基于一维卷积神经网络的网络流量分类方法
2020-02-19李道全黄泰铭
李道全,王 雪,于 波,黄泰铭
青岛理工大学 信息与控制工程学院,山东 青岛266520
1 引言
流量分类在网络流量工程中具有重要意义。通过将流量准确分类,可以实现服务质量保证(QoS),资源合理化使用,恶意软件检测以及入侵检测等目的[1]。近年来,对于流量分类工作的研究在不断的发展。最初的方法是基于端口的流量分类方法,这种分类方法虽然简单高效,但由于出现了很多应用程序伪装端口号或不使用标准注册端口号的情况,使得这种分类方法的准确度在不断下降[2]。文献[3]中提出的使用深度包检测机制(DPI)进行流量分类的研究方法解决了基于端口的分类方法所带来的问题,然而这种基于数据包中载荷信息进行流量分类的方法只适用于未加密流量并且计算开销很高。因此,基于统计特征的新一代方法应运而生,这种分类方法依赖于统计特征或时间序列特性,能够处理加密和未加密的流量。基于统计特征的分类方法通常采用经典的机器学习(ML)算法,如文献[4]提出使用无监督聚类算法(K-means)进行流量分类并取得了90%的分类准确度,后来的文献中相继使用监督式分类算法(如KNN、C4.5、Naive-Bayes)与半监督式分类算法进行流量分类并取得了较高的分类准确度[5-9]。基于机器学习的流量分类方法由于依赖特征的选取,从而限制了它们的可推广性。近来关于使用机器学习算法进行流量分类的研究也主要以优化特征的选择为主[10]。
随着人工智能及大数据时代的到来,深度学习算法在图像识别、自然语言处理以及情感分析等各大领域都取得了很好的应用。这种学习算法通过训练过程自动选取特征,可以用来解决使用机器学习算法进行网络流量分类的特征选取问题。文献[11]使用多层感知机(MLP)进行流量分类与传统机器学习算法的流量分类效果作比较,但是由于文中各分类器使用的分类数据集并不相同,其最终结果无法比较深度学习算法与机器学习算法对于流量分类的准确度。文献[12]首次提出一种端到端的流量分类模式,使用传统一维卷积神经网络结构,将数据处理为特定的文件形式,通过卷积神经网络构造特征空间,然后使用分类器进行分类并取得了较好的分类结果。本文在其研究基础上重新设计了一维卷积神经网络模型,从神经网络结构、数据预处理方式、代价函数以及梯度优化方面提高了一维卷积神经网络对于加密应用程序的流量分类效果。
2 应用程序流量分类问题描述
基于客户机下载的内容多于他们上传的内容而设计的现有网络接入链路结构是不对称的,然而对称需求应用程序(如对等(P2P)应用程序、IP语音(VoIP)和视频呼叫)的普遍性改变了客户的需求,使其偏离了最初的设计。因此,为了给客户提供满意的体验,需要其他应用程序级别的知识来为这些应用程序分配足够的资源。对用户隐私和数据加密的日益增长的需求极大地提高了当今互联网的加密流量的数量[13]。加密过程将原始的流量数据转换成一种伪随机格式,使其难以解密。这种加密过程导致流量数据几乎不包含任何可被用来识别网络流量的数据模式。因此,对于加密的应用程序流量的准确分类已成为现代网络的一个挑战[14]。
应用程序流量分类问题的传统处理流程如图1所示,特征的选择是传统流量分类的研究瓶颈。本文使用的卷积神经网络可以从原始数据集中通过多层卷积网络进行学习自主选择特征,然后根据卷积神经网络自身网络结构构造特征空间并通过大量数据的训练不断优化特征空间。这种分类方法不仅解决了特征选择的困难而且为在线流量分类提供了可能。
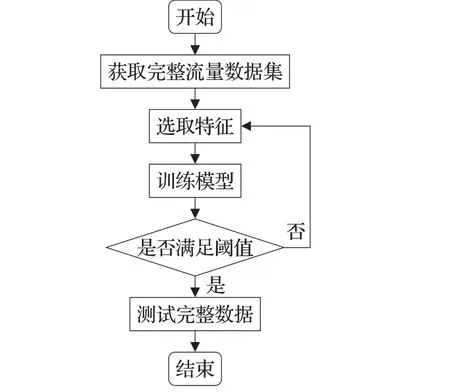
图1 传统流量分类流程图
3 1D-CNN流量分类方法
3.1 数据集来源
基于卷积神经网络流量分类方法的研究是监督式的,需要有完全标记的数据集作为训练子集。本文采用网络公开数据集“ICSX VPN-nonVPN”,已有不少文献使用该网络数据集进行研究,如文献[12,15]。本文采用的流量数据集统计信息如表1所示。数据集中流量类型包含通过虚拟专用网络(VPN)会话捕获的数据包。VPN是分布式站点之间的一种专用覆盖网络,通过公共通信网络(如Internet)上挖掘流量来运行。VPN最突出的方面是通过隧道IP数据包,确保对服务器和服务的安全远程访问[16]。与常规(非VPN)通信类似,VPN通信是根据不同的应用程序而被捕获的,如语音呼叫、视频呼叫和聊天等。本文根据表1中应用程序的种类进行网络流量分类,应用程序的种类数量对于本文神经网络模型结构的设计十分重要。

表1 本文流量数据集统计信息
3.2 数据预处理
在模型训练前必须经过的一步是数据的预处理,文献[12]开发了一种数据预处理工具“USTC-TK2016”,对原始数据包进行流量切分、流量清理、图片生成等一系列操作后将训练数据集和测试数据集生成为不同类型的IDX文件形式。本文的数据预处理流程图如图2所示。
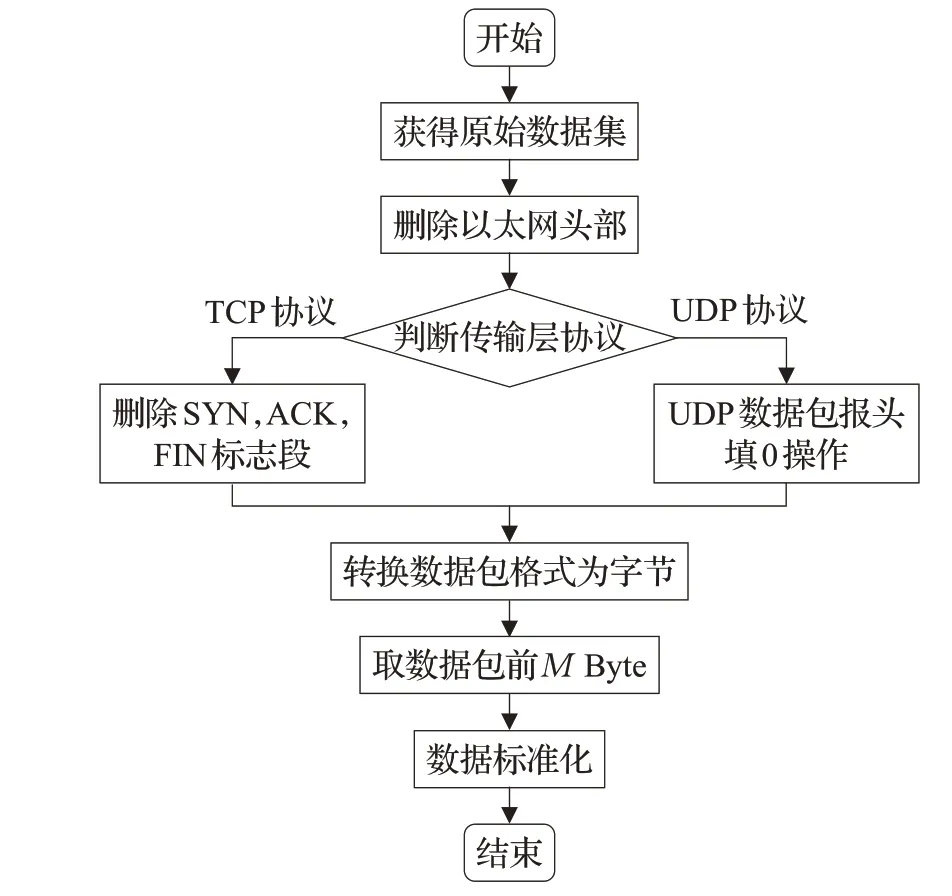
图2 数据预处理流程图
由于“ICSX VPN-nonVPN”数据集是在数据链路层捕获的,因此它包括以太网头。其中包含有关物理链路的信息,例如媒体访问控制(MAC)地址,这对于网络中帧的转发是必不可少的,但对于应用程序标识或流量特征化分类任务来说,它没有具体的意义。因此,在数据预处理阶段,首先删除以太网头。在传输层段,传输控制协议(TCP)和用户数据报协议(UDP)在报头长度上有所不同。前者报头长度通常是20个字节长度,而后者仅8个字节。为了使传输层段长度一致,在UDP段头的末尾添加零,使其与TCP段头的长度相等。然后将数据包从位转换为字节,这有助于减小卷积神经网络的输入大小。
因为数据集是在真实网络中捕获到的,所以含有一些本文不感兴趣的数据包,如在建立连接或完成连接的过程中的SYN、ACK、FIN标志段,这些字段并不携带有关生成它们的应用程序的信息,因此可以将这些段删除。此外,数据集中还有一些域名服务(DNS)段。这些字段用于主机名解析,即将URL转换为IP地址,这些字段与流量分类不相关,因此从数据集中删除。
经过以上步骤后的数据包文件已经满足流量分类的数据集的要求,然而除了考虑数据包中的有效载荷问题外还需要考虑卷积神经网络的输入要求。图3显示了经过以上步骤处理后的数据包长度概率密度分布图。如柱状图所示,数据集中的数据包长度变化很大。而使用卷积神经网络模型则需要使用固定大小的输入,因此需要选取固定的数据包长度。在文献[12,15]的经验基础上,使用全部的数据包长度会增大算法所需的空间和时间复杂度,因此本文选择同文献[12]相同的前784 Byte,对于有效负载小于784 Byte的数据包在末尾处作补零操作。为了获得更好的性能,进行离差标准化(min-max Normalization)操作将所有输入值归一化到范围[0∶1]内。

图3 数据包长度概率密度分布图
3.3 卷积神经网络结构
迄今为止,深度卷积神经网络已广泛运用于计算机视觉以及自然语言处理方面。文献[17]指出了一维卷积神经网络适用于序列数据或语言数据,二维卷积神经网络擅长处理图像或音频频谱图等数据,三维卷积神经网络适用于视频或体积图像等数据。
本文通过分析流量数据的特点得出:流量数据是一个按层次结构组织的一维字节流。字节、数据包、会话和整个流量的结构与NLP领域中的字符、字、句和整篇文章的结构非常相似。这种序列类型的数据非常适合选用一维卷积神经网络进行流量分类。本文设计的一维卷积神经网络模型如图4所示。
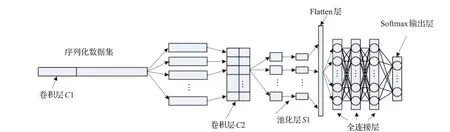
图4 卷积神经网络模型图
由图4可知,卷积神经网络模型的结构为:输入层、卷积层、卷积层、池化层、三层全连接层以及输出层。卷积层共两层,分别为C1、C2,卷积层可表述为:

其中,x代表输入,k代表卷积核,b代表偏置值。f为激活函数,常用的激活函数有ReLu、tanh、sigmoid等函数。本文选用的激活函数为ReLu函数。卷积层C1在序列化数据集上作窗口滑动与原始数据进行卷积操作后得到第一层特征。卷积层C2在得到的特征上继续作与C1相同的操作后得到更高级别的特征。
池化层为S1,池化层通常又称为下采样层,其主要作用是在保持特征不变性的前提下去掉一些冗余信息把重要的特征抽取出来,在一定程度上可以防止过拟合。池化层可表述为:

其中β和b为标量参数,down为下采样选择的函数,一般有最大池化和平均池化。考虑到最大池化层会产生大量数据信息的丢失,本文选用的池化层为平均池化。
通过以上操作后得到多个一维特征层,Flatten层用来将多个一维特征层“压平”,即将特征层一维化。然后将一维化后的特征数据输入到三层全连接层中,通过全连接层将特征空间映射到样本标记空间。在全连接层中为了防止过拟合本文采用了早停法技术(early stopping),这种技术可以根据损失函数值不再改变时提前结束训练过程以此避免网络模型对训练数据的过度拟合。为了加快学习速率,在全连接层中添加了批量归一化技术(Batch Normalization)。
输出层采用的是Softmax函数分类器,假设通过全连接层后的输出为y1,y2,…,yn,经过Softmax层操作后的输出为:

新的输出可以理解为一个样例为不同类别的概率分别是多大。这样就把神经网络的输出变成了一个概率分布,从而可以通过交叉熵函数来计算预测的概率分布和真实样本的概率分布之间的距离。交叉熵函数表达式如式(4)所示:
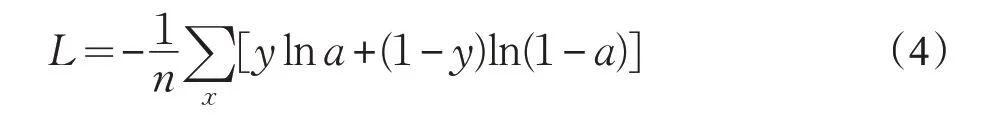
按照以上神经网络模型的结构,根据网络流量数据集输入特性要求,本文设计了如表2所示的4种不同超参数的网络模型,对于每一种网络模型进行10次10折交叉验证法寻找模型的最优参数,每次实验的结果为10次交叉验证的平均值。
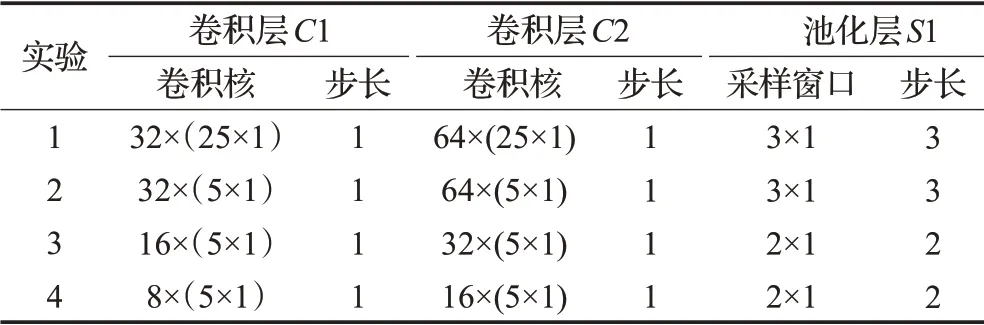
表2 不同超参数表
4种不同的实验编号的模型训练准确率对比图如图5所示,模型测试时间对比图如图6所示。通过不同超参数模型的训练准确率以及模型测试时间对比,实验2和实验3的模型训练准确率较高,而实验3和实验4的模型训练时间较短,因此本文选用的是实验3的超参数空间。本文完整的参数配置如表3所示。
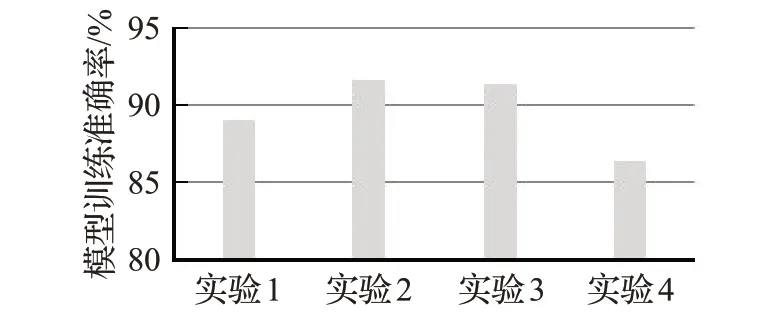
图5 不同超参数模型训练准确率对比图
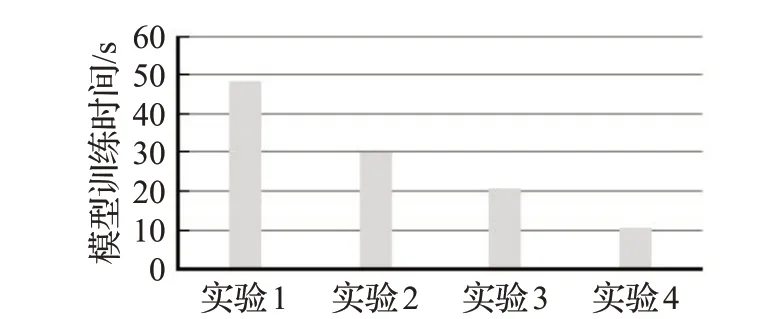
图6 不同超参数模型训练时间对比图
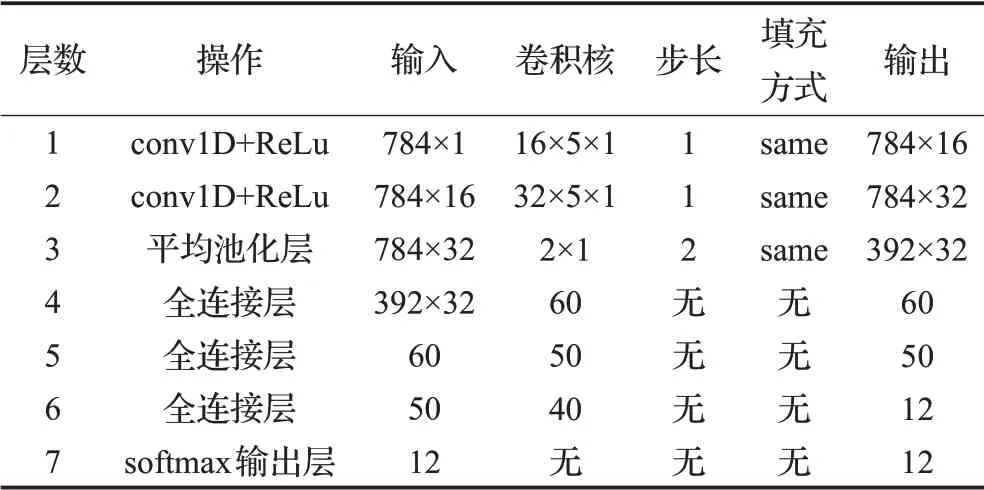
表3 本文一维卷积神经网络中的超参数设置表
4 方案实现与测试
为了验证提出的一维卷积神经网络模型对于流量分类的可行性,本文使用Keras库,其后端是TensorFlow,部署在一台处理器为Inter i5-6500,主频3.2 GHz,内存4 GB,64位Linux操作系统的机器上。
使用5个评估指标进行模型的对比,分别为:准确率、分类时间、召回率、类精确率以及F1分数。准确率用于评估分类模型的总体性能,准确率越高代表分类效果越好。F1分数、召回率、精确率三方面可观察分类模型对于每一类别分类的好坏。其中TP是正确分类为x的实例数,TN是正确分类为not-x的实例数,FP是错误分类为x的实例数,FN是错误分类为not-x的实例数。

文献[12]开发了数据预处理工具,将网络流量数据集处理为类似minist数据集形式,使用传统的一维卷积神经网络LeNet-5模型进行流量分类分类。本文提出的数据预处理方式保留了网络流量的序列化特性并去除了对于流量分类没有意义的字段。在本文的实验环境平台上,从准确率、类精确率、召回率、F1分数以及模型分类时间与传统的一维卷积神经网络模型对比,其对比结果如表4、表5、图7~图9所示。为确保总体分类时间对比结果的可靠性,两种模型的分类时间的对比实验分别在处理器为Inter i5-6500,主频3.2 GHz,内存4 GB,64位Linux操作系统的机器上以机器的正常CPU频率,最高CPU频率、最低CPU频率以及在一台处理器为Inter i5-3337U,主频1.8 GHz,内存4 GB,64位Linux操作系统的机器上以机器的正常CPU频率做对比实验,4次实验的时间对比结果如表5所示。从表5可以看出在不同主频和CPU频率下运行传统神经网络分类模型的平均分类时间为8.891 4 s,运行本文神经网络分类模型的平均分类时间为2.535 7 s。因此本文提出的分类模型的比传统模型的分类时间平均缩短了6.355 7 s,平均分类时间节省了约71.48%,这说明所设计的卷积神经网络在分类时间上有了很大的提升。

表4 总体准确率对比表
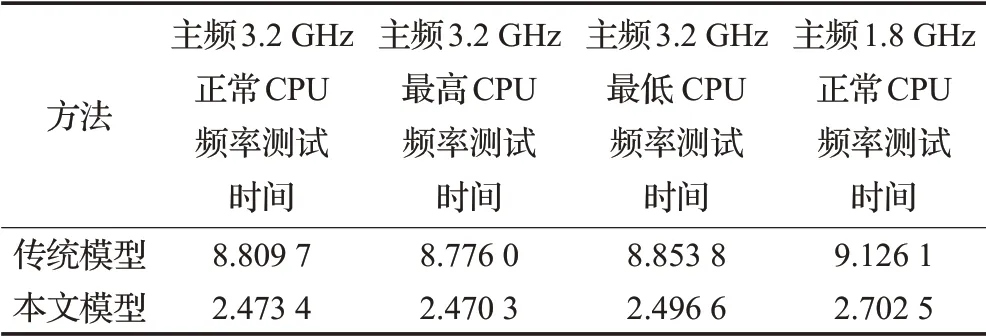
表5 总测试时间对比表s
通过图7~图9的对比结果可以看出,使用本文的一维卷积神经网络模型以及超参数空间与传统的一维卷积神经网络模型相比,在总体准确率、类精确率、召回率、F1分数几方面也有较好的提升。因此,提出的流量分类方法为后续实时网络应用程序流量分类奠定了基础。
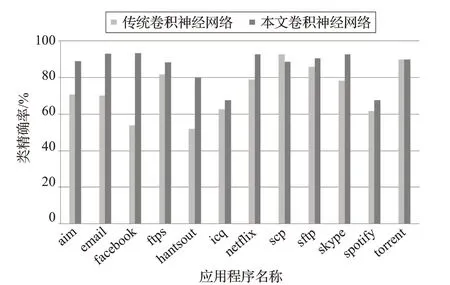
图7 类精确率对比图
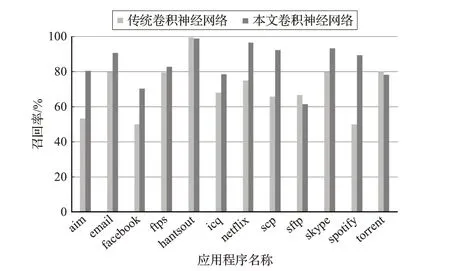
图8 召回率对比图
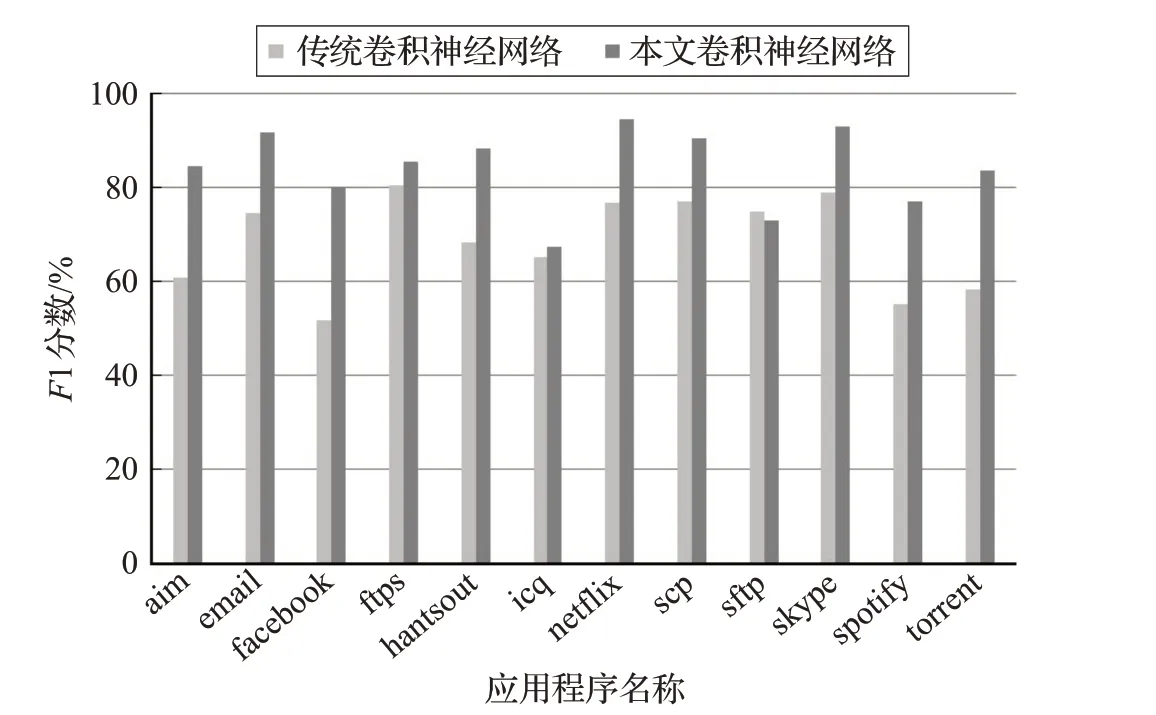
图9 F1分数对比图
5 结束语
本文基于传统机器学习算法进行流量分类的研究问题以及相关研究的基础上从神经网络结构、数据预处理方式、超参数空间以及梯度优化方面入手提出一种新的一维卷积神经网络模型。首先设计一种新的一维卷积神经网络模型结构,将网络公开数据集进行数据预处理,去除不相关的字段并截取固定长度后进行标准化操作作为卷积神经网络的输入。然后通过卷积神经网络结构特点自主学习网络流量的更高级别特征,经过网络模型的训练进行参数优化后构造特征空间进而完成网络应用程序的流量分类任务。最后使用网络公开数据集对本文提出的流量分类算法进行验证并取得较好的分类效果。因为深度学习算法在网络流量分类方面的研究仍处于不成熟的阶段,本文在未来的研究方向应朝着处理真实网络流量数据的分类问题继续努力。
