖数组的规模与理论最小规模之间的差距,同时最小规模有助于判断生成的2维约束覆盖数组是否真实存在.
1 基本概念
假设一个被测系统具有k个参数,分别为P1,P2,…,Pk,每个参数分别对应v1,v2,…,vk个取值,即对于任意参数Pi(1≤i≤k)其有vi个取值,具体表示为集合{0,1,…,vi-1},简记为[0,vi-1],各个参数之间取值均相互独立.记参数集合P={P1,P2,…,Pk},取值个数集合V={v1,v2,…,vk},配置空间模型(Configuration Space Model,CSM)M=
定义1(约束覆盖数组,约束混合覆盖数组)[17]:设A是一个n×k的矩阵,约束元组f=(a1,a2,…,ak)是一个k维向量,用于限制取值组合的出现,ai∈[0,vi-1]∪[x](1≤i≤k),如果约束中没有指定第j个参数的取值,则aj=x.对任意一个出现在测试数据中,且不会引起测试数据中出现约束元组的t维组合I={(Pi1,ai1),(Pi2,ai2),…,(Pit,ait)},aij∈[0,vij-1](1≤j≤t),如果A至少存在一行r,使得A[r,ij]=aij且不覆盖约束元组,则称A为约束覆盖数组(Constrained Covering Array,CCA),记为CCA(n;t,k,v;F),其中F是约束元组f的全集.
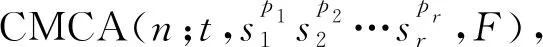
定义2(带有禁忌边的覆盖数组)[9]设A是一个n×k的带有禁忌边的覆盖数组(Covering Array with Forbidden Edges,CAFE),表示为CAFE(n,G),其中G=G(g1,g2,…,gk)是参数取值构成的图,gi(1≤i≤k)是图中第i列顶点的集合,E(G)是G中的边集,简记为E或EG.对A中任意一列,其取值范围为[0,|gi|-1].对任意的不属于同一列的两个顶点ai∈[0,|gi|-1]和bj∈[0,|gj|-1](i≠j),如果{ai,bj}∉E(G)且满足约束一致性,则A中一定存在一行r,使得A[r,i]=a,A[r,j]=b.
E中的边就是约束,在图中被称为边或禁忌边.CAFE(n,G)是力度为2的约束覆盖数组.N或NG用来表示对应于图G的覆盖力度为2的带有禁忌边的覆盖数组的最小规模.从图G中容易得出如下式所示关系式:
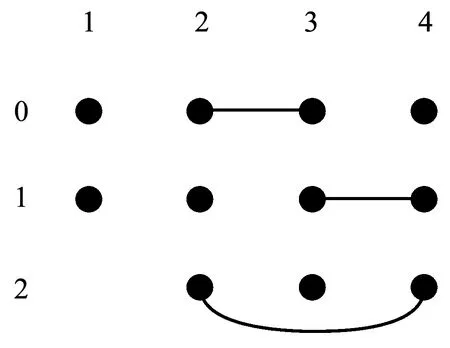
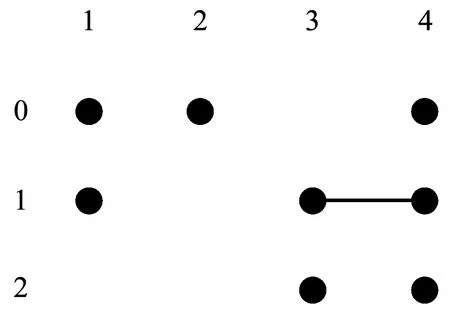
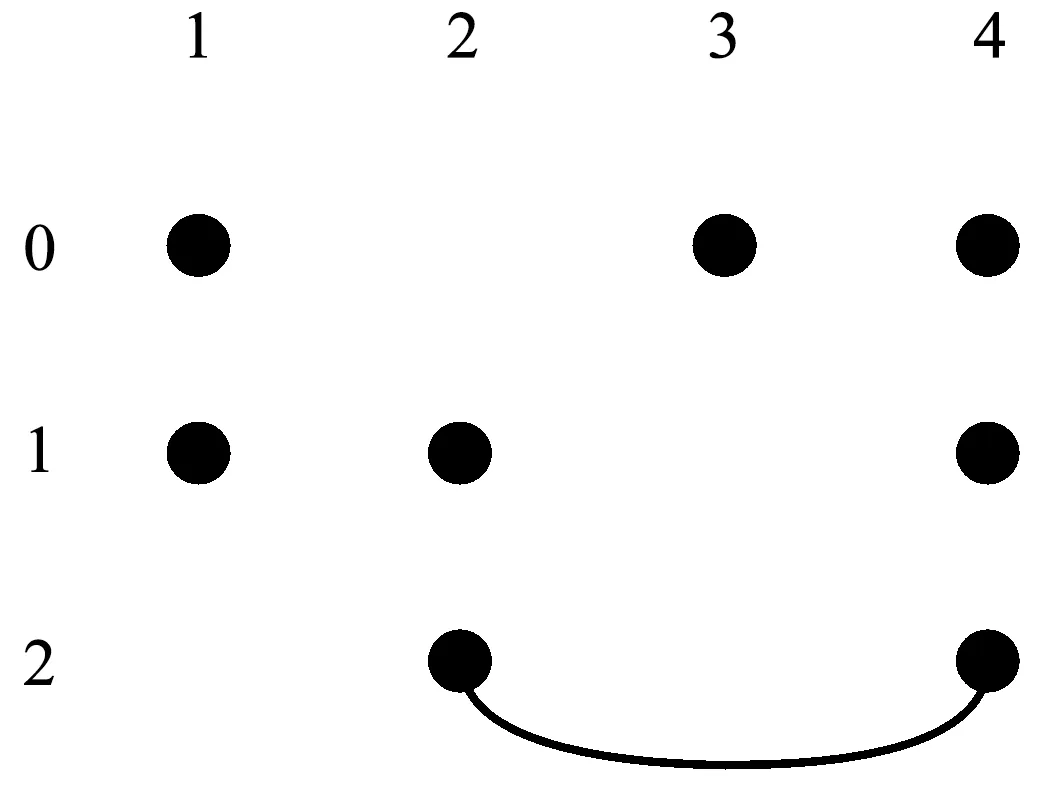
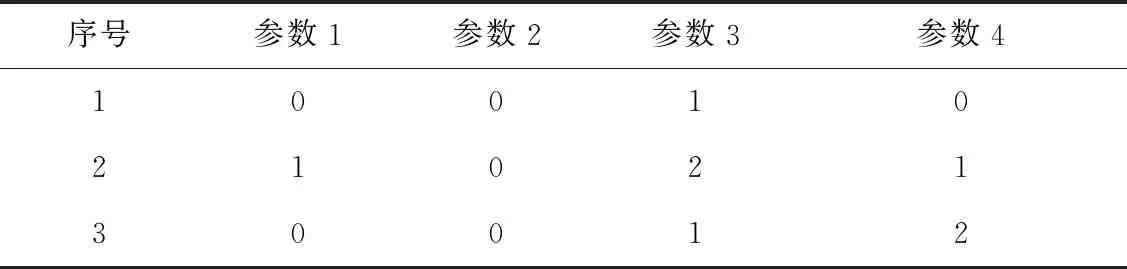
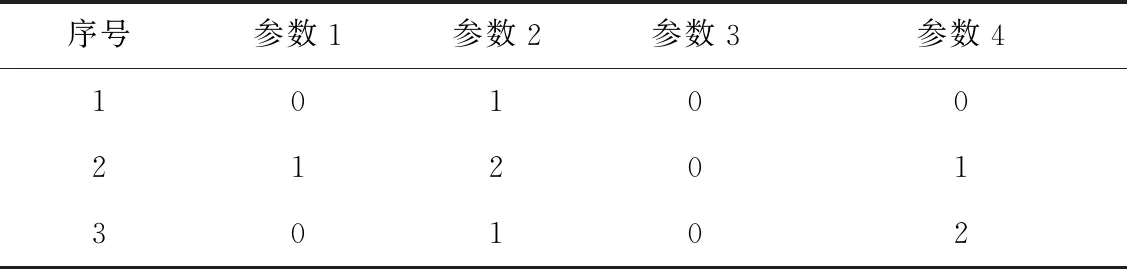
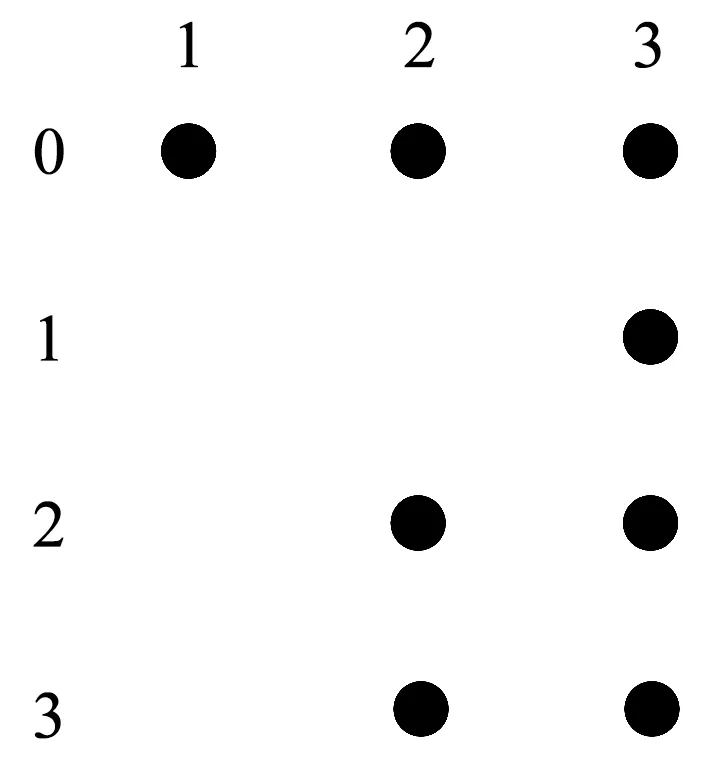
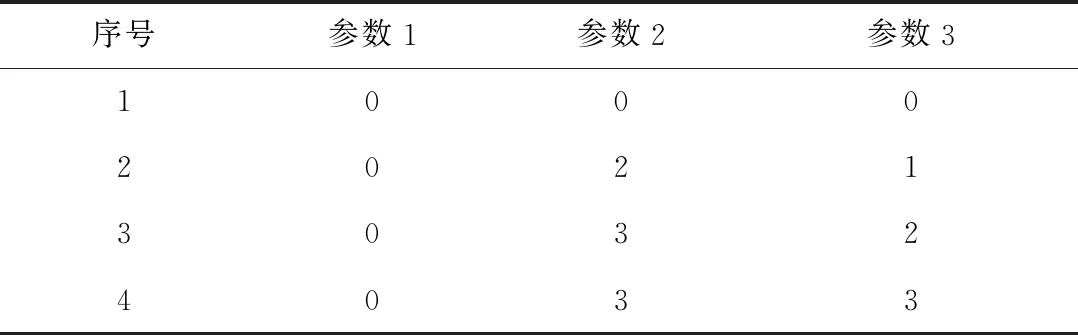
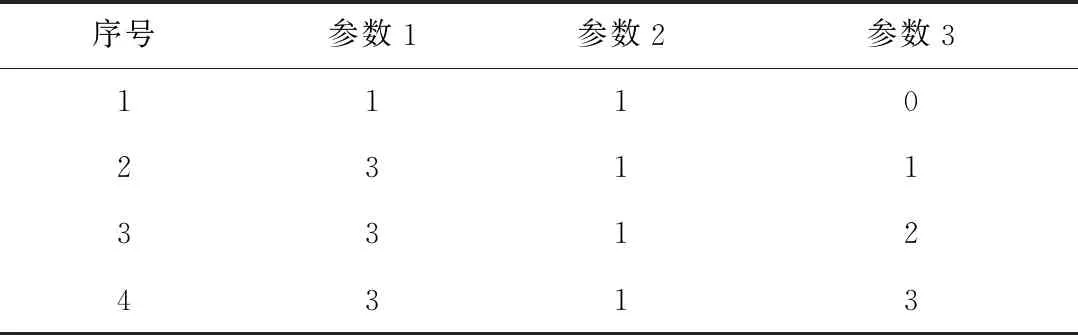
NG≥max1≤i (1) 式(1)中Eij表示图G中第i列和第j列中满足约束一致性的边,NG的下限是图G中任意两列满足约束一致性的取值组合个数的最大值. 定义3(顶点子图)Gi,a是图G的一个子图,移除了图G中第i列除了a之外的全部顶点(1≤i≤k),并且移除了与第i列中顶点a构成边的顶点. 定义4(顶点带禁忌边的覆盖数组)A是顶点子图Gi,a的一个n×k的顶点带有禁忌边的覆盖数组,顶点带有禁忌边的覆盖数组简记为CAFE(n,Gi,a),对顶点子图Gi,a中的任意一个顶点bj,A中一定存在一行r满足约束一致性且A[r,j]=b. 定义5(两列的取值组合个数)Ii,j(AGi,a)表示CAFE(n,Gi,a)中覆盖的第i列和第j列的取值组合个数.如果取值组合重复出现,则只记录一次. 式(1)在估计NG的范围时,只是根据两个参数之间满足约束的取值组合数进行估计,并没有依据实际的约束的特点进行估计,因此得出的NG的范围较为宽泛,通过对禁忌边进行分解可以更准确的估计NG的范围. 通常把地表500 m以下的矿床和矿体统称为深部矿。进行深部找矿的主要目的是为了找寻更多的矿产接替资源,以促进我国矿产资源的可持续发展。深部找矿主要在勘查程度较高的地区和现有矿山及其外围进行,其勘查对象主要是隐伏矿床(体)。 通过对图中的边进行分解,进一步分析组合约束对其余取值的限制关系,可以更为准确的得到CAFE(n,G)的最小规模NG的下限,式(2)所示为对G中的一条边(ai,bj)进行分解得到的NG的下限. NG≥max1≤i (2) 如式(2)所示,(ai,bj)是图G中的任意一条边,基于边(ai,bj)中的两个顶点可以从图G中分出两个顶点子图Gi,a和Gj,b.AGi,a和AGj,b是Gi,a和Gj,b对应的两个顶点带禁忌边的约束覆盖数组,NGi,a和NGj,b是AGi,a和AGj,b的规模,Ii,j(AGi,a)和Ii,j(AGj,b)是AGi,a和AGj,b中i和j两列参数的取值组合数. 式(2)的含义有如下两种解释: 1)为了覆盖第i列和第j列参数的|gi||gj|-|Eij|个取值组合,CAFE(n,G)规定一定包含顶点ai与第j列参数的全部满足约束的取值组合和顶点bj与第i列参数的全部满足约束的取值组合,这两组参数取值组合分别在规模最小的AGi,a和AGj,b中被覆盖,然而CAFE(n,G)中仍有|(|gi||gj|-|Eij|-Ii,j(AGi,a)-Ii,j(AGj,b)个满足约束的取值组合需要覆盖,加上已经生成的规模NGi,a+NGj,b,即得到NG的下限. 2)因为最终生成的覆盖数组中一定覆盖了包含顶点ai与第j列参数的全部满足约束一致性的取值组合,和顶点bj与第i列参数的全部满足约束的取值组合,所以规模最小的AGi,a和AGj,b一定存在于CAFE(n,G)中,原本CAFE(n,G)的最小规模为|gi||gj|-|Eij|,但是为了覆盖其中的Ii,j(AGi,a)个参数取值组合,需要增加的测试数据规模为NGi,a-Ii,j(AGi,a),为了覆盖Ii,j(AGj,b)个参数取值组合,需要增加的测试数据规模为NGj,b-Ii,j(AGj,b),所以为了覆盖|gi||gj|-|Eij|个取值组合,至少还要在其基础上增加NGi,a+NGj,b-Ii,j(AGi,a)-Ii,j(AGj,b)条测试数据. 以一个有4个参数的被测系统为例,其第1个参数有2个取值(0和1),其余参数有3个取值(0、1和2),其中参数2和参数3的取值组合(0,0)、参数2和参数4的取值组合(2,2)、参数3和参数4的取值组合(1,1)是约束,如图1所示. 图1 被测系统参数及取值配置对应图举例 Fig.1 Example graph of the parameters and value configurations of the system under test 为其生成带有禁忌边的覆盖数组时,按照式(1)的结论,可以得出NG≥9-1=8.然而在实际构造带有禁忌边的约束覆盖数组时,由于约束的存在,需要增加一定的测试数据才能覆盖8个取值组合,其最小规模为10,如表1所示.为了证明其最小规模为10,采用禁忌边分解方法首先对图进行分解,然后计算需要覆盖的参数间的取值组合数. 表1 带有禁忌边的覆盖数组举例 图2和图3分别是顶点子图G2,0和G3,0,在G2,0中移除了与第2个参数顶点0同一列的其他取值,同时移除了与顶点0构成边的其余参数的顶点,参数3的顶点0.同理可得G3,0.表2和表3分别是对应顶点子图G2,0和G3,0的CAFE(3,G2,0)和CAFE(3,G3,0),记为AG2,0和AG3,0,其规模都为3.因为每个顶点子图中,参数4最多有3个取值,所以覆盖这两个顶点子图中的全部顶点(取值)至少需要3条测试数据.所以AG2,0和AG3,0都具有最小规模,且覆盖的参数2和参数3的取值组合数I2,3(AG2,0)和I2,3(AG3,0)都是2,所以由式(2)可得NG≥3×3-1+3+3-2-2=10,从另外的两个边着手也可以得到相同的NG的下限,因此可以得出NG的下限就是10. 图2 G2,0 图3 G3,0 表2 CAFE(3,G2,0) 表3 CAFE(3,G3,0) 根据对图中边进行分解计算CAFE(n,G)的最小规模下限的过程,可以得出如下推论: 如果一个图满足下面3个条件: 1)所有的列具有相同的顶点数,即被测系统的每个参数具有相同的取值个数|g1|=|g2|=…=|gk|=g; 2)参数i和j之间只有一条边(ai,bj),a,b∈[0,g-1],i,j∈[1,k]且i≠j; 3)不存在任意顶点cl,c∈[0,g-1]且l∈[1,k],使得(cl,ai),(cl,bj)∉EG. 则有如下关系: NG≥|gi||gj|-1+|gi|-(|gi|-1)+ |gj|-(|gj|-1)=|gi||gj|+1=g2+1 上述推论的证明过程与上例计算NG的过程相同.该推论可以用一个简单的例子来理解,假设图G中每一列都有g个顶点,G中没有边时NG≥g2.假设存在一个带约束的禁忌覆盖数组AG覆盖了全部参数的取值组合,其规模为g2,当G中有一条边时,AG中一定存在至少一行违反了约束,违反约束的行至少要被扩展成两行才能满足约束,所以CAFE(n,G)的规模至少要增加1,因此,带有一条边的图G满足NG≥g2+1. 本文利用禁忌边分解方法给出5个典型被测系统的2维约束覆盖数组的最小规模的下限,典型的被测系统的配置如表4所示,这些系统来自于文献[11]和[16].现有算法生成的2维约束覆盖数组的规模如表5所示.禁忌边分解方法给出的最小规模的下限如表6所示.通过与生成的约束覆盖数组的规模进行比较,可以看出除了HSS为第2个被测系统生成的规模16小于下限17,其余结果都大于等于给出的下限.小于基于禁忌边分解方法给出的最小规模下限的约束覆盖数组一定不存在,可通过实际的生成过程来说明. 表4 被测系统的配置 表5 现有算法生成的2维约束覆盖数组的规模 Tab.5 Sizes of the 2-way constrained covering arrays generated by the existing algorithms 方法被测系统12345HSS1016263651SA_SAT1017263652mAETG_SAT1017263752PICT1019273956TestCover1017303854IPOG1117283955IPOG-F1018283854CTWT1017273852 表6 禁忌边分解方法给出的最小规模的下限 Tab.6 Lower bounds of the minimum sizes obtained by the forbidden edge decomposing method 被测系统12345最小规模下限1017253650生成规模1016263651 图4是第2个被测系统参数及取值配置对应的图,图5和图6是选取其中第1个参数的值0和第2个参数的值1构成的两个顶点子图.对应这两个顶点子图,能得到表7和表8给出的CAFE(4,G1,0)和CAFE(4,G2,1),记为AG1,0和AG2,1,其规模都为4,表中覆盖了第1个参数和第2个参数的5个取值组合,但是仍有9个取值组合没有被覆盖,如表9所示.所以可得出NG≥4+4+9=17,即第2个被测系统的约束覆盖数组规模的最小值不能小于17.违反禁忌边分解方法给出的最小规模的下限时,覆盖数组一定不存在,没有违反也不一定能够说明约束覆盖数组不存在,此时只有得到实际生成的约束覆盖数组才能进行验证. Fig.4 Graph of the parameters and value configurations of the 2nd system under test 图5 第2个被测系统的G1,0 图6 第2个被测系统的G2,1 表7 第2个被测系统的CAFE(4,G1,0) 表8 第2个被测系统的CAFE(4,G2,1) 表9 第2个被测系统的未被覆盖的取值组合 Tab.9 Uncovered value combinations of the 2nd system under test 序号参数1参数2110212313420522623730832933 本文提出了一种分析2维约束覆盖数组最小规模的禁忌边分解方法.通过将图分解成两个顶点子图,生成两个顶点带有禁忌边的覆盖数组,计算其规模和剩余需要覆盖的取值组合数,提升了2维约束覆盖数组的最小规模.该方法能够得到提升的2维约束覆盖数组的最小规模,更逼近真实值.生成的最小规模可以用于评价现有算法生成的2维约束覆盖数组,有助于判断其是否真实存在.2 基于禁忌边分解方法的约束覆盖数组最小规模下限的提升
3 试验结果与分析





4 结 论
